
基于人工智能的矿井水害水源自动识别方法研究①
2013-08-28 03:38孙莉民魏军贤黄江兰余生晨王晓菊
华北科技学院学报 2013年2期
李 枫 孙莉民 魏军贤 黄江兰 余生晨 郭 慧 王晓菊
(1.中国矿业大学,江苏 徐州 221116;2.高河能源有限公司,山西 长治 047100;3.华北科技学院,北京 东燕郊 101601)
0 引言
我国煤矿各种煤矿灾害(例如:水、火、瓦斯爆炸、煤尘、顶板、冲击地压等)频发。矿井水害是我国包括煤矿在内的各类矿床开采中经常遇到的主要地质灾害之一,也是制约矿区生产活动和可持续发展的重要因素,其表现形式通常 为突、涌、溃、淋水等。煤矿井突水灾害会造成重大财产和人员伤亡,例如,前2年山西省王家岭煤矿发生的重特大透水事故,造成20多人的死亡和几个亿的财产损失。多年来对矿井水害的预防和治理一直是相关领域科学、工程与生产工作者关注和研究的重要课题。水文地球化学(简称“水化学”)探测技术主要利用地面水质化验的结果,一般是八个指标,有时或更多,然后根据这些指标分析水源。它是矿井防治水工作中的一种重要手段,在矿井突水水源判别方面效果显著,是一种快速、经济、实用的方法。目前一般采用以下几种方法:(1)利用特征离子或特征离子比值法判别突水水源;(2)利用水质分析结合同位素综合分析方法判断突(涌、淋、溃)水水源;(3)利用人工示踪法判断水源;(4)通过建立数学判别模型的方法判断突水水源。例如,有单位通过研究认为某煤矿奥灰水中含量为9~10.5 mg/L,其它含水层水中离子含量很低,为此把离子含量的大小作为判断是否是奥灰突水的手段[1]。然而这种手工且根据单一地面水质化验的指标判断水源的方法,在一些复杂地区的判断结果与实际有较大的出入。另外,在地面水质化验的结果中,众多化验指标的单位是不统一的,例如,离子含量单位为mg/L(毫克/升),有些离子含量单位为mol/L(模尔/升,1模尔Mg2+离子=6.02×1023个Mg2+离子),这就给通过建立数学判别模型的方法判断突水水源的方法带来很大麻烦,导致该方法判断结果误差较大。为解决这两个问题,本论文给出了(1)对众多指标的单位进行统一的方法——归一化处理;(2)常用的模糊聚类算法的计算效率很高,但是它的主要缺点是所选定的这种模型常常不能反映数据的概率结构,因此用这些方法所得到的结果不能反映数据构造的真实情况,为此本文提出了一种利用多指标判断水源的方法。实验和生产实践证明该方法效果较好。
1 水源识别理论
利用数学模型对矿井水化学数据进行处理并判别充水水源,是现代地球化学、数学和计算机科学相结合的必然结果。水源识别过程的步骤如下:
1)根据实际情况,首先建立一个煤矿,或一个区域(例如,潞安集团所属煤矿区),或我国煤矿充水水源的水化学模型(或建水样库)。我国煤矿充水水源主要有砂岩水、奥灰水、太灰水、老空水。有些在浅海区下面开采的煤矿充水水源主要是海水,在水库或湖泊下面开采的煤矿充水水源主要是水库或湖泊水。
2)获取水质化验分析的多个指标:例如,即K(钾)、Ca2+(钙)、Mg2+(镁)、(硫酸盐)、PH(PH值)、Fe(铁)、(亚硝酸盐)、I(碘)和T(水温)。
3)建立数学判别模型的方法判断突水水源,例如可以应用人工智能方法判定水的来源;
4)当判定为奥灰承压水,或老窑采空区积水,即可能会发生水害的水源,则可采取预防措施;当判定为其它水源或危害性较小的水源时,可正常采煤。
2 众多指标单位统一的方法——归一化
在实际问题中,不同的数据一般有不同的量纲(即,单位),样本的各分析指标之间的尺度比例(单位或量纲)的确定也是一个十分重要的问题[2]。如图1 所示的四个样本 1,2,3,4。在两个坐标轴不同比例(即不同单位)的变换下,得到了完全不同的结果。

