
基于云计算的医学图像检索系统
2013-08-30 10:00:28徐胜才
计算机工程与应用 2013年21期
范 敏,徐胜才
FAN Min1,XU Shengcai2
1.杭州职业技术学院,杭州 310018
2.同济大学 电子与信息工程系,上海 201815
1.Hangzhou Vocational and Technical College,Hangzhou 310018,China
2.Department of Electronic Engineering,Tongji University,Shanghai 201815,China
1 引言
随着数字化影像技术发展,大量的医学图像随之产生,这些海量医学图像数据可以为临床诊断提供服务[1]。如何对这些医学图像进行有效管理和组织是医学工作者面对的难题,基于关键字的传统图像检索技术存在主观性较强、不能准确反映图像信息等缺陷,而基于内容的医学图像检索(Content-based Medical Image Retrieval,CBMIR)在该种背景下发展起来,在医学教学、辅助医学诊断、医学资料管理等领域得到了广泛应用[2]。
医学图像检索是一个典型的数据密集型计算过程,对于海量医学图像,基于B/S的医学图像检索系统难以满足图像的实时性要求[3-4]。具有分布式、并行处理能力云计算(cloud computing)可以将大型任务进行分解子任务,然后将子任务分配到各个工作节点共同完成任务,为医学图像检索提供了一种新思路[5]。云计算模型得到许多公司支持,如:Google、Amazon、Yahoo!等,在不了解底层细节的情况下,利用Map/Reduce函数轻松地实现并行计算,在大规模文本分类、专利图像分类等领域得到了广泛的应用[6-8]。云计算具有的优点可以较好地解决医学图像检索过程中的难题,而且目前国内还没有相关研究[9]。
为了提高医学图像检索效率,提出一种基于云计算的医学图像检索系统。首先采用Brushlet变换和LBP算法提取医学示例图像的频域和空域特征,然后采用Map函数将其与医学图像特征库中的特征进行匹配,并采用Reduce函数对Map任务的匹配结果进行收集和排序,最后根据排序结果找到医学图像的最优检索结果,并进行性能测试与分析。
2 云计算概述
云计算的Hadoop是一个使用Java的支持开发和并行处理大规模数据的分布式计算开源框架,主要由分布式文件系统(HDFS)和MapReduce并行计算模型组成。进行Hadoop开发时,可以将分布式并行程序运行于由大量节点所组成的大规模集群系统上完成海量数据的计算,而不用操心并行编程中的工作调度、分布式存储、容错处理、网络通信和负载平衡等问题[10]。
2.1 HDFS
HDFS采用master/slave架构,一个HDFS集群是由一个NameNode和一组DataNode组成,NameNode是一个中心节点,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中一般是一个节点上运行一个DataNode,负责管理它所在节点上的数据存储,并负责处理文件系统客户端的读写请求,在NameNode统一调度下进行数据块的创建、删除和复制[11]。HDFS把文件切割成块(block),这些block分散地存储于不同的DataNode上,每个block还可以复制数份存储于不同的DataNode上,因此具有较高的容错性和对数据读写的高吞吐率。
2.2 Map Reduce
MapReduce是一种处理海量数据的并行编程模型和计算框架,用于大规模数据的并行计算,其采用一种“分而治之”的思想,把大的任务分解成若干个较小的任务分发给各个节点来执行,再将各个节点的执行结果进行汇总,从而得到最终的结果。这种处理过程分为Map过程和Reduce两个阶段[12]。
在Map(映射)阶段,MapReduce框架将任务的输入数据先分割成若干固定大小的块(Split),对Split又分解成一批键值对(Key1,Value1)传给Map函数;每个节点的Map函数对每组键值对进行处理后,形成新的键值对(Key2,Value2),并按照Key2值相同的进行汇总,形成(Key2,list(Value2)),传给Reduce作为Reduce的输入。一般来说,Map会将Key2值相同的键值对传给相同的节点来进行Reduce阶段的处理。
在Reduce阶段,Map输出的(Key2,list(Value2))成为Reduce阶段的输入,对于输入作相应处理后会得到键值对(Key3,Value3),根据用户需要输出到HDFS或者HBase数据库等指定的位置。
为使得MapReduce的数据处理流程更加形象,MapReduce模型的计算流程如图1所示。

