
基于W-Kmeans算法的DNS流量异常检测
2013-09-08 10:18:30林成虎李晓东键1尉迟学彪
计算机工程与设计 2013年6期
林成虎,李晓东,金 键1,,尉迟学彪,吴 军
(1.中国互联网络信息中心,北京100190;2.中国科学院 计算机网络信息中心,北京100190;3.中国科学院研究生院,北京100190)
0 引 言
域名系统 (domain name system,DNS)的主要功能是实现IP地址到域名之间的相互转换[1]。在日常的网络应用中,DNS经常遭受到破坏者的恶意攻击,比较常见的有DNS缓存中毒、DNS重定向、DNS信息劫持、DNS放大攻击、DNS的DDOS攻击等。DNS方面的重大安全事件也时有发生,如:2009年 “5.19暴风影音”事件,2010年“百度域名劫持”事件等。DNS的安全形势越来越严峻,保护DNS的安全稳定不容懈怠,特别是能够主动地检测出DNS访问的异常,意义重大。
在DNS异常检测方面,Ishibashi等[2]针对特定域名的DDOS攻击,分析了修改DNS服务器配置对攻击流量的影响;Villamarin-Salomon等[3]对DNS流量进行相似性分析,利用贝叶斯算法来检测已知特征的僵尸网络流量攻击;Kirkpatrick等[4]通过对A根服务器的DNS流量进行聚类检测和线性判别,发现DNS服务器的错误配置;Chatzis等[5]对DNS查询流量进行了基于时间序列相似性的研究,用来检测邮件蠕虫。这些检测方法都有一定的局限性,检测的攻击类型过于单一,缺乏对未知特征攻击的检测能力,误报率较高,而且检测的实时性较差。
为此,本文主要提出了一种基于权重的Kmeans(WKmeans)算法,结合多特征检测,能够快速有效地发现DNS查询流量异常。
1 Kmeans算法基本原理
Kmeans算法[6]是一种基于划分的聚类分析方法,被广泛应用于各种异常检测中,其核心思想是:将n个向量(对象)的集合划分为k个类簇,使得同一类簇内的向量相似度高,不同类簇之间的向量相似度低。
设待分类的向量集合为 {x1,x2,x3,… ,xn},dis(x,ck)表示向量x与向量ck的欧氏距离,向量x表示待分类的向量,向量c表示聚类中心向量,m表示向量的特征个数。
该算法的基本流程如下:
(1)选定k个向量作为初始聚类中心 {c1,c2,c3,… ,ck}。
(2)将待分类的向量逐个计算与每个聚类中心的距离,按最小距离原则把每个向量划分到某一类中,这里是计算向量间的欧氏距离
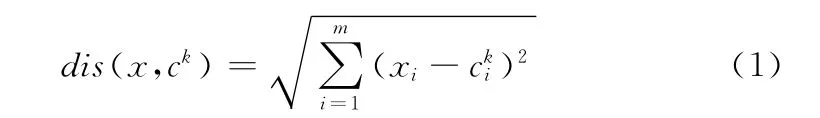
式中:cki——的是某个聚类中心ck的第i个特征取值,而不是聚类中心k的更换。
(3)重新计算分好类之后的每个类中心,即利用式(2)计算每个类中所有向量的均值,其中,v表示的是第k类内向量的个数

(4)如果重新计算的类中心有变化,则转至 (2)重新迭代,直到每个类中心不再发生变化。
2 基于W-Kmeans的检测方案设计
由于在不同的应用场景中,不同的向量特征对聚类结果的影响也不同。所以,我们需要对Kmeans算法做出一定的改进来应用于实际情况。本文主要是利用检测算法对“5.19事件”中真实的DNS数据进行实验分析,结合DNS流量异常的基本特征,提取了查询频率、源IP地址的分布空间、源IP地址的熵值、查询域名的分布空间、域名查询的最大次数、查询域名的熵值、递归查询的比例等7个相关特征 (即m=7),但发现提取出来的每个特征值之间的数量级差异很大,如果直接用式 (1)来计算欧氏距离,数量级大的特征值在检测算法中占用的权重就特别大,甚至可能抹掉数量级很小的特征值对检测结果的影响。为了得到更好检测效果,有必要对不同的向量特征赋予不同的权重,我们将这种基于权重的Kmeans算法称为 W-Kmeans算法。因此,采用式 (3)替代式 (1)来算欧氏距离

