
相关关键词与相关图书标签云
2013-09-12 02:23:44黎邦群惠州学院图书馆广东惠州516000
图书馆建设 2013年8期
黎邦群 (惠州学院图书馆 广东 惠州 516000)
自从照片共享网站Flickr应用标签云以来,Del、Technorati等网站纷纷跟进。标签云使得网站内容之间的相关性和网站的互动性大为增强,深受用户欢迎。随着Web 2.0的兴起和发展,标签云逐渐在各行业网站得以应用,包括众多的电子商务网站、网络搜索引擎网站及数据库公司网站等。国外图书馆亦进行了标签云应用的相关尝试,如美国密歇根州安阿伯图书馆的SOPAC (Social Online Public Access Catalog,社会化联机公共目录查询系统)应用了编目标签云,纳什维尔公共图书馆应用了青少年网络标签云等。这是图书馆为主动适应Web 2.0环境而做出的积极选择,为日渐式微的OPAC(Online Public Access Cataloge,联机公共目录查询系统)注入了新的活力。同时,相关的理论研究也层出不穷,如排序的算法[1-2]、个性化推荐[3-4]及可视化布局[5-6]等。这些实践与研究有力地推动了标签云应用与理论的发展,对本研究具有一定的参考价值。
然而,由于标签固有不受控、无等级结构、拼写易错等缺点,标签云这一新兴的检索推荐技术还没有在国内图书馆得到深入研究与广泛应用。现有的标签云多是基于用户自由定义的,标签由用户输入,甚至直接由书目编目数据中的主题词组成 ;现有的图书推荐多是基于用户兴趣的,图书馆将最符合阅读习惯的图书推荐给特定的已知用户;图书馆缺少对检索数据的深入分析和挖掘整理以及对未知用户的检索词与图书的推荐。本文试图对检索词、检索行为的特征以及它们之间隐含的关联规则进行知识分析,并对相关数据进行收集、利用、挖掘和整理,拟从知识的相关性角度来设计和实现非个性化的OPAC相关关键词或图书的动态标签云。
1 现状及需求
1.1 相关概念
标签(Tag)与标签云(Tag Cloud)的应用均属于Web 2.0的典型特征。标签是用户对网站内容的描述词方式,借此实现对信息的个性化分类和关键词检索。标签云由标签演变而来,是对一组拥有不同字号和颜色的超链接及相应权重的标签的可视化组织和表现形式。标签云以标签的使用频率或被关注度等指标为权重,定量地计算每个标签的权值,并使用不同的颜色或字体大小定性地表示,形象、直观地在网页上展现给每位用户。相关关键词或图书的标签云是OPAC根据用户行为数据来判断检索需求与查询意图,在网页上展示一组领域相同、主题相近及内容相似的检索词或图书,根据相关度或相似性赋予不同的权重,并采用一种类似云图的可视化形式呈现出来的推荐功能,属于一种图书馆大数据的信息挖掘技术与云计算的资源组织模式有效结合的新型应用服务。
1.2 应用现状
为了认清应用现状,笔者对国内部分高校图书馆OPAC进行了抽样调查。调查时间:2013年3月20日;调查对象:教育部最近公布的112个“211工程”高校图书馆OPAC;调查内容:相关关键词或图书的推荐功能以及其标签云的应用;调查方法:访问各图书馆OPAC,输入常见关键词进行检索,查看是否返回相关关键词,并浏览任一图书详细信息页面,查看是否推荐了相关图书,检查标签云应用状况;调查结果:除了4个图书馆OPAC因故无法访问,没有发现任一OPAC的检索结果或最终信息页设置了相关的推荐功能与标签云应用。
为了进一步认清现状,笔者又随机调查了部分其他图书馆OPAC,依然一无所获。结果表明,标签云的相关功能与应用尚未在图书馆广泛实践。于是笔者又查询了中国知网等数据库,没有找到专门针对检索行为的相关性而进行的非个性化推荐及以标签云的形式向OPAC用户进行展示的研究。然而,对用户进行相关信息的推荐是符合一定的用户需求的。
