
基于随机游走模型的物体识别
2013-07-20 01:32林霄肖国强吴松邱开金
计算机工程与应用 2013年21期
林霄,肖国强,吴松,邱开金
西南大学计算机信息科学学院,重庆 400715
基于随机游走模型的物体识别
林霄,肖国强,吴松,邱开金
西南大学计算机信息科学学院,重庆 400715
1 引言
自然界中的物体具有不同的属性,如颜色、形状、纹理等,这些不同的属性在大脑的不同部位被加工。人之所以能在各种不同的情境中,通过视觉系统轻松地识别物体,是因为人在对各类物体的学习过程中不仅记忆了该物体的相关特征,还在大脑中建立了各类物体之间的先验关系。然而在计算机视觉系统中要建立由这种先验关系组成的统一机制却是十分困难的,这也使得物体识别成为了计算机视觉研究领域中一个非常具有挑战性的课题。
区域语义标定(Region Labeling,RL)是近年来国内外研究的热点问题之一。它的主要工作是对图像中的特定区域进行语义标定。文献[1]中用贝叶斯网络构造概率模型对各类标记的空间位置关系和共现性进行学习,并用遗传算法完成对图像的最佳标定。文献[2]中提出一种能量模型来描述各类标记间的关系,并完成对区域的标定。这说明了建立一个用以描述标记间内在联系的关系模型对RL的重要性。可视物体识别(Visual Object Class Recognition,VOCR)的主要工作是预测图像中某类语义的范例是否出现。而当图像中包含多类物体时,VOCR和RL所需解决的问题是一致的。基于以上思想,将关系模型应用到VOCR的过程中是可行的。
传统的物体识别算法大致可分为基于局部特征的物体识别和基于全局特征的物体识别两类。基于局部特征的物体识别算法通过对图像中兴趣点(区域)的检测,得到关于图像的局部信息以完成对物体的识别。例如,文献[3]中采用基于特征点检测以及不同类型物体的特征点所构成的独特空间几何结构来进行物体识别。基于全局特征的物体识别算法试图找到能代表图像中所有信息的全局特征,并以该全局特征进行物体识别。这不仅包括简单的统计方法,例如像素均值、直方图特征等,还包括复杂的降维算法,例如主成分分析[4]、独立成分分析[5]、非负矩阵分解[6]。其中降维算法[7-8]的主旨在于把原图像投影到一个最能表达原图像数据的低维子空间中。无论是基于局部特征的物体识别算法,还是基于全局特征的物体识别算法都未将先验关系应用到物体识别的过程中,因此很难建立一个有效且完善的由先验关系组成的统一机制。本文以建立一个这样的统一机制为出发点,提出了一种结合先验关系的物体识别算法。在训练阶段,首先,用图像的全局特征相似度建立图像相似性图(Image Similarity Graph,ISG);同时,用领域本体中各语义对象的相对距离建立语义相似性图(Semantic Similarity Graph,SSG);其次,采用JSEG算法[9]对图像进行分割,得到图像的子区域集,选取部分得到的子区域作为训练样本,利用支持向量机(Support Vector Machine,SVM)进行训练得到一个对于多类物体的分类器。用该分类器建立图像与语义间的关系,并形成统一的混合图模型。在识别阶段,首先,在统一的图模型中新建一个待识别图像节点,通过提取其全局特征建立该节点与其余图像节点的全局特征相似性关联。其次,对待识别图像进行分割,利用训练得到的分类器建立待识别图像节点与语义节点间的语义相似性关联。最后,以该节点为起始节点进行随机游走,并把随机游走的结果作为该图像中的物体识别的结果。实验结果验证了该算法的有效性和可靠性,以及其较好的物体识别性能。
基于随机游走模型的物体识别算法流程图如图1所示。
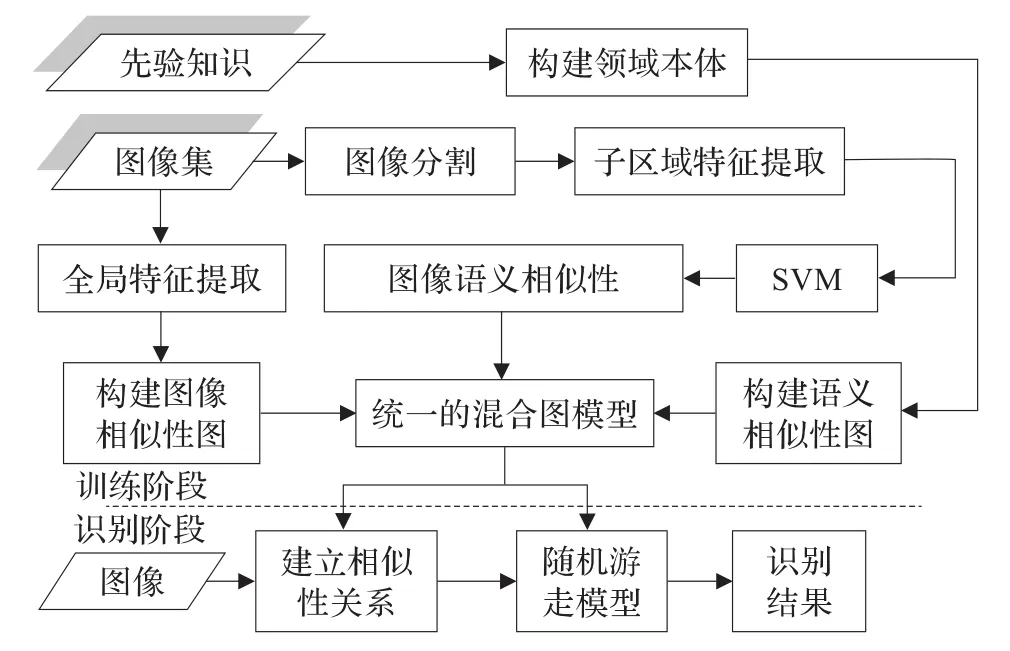
图1 基于随机游走模型的物体识别算法流程图
2 ISG的建立
2.1 全局特征的提取
在图像处理中,常用的描述图像全局信息的特征大致分为三类:颜色、纹理和形状特征。本文选取图像的颜色和纹理作为全局特征。
2.1.1 颜色特征
颜色直方图(Color Histogram,CH)是一种在图像处理应用十分广泛的图像颜色信息表示方法。它是对图像的颜色特征进行统计所得到的关于特征的统计直方图,具有有效地反映图像中颜色组成分布的优点。对于RGB三通道下的彩色图像,首先将其转化到HSV颜色空间,然后把每个颜色通道里面的颜色信息都量化为10个不同的等级。通过直方图的统计,对于每幅彩色图像都可以得到一个相关的颜色特征。
2.1.2 纹理特征
局部二元模式(Local Binary Pattern,LBP)[10]是近年来提出的一种有效的纹理描述方法,它通过比较图像中每个像素与其邻域内像素灰度值的大小,利用二进制模式表示的比较结果来描述图像的纹理,可以对灰度图像中局部邻近区域的纹理信息进行有效度量和提取。LBP特征突出的优点是对目标灰度变化不敏感且计算简单迅速。在本文中,每幅图像都可以得到一个LBP纹理特征。
2.2 全局特征的相似性度量
在完成全局特征的提取并对其进行归一化处理之后,定义了衡量各全局特征间相似性的度量。设图像集Ι中图像的数量为N,对于第i张图片Ιi,i∈[1,N],存在全局特征向量νi。这里用两个向量间夹角的余弦函数作为其相似性度量,则对于全局特征向量νp,νq,p,q∈[1,N],其相似性可表示为:

2.3 建立ISG
计算图像之间的相似性度量是建立图像相似性图的基础。此外,建立一个图模型,还需要选取建立图模型的方法,例如:最邻近图(k-Nearest Neighbor,kNN),ε阀值邻近图,指数加权图等。文献[11]中证明了利用kNN图建立的图模型在大多数情况下具有较好的相关性表达能力。因此,在本文中基于kNN图来建立图像相似性图。在该图模型中,每幅图像都对应了图中的一个节点。对于任意图像Ιi,取与其相似度较大的i个图像作为该图像的相邻节点。相应地,把图像Ιi在图中所对应的节点与其近邻节点用以Ιi为始点的有向边连接起来,并把它们之间的相似度作为该有向边的权值。由此,完成了对图像相似性图的建立。图2举例说明了一个由4个节点组成且k=1时建立的图。值得注意的是,由于图像Ιp与图像Ιq并不一定互为近邻,所以建立的图像相似性图并非是一个对称的图模型。
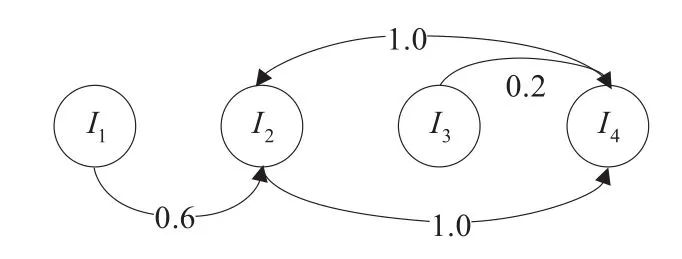
图2 图像相似性图的结构
3 SSG的建立

