
Kinect深度信息的研究及其在检测中的应用
2013-09-04 02:04黄鑫材
杭州电子科技大学学报(自然科学版) 2013年5期
魏 琳,黄鑫材
(浙江工业大学省信号处理重点实验室,浙江杭州310023)
0 引言
当前目标的检测与跟踪主要集中在基于RGB光学图像的处理上,依据颜色空间、边缘、纹理结构分析或者灰度特征、运动特征来实现[1]。但由于RGB图像无法获得物体的距离信息,相关的算法会受到光照、阴影、遮挡等因素的影响,难以实现复杂场景下的任意目标检测与跟踪。因此,深度图像为检测和跟踪开启了新的思路,通过引入TOF、Kinect、立体视觉等技术来恢复场景中的深度信息,将目标与背景分离,提高了目标检测与跟踪的准确率和鲁棒性[2]。微软公司的Kinect体感设备可以廉价而有效地捕捉到深度图像,这也是它创下史上销售最快电子消费产品吉尼斯纪录的最主要原因。本文首先研究了Kinect获取深度图像的原理,之后分析了深度图像的分割优势,最后设计实现了复杂背景下目标的快速检测与分割。
1 Kinect获取深度图像的原理
Kinect是微软开发的一款3D体感游戏的自然交互外设,主要用来实现体感游戏中人体的动作捕捉和识别。它集成了诸多先进视觉技术,可以同时捕捉彩色影像、深度图像和声音信号,在学术和游戏业界均享有很高的关注度。深度数据是Kinect的精髓,PrimeSense公司将其深度测量技术命名为光编码[3],属于结构光测量技术的一种。其采用的光源是激光照射到不均匀介质上形成的随机衍射斑点,即激光散斑,它具有随机性,随着距离的不同呈现不同的图案。在空间中打上这样的结构光,相当于对整个空间做了标记,通过物体表面的散斑图案即可获得物体的位置信息。
Kinect深度成像系统的3个核心元件是:激光发射器、不均匀透明介质和CMOS感光器件,构造如图1所示。激光发射器发射的光透过不均匀介质发生散射,之后经分束器反射到目标区域,在目标区域形成激光散斑。CMOS感光元件可以捕捉到映射到物体A上的散斑图案并使其聚集到由探测元件阵列组成的图像传感器上。
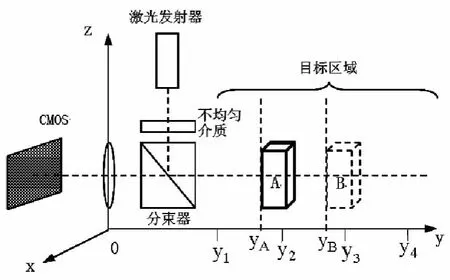
图1 Kinect深度成像系统构造图

图2 光编码技术的成像流程图
光编码技术成像流程图如图2所示,PrimeSense的专利[3]中把它分为4步:标定、取样、定位和重建。首先,在目标区域每隔一段距离,取一个参考平面,CMOS感光元件把参考平面上的散斑图案记录下来。图1中参考平面的位置分别记为y1,y2,y3,y4。此处间距越小,精度就会越高。进行测量的时候,拍摄一幅待测物体的散斑图像,称其为测试图像,物体A和B表面形成散斑的位置分别是yA,yB。之后将测试图像与保存下来的参考图依次做互相关运算,得到相关图像,选取最大的互相关系数,认为其对应的参考图像所标定的位置即为物体的位置,认为物体A,B的位置分别为y2,y3。最后,对相关图像上的峰值(即空间中物体存在的位置)进行峰值叠加运算,再经过插值运算就能构建出此刻场景的3D图像。对距离数据归一化,转换为图像灰度值,即可将带有深度信息的图像输出给外部设备。之后返回执行物体上的散斑测试图案的采集,可以得到连续的深度图像视频流。
2 深度图像的分割
2.1 深度图像的性质分析
深度图像与二维光学图像不同,深度图像中的象素值代表着深度信息,即三维坐标系下各个坐标值的信息。理想的深度图像外观示意图[4]如图3所示。图3中,上方是立体结构的可见光图,下方是其深度图像,不难发现物体的深度图像不受光照、阴影、色彩和纹理的影响,只与距离有关。结合第一节所述的Kinect成像原理,可以得到深度图像具有以下性质:(1)颜色无关性;(2)灰度值变化方向与相机所拍摄的视场方向y方向相同。
第一个性质表明深度图像相比于二维图像应对环境的变化更具鲁棒性,这也解释了为何Kinect可以不受玩家体型、身高、肤色、着装等因素的限制,实现对不同玩家的完美识别。第二个性质表明,利用深度图像的距离数据,即灰度值的分层性,可以在一定程度上解决物体遮挡或重叠的问题,这是可见光图像无法完成的。此外,在有关学者联合发表的重要论文[5]中,通过单帧深度图像有效地实现人体姿势估计与实时的人体姿势部分识别,该文使用了几个简单的特征参数即描述出了深度信息,且这些特征参数不需预处理、运算量小、扩展性强并可直接在GPU上实现。这也体现了深度数据的处理具有高效性。
2.2 深度图像的阈值分割优势
图像分割是指将图像中某个特定区域与其它部分进行分离并提取出来的处理,是图像处理和机器视觉的基本问题之一。目前的图像分割方法大致分为3大类:阈值化、基于边缘的分割和基于区域的分割[6]。阈值化是最简单的分割处理,计算代价小速度快,特别适合于目标与背景占据不同灰度级范围的图像。深度图像的灰度值具有分层性,所以使用阈值分割可以快速地区分图像中的前景目标和背景。
深度图像的分割优势仿真分析如图4所示。截取Kinect同时获取的一帧深度图像和光学图像如图4(a)、(g)所示。观察图4(a)可以发现Kinect获取的深度图像是不稳定的,特别在目标边缘处存在很多空洞与噪声点,直接对其处理会影响算法的准确性。本文采用了中值滤波算法对其进行预处理,因为相比于传统的线性滤波算法和低通滤波算法,中值滤波即可以有效地去除场景中的孤立噪声点又能保留目标边缘信息,滤波后深度图像如图4(b)所示。接下来用matlab对图4(b)、(g)分别进行简单的仿真分析,对比两幅图像的深度直方图和单阈值分割结果如图4(d)、(i),深度图像的分割优势一目了然。