1.3 需求分析
缺乏对网站信息进行多元化地揭示、辨识与引导,内容表现形式过于专业与僵化,是传统OPAC固有的缺陷。如何让用户从浩如烟海的信息中找出自己感兴趣的信息,同时让有价值的信息被需要的用户享用,一直是业界关注的热点问题[7]。OPAC存在的根本目的就是为了尽力帮助用户找到需要的馆藏资源。以用户为中心的服务宗旨要求图书馆为了用户更便捷地寻找资源而不断改进OPAC,提升其可用性和使用体验。相关关键词标签云能够在书目检索时给予用户可能比检索词更合理、更科学的关键词推荐,符合用户检索时的最省力法则,并在检索失败时,可以引导用户点击标签链接,轻松地选择新的关键词重新进行检索,而不至于不知所措。相关图书标签云能够让用户在对检索结果不满意时重新找到需要的图书,或向用户推荐隐藏的相关图书,将用户的隐性知识显性化,让用户感到意外的惊喜。这种具有知识性与互动性的OPAC,无疑对用户更具诱惑力。
2 设计与实现
相关关键词或图书标签云的设计与实现,需要利用数据挖掘技术对检索词及检索行为数据进行隐性知识分析与整理。相关标签云的设计与实现实际上是一种未知知识的发现过程,与数据挖掘(Data Mining)过程密不可分。数据挖掘是指通过分析每个用户数据,从大量数据中寻找其规律的技术,主要包括数据准备、规律寻找和规律表示3个步骤。
2.1 方案设计
用户需求促使笔者采用一定的技术方案来进行设计。两种标签云设计的关键在于如何获取标签及计算权值,依据其差异性存在如下两种设计方案:
(1)分割设计 将相关关键词与相关图书加以区分,分别独立设计两种标签云:以历史检索词为目标,与关键词进行对比,选择相似词语作为标签组成相关关键词标签云;采用用户添加的图书标签或主题词等书目元数据作为标签组成相关图书标签云。
(2)关联设计 对用户输入的检索词及检索行为数据进行深入挖掘,找出其中存在的知识关联,并以此确定相关关键词或图书标签云,综合设计两种标签云。这两种标签云的标签虽然不是用户或图书馆编目员显性添加的,但是更能反映用户的直接需求。
对两种方案进行对比发现,前者设计思想简单,但标签的相关度低;后者设计原理复杂,但标签之间的相关度更高,用户体验更好,因而笔者决定采用方案(2)即关联设计方案。
2.2 技术思路
根据方案(2)的设计,相关关键词与相关图书的技术思路如下:系统存储用户多次的检索行为及数据,分析第n次与第n-1次行为之间的内在联系,并以此确定相关的关键词或图书,利用它们之间的关联数据设计相关标签云。用户检索行为大致分为7个部分,如图1所示。
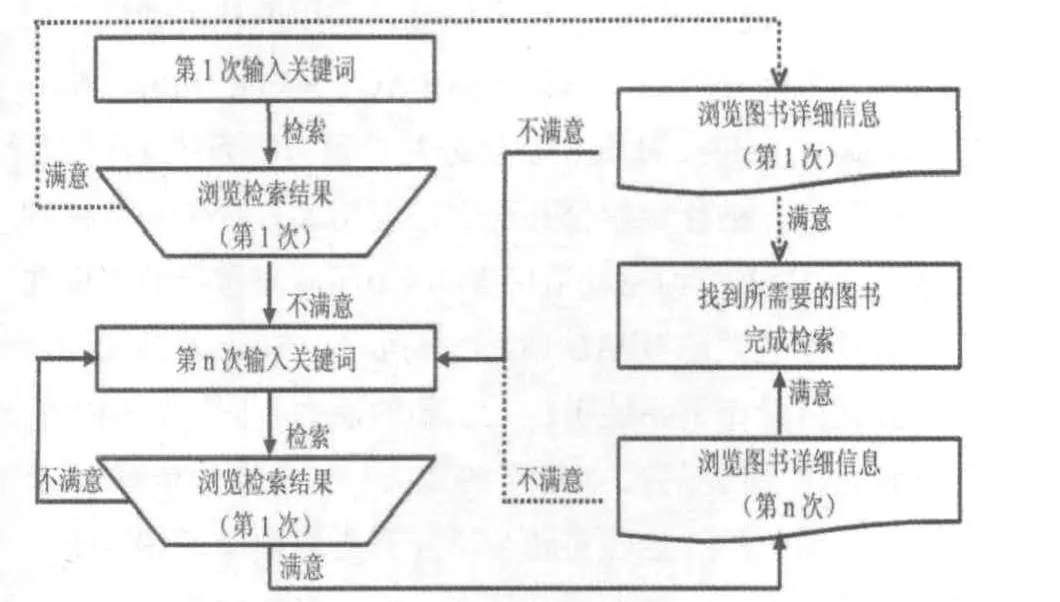
图1 相关关键词与相关图书技术思路图
技术思路的关键在于假设用户在短时间内连续执行了多次检索,并且先后浏览了相关的多种图书。技术难点在于跟踪与分析用户的检索过程,判断与甄别检索的意图与结果。
2.3 相关原理
在Web 2.0时代,用户应该既是标签的创造者,也是标签的使用者。因此标签云的设计离不开标签的创建与显示。根据相关技术思路,用户对第n-1(n大于1)个关键词及第n-1次的检索结果不满意,再输入第n个关键词,产生第n次检索结果,那么第n-1次的检索行为是第n次检索的相关检索行为;第n-1个关键词是第n个关键词的相关关键词;第n-1次浏览的图书是第n次浏览的图书的相关图书,即根据用户每次及前一次的检索行为来确定相关的关键词或图书。系统再把所有用户的这些相关关键词或图书的数据进行累积,按照它们被用户关注的程度标注相应的频率或权重,存储在相关数据表中,作为用户贡献的标签,组成相关关键词或图书的标签云。
