
基于增量的贝叶斯算法在网页文本中的应用
2013-07-22 02:52屈军
赤峰学院学报·自然科学版 2013年13期
屈军
(台山磐石电视大学,广东台山529200)
基于增量的贝叶斯算法在网页文本中的应用
屈军
(台山磐石电视大学,广东台山529200)
如今文本自动分类技术发展已较为成熟,中文网页的分类也是自动分类技术的应用之一.分类精度依赖于分类算法,贝叶斯算法在网页分类中有很广泛的使用,但它需要大量且已标记的训练集,而获得大量带有类别标注的样本代价很高.本文以中文网页信息增量式的学习作为研究对象,利用网页已验信息处理训练集增量问题,提出一种改进的增量式的贝叶斯分类算法,研究利用未标记的中文网页来提高分类器的性能,并进行相关实验对比和评价.
增量学习;贝叶斯;TFID;文本自动分类;网页
1 引言
能否从海量的网页中迅速、准确的搜索用户感兴趣的信息是对网页分类技术的挑战.如今,网页分类相关技术的研究正逐渐成为继文本分类之后机器学习领域的研究热点.虽然文本分类技术已经在中文网页分类中使用,但网页分类中的问题相对文本分类更加难以处理,因为网页格式多样化,除纯文本以外,还有其它一些内容对分类有影响.贝叶斯分类器对网页的分类通过对训练集的样本进行学习,训练集的样本数量要求尽可能大的,并且要对样本进行标记,样本的标记是需要通过人工来完成,工作量大而且容易出错.因此,本文研究训练集的中文网页样本在没有标记的情况下,通过分类器的进行增量学习,从而提高分类器的分类效果,并结合TFIDF算法设计了一个的增量式贝叶斯分类系统,并进行相关实验对比和评价.
2 贝叶斯分类算法及改进算法
2.1 贝叶斯条件概率公式
随着计算机技术的日益成熟,使用机器来模拟人类学习活动学科-机器学习,成为研究的热点之一.机器学习是一门研究机器获取新知识和新技能,并识别现有知识的学问.贝叶斯理论在机器学习研究领域就以其独特的性能成为注目的焦点,比如具有概率表达能力的丰富性、知识表达形式不确定性、综合先验知识的增量学习特性等,所以贝叶斯理论占有相当重要的地位在机器学习研究领域中.假设概率计算的方法是贝叶斯理论的核心内容,数据本身和不同数据的概率是在基于假设的先验概率和给定假设下的前提下完成的.贝叶斯理论提供的理论架构是其他算法研究和应用的依据,对于概率的直接操作和定量多个假设的置信度的算法提供了基础.在贝叶斯理论中,学习和推理都是以概率的规则来实现,使用概率地表示所有形式的不确定性.贝叶斯学习的结果表示为随机变量的概率分布,它可以解释为我们对不同可能性的信任程度.贝叶斯公式表示为如下形式其中,h代表假设,而D代表看到的数据集.P(h|D)为给定集D时假设h成立的概率(后验概率),P(h),P(D)为先验知识,而P(D|h)为在给定假设下观察到数据集D的概率,此为先验概率,可用统计的方法得到.
2.2 分类算法TFIDF介绍
TFIDF是常用的文本分类中算法,它采用的是空间向量模型,特征词需要通过分词系统取得,每个特征词作为一个特征项,特征项的参数是tk,文档用向量表示为…,xin),wik是赋予特征项tk(1≤k≤n,n表示文档中特征项的总数)的数值,wik的值反映特征项tk对文本的重要程度,称为特征项的权重,即:wik=tfik*idfkidfk=log(N/dfk+1),词频tfik指某个特征项tk在文档di中出现的次数,文档频率dfk指整个文档集合中,包含特征项tk的文档个数,idfk是特征项tk反比文档频率,N代表训练集文本的数量.TFIDF算法通过对同属一类的所有文本中的向量进行叠加,得到每一个类Cj(Cj∈C,C是一个集合,代表分类文档的类别)的特征向量.利用TFIDF分类器测试文本所属的类别时,通过计算该篇文本的向量和每个类特征向量的相似度距离,相似度距离最大的类向量所属的第j类就是被测试文本的类别.计算公式如下:
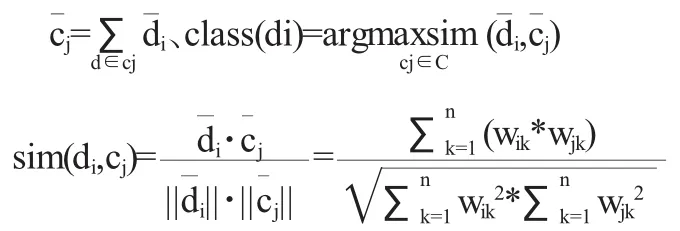
TFIDF算法作为一种有监督学习的分类算法,训练集的规模和样本的选择对算法有明显的影响,对于己标记的文档的训练集,增加训练集的规模,TFIDF算法的分类精度明显提高.
2.3 改进的贝叶斯分类增量算法
改进的增量式训练分类算法的提出前题是:(1)保证现在分类处理的精度;(2)训练集的规模尽可能要小;(3)已被标记的训练集.该算法的特点是通过利用两种不同的分类算法,增量式地训练未标记文档.这两种算法采用文本分类中较为典型的朴素贝叶斯(简称NB)和TFIDF算法,由基于概率模型的朴素贝叶斯负责计算文档后验概率,由基于向量空间模型TFIDF方法负责计算文档向量和类向量的相似度.由于TFIDF算法不需要朴素贝叶斯算法所需要的贝叶斯前提假设,因此利用TFIDF分类器联合朴素贝叶斯分类器进行增量训练,能更好地降低朴素贝叶斯假设条件带来的影响.