式中:wi——向量第i特征的权重。
本文在实验提取7个向量特征之后,通过对特征数据集的具体分析,对各个特征赋予不同的初始权重。在本设计方案中,各个特征的初始权重取值如下:查询频率取权重 (1/10000)2,源IP地址的分布空间取权重 (1/1000)2,源IP地址的熵值取权重102,查询域名的分布空间取权重(1/10000)2,域名查询的最大次数取权重 (1/1000)2,查询域名的熵值取权重102,递归查询的比例取权重102。因为在不同的流量环境中,单位时间内的DNS查询次数不同,故提取的特征数据值也不同,但总的原则是,初始权重的取值大小要使得同一特征值的大部分数据两两相减的差值范围落在0至1之间,不同特征值相减后的差值数量级也尽量控制在10倍以内。同时,为了分类效果更佳,还需要根据实验结果对各特征值的权重值进行微调,根据先验知识,可以在检测 “5.19事件”DNS流量异常的具体情景中再适当调高递归查询比例的权重值。
W-Kmeans算法是机器学习领域中的一种无监督学习,除了可以检测出在训练集中标记过的异常类簇,还能发现新的未知特征异常。为了更好地检测出未知特征的DNS异常流量,提高检测算法的泛化能力和准确率,我们设定一个欧氏距离阈值Dthreshold。当某个向量开始被划分到正常类簇中,但是该向量与正常类中心向量的距离大于阈值Dthreshold时,要重新将该向量划分为异常类。阈值Dthreshold取值的大小可根据具体应用环境进行设置,在不同的检测环境中,阈值的大小也不同,需要对 “5.19事件”的真实数据和实验的分类结果进行分析后再确定。
在应用W-Kmeans算法的过程中,k值是需要事先给定的,k值的大小直接影响分类的效果,很多时候,由于待检测样本的未知性,k值的选定很难预测和评估。但在这里,我们分类的目的很明确,就是要区分出正常流量和异常流量,因此,类簇取值k=2,不存在k的取值问题。
此外,初始聚类中心的选择,对聚类结果也有较大的影响。而且,特征集的孤立噪声点比较敏感,不能选为初始聚类中心。这里,为了实验结果的可复现性,我们根据先验知识选取了16:00和19:00左右的两个向量点作为初始聚类中心,并可将训练结果的聚类中心纳入知识库,用于以后的DNS流量异常快速检测。
利用该设计方案来检测DNS流量异常的基本流程如图1所示。

图1 DNS流量异常检测流程
其中,特征提取是将原始数据源转化为算法参数的关键一环,将在第2.2部分详细阐述。向量特征的相关程度,直接影响算法分类效果好坏。同时,结果分析是根据著名“5.19事件”的公开性、可调查性来调整检测算法参数的选择,优化分类结果,并为算法的检测效果提供权威的让人信服的依据。
2.1 数据预处理
DNS查询日志蕴含着丰富的有用信息,记录了用户查询行为的绝大部分信息,是DNS系统中最宝贵的资源之一。算法检测的数据来源,是CN域名权威服务器上记录的DNS查询日志,其产生的日志记录每一行代表一次查询行为,形如:

其中,为查询请求时间;为查询来源IP地址;为用户源端口;“ns.xinnet.cn”为用户请求查询的域名;为资源类别 (class),表示Internet,是最常见的一种;为资源记录类型 (RR type),表示请求查询该域名的IPV4地址;“+”表示递归查询。
可以看出,每条日志中有用的信息是:时间、源IP、源端口、查询域名、资源类别、资源记录类型、递归标识。在数据的预处理过程中,我们就把这些信息提取出来。