图1 MapReduce数据处理流程
3 云计算的医学图像检索
3.1 提取Brushlet域特征
Brushlets变换可以有效地分析富含方向信息的纹理图像,其具有类似于小波包的多层结构,可以对Fourier域进行极佳的分解[13]。Brushlets一层分解把Fourier平面分成4个象限,分解后的系数由4个子带组成,对应的方向为π/4+kπ/2,k=0,1,2,3,那么Brushlets两层分解把每个象限进一步分为4个部分,共12个方向,分别为 π/12+kπ/6,k=0,1,…,11,分解后的系数由16个子带构成,其中环绕着中心的4个子带为低频纹理分量,其余的为高频纹理。Brushlets多层分解是对上一层继续加以细分,但如果层数过多就会出现明显的频谱混叠现象,故而一般采用1~3层分解,3层分解如图2所示。

图2 Brushlet三层分解方向
令∧f表示Brushlet分解后的系数,而实部和虚部的第带模值的均值 μn和标准差σn分别为:

其中i=1,2,…,M ,j=1,2,…,N,M 和 N 是每个子带的行数和列数,图像最终的特征为:

3.2 提取LBP特征
LBP可以刻画领域内像素点的灰度相对于中心点的变化情况,注重像素灰度的变化,符合人类视觉对图像纹理的感知特点[14-15]。因此对图像提取LBPu23,并将直方图作为图像的空域特征。
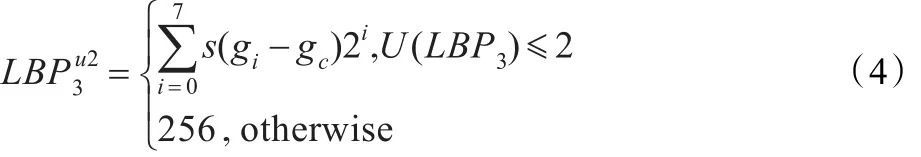
其中,

式中,gc为一个邻域中心像素点的灰度值,gi是以gc为中心3×3邻域顺时针各像素点的灰度值。
3.3 相似度匹配
对Brushlet域特征相似性采用平均距离度量:

其中,P为待检索医学图像,Q为医学图像库的图像。
对于图像LBP特征,首先对特征进行归一化处理,然后采用欧式距离计算相似度。
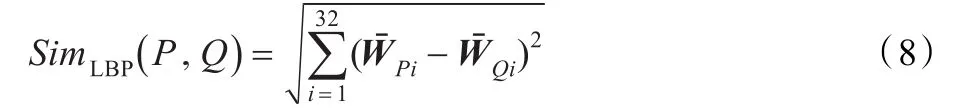
式中,Wˉ为归一化后特征矢量。
由于SimBrushlet和SimLBP取值范围不同,对它们进行“外部归一化”处理,具体为:

两幅医学图像间的距离为:

式中,w1和w2为权重,并且满足w1+w2=1。
3.4 医学图像检索步骤
医学图像及其特征均存储于HBase中,当HBase的数据集非常大时,扫描搜索整个表要花费比较长的时间。为了减少检索图像的时间和提高检索效率,利用MapReduce计算模型对医学图像检索进行并行计算,具体框架如图3所示。
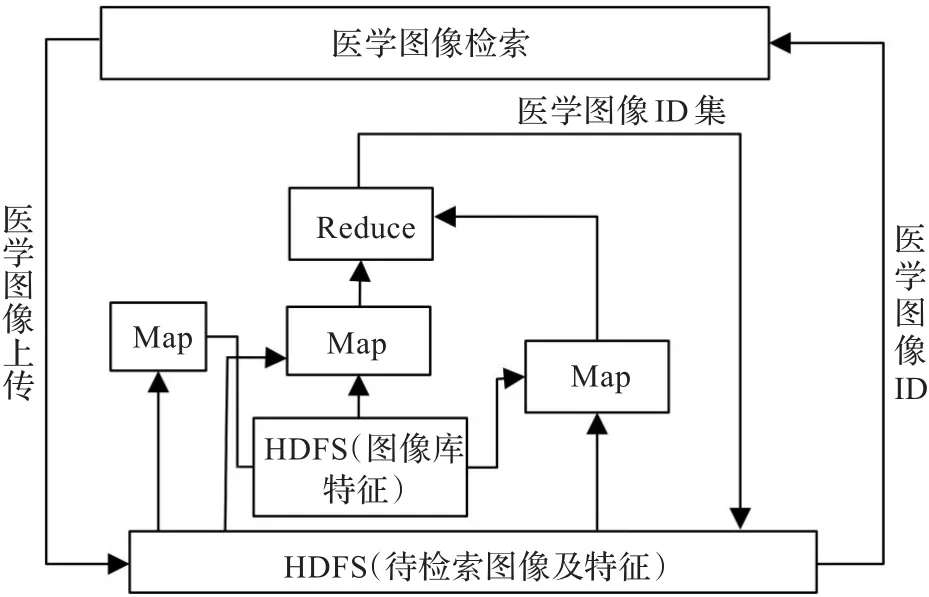
图3 图像检索的工作框图
基于MapReduce的医学图像检索步骤如下:
(1)收集医学图像,提取相应的特征,并将特征数据存入HDFS。
(2)用户提交检索请求,提取待检索的医学图像的Brushlet域特征和LBP特征。
(3)Map阶段。将待检索的医学图像特征与HBase中的图像特征进行相似度匹配,map的输出为<相似度,图像ID>键值。
(4)根据相似度的大小对map输出全部<相似度,图像ID>键值进行排序和重新划分,然后再输入到reducer。
(5)Reduce阶段。收集所有的<相似度,图像ID>键值对,再对这些键值对进行相似度的排序,把前N个键值对写入到HDFS。
(6)输出与待检索医学图像最相似的那些图像的ID,用户得到最终的医学检索结果。
云计算医学图像检索系统的工作流程如图4所示。
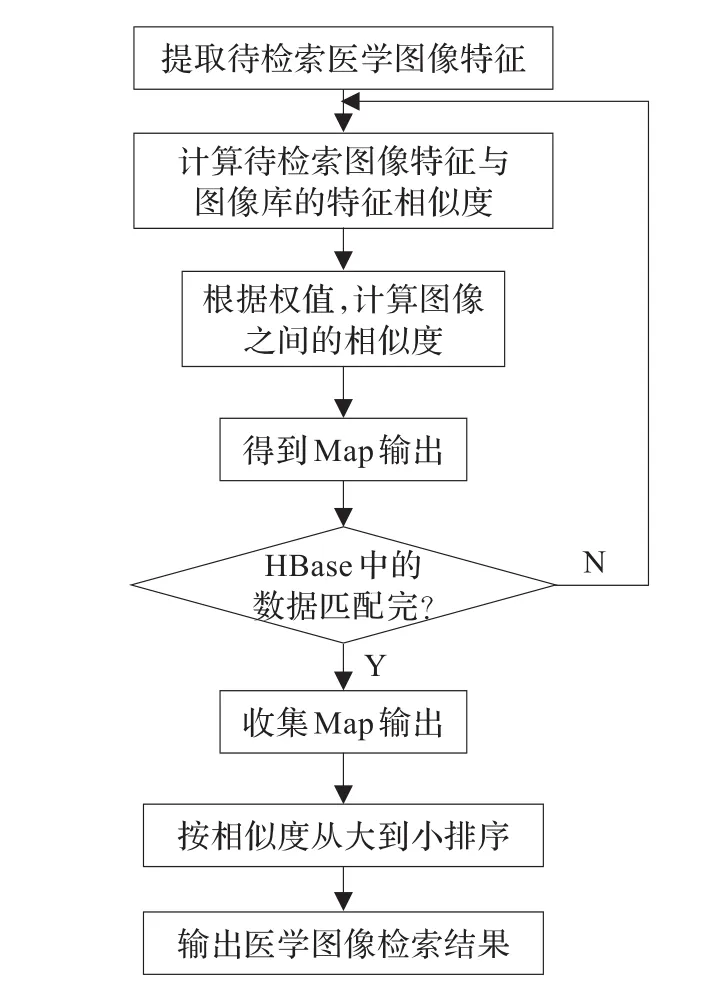
图4 云计算医学图像检索系统的工作流程
4 仿真测试
4.1 实验环境
在Linux环境下,通过1个主节点(NameNode)机和3工作节点(DataNode)组成一个云计算系统,通过主节点对工作节点进行管理,具体配置见表1。在云计算系统中,通过在不同的节点数下进行医学图像检索测试,将其测试结果与传统B/S架构下的图像检索系统的测试结果进行对比,系统性能评价标准采用存储效率、检索速度、查准率(%)、查全率(%)、检索速度,并对云计算图像检索系统的性能进行分析。
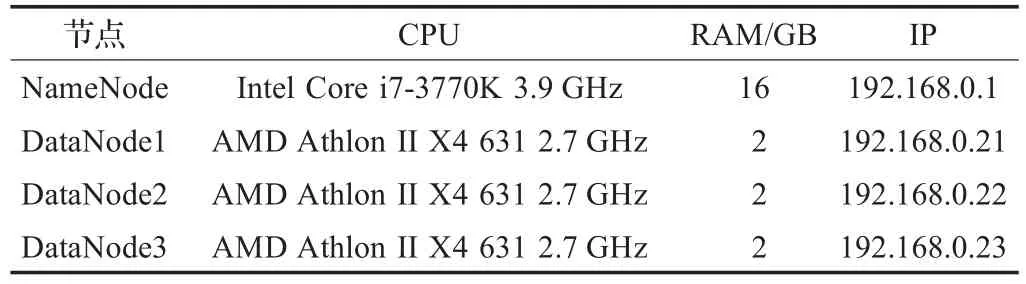
表1 云计算系统各节点的配置情况
4.2 系统负载性能测试
通过向云计算系统(节点数为3)提交医学图像检索任务,在不同时间点以及不同数据量下测试各节点的负载情况,记录各节点CPU的使用率,时间采样平均分布在检索任务的执行时间内,统计结果如图5~7所示。从图5~7可以得到如下结论:

图5 处理40万幅图像的CPU使用率

图6 处理80万幅图像的CPU使用率

图7 处理100万幅图像的CPU使用率
(1)当医学图像数据量为40万幅时,只有2个Map任务,2个Map任务分别分配给DataNodel和DataNode3,t1和t2时刻(时间间隔为10 s),两个节点的Map任务在执行中。
(2)t3时刻,DataNode3节点的Map任务执行完毕,并在该节点开始执行Reduce任务,DataNodel节点的Map任务还在执行。
(3)在t4时刻,DataNodel节点上的Map任务完成,该节点将Map任务产生的中间结果交由DataNode3进行Reduce处理。
(4)在t5时刻,只有DataNode3在执行Reduce任务,DataNodel和DataNode2处于空闲状态。
(5)t6时刻,整个检索任务完成,各节点处于空闲状态。
(6)在处理80万幅医学图像(时间点间隔为25 s)和120万(时间点间隔为40 s)时,各节点的负载情况类似于处理40万幅医学图像的负载情况。
4.3 与传统方法的性能对比
4.3.1 存储性能对比
采用不同数量的医学图像,在不同节点情况下,图像存储时间如图8所示。从图8可知,当医学图像数量较小时,相对于B/S单节点系统,云计算系统的优势不明显。当医学图像数量增大时,B/S单节点系统的存储时间大幅度增加,而云计算系统存储时间增长比较缓慢,这表明采用MapReduce方式将医学图像上传到HDFS中,提高了存储效率。
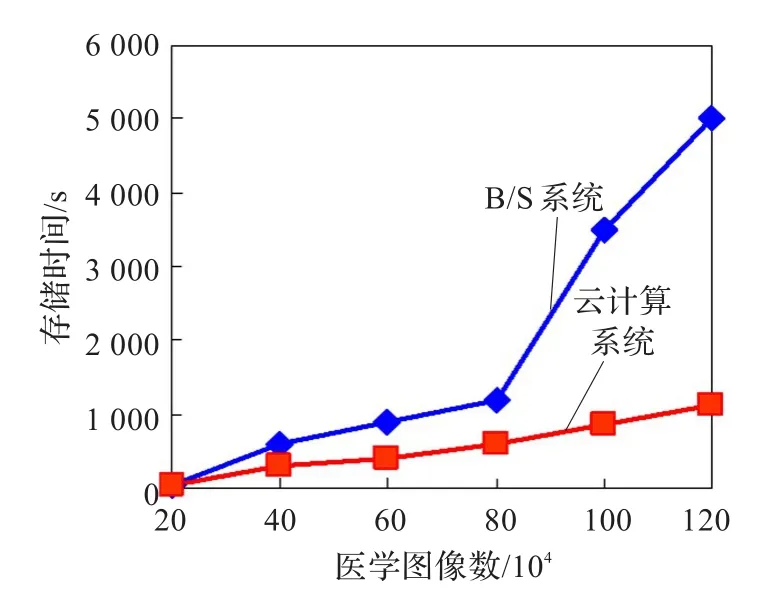
图8 两种系统的医学图像存储时间对比
4.3.2 检索效率对比
医学图像的数据量分别为20万、40万、60万、80万、100万以及120万幅时,云计算的医学图像检索系统与B/S单节点系统的图像检索的耗时,实验结果如图9所示。当医学图像数据量为20万幅,云计算系统检索速度比B/S单节点模式慢,因为此时医学图像数据量比较小,云计算把数据集作为一个Map任务,存放在一个节点上进行处理,即只有一个节点执行一个Map任务,任务的初始化、分配以及清空作业的耗时造成检索时间的延长。当医学图像数据量为40万幅时,此时有2个Map任务,云计算系统医学图像检索的速度有了很大提高,相比B/S单节点系统,检索速度分别提高了41.15%;当医学图像数据量为60万幅时,此时有3个Map任务,云计算系统的检索时间相对于B/S单节点模式分别提高了33.89%。当数据量继续增大时(数据量大于60万),此时云计算系统的检索时间成线性增长,因为Map任务已超出了分布式系统的节点数,部分节点会分配多个Map任务,而一个节点同一时刻只能处理一个Map任务,从而使检索时间呈线性增长,因此适当增加云计算系统的节点数,以增强分布式系统并行处理Map任务的能力,并提高医学图像检索速度。