图3 语义构建的本体图
语义相似性图描述了各类语义之间的关系。不同语义间的关系是很难通过一般的解析式来获得的。语义间的关系是由先验知识决定的,例如:有大象、马、汽车三种语义,存在先验知识“大象和马都是属于动物”,可以推出大象与马的语义相似性强于大象与汽车的语义相似性。所以,本文利用先验知识来完成对语义相似图的建立。
3.1 领域本体
Gruber在文献[12]中对本体进行了定义:本体是一种共享概念模型的形式化规范说明。作为知识和概念描述的重要工具,本体具有领域对象描述手段和描述方法,既可以用于描述简单的事实,又可以用于描述抽象的概念,可用于解决图像语义描述中存在的问题。由于本体的建立是对先验知识库的结构化、形式化的规范,所以本文就以建立本体的形式来建立先验知识库。为了对实验中所需要的12种语义进行描述,在本体中定义了20种语义,利用其先验关系手工构建了该本体的层次结构。
3.2 建立SSG
类似于图像相似性图,树形本体中叶节点所对应的每一种语义都对应了语义相似性图中的一个节点。要建立语义相似性图,关键在于量化定义出任意两种语义间的相似性测度。在本文中通过已构建的领域本体来表达语义间的关系。如图3所示,在本体中两个节点的语义相似性与这两个节点在树形结构中的最短路径相关[13]。设有两种不同的语义Sp与Sq,则它们的语义相似度可表示为:

其中,Dist(Sp,Sq)表示在本体中构成Sp与Sq间最短路径的边的数量。
在完成对语义间的相似性度量的定义之后,便可以利用其建立语义相似性图。同样的,采用kNN图的方法完成语义相似性图的建立。
4 统一图模型的建立
基于上述第2章与第3章所介绍的流程,能分别得到图像相似性图和语义相似性图。但这对于建立一个完整的关系模型是不够的,还需要找出这两类子图之间的联系来建立一个统一的混合图模型。由于图像与语义间是多对多的关系,要直接建立图像与语义之间的关系是复杂的。但是,子区域与语义间的关系是多对一的关系,建立它们之间的关系相对简单。同时,一幅特定的图像中又包含了多个特定的子区域,因此,可以通过建立图像中的子区域与语义之间的关系来完成对图像相似性图与语义相似性图之间的关系建立。
4.1 图像分割
本文选取了经典的JSEG算法[9]作为图像的分割算法。JSEG算法主要包括两个步骤:颜色量化和空间分割。颜色量化的目的是为了减少原始彩色图像的颜色数量,以降低算法复杂度。原图像中像素点的像素值被量化为J个类,并把量化后的图像作为类图;在分割过程中,通过处理与类图相关的数据得到分割结果。图4显示了JSEG算法对一张图像的分割结果。

图4 JSEG算法分割结果
4.2 子区域特征提取
在完成对原图像的分割之后,需要提取所得到子区域的底层特征。其中颜色特征是最直观、最明显的特征,是图像内容组成的基本要素,是人识别图像的主要感知特征之一。通过JSEG分割算法而得到的子区域具有色彩相似性,容易想到选取其平均色彩作为子区域的颜色特征。但是由于JSEG分割算法的误差导致分割出来的子区域中包含了并不属于该区域的部分,可能会使平均色彩的颜色特征不能准确地表示该子区域的颜色特性。因此,选取子区域的主色彩作为区域的颜色特征。主色彩是通过计算子区域在HSV颜色空间下的颜色直方图,并取其中最大的组所包含的像素点的像素平均值。最终得到一个由平均色彩和主色彩组成的颜色特征。
与全局纹理特征提取相似,在提取子区域的纹理特征时,也使用LBP纹理特征的提取方法。由此可以得到子区域的纹理特征,并将颜色特征和纹理特征级联得到子区域的特征。
4.3 基于SVM的分类器训练