图3 理想深度图像示意图
分析到深度图像具有分层性,这也可以从其深度直方图4(c)中看出。深度场景中目标的深度是离散分布的,可把场景看作是背景叠加了多个前景目标,因此不同的目标出现遮挡时,深度直方图中各目标深度处会出现波峰。但由于每个目标内深度差异较小,采用波峰分割会造成目标分割不完整,故本文采用波谷分割,把相邻两波谷间的深度范围视为同个目标,图4(b)经过多阈值分割得到图4(f),如图所示不同的颜色代表着不同的距离。深度图像的单阈值分割就可以提取出目标区域,这与传统的图像检测需要多帧差分运算相比,大大提高了检测速度和效率。利用图4(d)作为同时捕获到的图4(g)的掩膜即可得到图4(e),实现了传统图像检测中的目标提取,改变图4(e)的背景如图4(j),表明结合深度信息可以实现快速地检测出前景目标并把它分割出来。

图4 深度图像的分割优势仿真分析
3 结合深度信息进行目标检测的OpenCV实现
硬件配置:Kinect X360(有独立电源适配器)一台;无线上网本一台(处理器型号:Intel Atom N270;处理器主频:1.6GHz;内存容量:1GB DDR2)。
软件环境:操作系统Ubuntu 12.04;编译环境 CodeBlocks 10.05;计算机视觉库 OpenCV 2.4.5。首先在上网本上安装配置OpenNI、SenserKinect和NITE软件包驱动Kinect,之后配置OpenCV与Code-Blocks开发环境,使得在开发环境下可以使用Kinect获得的深度图像和RGB图像数据,并可以在编译环境中调用OpenCV库函数。
结合深度信息的分割优势,可以避免传统目标检测中对二维图像的全局搜索。由于深度图像反映了场景的距离信息,因此可以先对场景进行层分,提取可能的前景目标,再对目标进行定位与分割,最后与RGB图像进行匹配输出检测结果,框架设计如图5所示。

图5 结合深度信息的快速目标检测框架
根据设计框架,首先对获得的深度图像进行中值滤波去噪处理,利用阈值分割把深度场景分层,定位分割出所需目标,之后与同时获得的RGB图像进行匹配(Kinect获取的深度图像与RGB图像大小并不相同,但OpenNI提供了两图的匹配方法),即可分割出RGB图像中的待检目标区域。这种方法与传统目标检测相比简单快速,因其运用了深度图像的分割优势,锁定了目标搜索区域。实现检测的过程中没有用到复杂的运算,中值滤波、阈值分割均可调用OpenCV库函数,检测结果如图6所示。图6(a)为截取的一帧Kinect获得的彩色图像,图6(b)-(e)为不同时刻选取人体为检测目标的输出结果。Kinect获取深度图像和GRB图像均为30帧/s,输出结果可以做到与Kinect输出的图像数据流同步,即该方法可以有效实现复杂场景下的目标检测与分割,且时间复杂度很低。另外此实验是在配置较低的上网本上实现的,这说明该系统对硬件的配置要求不高,实现成本较低。

图6 复杂场景下的快速目标检测与分割
4 结束语
本文首先研究了Kinect深度成像技术,之后结合其成像原理分析了深度图像的性质,利用matlab仿真讨论了其在分割方面的优势,最后结合OpenCV在Ubuntu系统下设计实现了结合深度信息的快速目标检测和分割。此设计框架具有通用性,更换局部目标检测阈值便可分割不同的目标,并且此方法简单快速对硬件配置要求不高,具有较好的实用价值。
[1]Joshi K A,Thakore D G.A Survey on Moving Object Detection and Tracking in Video Surveillance System[J].International Journal of Soft Computing and Engineering,2012,2(3):2 231 - 2 307.
[2]Xia L,Chen C C,Aggarwal J K.Human detection using depth information by Kinect[C].Colorado Springs:IEEE Computer Society Press,2011:15 -22.
[3]Garcia J,Zalevsky Z.Range mapping using speckle decorrelation:U.S.Patent 7,433,024[P].2008 -10 -07.
[4]Wikipedia entry.Depth map[EB/OL].http://en.wikipedia.org/wiki/Depth_map,2012 -02 -13.
[5]Shotton J,Sharp T,Kipman A,etal.Real-time human pose recognition in parts from single depth images[J].Communications of the ACM,2013,56(1):116 -124.
[6]Sonka M,Hlavac V,Boyle R.艾海舟译.图像处理、分析与机器视觉(第三版)[M].北京:清华大学出版社,2011:124-172.
猜你喜欢
上海电机学院学报(2021年5期)2021-02-11
数字通信世界(2021年2期)2021-01-13
中学生数理化·高一版(2020年1期)2020-02-20
制造技术与机床(2019年9期)2019-09-10
西南交通大学学报(2018年6期)2018-12-18
中学生数理化·八年级物理人教版(2018年10期)2018-12-06
雷达学报(2017年3期)2018-01-19
河北遥感(2017年2期)2017-08-07
衡阳师范学院学报(2016年3期)2016-07-10
华东理工大学学报(自然科学版)(2015年3期)2015-11-07