2.4 数据结构
在采用了一定的设计方案,分析了技术思路及相关原理之后,即可进行标签云的数据结构设计,包括数据表构建及数据存储等标签云实现前的准备工作。
(1)数据表结构 为了存储关键词与检索行为以及相关性,需要在服务端数据库中设计相关关键词x_ keyword数据表与相关图书x_book数据表等二维表,表结构分别如表1、表2所示。
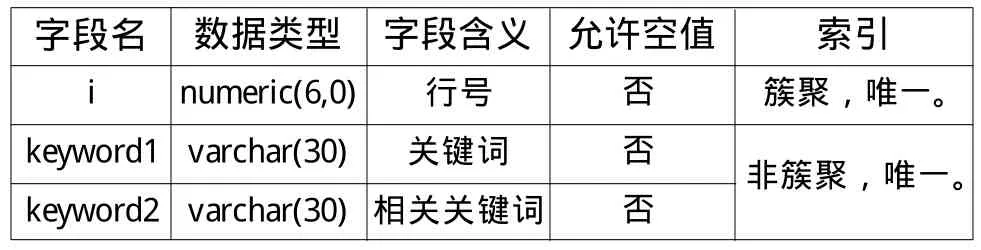
表1 相关关键词x_ keyword数据表结构

表2 相关图书x_book数据表结构
表1、表2还包括Fre1(关键词被检索频率或相关图书被流通的频次)、Fre2(相关关键词被检索频率或图书被认为相关的频率)、Fre3(被认为相关的频率)、Ftime(被认为相关的时间)及h(点击次数)等字段。字段keyword1与keyword2仅存储“2≤字符长度≤30”的有效关键词信息,部分字段间存在关联。
(2)数据存储 当用户连续两次以上检索时,系统即开始启动相关数据的分析与存储程序。例如,用户首次使用的检索词为“红楼梦”,其在检索结果中浏览了图书《红楼梦》的详细信息,但对该结果不满意或尚需查找更丰富的类似图书,便再次输入“石头记”,浏览了图书《脂本汇校石头记》的详细信息。此时,系统将认为第1个与第2个检索词为相关关键词与关键词,第1种图书为第2种图书的相关图书。系统首先使用字符串连接数据库,再使用“Select”等Sql语句在相关数据表中进行查重,如果有重,则使用“Update”等Sql语句更新Fre(n)(1≤n≤3)等相关频率字段值,否则使用“InSert”等Sql语句在数据表中插入新记录。经过一段时间的实践积累,随着检索行为与用户关注度的增加,数据表记录会不断丰富,从而为标签云的实现提供了足够的相关标签及权重选择。
2.5 功能实现
图书检索是一种认知过程,从用户产生图书查找的需求开始,通过输入关键词、检索和评价而完成。用户选择检索结果的行为实际上就是一种对系统性能、检索质量及所选图书的评价行为。有了前面的设计基础,即可开始实现标签云的功能,具体步骤如下:
(1)分析检索词及检索行为 系统首先接受用户在客户端输入的检索词,并对数据特征及用户的其他检索行为进行关联分析,以便通过用户的多次检索行为来判断关键词及图书的相关性。如果用户仅进行了1次关键词检索及图书浏览等检索行为,则不产生相关数据;如果用户进行了两次以上的检索,则还需要分析检索词的数据特征,过滤“!"#$%&'()*+,.-_/:;<=>?@[]^`{|}~”等特殊符号与无效字符、过长与过短的词语等无意义或相关度不高的关键词,保留正常的关键词。依据用户所浏览图书的题名、主题词、分类号、责任者和出版社等编目元数据以及发送检索请求的时间间隔与先后次序,将其作为辅助手段来判断用户连续多次检索过程中的意图是否相近,以甄别用户连续输入的检索词及先后浏览的图书是否具有相关性。
(2)查询相关数据表 当用户输入关键词“key”进行书目检索时,系统除了检索书目表外,还需要同时查询x_ keyword数据表的keyword1字段,获取所有匹配记录的keyword2及Fre3等字段值;当用户浏览图书“F200”的详细信息时,系统应查询x_book数据表的F200a1字段,获取所有匹配记录的F200a2及Fre2等字段值。关键词“key”的查询语句如下:
Set RowCount 120 Select keyword2, Fre1, Fre2, Fre3,Ftime From x_ keyword Where keyword1 Like '"& key &"'Order By Fre2 Desc
(3)客户端效果展示 即功能实现。标签云通常使用XHTML元素来表现,依照字典顺序、随机顺序及热门程度等准则来确定标签的排列顺序,一个标签云一般拥有多个内容相似的标签,以更方便地组织数据、汇总检索结果及辅助二次检索。查询数据表获取相关关键词或图书后,按照x_ keyword数据表的Fre1、Fre2、Fre3字段及Ftime值的区别,或按x_book数据表的Fre1、Fre2字段及Ftime值的不同,分别赋予keyword2或F200a2差异化的字体和渐变的过渡效果来展现标签的受欢迎程度,还可以通过字体粗细、颜色及标签的位置等标示来表现标签的使用频率或受关注程度,并输出到客户端展示给每位访问者,把用户的关注点吸引到特定区域,如图2、图3所示。

图2 相关关键词标签云图

图3 相关图书标签云图
图2和图3可以分别放置于检索结果页和图书详细信息页的右侧显眼处,供用户选择。点击“显示更多”链接,最多可显示150个标签。点击图2中的标签链接,访问关键词的检索结果页;点击图3中的标签链接,直接返回图书详细信息页。还可以在链接目标页鼓励用户对被推荐的图书投票,如用户认为某图书具有准确的相关度或相似性,确实值得向其他用户推荐,即可以投其一票。用户的评价将被系统作为推荐的重要依据。
2.6 实现效果
从惠州学院图书馆OPAC的相关关键词与相关图书标签云试用情况来看,其功能运行性能及用户反映不错,在单位时间内初步取得了较好的用户反馈与实践效果(见表3)。
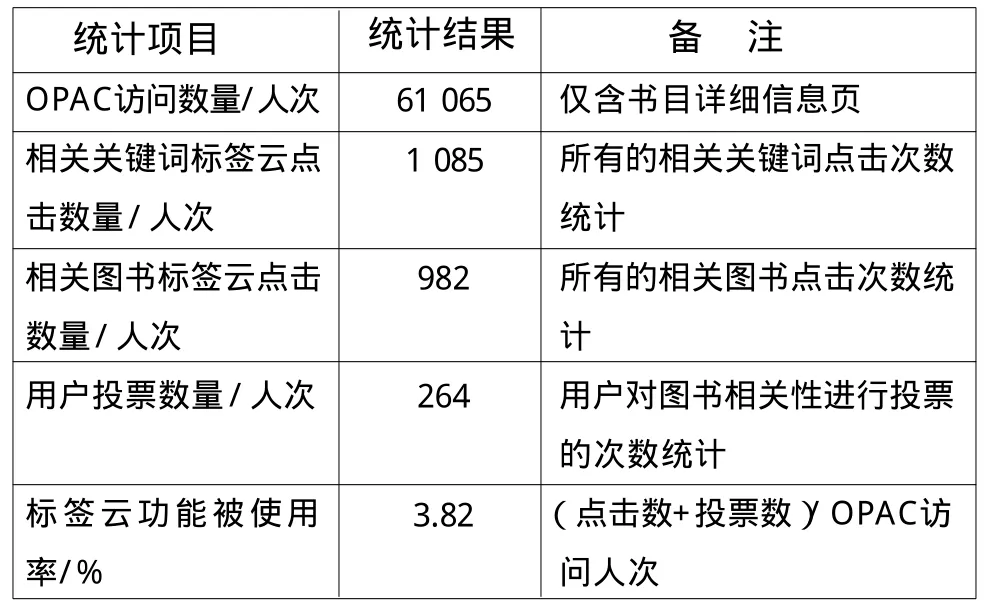
表3 2013年1—3月惠州学院图书馆OPAC的相关关键词与相关图书标签云应用统计
分析表3得知,OPAC用户具有一定的推荐需求与反馈兴趣,标签云的应用已成为图书馆拓展服务内容与形式的新渠道。经过一定时间的累积,相同、相关或相似的关键词与图书数据会更丰富,使用的用户也会逐渐增多,服务功能将日臻成熟。
2.7 用户体验的提升
OPAC作为图书馆的资源门户,已经从Web 1.0、Web 2.0发展到了Web 3.0,其用户已从早期的被动接受,到被动参与,再到主动参与,到自我创造内容,再到注重体验[8]。任何新技术的应用都可能受到广泛的欢迎或部分的质疑,标签云的应用亦不会例外。例如,部分用户可能对放大的字体或异常的标签颜色不习惯,感觉视觉不舒服,认为网页制作得“很糟糕”或“不专业”;也有可能并非字体越大,就越容易被用户所接受和选择。这不是简单的品味或审美问题,而是标签云在图书馆应用缓慢的原因之一。对标签云的显示效果与用户评价图书馆应予以高度重视,从各方面加以改善、提升体验,具体策略包括:
(1)数据异常处理 查询x_ keyword与x_book数据表时,完全有可能返回的记录数太少,甚至结果为0,从而导致显示的标签数量过少或完全没有。数据异常将造成标签云显示效果不美观,影响用户的使用体验,甚至给其带来不小的困惑。时间因素导致检索行为数据积累不够,相关数据过少或不存在,从而造成数据异常。图书馆可以将检索词“key”进行中文分词,使用x_ keyword数据表的keyword2字段替代原keyword1字段作为查询对象,对keyword2执行Sql模糊查询,以扩大查询范围。还可以将图书题名、主题词、分类号、责任者或出版社等信息作为查询词,并以图书的点击次数或流通频率作为衡量标签权重的依据。