在一些常见DNS流量攻击中,经常出现很多伪造的查询域名,即:随机字符串+固定域名后缀,而且在域名系统中,形如 “ns.xinnet.cn”和 “ns2.xinnet.cn”的域名是属于同一个子域 “xinnet.cn”的,也是位于同一个区数据文件中的。所以,我们有必要对查询域名进行归约处理,根据CN域名的命名规则[7],将日志记录中出现的所有CN域名都归约为CN域下的二级域名,或者CN域下的43种按机构性质、行政区域申请的三级域名。比如www.sina.com.cn、 news.sina.com.cn、 sports.sina.com.cn等,都将被归约为sina.com.cn的查询。
2.2 特征选取
W-Kmeans算法检测的精确性很大程度上依赖于DNS流量特征的选取。在仔细分析了DNS流量异常的一般特征后,我们从CN顶级域主机房节点的权威服务器上采集了2009年5月19日16:00—24:00之间的查询日志来做检测分析,对原始的DNS查询日志经过预处理后提取了7个向量特征值作为检测算法的输入参数。
(1)查询频率——单位时间内DNS查询请求的总次数,这是最直接反映DNS流量变化情况的一个特征值。当查询频率发生突变时,DNS流量必定有异常,反之则不一定成立。如图2所示,是所用数据集的查询频率图。

图2 查询频率
(2)源IP地址的分布空间——单位时间内访问的不同源IP地址的数目。恶意流量攻击发生时,源IP地址的分布空间必定会发生变化。在一些攻击中,攻击者通过伪造源IP地址,或者通过控制大量的被感染 “肉机”来发起恶意流量攻击,在攻击的初始阶段,源IP地址的分布会先增大,当恶意流量占满被攻击目标的服务信道,其它正常IP的请求被湮没,甚至无法进入服务信道后,源IP地址的分布再逐渐减小。
(3)源IP地址的熵值——在信息论中,熵[8]表示整个系统的平均信息量,可以用熵值来表示一个系统的稳定性。当DNS发生流量异常时,必定会引起查询源IP地址熵值的突变。如图3所示,是源IP地址的熵值图。计算熵值的式 (4)如下

式中:X——单位时间内的事件集合 {x1,x2,x3,…,xn},pi——事件xi出现的概率,s——单位时间内出现的不同源IP地址的数目。

图3 源IP地址熵值
(4)查询域名的分布空间——单位时间内请求查询的不同域名的数目。当发生恶意流量攻击时,查询域名的分布空间也会呈现出与正常情况不一样的规律,分析与源IP地址的分布空间类似。
(5)域名查询的最大次数——单位时间内单个域名被重复查询的次数,取最大值。次数越大,说明同一个域名被访问的平均时间间隔就越小。此特征能有效检测针对特定域名的恶意攻击异常。
(6)查询域名的熵值——当DNS流量发生异常时,也必定会引起查询域名熵值的明显变化。同样利用式 (4)来计算熵值,分析情况与源IP地址的熵值类似。
(7)递归查询的比例——单位时间内递归查询的次数与查询频率的比例。这是DNS特有的流量特征。在很多的DNS攻击事件中,攻击者经常伪造大量的递归服务器,然后利用这些伪造的递归服务器向攻击目标不断地发出DNS请求,以达到耗尽攻击目标资源的目的。
经过实验对比分析,发现如果单位时间粒度取值太小(1s),特征值就没能包含足够多的信息来更好地判断流量异常,而且时间粒度过小会造成检测算法误报率过高,容易产生虚警。因此,在以上的特征值提取中,我们统一将单位时间取值为10s。
3 实验结果分析
根据工信部的通报[9],2009年5月19日21时左右,我国境内发生大面积的网络故障现象。据调查,事件的起因是域名托管商DNSPOD的服务器在18日19时[10]左右开始遭受大规模恶意流量攻击,其托管在江苏常州电信机房内的服务器被迫离线,包括暴风影音baofeng.com、360.cn等大型网站在内的约10万个域名无法被正常解析,导致全国各地的ISP域名递归服务器收到海量的DNS异常查询请求,各地ISP的服务器不堪重负而瘫痪,进一步演变为全国性网络故障问题。来自基础运营商事后的统计,此次5.19事件的波及范围多达23个省,其中影响较为严重的省份有5至10个。
