
一种基于MFCC与韵律特征的说话人确认方法
2013-09-04 02:04骆启帆章坚武吴震东
杭州电子科技大学学报(自然科学版) 2013年5期
骆启帆,章坚武,吴震东
(杭州电子科技大学通信工程学院,浙江杭州310018)
0 引言
说话人确认系统目前的主流系统为基于通用背景模型(Universal Background Model,UBM)与高斯混合模型(Gaussain Mixture Models,GMM)的系统,其中UBM通过期望最大化算法得到,而高斯混合模型则是在UBM的基础上自适应的选择最大概率的几个混合数并进一步计算得到[1,2]。常用特征参数中,从人耳角度描述短时声道信息的梅尔倒谱系数(Mel Frequency Cepstral Coefficient,MFCC)相对于基于线性预测理论的线性预测倒谱系数(Linear Prediction Cepstrum Coefficient,LPCC)有着更好的识别性能。然而后续研究者在对MFCC进行了不断研究与优化后[3,4],MFCC的性能进入了一个瓶颈。研究人员开始开发其他特征,如基频,能量等。但这些特征往往有着注册语音长,性能不如MFCC等缺点。由于这些韵律特征表征的是声门信息,它们与表征声道的MFCC有着良好的互补性。此外,特征之间的融合也进入了研究者的视线。人们提出将不同的特征加以融合,如将MFCC与能量信息等其它特征直接线性拼接为一个特征,并在拼接的基础上进行降维[5]。本文研究了韵律特征参数与MFCC的原理及其提取方法,并在此基础上提出采用二次判决的方法融合MFCC与韵律特征参数。通过实验,验证了该方法的有效性。
1 MFCC参数提取
MFCC作为最常用的特征参数,从人耳对频率的非线性感知角度描述了声道变化特性,作为一种短时特征,比其他类似的短时特征有着明显的优势。
简单的来说,MFCC就是在频率域采用一组基于Mel频率的三角带通滤波器来模拟人耳对声音的感知。其提取流程图如图1所示。Mel频率与线性频率的转化关系为:


图1 MFCC提取流程图
MFCC提取的主要步骤如下:
(1)语音信号的预处理,包括预加重,分帧,加窗;
(2)对上一步得到的每帧信号进行FFT,获得频域幅度谱;
(3)对每帧信号的频域幅度谱取平方获得功率谱;
(4)将功率谱通过基于Mel频率的三角带通滤波器组,该组三角带通滤波器的中心频率在Mel频率域呈均匀分布。三角带通滤波器组的传递函数为:
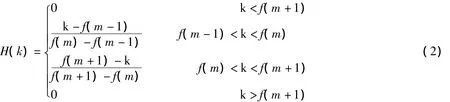
式中,f(m)为带通滤波器组中第 m个滤波器的中心频率,其公式为其中,fmel(fh),fmel(fl)分别为最高频率,最低频率在Mel频率上的对应值,N为FFT长度,M为Mel三角滤波器组中滤波器个数。其中
(5)对每个带通滤波器的结果取对数,得到对数功率谱参数;
(6)对上一步得到的对数功率谱参数进行DCT变换,即得到MFCC特征参数。
2 韵律特征提取
浊音信号是一个准周期信号,即时域波形如图2所示,呈准周期性,该周期的倒数即为基音频率。研究表明,人的基音频率处在50 450Hz之间。
基音周期的获取方法有许多,包括短时自相关函数法,平均幅度差法等,各有其优点与缺陷。在这里,采用短时自相关函数法计算。短时自相关函数的公式如下:

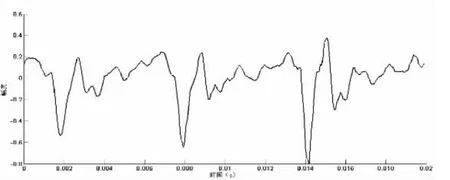
图2 浊音信号时域波形图
式中,s(n)为语音帧,N为该帧的长度。
基音周期获取具体算法如下:
(1)首先进行预加重,分帧,并计算每一帧的短时能量E与整段语音的平均能量,将小于平均能量百分之一的帧作为静音帧去除;
(2)采用中心削波法对语音信号进行削波。削波函数为:

式中,T为削波电平,一般取本帧语音幅度最大值的60% 70%,本实验中取60%。削波后的时域波形如图3所示;
(3)计算削波后的信号短时自相关函数,计算得到的自相关如图4所示。对自相关函数结果取峰值并记为R0,并将峰值附近赋值为0。若R0过小则记R0为0;
(4)再次取峰值,记为R1,同时对R1进行判断,若R1过小或过大均置为0;
(5)将|R1-R0|作为基音周期,采用5点平滑算法对得到的基音周期进行平滑,并将周期不在基音范围内的语音帧作为清音帧删除;
(6)参考采样频率计算基音周期,并取其倒数作为基音频率;
(7)取剩余帧中基音频率的对数与能量E的对数,将这两者拼接起来作为韵律特征。

图3 中心削波后的信号
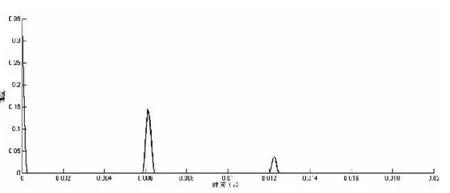
图4 削波后的自相关函数
3 线性融合
说话人确认是一个闭集问题,即判断给定的测试语音是:H1是由申明说话人发出;H2不是由申明说话人发出。其大致流程图为:

