
基于隐含语义分析的音乐检索
2013-09-11 03:20周皓东
计算机工程与设计 2013年6期
周皓东,刘 炜
(江西省科学院 高科技开发中心,江西 南昌330029)
0 引 言
由于音乐形式的多样性和内容的复杂性,普通人很难准确表达出音乐的曲调,但收听曲调类似、相近的音乐却是一般用户都具有的需求。传统基于人工标注风格的音乐检索方式会产生过多的结果而不能找到最接近的音乐,而使用曲谱的查询则只会找到完全相同的曲调,因此对音乐的近似检索一直受到研究者的重视。近年来,基于哼唱等近似音乐检索方法取得了一系列突破,许多研究者在提出了相关的解决方案。基于音乐特征的提取与匹配,陈晓颖[1]等人提出使用音高和音长描述乐曲的方法,并利用平均音高差和平均音长变化率建立 M树索引结构,在一定搜索半径内查找与输入最相似的音乐文件。秦 静[2]等人提出基于动态阈值分割音符并将音高模板归一化的加权综合匹配算法,提高音乐检索的精确性和鲁棒性。李鹏[3]等人采用改进的YIN算法提取基音序列,然后使用 “小阁”基音后处理方法对基音序列的规整化操作,基于旋律轮廓进行音乐的模糊匹配。刘怡与郝云飞[4]对比了各种近似匹配算法的性能,指出音乐哼唱检索系统中基于单侧连续匹配的算法不仅查询速度快,而且查询的准确率较高。基于单侧连续匹配的算法,于琪[5]等人提出一种分层聚类的方法,提取音乐数字特征并进行聚类,在保证音乐检索中查准率同时提高了检索效率。音乐特征除了片断中的音高与音高变化外,还体现在片断间的变化,王小凤[6]等人提出基于单句特征和多句转换相结合的检索方法,获得了良好的检索效果。
从研究成果来看,特征值匹配是现有方法的基础,但现有特征值主要是从数学上对原数据进行精简,音乐中有许多信息正是由被数学上忽略掉的 “冗余”数据表达,因此根据具体音乐分析潜在的相关性远比简单的数字特征匹配有意义。潜在语义分析 (latent semantic analysis,LSA)是一种较好的潜在相关性分析方法,在文本检索中取得了较好的成果。近年来,一些研究者尝试了将LSA引入多媒体数据检索或分类排序,如针对遥感图像中 “同物异谱”和 “同谱异物”的现象,陶超[8]等人提出一种基于潜在语义分析的遥感图像分类排序方法,有效提高了遥感图像分类精度。常军[9]等人对描述视频内容结构的视频文档矩阵进行潜在语义分析,使用可视特征相关性的关系矩阵进行视频检索,改善了视频语义内容检索的效果。王新颖[10]等人提出一个基于潜在语义分析的非线性降维方法并用于三维模型的语义检索,在三维模型的特征降维处理和检索结果方面都取得了较好的效果。为使检索结果更加接近用户意图,本文尝试了基于LSA的音乐检索方法。
本文算法首先建立音乐词典,再将音乐矩阵化表示,最后进行词汇相关性分析,算法总体技术方案如图1所示。