图1 水源分析指标单位不同影响判别结果
在上图1中,当x1轴压缩成x'1时,判别聚类结果是1,2为一类,3,4为另一类。而当x2轴压缩成x'2时,判别聚类结果则完全不同,1,3被聚成一类,2,4被聚为另一类。这说明在实际进行判别分析时,要很慎重地对待这个问题。
为了使有不同量纲的量能够进行比较,需要将数据规格化,即将数据变换为无量纲的数据,然后再判别聚类分析,本文给出的方法有:
以Ca2+(钙)离子为例,假设 xi=Ca2+(钙)离子,其观测了20个数据,这里n=20。
2.1 标准差标准化
对于第i个测量指标归一化(标准化),就是将第i个测量指标换成x'i,
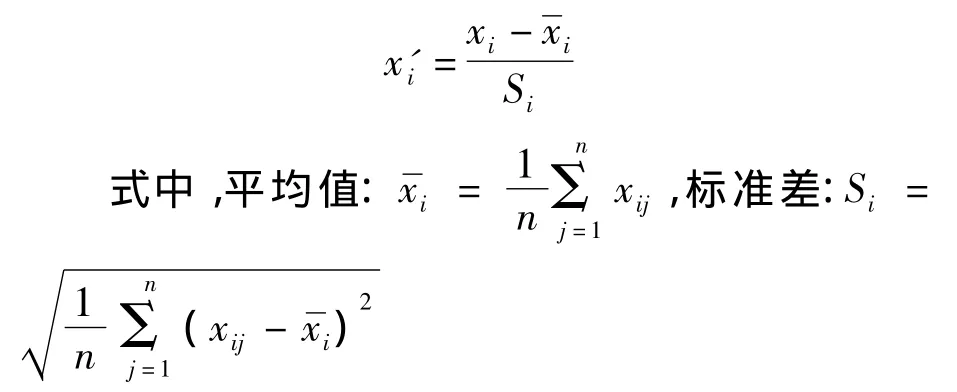
这样归一化后,第i个测量指标的取值在-1~+1之间。
2.2 极差正规化

式中,最小值:min(xi);最大值:max(xi)
这样归一化后,第i个测量指标的取值在0~+1之间。
2.3 极差标准化
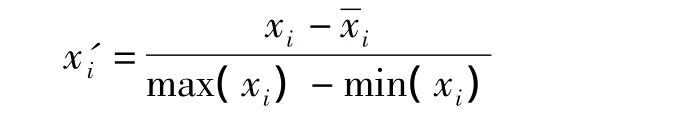
式中,最小值:min(xi);最大值:max(xi)这样归一化后,第i个测量指标的取值在-1~+1之间。
2.4 最大值规格化

式中,最小值:min(xi);最大值:max(xi)
这样归一化后,第i个测量指标的取值在0~+1之间。
3 水源快速自动识别技术
常用的模糊聚类算法的计算效率很高[3],但是它的主要缺点是所选定的这种模型常常不能反映数据的概率结构,因此用这些方法所得到的结果不能反映数据构造的真实情况,为此本文提出了一种利用多指标判断水源的方法——动态自适应模板方法。
3.1 动态自适应模板方法
我国煤矿充水水源主要分为4大类:砂岩水、奥灰水、太灰水、老空水,也可加入其它水源,例如,海水、湖泊水、地面泉水和断层氧化带水等。一般是根据实际问题,确定水源的分类。
动态自适应模板方法可以自动完成分类识别水源,它综合了自顶向下(将所有样品看作为一个大类,然后再找出最不相似的样品分列出去成为两类)和自下向上(每个样品为一类,然后再将最近的两类合并为一类)的分类识别方法的优点,能自动地进行类(水源)的合并和分裂,能吸取中间结果所得到的经验,主要是在迭代过程中可将一类一分为二,亦可能二类合二为一,从而得到类数较合理的聚类结果。也可以加入一些试探性步骤和人机交互功能,这种算法已具有启发式的特点。
下面给出动态自适应模板方法
1)动态自适应模板方法的步骤,其基本步骤为:
(1)选择某些初始值―可选不同指标,也可在迭代运算过程中人为修改,以将N个模式样本按指标分配到各个聚类中心去。
(2)计算各类中诸样本的距离函数等指标。
(3)~(5)按给定的要求,将前一次获得的聚类集进行分裂和合并处理((4)为分裂处理,(5)为合并处理),以获得新的聚类中心。
(6)再次迭代运算,重新计算各项指标,判别聚类结果是否符合要求,经过多次迭代运算后,如结果收敛,运算结束。
2)动态自适应模板方法的具体步骤为:
已知样本集为{x1,x2,…,xN},将 N 个模式样本{x1,x2,…,xN}读入。
预选 Nc个初始聚类中心{},它可以不必等于所要求的聚类中心的数目,其初始位置亦可从样本中任选一些代入。
第一步:规定下列控制参数:
预选:K=期望得到的聚类数,也即预期的聚类中心数目;
QN=一个聚类中的最少样本数,即如少于此数就不作为一个独立的聚类;
Qs=一个聚类域中样本距离分布的标准偏差参数;
Qc=合并参数;
L=每次迭代允许合并的最大聚类对数;
I=允许迭代的次数。
设初始的聚类数c和初始的聚类中心wi,i=1,2,…,c。
第二步:按照下述关系
若‖x -wi‖ < ‖x -wj‖,j=1,2,…,c,j≠i,则 x∈Ri
将所有样本分到各个聚类中去。Ri为第I个聚类,其中心为wi
第三步:若有任何一个 Ri,其基数 Ni<QN,则舍去 Ri,并令 c=c-1;
第五步:计算Ri中的所有样本距其相应的聚类中心wi的平均距离