(2)优化显示效果 标签云的显示效果与标签的字体大小、类型、颜色、粗细、字符数量、摆放位置、叠词效果、笔画繁简程度、标签区域及宽度、强度和像素数等属性的设置有关。图书馆可以利用JavaScript、Flex、Flash及Css等网页显示技术将标签云设计成动态或3D特效,克服文字尤其是汉字标签显示效果不佳的弊端,最大程度地优化显示效果,以更好地吸引眼球。例如,雅虎研究院设计的Flash版TagLines[9],不仅可以按时间线形显示文字,还可以显示动画,可视化效果震撼(见图4)。

图4 Tag Lines演示图
(3)改进标签的排序方法 按字顺排序,不能很好地体现标签的被关注程度;按使用频次、热门程度或流行程度排序,会让关注度高的标签一直排在前面,形成人为地从高到低排列的视觉效果,不仅不美观,而且无法体现标签之间的相关度。另外,历史关键词可以通过时间的累积而累加频次,部分新的关键词固然重要,但因使用频次低而无法“曝光”。为了消除时间累积效应,在不同时段内分别计算标签的权重[10],即应用带时间轴的标签云是比较科学的排序方法。设计者通常需要凭实际情况来决定如何组织与显示标签,以达到最佳效果。
3 扩展应用
图书馆要秉承一切为了用户的服务理念,不断优化、改进各项OPAC功能,使书目检索向更便捷、更符合人类思维的方向发展,向用户提供更人性化、个性化的服务,从而更好地发挥检索功能,提升服务水平。通过对相关关键词或图书的标签云进行扩展应用,能够增强OPAC与用户的互动性与检索功能,提升其服务效果。
3.1 相关思路扩展应用
依据相关思路与原理,将相关关键词的实现方法按照需要进行相应修改,即可实现如下3种功能:
(1)利用x_ keyword数据表的keyword1与keyword2字段的相关性,实现类似网络搜索引擎搜索结果页面底部的“相关搜索”功能[11]。
(2)利用x_ keyword数据表的keyword1字段及其拼音,实现基于Ajax的检索输入框连续输入提示与“拼音搜索”功能[12]。
(3)利用x_ keyword数据表的keyword1字段,构建基于关键词的拼写词汇数据库字典,实现检查用户检索词输入正确与否的“拼写检查”功能[13]。
上述功能将提高书目检索的查全率与查准率,为用户提供丰富的检索建议与提示。
3.2 标签云扩展应用
按照图书标签云的设计思路与原理,很容易联想并实现主题词或责任者、热门图书或主题词以及图书分类等多种标签云,其中有些已在部分图书馆应用,如厦门大学图书馆OPAC[14]应用了热门检索词标签云,中国社会科学院图书馆[15]和中山大学图书馆[16]等Ex Libris用户的OPAC系统应用了主题词标签云等。
4 结 语
本文就相关关键词与图书标签云的背景、现状及需求、设计与实现以及扩展应用进行详尽的研究,是对普通标签云的延伸和扩展。本文所研究的相关关键词与相关图书标签云,除了具备一般标签云的交互性、开放性及扁平化等Web 2.0的典型特征外,还具有如下个性特色:标签并非用户直接标注,而是基于检索行为分析的结果;每个标签之间具有高度的相关性,对用户更有吸引力;两种标签云之间的数据存在因果关系或其他知识关联,更能改善用户检索体验。相关关键词与相关图书标签云作为OPAC的一项附加功能,体现了“群体智慧”,承载的数据量大,信息投放精准,能给检索行为带来一种全新的体验,达到了用户贡献知识以共享和交流的目的。
[1]Park J ,Choi B, Kim K, et al.A Vector Space Approach to Tag Cloud Similarity Ranking[J].Information Processing Letters,2010(12):489-496.