由于DNS的缓存作用,DNSPOD托管的域名有24小时左右的缓存期,所以当DNSPOD的服务器18日晚被关闭后,并没有立刻出现大面积的网络异常现象。而是在19日下午以后,各地的DNS递归服务器对DNSPOD托管域名的缓存相继失效,大量解析失效的域名不断地发出重复的查询请求,同时大批相关的CN域名的异常查询被引向CN顶级域的权威服务器。因此,CN权威服务器上的DNS日志有效地记录了5.19事件的异常情况。
如图4所示,我们采集了CN顶级域主机房节点19日16:00—24:00之间的查询日志做DNS异常检测分析。通过W-Kmeans算法的聚类分析,图4中得到了正常流量类和异常流量类这两类的分类结果。图4中,每隔90s显示一个采样的向量点,类1表示正常流量类,类2表示异常流量类。
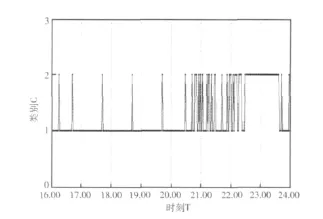
图4 分类结果
由图4中容易看出,从16:00左右开始,就出现零星的异常流量点,这是由于DNSPOD托管的部分域名在各地ISP域名递归服务器上的缓存已经开始失效,异常查询请求开始出现,直到21:00左右,大规模的递归服务器缓存失效,大量的DNS异常查询请求涌入到正常网络流量中,CN权威服务器上记录到的异常流量也频繁出现,达到一个峰值。同时,随着DNS异常流量的持续增多,各地的ISP递归服务器达到负荷极限而崩溃,造成更多相关的CN域名访问无法到达CN顶级域的权威服务器,因此,在22:00以后的很长一段时间内,CN顶级域检测到的都是异常流量,直到20日凌晨左右才慢慢恢复正常。这些检测结果都与工信部公布的通报高度吻合,说明W-Kmeans算法在DNS异常流量检测中具有较好的检测效果。
通过研究发现,利用 W-Kmeans算法来设计多特征和距离阈值相结合的检测方案,并专门用来检测DNS的访问异常,本文所做的这些工作在国内外的DNS领域中都属于首次应用,突破了Kmeans算法应用场景的一些局限性,对 比 于 Ishibashi、Villamarin-Salomon、Kirkpatrick 和Chatzis等人的DNS异常检测方法,也有一定的优势,主要优点在于:①能够结合多特征检测,降低单一特征的误报率;②实时性较好,以10s为单位时间来统计数据样本,既包含了足够多的检测信息,又保证了检测算法的灵敏度,能迅速判断出异常流量;③运算量小,数亿条的原始数据转换成了几千条的向量特征值,向量的数目只与时间粒度有关,新的待检测样本只需要与处理好的训练向量集和聚类中心进行比较,无需与大量的原始训练数据进行计算;④具有较强的泛化能力,通过增设欧氏距离阈值Dthreshold,既能检测出已知特征的流量异常,也能检测出未知特征的流量异常;⑤算法简单易用,收敛速度快,通过各种初始条件的合理设置,能够很好地加快算法的收敛速度。
4 结束语
本文基于W-Kmeans算法设计了DNS流量异常检测的方法,并结合DNS流量异常的一般特征,提取了查询频率、源IP地址的分布空间、源IP地址的熵值、查询域名的分布空间、域名查询的最大次数、查询域名的熵值、递归查询的比例等7个相关特征,设置了欧氏距离阈值Dthreshold,经过真实的实验数据分析,证明了该检测方法具有较高的准确性,而且能通过适当调整算法参数,取得更好的检测效果。
DNS在互联网系统中的地位越来越重要,必须尽可能保证DNS的安全稳定。我们下一步的工作重点是,将本文的检测方法应用于其它场景的DNS查询流量中,并结合中科院自主研发的DNS抗攻击设备,在实践中继续分析与优化特征的选取和各种参数的设置,不断改进该检测方案,进一步提高算法检测性能。
:
[1]Albitz P,Liu C.DNS and BIND [M].Beijing:O’Reilly Media,2006.