图1 音乐语义检索总体技术方案
图1中,词典建立为矩阵化表示提供基础数据,相关性分析同时使用词典和乐曲矩阵,最后基于语义进行检索。
1 音乐词曲的建立
1.1 曲谱的标准化表示
曲谱是音乐的核心内容,代表了乐曲的曲调,也是大多数人检索音乐的主要依据。无论节奏、音高还是情感,都通过曲谱来表达。然而,传统的曲谱表达虽然主体部分是1-7的数字,但同时也夹杂了其它非数字符号,并不利于计算机表达或数值化分析。为此,首先要对曲谱进行标准化表示,方便程序处理。
曲谱由不同的音符通过不同的方式连接而成,不同音符代表了不同的音高 (mh),音符间的连接则包含了不同的音长 (ml)和音转 (mc)方式,对曲谱的标准化表示主要是对音高 (mh)、音长 (ml)和音转 (mc)进行描述。
对一般音乐来说,共有七个音符,而每个音符又有高、中、低这3个音阶,加上休止符0,共22个,因此可以将音高映射到集合MH= {mh|0≤mh≤21,mh∈Z}。
音长是曲谱中决定一个音符延续时间的因素,理论上一个音符可以延续任意音长,幸运的是,所有音长都是按“拍”来计算,理论上最短的音长为三十二分之一拍,而常见的音符最短为八分音符。由于十六分音符和三十二分音符很少见,忽略它不会影响检索结果,为简化计算,我们将八分音符定为基本音长单位 (mu),而将短于八分之一拍的音符近似为八分音符,于是所有音符长度可以转换为音长单位的整数倍,曲谱中所有音符都可被拆分为单位音符的连接。
对较长音符进行拆分后,同一音符被转化为多们音符的连接,但这种连接与多个相同音符的发音显然不同,另外,不同音符间还存在上弧线的连接和普通连接之分,为区分不同单位音符间的连接方式,为每个单位音符后都附加一个音转方式属性mc∈MC,MC= {c,a,s},其中c代表普通连接,a代表弧线连接,s代表同音延续。于是任意曲谱可以表示为标准音符和音转的交替串:Staff=mu0mc0…munmcn。
1.2 音乐词典建立
理论上,mu、mc对 (以下记为muc)间的排列方式可以有无限多个,实际应用中,曲谱总是按句分段,每段的长度有限,并且排列的方式具有一定的规则,为提高检索效率,先将常用排列方式组合成 “词”。曲谱的词没有固定的长度或显式的表达,需要利用人工智能方法自动提取常用的词汇。提取词汇的目标是找到最常用的muc排列方式,一般来说,单个muc使用频率高于包含它的多muc排列,小的muc排列使用频率高于包含它的大muc排列,由此可以得到以下音乐词汇统计算法。
算法1 (音乐词汇统计算法)
步骤1 将音乐库转换为标准muc排列集MUS,令词汇表容量为V,MUS的总muc数为|MUS|,则规定频率阈值Fthre=V/ (V-|MUS|)。
步骤2 将所有单个muc加入词汇表W,统计各词汇wi在MUS中的出现频率fi,若fi<Fthre,则将wi移除。令迭代数t=1,hasnew=false。
步骤3 对词汇表W 长度为t的词汇,计算它们与长度为1的词汇组合wnew出现的频率fnew,若fnew>=Fthre则令W=W∪ {wnew},hasnew=true。
步骤4 若hasnew=false,转步骤5,否则令t=t+1,转步骤3。
步骤5 在W中选择频率最大的V个词汇作为最终词汇表,结束。
2 乐曲的矩阵化表示
隐含语义分析的关键过程是进行奇异矩阵分解,为此需要首先将各乐曲进行矩阵化表示。乐曲通常都有自然分句,但这些分句长度可能不同,为使各分句能整齐地转化为相同维数的向量,使用最长的分句长度作为标准维数
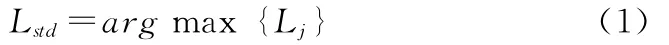
由于词语间存在包含、重叠的情况,各语句存在不同的划分方式,使用每句的最短长度作为语句的参考长度,即
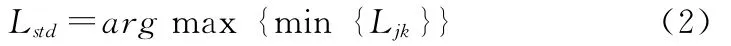
在确定标准维数后,需要对较短的语句进行单词分割(显然,根据算法1产生的单词的分割仍然是单词),我们使用增加频率和的算法进行单词的重新分割,算法如下:
算法2 (乐曲语句再分割方法)
步骤1 令语句现有单词集为Wn,单词数量为|Wn|,对语句中各单词按词典中的频率排序,选择其中频率最小的Lstd-|Wn|个长度大于1的单词作为候选分割集Wdiv,令Wn=Wdiv,i=1。
步骤2 对wi∈Wdiv,令j=|wi|/2,wij为wi中从0到j个muc所组成的单词,wij中从j到|wi|个muc所组成的单词。
步骤3 若fwi(j+1)+fwi(j+1)> fwij+fwij,则令j=j+1,重复步骤3。
步骤4 若fwi(j-1)+fwi(j-1)> fwij+fwij,则令j=j-1,重复步骤4。
步骤5 令Wn=Wn∪ {wij,wij},若i<| Wdiv|,则令i=i+1,转步骤2。
步骤6 若|Wn|<Lstd,则转步骤1,否则结束。
通过算法2将乐曲的各句转化为固定数量的单词序列,再将各单词根据出现频率编号,则语句可以表示为编号组成的向量,乐曲可以表达为语句向量所组成的矩阵。
3 乐曲语义相关性分析
对语义相关性的分析是实现语义检索的关键。当前,对语义相关性的描述方法很多,一般可以分为潜在语义、词网 (WordNet)关系、本体等三类。词网要求检索内容间存在严格的关联规则,音乐内容和乐谱中的关联并不严格,因此词网的方式不适合表达音乐相关性。本体关系要求被描述对象有明确的规范,音乐本身是一种自由的情感表达,并没有严格的规范或要求,因此无法总结出各种音乐的本体,也不容易将本体的概念用于描述音乐的语义。潜在语义分析使用奇异值矩阵描述对象间的关系,并不要求被描述对象有特殊标准或规范。综合对比,本文采用潜在语义分析作为乐曲语义相关性分析的工具。
经过矩阵化表示,乐曲可以通过向量、矩阵的相似性进行检索,但这种检索只能获得表面相近的结果,检索的优劣依赖于向量、矩阵的距离定义。为了使检索结果能体现更多的潜在相关性,我们采用向量空间矩阵来分析和处理,以反映语义特征相关性的关系。
令乐曲表达矩阵K可以进行奇异值分解