增量贝叶斯分类算法步骤如下:
假设L为已分类数据集;U为未分类数据集;L0为改变后的已分类的数据集;U0为改变后的未分类的数据集.
step1:令L0=L;U0=U;
step2:if(U0),则:
①用L0对NB和TFIDF分类器进行训练;
②用NB分类器判断U0中每个文档的类别,做标记;③用TFIDF分类器判断U0中每个文档的类别,做标记;④取每个相同类别中的文档的交集(即利用NB和TFIDF分类器进行投票);⑤若交集为空,goto step3⑥在每一个交集中,根据文档的相似度,对文档进行排列,作为评分标准,从中选取m个评分高的文档,加入L0中;⑦令加入L0中的文档数为T,L0=L0+T;U0=U0-T;goto step2;step3:以L0为训练集进行训练并对测试集进行测试,评价.算法中的m值从实验经验得出.从以上算法可以看出,结合TFIDF算法的NB分类器(以下简称T_N分类器),充分利用了未标记数据来补充训练集,即训练算法采用的是增量训练,利用两种分类算法建立内嵌的分类器协同合作地训练未分类文档,逐次用内嵌分类器判别未知文档的类别并增量地加入到已标记训练集中,达到增加训练集的目的.
3 实验环境及结果分析
3.1 语料库选择
(1)采用中科院成熟语料库,该语料库是经过人工分类好的平衡语料库,包括十个类别:环境、计算机、交通、教育、经济、军事、体育、医药、艺术、政治.(2)从人民网抓取中文网页3265个,根据其从属类别进行人工分类,分为八个类别:教育、游戏、饮食、体育、娱乐、科技、旅游、军事.
3.2 实验
实验①:NB分类器和T_N分类器分类准确率的比较.经过分类测试,得到如下实验结果,见图1.
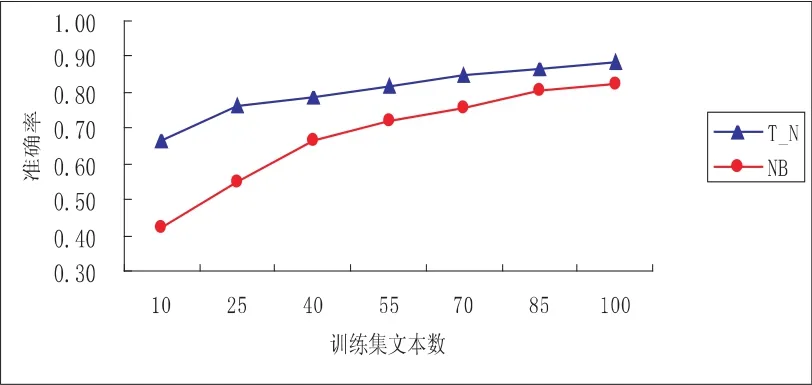
图1 分类性能对比图
从实验结果中得出T_N在分类性能上比NB有一定的提高,在初始训练集较小的情况下,也可以得到不错的分类准确率,随着训练集文本数的提高,分类性能虽有提高,但起伏不大,这表明增量集对分类性能起到较大的作用;而NB分类性能整体比T_N分类器差,而且对训练集大小比较敏感,随着训练集文本数的递增,性能曲线起伏较大,在训练集文本数少的情况下,分类性能明显降低.这说明,未标记的数据集在分类中对分类性能起到较大的作用.实验①:观察算法迭中增量集对分类性能的提高所作的贡献.在T_N分类器中,每经过两次迭代,就对测试集进行测试评价.经过分类测试,得到如下实验结果,见图2.

图2 分类器迭代过程中的准确率
从准确率的分布情况,我们可以看到,T_N分类器在经过每次迭代后所增加的训练样本都起到一定的作用,这进一步说明我们所设计的分类系统在每一次的增量学习中都能够提高分类器的性能.
总的来说,针对海量的中文网页自动分类问题,贝叶斯分类算法充分利用了先验信息的特性,是增量学习中的最佳选择模型,结合TFIDF算法的贝叶斯分类器实验证明确实能发挥其优点,可以解决获得大量已标记文本的问题,实验结果表明增量式训练算法具有较高的分类准确度.
〔1〕苏金树,张博锋,徐昕.基于机器学习的文本分类技术研究进展.软件学报,2006,17(9).
〔2〕余芳.一个基于朴素贝叶斯方法的WEB文本分类系统:WebCAT.计算机工程与应用,2004(13).
〔3〕刘青,何政.结合EM算法的朴素贝叶斯方法在中文网页分类上的应用.计算机工程与科学,2005,27(7).
TP391.1
A
1673-260X(2013)07-0023-02
猜你喜欢
当代陕西(2022年6期)2022-04-19
中学生数理化·中考版(2019年9期)2019-11-25
计算机应用(2017年4期)2017-06-27
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
电信科学(2016年9期)2016-06-15
铁道通信信号(2016年6期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
电子器件(2015年5期)2015-12-29
电子设计工程(2015年16期)2015-02-27