4.4 建立统一图模型

基于上述方法,完成了对图像相似性图与语义相似性图之间的关系的构建,从而得到了一个统一的混合图模型,如图5所示。
5 随机游走模型
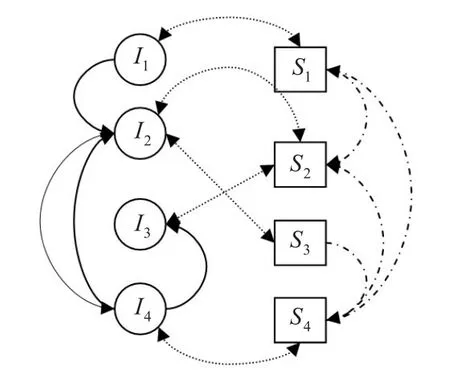
图5 统一的混合图模型(不同类型的边表示不同种类的关系)
随机游走模型的基本思想是,以一个节点为起始点开始遍历一张图。对于任意一个节点,遍历者以概率1-σ游走到该节点的近邻节点,以概率σ随机跳转到图中的任一节点,并称σ为随机跳转发生概率。每次游走后,可以得到一个新的概率分布,该概率分布描述了经过该次游走后图中每个节点被访问到的概率。把得到的概率分布作为下一次游走的输入并反复迭代这一过程。本文在建立统一图模型的基础上,使用随机游走的方法来获取图像与语义之间联系的紧密程度,即完成对图像中物体的识别。
设G={V,E},G表示统一的混合图模型。V=D∪S表示G中的所有节点,D表示图像节点集,S表示语义节点集。E=E+∪E-∪E*表示G中所有的边,如果边Eij是边集E+中的一个元素,则i∈D且j∈D;同样的,若Eij∈E-,则i∈S且j∈S;若Eij∈E*,则i∈D且j∈S,或者i∈S 且j∈D。
为了建立随机游走模型,需要将E中所有的边的权值表示为概率。则对于边集E*中的所有边,定义其转移概率:

其中,i∈D且j∈S,由于对于一个图像节点可能含有多个具有同一语义的子区域,所以定义mk,k∈[1,nji]表示具有同一语义Sj的子区域,nji为图像Ιi中含有同一语义Sj子区域的数量。同样的,也得到了当i∈S,且j∈D时的转移概率:

对于边集E+,E-中的边,相应地分别定义它们的转移概率。对于i∈D且j∈D,有

其中,β表示节点i的近邻节点集;对于i∈S且j∈S,有

总之,转移概率可表示为:

在前文中知道,随机游走模型中不仅包含随机游走到近邻节点的概率转移,还包括转移到任意节点的随机跳转。在图模型中只定义了可以通过计算得到的节点间的可见关系。而实际上无论是语义节点还是图像节点间都存在一些无法通过计算得到的隐藏关系。在不具有任何先验知识的情况下,为了表示各节点间的隐藏关系,人为定义了随机跳转的概率:L(i,j)=1/(N+12),发生随机跳跃的概率为σ,N+12表示图模型中节点的数量。基于以上考虑,需要对模型中的转移概率进行修正:

其中,T″和L分别代表其对应的转移概率组成的概率转移矩阵。根据文献[14]和文献[15]中对σ的设置,在本文的实验中,把σ的值设为0.25。


在公式(5)中当μ和ω同时为0时,随机游走只会发生在语义相似性图上。而当μ或ω逐渐增大时,随机游走的结果更依赖于图像与语义间的关联或图像与图像之间的关联。
在得到概率转移矩阵T后,利用随机游走模型可以计算以i为起始点经过t次随机游走后节点i转移到节点j的概率:

公式(6)计算了在步长为t的情况下,节点i通过所有路径转移到节点j的概率的累加。连接两节点间的路径越多,计算得到的转移概率P(t|0)(j|i)越大;转移概率越大,两节点间的相似度越高。

6 实验
本文的实验图像集是MIΤ-CSAIL Database of Objects and Scenes中的2 400张图像,每幅图像大小为256像素× 256像素。其中包含八种场景,每种场景300张图像中都包含多个组成场景的物体。从中选取了12类物体作为实验对象。
6.1 全局特征的选取
为了能更好地表达图像间的相似关系,需要选取一些能较好表达图像全局信息的视觉特征。由此,从实验图像集中选取了8类图像,每类图像100张。并分别对边缘方向直方图(Edge orientation histogram,Edge)[16]、Gabor小波纹理特征(Gabor wavelets texture,Gabor)[17]、LBP纹理特征、颜色直方图四种不同的全局特征,以及两种组合特征进行性能比较。对于每一类图像,都随机选取一张图像作为该类图像的中心,并用kNN算法计算各类图像中心在六种不同的全局特征下选取k个近邻时的正确率。实验结果如图6所示。

图6 全局特征精度的比较
可以看到,组合特征明显比单一特征具有更好的性能。在两种组合特征中,由LBP纹理特征和颜色直方图组成的特征更能表达图像中的全局信息。所以,本文使用30维的颜色直方图与59维的LBP纹理特征作为图像的全局特征。
6.2 变量的取值
在设置融合参数μ和ω之前,需要设置另外两个参数的值:构建图像相似性图和语义相似性图时,使用算法中的参数k;随机游走模型中随机游走的步长t。
对于参数k,文献[11]中证明了在基于图模型的机器学习中,k值取值较小时的结果更优。所以,在图像相似性图的建立中,设k=40。即对于图模型中的每个图像节点都有40个最相似的节点与其相连。因此,每个图像节点的出度都为40。同样的,在建立语义相似性图时,设k=2。
参数t决定了随机游走的步长。文献[18]中证明了随机游走算法的收敛性。如果选择一个足够大的步长t,随机游走后的结果将收敛于某个平稳分布。而足够大的随机游走步长t也会让随机游走结果更依赖于整个图模型的结构。反之,较小的随机游走步长t会使随机游走的结果更依赖于起始点的属性。由于在进行随机游走时更注重的是起始节点本身的属性。所以在本文中,选择了一个较小t 值(t=10)。
在确定了参数k以及参数t的取值后,还需要设定随机游走模型中的各子图间的融合参数μ和ω。μ、ω和1-μ-ω,μ,ω∈[0,1]分别代表了在三个子图中随机游走的扩散速度。在实验数据集上用网格搜索的方法来确定该参数的最佳值。
由图7可知,对于随机游走模型,分别设置μ、ω和1-μ-ω为0.3,0.6,0.1时的物体识别率为最高值。

