
数字图书馆个性化推荐系统研究与设计*
2013-09-07 09:32:12王秀玮刘旭东
潍坊学院学报 2013年2期
王秀玮,刘旭东
(烟台职业学院,山东 烟台 264670)
随着计算机网络技术以及数据库技术的不断进步,网络上资源的丰富性以及复杂性明显提高,数据类型显得更加复杂多样,当前已经产生了海量的数据资源,以往的数据库系统技术在对网络信息资源进行处理的过程中显得力不从心,迫切需要全新的系统技术处理、维护资源,在这样的背景下,个性化服务在当前数字图书馆的应用过程中越来越受到重视,作为个性化服务的核心价值所在,个性推荐系统在常见情况下会先建立用户模型,对使用者可能感兴趣的信息进行预测,从数字图书馆中自动寻找网络、数据资源推荐给使用者。
1 个性化推荐系统的核心技术分析
1.1 信息资源的检索以及抽取
为配合用户的搜索请求,系统返回对应的信息查询结果的关键信息技术被称之为信息检索,检索的结果多是从资源的相似度出发进行排序,当前常见的流行搜索引擎主要包括Google、百度、yahoo等,这一技术利用的是关键词检索法,但是其搜索的整体正确率水平不高,必须进行人工判断,而信息检索应用系统回答的知识使用者咨询的问题,其为非个性化、较常见的信息服务。
从使用者抽取信息相关要求出发,利用特定信息模板对信息进行自动识别、抽取的技术被称之为信息抽取。主要内容是对实体信息、实践信息、实体信息间的联系等的抽取,能对使用者需要获得的信息进行准确抽取,但是由于以往模板只是反映了部分领域的信息,因此信息抽取在特定的领域才能发挥作用。因此将信息检索与信息抽取两项技术进行结合,克服各自领域的局限性,是提升个性化推荐系统的关键技术之一。
1.2 知识和数据发掘技术
知识发掘主要是从数据信息中发现有用知识的过程,数据发现指知识发现的特定步骤,数据是知识发掘的核心技术,数据与知识的发现在推荐系统中主要是作为同义词进行操作,常见的是利用分析、OLAP分析、关联性分析等算法智能抽取信息源信息,对数据信息的关联性做出智能处理,对数据的隐藏关系,运用方程、科学定律、法则等方式方法对知识进行抽取。数字挖掘主要利用的是特征型、广义型或者预测型知识,其主要是对有用的知识点进行提取,用固定的手段方式对知识特性聚集做出表示。这些知识点主要用于信息管理、科研、智能支持等多个方面。在商业领域已经成功应用了知识和数据的发掘技术,当前实现数字资源的知识挖掘,并对其提供有效的信息数据服务,这也成为了当前数字图书馆个性服务的重要发展趋势。
2 数字图书馆个性化推荐系统设计
2.1 个性化推荐系统框架设计
个性化推荐系统主要包含了4个方面的内容,推荐策略部分、用户感兴趣信息部分、用户的反馈和评价部分、数据信息偏好部分。主要的设计框架如图1所示。

图1 个性化推荐系统框架
在构建数字个性推荐系统过程中,必须掌握使用者的对象特点以及信息源特点。当前数字图书馆、电子商务或者网络供应商主要利用推荐系统进行工作,在数字化图书馆中,信息服务相对应的对象未对声像等较为复杂的进行推荐,仅推荐文本信息,另外数字图书馆自身含有知识分类框架,这主要的原因在于数字图书馆推荐的是一般的文献数据。数字图书馆推荐系统中的使用者从信息查询偏好、实际年龄、文化程度或者教育层次都存在较大差别,而论文设计系统框是对较为稳定的学历层次以及文化背景用户群体而言,须根据使用者涉及范围较广这一特殊现象进行分析研究。
2.2 数字图书馆个性化推荐系统建模技术的应用
用户偏好建模在个性化系统中主要是对使用者提取的信息要求持续到信息注销时间段内,对使用者信息需求的整体描述,内容包括了动态更新、用户偏好精确性确定等。主要做法在于用三元组Q对用户喜好模型进行描述,Q=(A,R,Y),在这一三元组中:
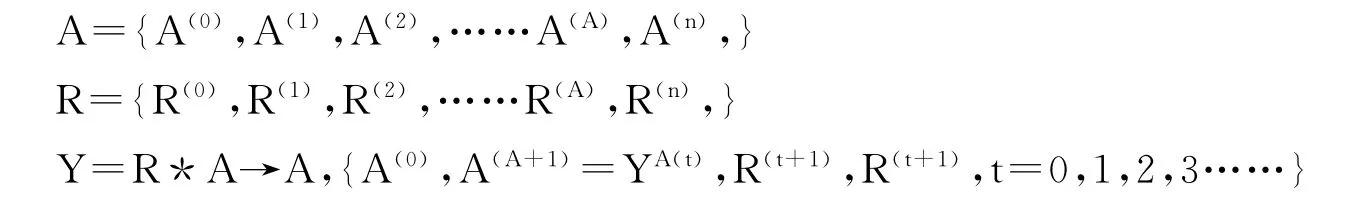
R的内涵是个性化推荐系统中为用户喜好模型集合而成的信息反馈集,主要是进行驱动更新,A的内涵是个性化推荐系统中为用户喜好模型集合而成的全部状态数据集,Y的内涵是用户喜好模型的函数。用户模型的原始状态用A(0)表示,经过t次更新的模型用A(t)表示,推荐系统的t次反馈信息更新用R(t)表示,从以上公式可以看出,用户的喜好模式始终是在不断变化的,能及时更新和反应使用者的喜好性或者可能感兴趣的信息内容。