[2]Ishibashi Keisuke,Toyono Tsuyoshi,Matsuoka Hirotaka,et al.Measurement of DNS traffic caused by DDoS attacks[C]//Washington:Proceedings of the Symposium on Applications and the Internet Workshops,2005:118-121.
[3]Villamarin Salomon R,Brustoloni J C.Bayesian bot detection based on DNS traffic similarity [C]//Hawaii:Proceedings of the ACM Symposium on Applied Computing, 2009:2035-2041.
[4]Kirkpatrick B,Lacoste-julien S,Xu Wei.Analyzing root DNS traffic [C/OL]. [2012-03-29]http://www.cs.ubc.ca/-bbkirk/papers/cs281a-2004.pdf.
[5]Chatzis N,Brownlee N.Similarity search over DNS query streams for email worm detection [C]//Washington:International Conference on Advanced Information Networking and Applications,2009:588-595.
[6]Han J,Kamber M.Data mining concepts and techniques[M].FAN Ming,MENG Xiaofeng,transl.Beijing:China Machine Press,2010 (in Chinese). [Han J,Kamber M.数据挖掘概念与技术 [M].范明,孟小峰,译.北京:机械工业出版社,2010.]
[7]China Internet Network Information Center.Category of dot CN[EB/OL].http://www.cnnic.cn/jczyfw/cnym/cn01 _ymzc/201102/t20110215_20334.html#2 _1,2012/2012 (in Chinese).[中国互联网络信息中心.CN域名的类别 [EB/OL].http://www.cnnic.cn/jczyfw/cnym/cn01 _ymzc/201102/t20110215_20334.html#2_1,2012/2012]
[8]JIANG Nan, WANG Jian.The theory of information and coding [M].Beijing:Tsinghua University Press,2010 (in Chinese).[姜楠,王健.信息论与编码理论 [M].北京:清华大学出版社,2010.]
[9]Ministry of Industry and Information Technology of the People’s Republic of China.Internet network failure briefing of some areas on May 19 [EB/OL]. [2012-03-29].http://www.miit.gov.cn/n11293472/n11293832/n11293907/n11368223/12365340.html (in Chinese).[中华人民共和国工业和信息化部.关于5月19日部分地区互联网网络故障情况通报 [EB/OL].[2012-03-29].http://www.miit.gov.cn/n11293472/n11293832/n11293907/n11368223/12365340.html.]
[10]Baidu Baike.DNSPod [EB/OL].[2012-03-29].http://baike.baidu.com/view/1838299.html,2012/2012-03-29 (in Chinese).[百度百科.DNSPod [EB/OL].[2012-03-29].http://baike.baidu.com/view/1838299.html,2012/2012-03-29.]
猜你喜欢
当代陕西(2020年17期)2020-10-28 08:18:18
铁道通信信号(2020年11期)2020-02-07 01:02:20
人大建设(2018年5期)2018-08-16 07:09:00
计算机与网络(2018年10期)2018-02-15 09:06:37
电信科学(2017年6期)2017-07-01 15:44:57
黑龙江电力(2017年1期)2017-05-17 04:25:16
中国知识产权(2015年9期)2015-05-30 10:48:04
河南科技(2014年15期)2014-02-27 14:12:51
互联网天地(2012年6期)2012-03-24 07:52:48
计算机应用文摘(2011年4期)2011-04-29 00:44:03