第六步:计算所有样本距离其相应的聚类中心的平均距离

第七步:(a)若这是最后一次迭代(由参数I确定),则置θc=0,转下面第十一步;
(c)若是偶数次迭代,或若是c≥2K,则转第十一步。否则,往下进行。
第八步:对每一个聚类Ri,用下列公式求标准差 σi=(σi1,σi2,…,σin)T

第九步:对每一个聚类,求出具有最大标准偏差的分量 σimax,i=1,2,…,c
第十步:若对任一个 σimax,i=1,2,…,c,存在σimax>θs,并且有:

则把Ri分裂成两个聚类,其中心相应为wi+和wi-,把原来的wi取消,且令c=c+1,wi+和wi-的计算如下:
给定一个α值,0<α≤1,令ri=σimax,则wi+和wi-的距离不同,但又应使Ri中的样本仍然在这两个新的集合中。
第十一步:对于所有的聚类中心,计算两两之间的距离

第十二步:比较 Dij和 θc,将 Dij< θc的值按上升次序排列:
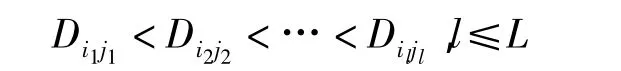

第十四步:若这是最后一次迭代,则算法终止。否则,若根据经验需要改变参数,则转第一步;若不需要改变参数,则转第二步。本步中,还应将迭代计数器加1。本算法完毕。
3.2 应用动态自适应模板法识别水源
基本做法是将每一个水源样本与已存的模板一一进行相似性度量测量,取距离最小或相关系数最大者归类。动态自适应模板法的基本思想是原有模板在聚类过程中不断更新,并且允许在聚类分析过程中构成新的模板。具体说来如下:
1)原有模板在聚类过程中不断更新,是指当某一水源类别t增添了新样本Xk时,则以下面的递推公式对模板进行刷新:

式中 Mt,k是第 K 次更新的模板向量;Nt,k是归入第t类的样本数,所得的新模板是该类样本的平均值。从统计学的观点看,平均值更接近于真值。
2)允许在聚类分析过程中构成新的模板是指对相似性测量的结果设定一个阈值,当新的水源样本与原有所有模板的距离均大于这个阈值时,则证明它不属于已有的任一形态集,算法将以表达该水源的向量构造一个新的模板。
定义第i个样本和第m个模板之间的距离为:

4 实验结果与讨论
本文用潞安集团所属煤矿区的矿井和钻孔水样,利用在地面对其水质化验的指标判断水源。该煤矿区的充水水源主要分为4大类:砂岩水、奥灰水、太灰水、老空水,地面泉水和断层氧化带水等。表1给出了用动态自适应模板方法识别该煤矿区水源的结果。

表1 用本文研究的方法识别水害水源的结果比较

表2 用本文研究的方法识别水害水源的结果和部分数据
由表1和表2可以看出几种不同的方法对水害水源的识别正确率是不同的。运用动态自适应模板方法对水源的正确识率是最高的,从而证明本文研究的方法是有效的而且是可行的。
[1] 刘峰.矿井水害水源的水文地球化学探测技术[J].煤田地质与勘探,2007,35(4):20-23
[2] 董书宁.对中国煤矿水害频发的几个关键科学问题的探讨[J].煤炭学报,2010,35(1):66-71
[3] 郑纲.模糊聚类分析法预测顶板砂岩含水层突水点及突水量[J].煤矿安全,2004,35(1):24-25
[4] 石磊,徐楼英.基于水化学特征的聚类分析对矿井突水水源判别[J].煤炭科学技术,2010(3):97-100
[5] 周健,史秀志,王怀勇.矿井突水水源识别的距离判别分析模型[J].煤炭学报,2010,35(2):278-282
猜你喜欢
品牌研究(2022年18期)2022-06-29
内江科技(2021年6期)2021-12-28
煤矿安全(2021年11期)2021-11-23
工程技术与管理(2021年19期)2021-04-03
当代陕西(2019年24期)2020-01-18
小天使·六年级语数英综合(2016年7期)2016-05-14
铁道科学与工程学报(2015年5期)2015-12-24
科技传播(2014年21期)2014-11-17
河南科技(2014年16期)2014-02-27
河南科技(2014年15期)2014-02-27