从数字图书馆特有的使用者群体具备的特点出发,论文也对使用者的短期偏好或者长期偏好进行了综合分析和研究,大致将使用者提供的示范性文本文档信息以及使用者查询记录归类为短期喜好,将对象的受教育程度、年龄层次等作为参考对长期喜好进行归类。
在对使用对象的喜好性进行分析时,制定出了对象偏好模型As(1-ɑ)+ɑAl:在这一模型中,短期喜好用向量用As表示,长期喜好的向量用Al表示,ɑ是为(0至1)之间参数值,对短期、长期的喜好程度进行调整。特别针对于使用对象在长期喜好方面的设计,可以运用规则法对对象的喜好特性进行分析,这一规则可以用特定的语言进行表述,例如,针对于教育程度不同、年龄阶段不同性格有所差异的群体而言具有各自不同的数据信息需求,专业人士比非专业人士需要的数据信息的专业程度更高。
2.3 数据挖掘算法构建用户兴趣
2.3.1 主动构建方式
使用对象先对数据库的本地资源进行查询,反馈查询结果文献,利用用户的喜好模型对算法进行更新,推荐系统自动创建出兴趣模型,使用者利用获得反馈的文献确定图法分类号,事实上,信息挖掘中挖掘频繁项的行为,可将一个分类号与一个事务进行对应,保证分类号的有序性,频繁项同样保持已有的顺序性,作为实际的分类号存在。
2.3.2 手动构建方式
使用对象将最为初始的喜好类别进行分类,相同的使用对象可以进行多个喜好的注册,一旦使用对象喜好存在互相折叠现象,则选择相同兴趣项作为喜好列别。在确定了使用对象的分类号之后,则可列出分类号对应的不同的主题词,从确定的主题词中获取使用对象的喜好特征。在使用对象的本地的信息库中如果含有对象曾经的论文文献,则推荐系统快速将相关的关键词提供给使用者以便使用对象进行选择。
3 结束语
在网络技术不断发展的前提下,人们能够利用丰富的搜索手段、网络资源快速获取信息和文献资料,因此,从用户需求出发,建立个性化信息检索推荐系统成为当前发展的新方向。在设计和实现数字图书馆个性化服务系统中,需要解决的重要问题在于建立起个性化的用户喜好模型。怎样准确表达使用对象的喜好成为个性服务系统的重点、难点问题之一,当前需要从不同的应用需求入手,仔细分析设计推荐系统中各个细节环节,加强适用对象喜好模型的设计,研究优化推荐算法,加强数据信息的处理和个性化表述。
[1]姚星星,屈鹏,谢静.国内外数字图书馆研究与发展现状[J].图书情报工作,2009,53(13)24-29.
[2]刘建国,周涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1):1-15.
[3]马丽华.高校图书馆个性化信息服务的定制模式[J].科技情报开发与经济,2006,16(20):25-27.
[4]田晓珍,尚冬娟.Web的个性化服务[J].重庆工学院学报:自然科学版,2008,22(7):76-95.
[5]庞秀丽,冯玉强,姜维.电子商务个性化文档推荐技术研究[J].中国管理科学,2008,(16):581-586.
猜你喜欢
小火炬·阅读作文(2023年5期)2023-03-02 12:44:57
睿士(2023年2期)2023-03-02 02:01:09
文苑(2020年4期)2020-05-30 12:35:12
新闻传播(2018年12期)2018-09-19 06:27:10
好日子(2018年5期)2018-05-30 16:24:04
意林(2018年3期)2018-03-02 15:17:24
汽车与新动力(2016年6期)2017-01-04 10:50:48
厦门理工学院学报(2016年1期)2016-12-01 04:50:48
中国新闻周刊(2016年33期)2016-10-27 17:58:47
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:48