对式 (3)两边右乘以V、Is(其中Is为对角矩阵,前s个对角元素为1,其余元素为0):

令需要查询的语句向量为q,则将查询语句与乐曲矩阵相似性定义为

其中,VIs代表了从词语空间到语义空间的映射,KVIs构成了语义空间中的乐曲矩阵;qVIsT构成了语义查询向量。
式 (4)可以进一步整理为

式 (6)中的R既能反映矩阵K的自相关性,又能获得K与q的互相关性,因此通过式 (6)可以得到乐曲的完整相关性,利用这种相关性对乐曲排序,可以产生令用户满意的检索结果。
4 实验结果
为验证算法的有效性和执行效率,我们建立了相关的乐曲库和检索材料进行了实验。从中国曲谱网 (http://www.qupu123.com)下载和识别曲谱20601首建立曲谱库(其中民歌13861首,通俗5359首,美声1381首),识别过程使用区域分割和谷歌OCR包。为对比传统哼唱音乐检索方法,邀请了50人哼唱曲谱库中的歌曲各2首,并人工标注哼唱的预期前10项检索结果。实验中使用三星NP400B2B笔记要电脑,CPU频率2.10GHz,内存4.0G,操作系统为64位 Windows 7。实验对比算法包括 “小阁”基音后处理方 法[3](CPT),单侧 连续匹 配方法[4](OSCM),分层聚类音乐检索方法[5](HCMR),将本文算法称为潜在语义分析检索算法 (LSAR)。
实验测试了算法对音乐检索的结果,分别使用哼唱和原曲进行检索,统计检索结果的命中率、精准度和满意度,其中命中率为检索结果中存在目标乐曲的比例,精准度为检索的前10个结果中存在预期结果数量的比例,满意度为预期结果正确排序的比例,即

其中,对于仅有单个结果的检索算法,将上一次检索结果排除后再进行下一次实验,以获得检索结果集及其排序。测试结果见表1。

表1 检索结果的命中率、精准度和满意度
在表1中,CPT与OSCM的满意度在某些时候超过了LSAR,但由于其精准度较低,故实际满意的结果并不如LSAR。HCMR的精准度在哼唱检索中超过了LSAR,但其命率和满意度均低于LSAR,在实际检索中HCMR满意的结果数目仍然不如LSAR。
对音乐检索来说,检索时间也是需要考虑的因素之一,为验证LSAR的时间有效性,对不同长度的音乐进行了检索时间统计,结果如图2所示。