图5 普通判决流程图
在说话人确认中通常采用对数似然比得分来代替概率,判决式为:
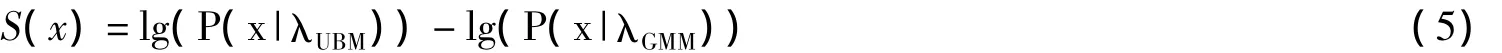
式中,x为特征矢量,λUBM为UBM参数,λGMM为申明说话人的参数;当S(x)小于给定门限γ时,判决语音由申明说话人发出,否则语音不是由该说话人发出。
为将MFCC与韵律特征结合的更好,本文提出,可以采用先对语音信号进行MFCC特征的判决。当差值在某个门限内时,记录下该段语音,并跳过MFCC对该段语音的判决。其后对在前一个阶段被记录下的语音采用对数基频及对数能量进行二次判决。
在对MFCC实验的过程中,发现等错误率的门限一般在2 3003500这个区间内,换句话说,对于得分在这段区间附近的语音而言,MFCC已不能很好地分辨是否由说话人发出的。基于以上考虑,将参考门限设定为3 000 4 000,即得分在该区间内的语音被判为MFCC无法正确判决的语音,采用基于韵律特征的方法对其进一步判决。
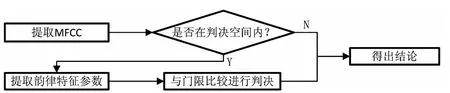
图6 线性判决流程图
4 实验仿真及结果分析
本实验采用语音库:语音库1为源于网络的23人语音库,在本次实验中用于通用背景模型的训练;语音库2为实验室采集的36人语音库,每人采集10句中文语音,说话内容从朗读到随意讲述不限,平均每句语音长约10s,在本次实验中用于训练个人的GMM与测试实验结果。语音库1、2采样频率同为16k。
实验对比了只采用MFCC与采用二次判决两种方法时的系统性能。在本次测试中,语音帧帧长设置为0.02s,帧移为0.01s,实验中加窗采用汉明窗。UBM的训练采用语音库1中语音,总长约20min,混合数为64;个人GMM训练时,每人采用3段语音进行训练,混合数为5;测试时每人均采用剩余7段语音用于测试。韵律特征部分中语音帧帧长,帧移,加窗和UBM混合数等参数与MFCC部分一致。判决时,先对MFCC部分得分进行计算,当得分在2 000-4 000内时,记录下该段语音的标号,否则给出判决结果;MFCC部分判决结束后,启动韵律特征部分对被记录下标号的语音进行二次判决,该判决结果即为最终判决结果。
实验判决结果如表1所示。从表1中可以看出,使用本文提出的二次判决融合特征方法使系统的等错误率明显下降,充分表明了本文提出的融合方法的有效性。另外,经实验发现,采用MFCC模型时,得分在二次判决得分空间范围内的语音数不足7.5%,这从侧面证明了MFCC的良好性能。在最后一次实验中,进入二次判决空间的语音为676条,但是在等错误门限处判断错误数(包括虚警与漏报)为413条,这表明韵律特征虽然在本系统中作为辅助性特征,使话者识别性能有较大提高,但其单独作为一个特征参数仍显不足。
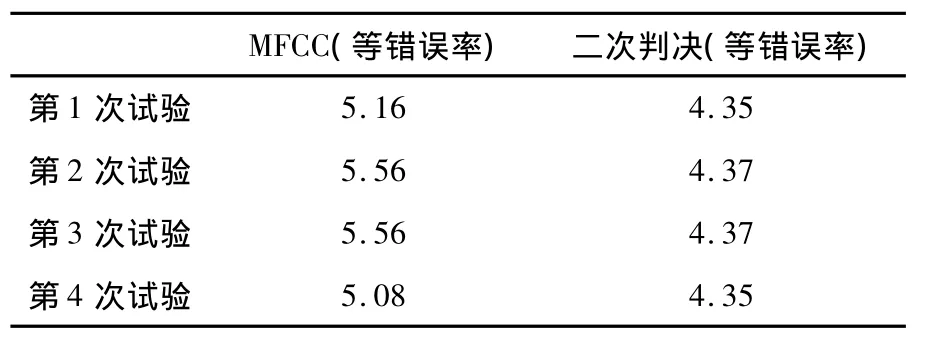
表1 实验判决结果(%)
5 结束语
本文介绍了一种融合了MFCC与韵律特征的说话人确认方法。该方法充分利用了两种不同角度特征的互补性。实验结果表明,该新方法提高了话者识别系统的性能。
[1]Reynolds D A,Quatieri T F,Dunn R B.Speaker verification using adapted Gaussian mixture models[J].Digital signal processing,2000,10(1):19 -41.
[2]Reynolds D A,Rose R C.Robust text-independent speaker identification using Gaussian mixture speaker models[J].IEEE Trans on Speech Audio Process,1995,3(1):72 -83.
[3]甄斌,吴玺宏,刘志敏,等.语音识别和说话人识别中各倒谱分量的相对重要性[J].北京大学学报(自然科学版),2001,37(3):371 -378.
[4]陆伟,戴蓓蓓,李辉,等.MFCC中的基音频率信息对说话人识别系统性能的影响[J].中国科学技术大学学报,2009,39(8):859 -860.
[5]汪峥,连翰,王建军.说话人识别中特征参数提取的一种新方法[J].复旦学报(自然科学版),2005,44(1):197-200.
猜你喜欢
中国特种设备安全(2021年5期)2021-11-06
装备制造技术(2021年4期)2021-08-05
中华诗词(2019年1期)2019-08-23
福建基础教育研究(2019年11期)2019-05-28
成都信息工程大学学报(2019年1期)2019-05-20
乡村地理(2018年4期)2018-03-23
制造技术与机床(2017年11期)2017-12-18
新疆师范大学学报(自然科学版)(2016年2期)2016-07-31
新疆大学学报(哲学社会科学版)(2015年5期)2015-10-12
电测与仪表(2015年7期)2015-04-09