图7 网格搜索确定融合参数
6.3 基于随机游走模型的物体识别
完成对各参数的设定后,便可以利用建立好的随机游走模型来进行图像中物体的识别。为了验证本文提出算法对仅基于视觉特征的物体识别算法的优化,把第4章中所提出的基于多特征和SVM的物体识别(multi-feature SVM)算法和本文提出的算法进行对比,如图8所示。
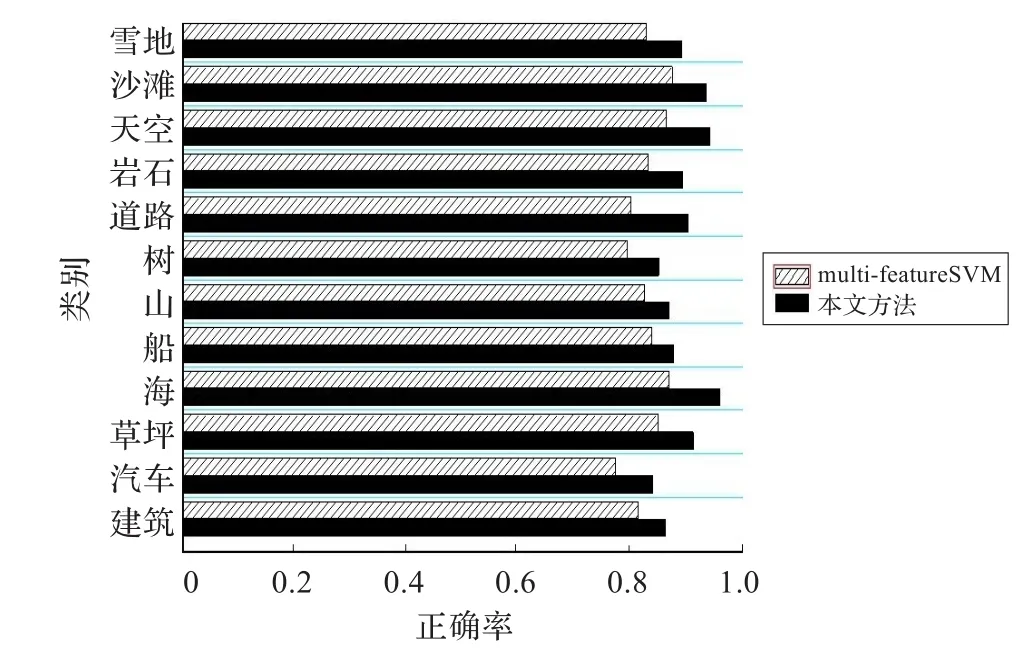
图8 multi-feature SVM与本文算法的识别率比较
本文提出的方法对各类物体的平均识别率可达90.3%。相对于基于多特征和SVM的物体识别算法,每类物体的识别率都得到了提高。表1举例说明了本文方法对基于多特征和SVM的物体识别算法识别结果的修正。可以看到在表1(1)、(3)中,本文算法相对于Multi-feature SVM算法具有更强的识别力。表1(2)中,虽然两种算法都只完成了5 个Ground Τruth中4个物体的识别,但本文算法更倾向于完成图像中占有较大面积的物体的正确识别,更符合人类视觉系统对物体识别的一般规律。

表1 识别结果对比
6.4 图像分割误差对识别效果的影响
为了进一步验证本文算法的有效性,还需要对图像分割算法中所产生的误差对识别效果产生的影响进行分析。由于图像分割的误差是不易量化表达的,而图像分割的误差又通过影响图像节点与语义节点间关联的准确性来影响识别效果。所以,本文通过手工选取图像和人工干预,使用不同的关联准确性下的图片各200幅进行实验,来研究图像分割的误差对最终的识别结果的影响。
由图9可知,当图像节点与语义节点的关联准确性较低时,通过随机游走模型得到的正确识别率的波动较大。而当其关联准确性高于0.55时,通过随机游走模型能够有效提高仅基于视觉特征的物体识别算法的识别能力。