图2 音乐检索时间对比
图2中统计了几种检索算法对不同长度音乐检索的平均时间,检索时均使用原曲进行检索。
虽然LSAR在检索时间上与其它算法相比并无明显优势,但在给用户带来语义检索的功能同时保证了时间上的性能。
5 结束语
本文将潜在语义分析的方法引入音乐检索问题中,建立了音乐的词汇表、表示矩阵和语义相关性分析方法,总体上获得了良好的检索结果。与现有的方法相比,基于语义的检索方法在进行哼唱检索中可以获得更高的命中率,检索结果中具有更多与人们预期排序相符的乐曲。但需要注意的是在哼唱检索中,由于个人哼唱技术的差异,本文方法并不能获得100%的命中率,这在实际应用中是无法使用户满意的;相应地,哼唱检索时本文算法在检索精准度也低于HCMR算法。要进一步提高音乐检命中率,使检索结果达到用户满意的程度,需要改进对用户哼唱的识别算法和适应方法,作者下一步工作将继续研究哼唱特征的提取和哼唱语义的表达等问题。
[1]CHEN Xiaoying,GAO Feng,LU Ruzhan.New indexing method for content-based music information retrieval and its application [J].Computer Engineering and Applications,2007,43(14):233-235 (in Chinese).[陈晓颖,高峰,陆汝占.一种新型的音乐信息检索索引方法及其应用 [J].计算机工程与应用,2007,43 (14):233-235.]
[2]QIN Jing,ZHOU Mingquan,WANG Xingce,et al.MIR approach based on dynamic thresholds segmentation and weighted synthesis match [J].Computer Engineering,2007,33 (13):194-199 (in Chinese).[秦静,周明全,王醒策,等.基于动态分割和加权综合匹配的音乐检索算法 [J].计算机工程,2007,33 (13):194-199.]
[3]LI Peng,ZHOU Mingquan,XIA Xiaoliang,et al.A music retrieval research and implementation of new methods [J].Journal of Beijing University of Posts and Telecommunications,2010,33 (3):62-66 (in Chinese).[李鹏,周明全,夏小亮,等.音乐检索新方法的研究与实现 [J].北京邮电大学学报,2010,33 (3):62-66.]
[4]LIU Yi,HAO Yunfei.Evaluation of approximate match algorithms in large query by humming music retrieval systems [J].Journal of Hunan University of Science & Technology (Natural Science Edition),2009,24 (1):81-86 (in Chinese).[刘怡,郝云飞.大型音乐哼唱检索系统中的近似匹配算法及性能评测 [J].湖南科技大学学报 (自然科学版),2009,24 (1):81-86.]
[5]YU Qi,JIANG Yongping,XU Du,et al.A kind of application hierarchical clustering in music retrieval [J].Computer Engineering and Applications,2011,47 (30):113-115 (in Chinese).[于琪,蒋永平,徐杜,等.一种分层聚类方法在音乐检索中的应用[J].计算机工程与应用,2011,47 (30):113-115.]
[6]WANG Xiaofeng,GENG Guohua,LIU Xiaoning,et al.Multisentencemusic retrieval algorithm based on relative features[J].Application Research of Computers,2011,28 (3):918-920(in Chinese).[王小凤,耿国华,刘晓宁,等.基于相对特征的音乐哼唱多句检索算法 [J].计算机应用研究,2011,28(3):918-920.]
[7]Park LAF,Ramamohanarao K.An analysis of latent semantic term self-correlation [J].ACM Transactions on Information Systems,2009,27 (2):1-35.
[8]TAO Chao,TAN Yihua,PENG Bifa,et al.A probabilistic latent semantic analysis based classification for high resolution remotely sensed imagery [J].Acta Geodaetica et Cartographica Sinica,2011,40 (2):156-162 (in Chinese).[陶超,谭毅华,彭碧发,等.一种基于概率潜在语义模型的高分辨率遥感影像分类方法 [J].测绘学报,2011,40 (2):156-162.]
[9]CHANG Jun,HU Ruimin,WANG Zhongyuan,et al.A correlation analysis method of latent semantic for semantic-based video retrieval[J].Geomatics and Information Science of Wuhan University,2011,36 (11):1256-1258 (in Chinese).[常军,胡瑞敏,王中元,等.基于隐含语义相关性分析的视频语义检索 [J].武汉大学学报 (信息科学版),2011,36 (11):1256-1258.]
[10]WANG Xinying,LV Tianyang,WANG Shengsheng,et al.3Dmodel retrieval based on latent semantic linear embedding[J].Journal of Chinese Computer Systems,2010,31 (4):761-765 (in Chinese).[王新颖,吕天阳,王生生,等.一种基于潜在语义线性嵌入的三维模型检索方法 [J].中国计算机系统杂志,2010,31 (4):761-765.]
猜你喜欢
河北画报(2021年20期)2021-11-26
艺术品鉴(2021年21期)2021-08-15
智族GQ(2019年7期)2019-08-26
作文大王·低年级(2019年5期)2019-06-13
作文小学中年级(2019年4期)2019-04-25
中国工人(2017年2期)2017-03-10
幸福(2016年6期)2016-12-01
语文世界(初中版)(2015年9期)2015-11-18
今日中学生(初一版)(2013年8期)2013-08-19
琴童(2009年6期)2009-06-18