[2]夏秀峰,张 姝,李晓明.一种个性化标签云中的标签排序算法[J].沈阳航空航天大学学报,2011(1):46-50.
[3]Naureen N,Carolyn W.A Comparative Study of Navigation Using Single VS.Community Driven Tag Clouds on Websites[J].Proceedings of the American Society for Information Science and Technology,2012(1):1-4.
[4]曾子明,张 振.社会化标注系统中基于社区标签云的个性化推荐研究[J].情报杂志,2011(10):128-133.
[5]Daisuke Y,Tomoki M,Shigeki O,et al.Collaborative Video Annotation by Sharing Tag Clouds[J].Transactions of the Japanese Society for Artificial Intelligence,2010(2):243-251.
[6]张 媛,赵艺超.基于用户体验的标签云可视化布局研究[J].计算机与数字工程,2011(10):16-17.
[7]黎邦群.用户参与书目建设研究[J].图书馆杂志,2012(12):20-23.
[8]李 宾,沈晓梅.从用户接受到用户体验:谈图书馆用户角色变化[J].图书馆论坛,2010(2):17-19.
[9]雅虎研究院Taglines演示[EB/OL].[2013-02-20].http://www.research.yahoo.com/taglines.
[10]廖 凤,张建勇.Keyword Cloud在文献检索中的应用研究[J].图书馆杂志,2010(9):57-61.
[11]黎邦群.OPAC相关搜索功能的设计与实现[J].图书馆学研究,2011(12):56-59.
[12]黎邦群.OPAC拼音搜索功能的设计与实现[J].现代图书情报技术,2011(9):88-93.
[13]黎邦群.OPAC拼写检查功能的设计与实现[J].图书馆学研究,2012(4):73-79.
[14]厦门大学图书馆书目检索系统[EB/OL].[2013-02-20].http://210.34.4.28/opac.
[15]中国社会科学院图书馆[EB/OL].[2013-02-20].http://www.lib.cass.org.cn.
[16]中山大学图书馆[EB/OL].[2013-02-20].http://library.sysu.edu.cn.
猜你喜欢
江苏科技信息(2022年16期)2022-07-17 09:07:36
党员生活(2020年2期)2020-04-17 09:56:30
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
铁道通信信号(2018年10期)2018-12-06 09:34:56
专利代理(2016年1期)2016-05-17 06:14:36
图书馆建设(2015年10期)2015-02-13 03:48:27
中国石油企业(2014年4期)2014-11-30 06:13:06
新世纪图书馆(2014年7期)2014-09-19 12:20:40
河南科技(2014年24期)2014-02-27 14:19:25
图书馆建设(2014年3期)2014-02-12 15:41:35