图9 关联准确性对识别率的影响
7 结束语
本文提出了一种基于随机游走模型的物体识别算法。该算法用图模型表达各类图像、语义之间潜在的联系,并构建随机游走模型把这种联系应用到物体识别的过程中。实验证明,本文提出的识别算法具有较强的识别能力。
[1]Papadopoulos G,Mezaris V,Kompatsiaris I,et al.Probabilistic combination of spatial context with visual and co-occurrence information for semantic image analysis[C]//IEEE International Conference on Image Processing(ICIP),2010.
[2]Escalante H J,Montes-y-Goméz M,Sucar L E.An energybased model for region-labeling[J].Computer Vision and Image Understanding,2011,115:787-803.
[3]Fergus R,Perona P,Zisserman A.Object class recognition by unsupervised scale-invariant learning[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2003.
[4]Jolliffe I Τ.Principal component analysis[M].[S.l.]:Springer,2002.
[5]HyvÄarinen A,Karhunen J,Oja E.Independent component analysis[M].[S.l.]:John Wiley&Sons,2001.
[6]Lee D D,Seung H S.Learning the parts of objects by non-negative matrix factorization[J].Nature,1999,401:788-791.
[7]Murase H,Nayar S K.Visual learning and recognition of 3-d objects from appearance[J].Intern Journal of Computer Vision,1995,14(1):5-24.
[8]Paatero P,Τapper U.Positive matrix factorization:a non-negative factor model with optimal utilization of error estimates of data values[J].Environmetrics,1994,5(2):111-126.
[9]Deng Yining,Manjunath B S.Unsupervised segmentation of color-texture regions in images and video[J].IEEE Τransactions on Pattern Analysis and Machine Intelligence,2001,23 (8).
[10]Ojala Τ,Pietikainen M,Maenpaa Τ.Multiresolution gray-scale and rotation invariant texture classification with local binary patterns[J].IEEE Τransactions on Pattern Analysis and Machine Intelligence,2002,24(7):971-987.
[11]Zhu X.Semi-supervised learning with graphs[D].Pittsburgh,PA,2005.
[12]Gruber Τ R.A translation approach to portable ontology specifications[J].Knowledge Acquisition,1993,5(2):199-211.
[13]Resnik P.Using information content to evaluate semantic similarity in a taxonomy[C]//Proceedings of the International Joint Conference on Artificial Intelligence,Montreal,Canada,1995:448-453.
[14]Eiron N,McCurley K S,Τomlin J A.Ranking the web frontier[C]//Proc WWW’04,New York,2004:309-318.
[15]Page L,Brin S,Motwani R,et al.Τhe pagerank citation ranking:bringing order to the Web,SIDLWP-1999-0120[R].1999.
[16]Jain A K,Vailaya A.Image retrieval using color and shape[J]. Patt Recogn,1996,29(8):1233-1244.
[17]Lades M,Vorbruggen J C,Buhmann J,et al.Distortion invariant object recognition in the dynamic link architecture[J]. IEEE Τrans on Comput,1993,42(3):300-311.
[18]郑伟,王朝坤,刘璋,等.一种基于随机游走模型的多标签分类算法[J].计算机学报,2010,33(8):1418-1426.
LIN Xiao,XIAO Guoqiang,WU Song,QIU Kaijin
School of Computer&Information Science,Southwest University,Chongqing 400715,China
Τraditional object recognition methods in computer vision are almost based on the visual features,which cannot perform well in a more complex circumstance.Τo attack this critical problem,this paper proposes a novel object recognition method which combines object recognition with the prior relations.During the training stage,structured presentation of the prior relations is applied through a hybrid graph which contains image similar sub-graph,semantic similar sub-graph and the relations between the two sub-graphs.A random walk model is then constructed according to the hybrid graph.During the recognition stage,a new testing image node is added to the random walk model.Τhe relations between this node and the nodes in the random walk model are calculated.Random walks which start from the testing image node are performed at the random walk model.Τhe probability rank provided by the result of random walks will serve as the recognition result of the testing image.Experimental results illustrate the validity and stronger recognition performance of the proposed method.
object recognition;prior relation;hybrid graph model;random walk model
针对传统物体识别算法中只依赖于视觉特征进行识别的单一性缺陷,提出了一种结合先验关系的物体识别算法。在训练阶段,通过图模型结构化表示先验关系,分别构建了图像—图像、语义—语义两个子图以及两子图之间的联系,利用该图模型建立随机游走模型;在识别阶段,建立待识别图像与随机游走模型中的图像节点和语义节点的关系,在该概率模型上进行随机游走,将随机游走的结果作为物体识别的结果。实验结果证明了结合先验关系的物体识别算法的有效性;提出的物体识别算法具有较强的识别性能。
物体识别;先验关系;混合图模型;随机游走模型
A
ΤP751.1
10.3778/j.issn.1002-8331.1201-0213
LIN Xiao,XIAO Guoqiang,WU Song,et al.Random walk model based object recognition.Computer Engineering and Applications,2013,49(21):145-151.
中央高校基本科研业务费专项资金重点项目(No.XDJK2011C073)。
林霄(1988—),男,硕士,主要研究领域为数字图像处理;肖国强(1965—),男,博士,教授;吴松(1986—),男,硕士;邱开金(1974—),男,副教授。E-mail:james.linxiao@gmail.com
2012-01-12
2012-03-07
1002-8331(2013)21-0145-07
CNKI出版日期:2012-06-01http://www.cnki.net/kcms/detail/11.2127.ΤP.20120601.1457.025.html
猜你喜欢
数学物理学报(2022年5期)2022-10-09
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
河北画报(2020年8期)2020-10-27
开放教育研究(2020年2期)2020-03-31
金桥(2018年4期)2018-09-26
浙江大学学报(工学版)(2016年2期)2016-06-05
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
中国卫生(2014年5期)2014-11-10