图9 两种系统的医学图像检索效率对比
4.4 与B/S系统的检索结果对比
对于表2不同类型的医学图像,采用云计算系统和B/S系统进行检索,得到的检索结果见表2。从表2可知,云计算系统的查准率和查全率均要优于B/S单节点系统,这表明云计算系统提高了医学图像检索速度,获得了更高医学图像的查准率、查全率。

表2 多类医学图像检索结果对比
5 结束语
针对海量医学图像检索效率低的难题,提出一种云计算的医学图像检索系统。仿真测试结果表明,云计算的医学图像检索系统缩短了图像存储和检索时间,获得较优的检索结果,较好地满足了图像检索的实时性要求,尤其当处理大规模医学图像时,具有传统算法不可比拟的优势。
[1]沈哗,夏顺仁,李敏丹.基于内容的医学图像检索中的相关反馈技术[J].中国生物医学工程学报,2009,28(1):128-137.
[2]张泉,邰晓英.基于Bayesian的相关反馈在医学图像检索中的应用[J].计算机工程,2008,44(17):158-161.
[3]焦蓬蓬,郭依正.特征级数据融合在医学图像检索中的应用[J].计算机工程与应用,2010,46(6):217-220.
[4]Chang F,Dean J.Bigtable:a distributed storage system for structured data[C]//7th OSDI,2006:276-290.
[5]Kekre H B,Thepade S,Sanas S.Improving performance of multileveled BTC based CBIR using sundry color spaces[J].International Journal of Image Processing,2010,4(6):620-630.
[6]利业鞑,林伟伟.一种Hadoop数据复制优化方法[J].计算机工程与应用,2012,48(21):58-61.
[7]王贤伟,戴青云,姜文超,等.基于MapReduce的外观设计专利图像检索方法[J].小型微型计算机系统,2012,33(3).
[8]Ghemawat S,Gobioff H,Leung S T.The Google file system[C]//Proceedings of the 19th ACM Symposium on Operating Systems Principles.Bolton Landing:ACM,2003:29-43.
[9]李彬,刘莉莉.基于MapReduce的Web日志挖掘[J].计算机工程与应用,2012,48(22):95-98.
[10]Dean J,Ghemawat S.MapReduce:a flexible data processing tool[J].Communications of the ACM,2010,53(1):72-77.
[11]Shvacliko K,Kuang H,Radia S,et al.Hadoop distributed file system for the grid[C]//Proceedings of the Nuclear Science Symposium Conference Record(NSS/MIC),2009:1056-1061.
[12]Dean J,Ghemawat S.Mapreduce:simplified data processing on large clusters[C]//Proceedings of the 6th Symposium on Operating Systems Design and Implementat.San Francisco:Google Inc,2004:107-113.
[13]练秋生,李芹,孔令富.融合圆对称轮廓波统计特征和LBP的纹理图像检索[J].计算机学报,2007,30(12):2198-2204.
[14]王中晔,杨晓慧,牛宏娟.Brushlet域复特征纹理图像检索算法[J].计算机仿真,2011,28(5):263-266.
[15]赵汝哲,房斌,文静.自适应加权LBP的单样本人脸识别方法[J].计算机工程与应用,2012,48(31):146-149.
猜你喜欢
北京大学学报(自然科学版)(2021年3期)2021-07-16 07:13:40
东北师大学报(自然科学版)(2021年1期)2021-03-27 01:22:14
电脑爱好者(2020年19期)2020-10-20 06:02:06
电脑爱好者(2020年18期)2020-09-26 14:53:01
电子制作(2019年13期)2020-01-14 03:15:18
信号处理(2018年1期)2018-09-03 07:53:04
信号处理(2018年5期)2018-06-28 02:16:02
信号处理(2018年4期)2018-06-27 03:34:16
信号处理(2018年3期)2018-06-27 03:30:18
电脑爱好者(2017年9期)2017-06-01 21:38:08
