
对随机投影算法的离群数据挖掘技术研究
2013-07-20 02:34李桥周莹莲黄胜马翔
计算机工程与应用 2013年24期
李桥,周莹莲,黄胜,马翔
湖南涉外经济学院信息科学与工程学院,长沙 410205
对随机投影算法的离群数据挖掘技术研究
李桥,周莹莲,黄胜,马翔
湖南涉外经济学院信息科学与工程学院,长沙 410205
1 引言
离群数据挖掘技术广泛应用于信用卡欺诈检测、网络流量入侵检测、视频监控异常行为检测等领域,因而成为数据挖掘领域的一项重要课题得到人们的深入研究。离群数据检测就是发现严重偏离数据总体分布范围的离群数据。由于与数据总体分布情况不同,因此这些数据可以看成是可疑数据。例如,对于信用卡诈骗检测问题,数据集包括卡片主人的交易信息。交易记录记载了每名用户消费行为的卡片使用情况。如果卡片被盗,用户消费行为往往会发生变化。如果交易记录消费额度高、消费频率高、消费项目重复,则可认定出现异常消费模式。
离群数据挖掘技术多应用于超高维数据领域[1]。例如,信用卡数据集交易记录有100多个属性。为了对视频监控进行异常行为轨迹检测,必须处理连续视频帧的超高维像素特征。由于众所周知的“维度灾难”问题[2],当前大多数算法都或多或少地需要在全维空间对欧几里德距离进行考察,因此效果欠佳。传统的基于距离[3]和基于密度[4]的离群数据检测算法,需要进行高维数据最近邻搜索,因此计算复杂度较大。此外,数据维度越高,最近邻和最远邻数据就越难以区分。此时,如果还是根据高维空间距离和最近邻概念来考察数据的相邻点,就会出现大部分数据都被判定为离群数据的情况[5]。
本文提出一种近线性时间算法,对各数据对象的角度方差进行近似。对d维空间的n组数据,本文算法的计算时间为O(nlbn(d+lbn)),可输出各数据对象角度方差非偏估计量。本文主要技术创新就是将随机超平面投影[6]和乘积域AMS Sketch[7]结合在一起,使得可以将原方法的三次方时间复杂度降低到本文近似方法的近线性复杂度。本文算法另一个优点就是支持并行处理。实际上,本文运行时间并行加速比可以达到准线性(根据使用的处理器数量而定)水平。还对近似方法进行了理论分析,以保证本文估计算法的可靠性。基于实际数据和仿真数据的实验表明,本文方法应用于超高维数据,效率高、可扩展性强。
2 相关工作
对离群数据挖掘,一个良好的离群指标是保证数据挖掘效果和效率的关键。人们提出了大量离群指标,包括全局和局部离群模型。一般而言,全局离群模型对总体数据加以考虑,局部离群模型只考虑各数据对象周边部分相邻区域。
Knox和Ng等人[8]定义了一种简单直观的基于距离的离群模型,该模型是数据库背景下最早提出的全局离群模型。参数k和λ条件下的离群数据是指距离λ范围内近邻数量少于k个的数据对象。文献[3]提出了另一种基于距离的算法,该算法将数据对象相对其第kth个最近邻数据的距离作为该对象的离群分值,然后将分值最高的m个对象作为离群程度最高的m个离群数据。为了避免嵌套循环最坏情况下的二次方计算复杂度问题,该文献提出了几种关键的优化方法。根据不同的修剪策略,这些优化方法可以分为多种类别,比如说近似最近邻搜索[3]、数据分区策略[3]和数据分级策略[9]。虽然这些优化方法可以带来一定程度的性能提升,但是可拓展性较差,尤其是当维度或数据规模变大或数据对象变得非常稀疏时,这些方法的效率将会显著下降。
全局模型在基于相邻数据点距离来检测离群数据时,考虑了整个数据集,而基于密度的局部模型根据相邻数据点密度来评估各数据对象的离群程度。在许多应用中,局部离群模型有多个优点,比如检测到不同密度的全局和局部离群数据,确定正常数据和异常数据间的分界线。这种类型的方法根据k-最近邻局部密度[10]或ε-近邻多粒度偏差[4]为每个数据对象分配一个局部离群因子来描述该对象的离群程度。实际上,这些方法都需要为每个数据对象寻找最近邻,经常使用索引数据结构来提升性能。因此,无法满足高维离群数据挖掘要求。
因为基于距离或最近邻数据的指标在高维空间中可能没有实质性意义,最近人们利用子空间投影方法进行离群分层[11]。换句话说,这些方法只将数据对象的部分属性作为子空间加以考虑。然而,这些方法要么难以选择有意义的子空间,要么存在计算复杂度随着数据维度呈指数增长问题。如上所述,Kriegel等人[5]为高维离群数据检测提出一种健壮的基于角度的考察指标。该方法根据数据对象与其他对象的角度差异来评估各数据对象的离群程度。数据对象与其他数据对象的角度差异越小,成为离群数据的概率越大。因为随着数据维度上升,数据对象间的角度频谱比距离更加稳定,因此该方法即使面对高维数据,性能也不会下降。然而,该方法的原型和近似方法的计算复杂度分别为三次方和二次方,均存在计算复杂度过高问题。
3 本文方法
3.1 基于角度的离群数据检测(ABOD)
如上所述,基于距离或近邻理念的高维数据离群挖掘模式是不可行的。文献[5]提出一种新的基于数据点角度差异的离群点检测算法,以降低“维度灾难”影响。图1显示了三种数据点的角度差异,其中Outlier是离群点;border point是边界点;inner point是内部点。可以看到,该群数据点中,边沿点和内部点的角度差异较大,离群点的角度差异较小。换句话说,一个点相对其他点的角度差异越小,该点为离群点的概率越大。这是因为位于群内的点被位于其他方向上的其他点包围,而群外的点只在部分方向上存在。因此,使用角度方差(VOA)作为离群因子来评估数据集中各点的离群程度。文献[5]方法没有直接提出角度方差,而是使用经过数据点相应距离加权的角度余弦方差代替。鉴于“维度灾难”影响,加权因子对高维数据的意义越来越低。希望对于高维数据,基于余弦谱方差的离群点分级(不论有没有加权因子)和基于角度频谱方差的离群点分级,能够展现出一定的相似性。因此,利用角度方差,定义了基于角度的离群因子:

很显然,VOA指标不含参数,因此适宜无监督离群检测算法。ABOD原型算法计算每个数据点的VOA,并返回VOA最小的m个点作为离群点。然而,原型算法的计算复杂度为O(dn3)。三次方的计算复杂度意味着超大规模数据集的离群点挖掘将会非常困难。

图1 不同类型的点的角度差异
3.2 算法主要思路
本文算法的主要思路是,高效计算出各数据点的角度方差无偏估计值。换句话说,估计的期望值等于角度方差,还将表明,角度方差围绕期望值分布。于是,这些估计值可用于对点分级。角度方差最小的m个点判定为数据集离群度最大的离群点。
为了估计某点与其他所有点的角度方差,首先将数据集投影到与随机向量(向量坐标从标准正态分布N(0,1)中随机选择)正交的超平面上。根据投影之后的数据分区,能够估计每个点的角度无偏期望值。然后,使用AMS Sketch估计二阶矩,得出方差及投影到随机超平面上数据点的频率矩的总体情况。将随机超平面投影和乘积域AMS Sketch结合在一起,可以将计算复杂度降低到O(nlbn(d+lbn))水平。接下来,将首先介绍随机超平面投影和AMS Sketch的基本概念,然后给出数据集各点角度方差估计算法。
3.3 随机超平面
依照文献[6],取随机向量r1,r2,…,rt∈Rd,其中各向量坐标从标准正态分布N(0,1)中独立选取。

对向量ri,只有当向量a-p和b-p位于与ri正交的超平面不同侧时,才有=1,且(a-p)·r<0。这种情况的概率与Θapb成正比,具体内容可参考文献[6]。更准确地,有:
引理1对所有:

Alon在文献[12]中描述并分析了一种称为AMS Sketch的近似方法,以估计高维向量的二阶频率矩:

最近,Indyk和McGregor[7]及Braverman等人[13]考虑了带有两个不同4维独立向量的AMS Sketch进行外积计算。于是,可以把矩阵看成矩阵元素向量,有:

3.4 ABOD近似
为避免出现三次方计算复杂度,根据随机超平面投影提出一种近线性时间算法,来估计各数据点角度方差。
3.4.1 一阶矩估计
设有随机向量r和点p∈S,估计MOA1(p),有:

需要指出的是,该值是p点和其他点角度期望无偏估计。通过使用t个随机投影来提高估计精度。于是,得到更精确的MOA1(p)无偏估计量:
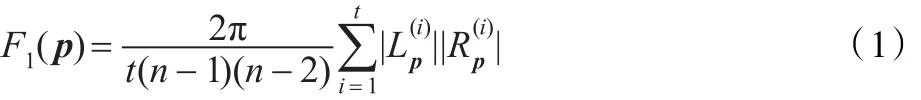
3.4.2 二阶矩估计
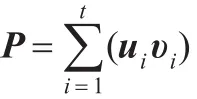

根据以上公式,可以估计MOA2(p)。
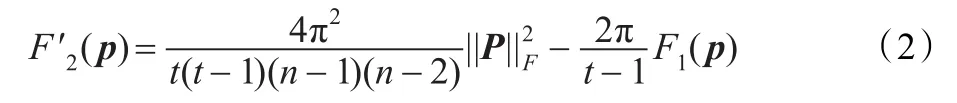
然而,无法在二次方时间内准确计算出Frobenius范式。于是,利用乘积域AMS Sketch来进行估计。设向量ui和υi的AMS Sketch分别为AMS()和AMS()(使用不同的4维独立随机向量)。由于存在线性关系,分布的和的sketch等于分布的sketch的和,因此有:
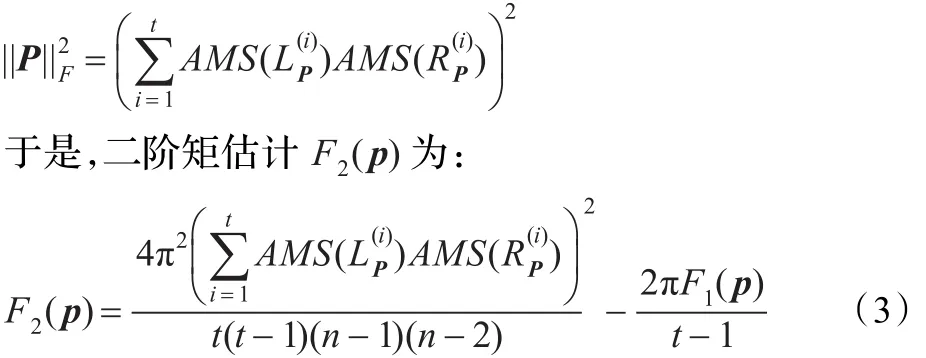
3.4.3 算法
上文讨论了如何计算点p的估计量MOA1(p)和MOA2(p),现在讨论近线性时间算法FastVOA,以估计数据集各点的角度方差。算法1伪代码描述了FastVOA的内容。

首先,将数据集投影到与随机投影向量正交的超平面上(算法2)。函数Random Projection()返回一个包含集合t次随机投影后分区信息的数据结构L。通过L,可以高效地确定点p和ri的对应值||和||。
算法2RandomProjection(S,t)


在算法3中,使用L计算各点p的Frobenius范数||P||F。为了提高AMS Sketch的精度,必须重复计算Frobenius-Norm()s1s2次,输出F2作为s2个随机变量Y1,Y2,…,Ys2的中位数,每个值均为s1个值的均值(第3~6行)。然后,第9~10行计算各点的二阶矩估计值和方差。
算法3FrobeniusNorm(L,t,n)

3.4.4 计算复杂度和并行处理
很明显,FastVOA的计算复杂度跟算法2、3有关。请注意,算法2在计算点积和对点分类时的计算复杂度为O(tn(d+lbn)),算法3复杂度为O(tn)。为了保证FastVOA的精度,特地使t=O(lbn)且s1s2足够大,以提高估计的精度,具体分析见第4章。因此,计算时间主要由AMS Sketch的计算时间决定。这意味着,FastVOA的计算时间为O(s1s2nlbn)。需要指出的是,算法2、3使用涉及t个随机向量的for循环,对每个随机向量执行相同的独立操作。因此,可以并行计算这三个算法中的循环,获得近线性加速效果(依使用的处理器数量而定)。
4 误差分析
前面已经论述,本文估计值是无偏的,可以获得合适的一阶和二阶矩E[F1(p)]=MOA1(p),E[F2(p)]=MOA2(p)。
本章对随机投影进行分析,并给出若要达到精度ε,需要的随机投影和AMS Sketch数量范围。角度方差估计时存在附加误差O(ε)。对MOA1(p),可以直接求得且概率较

一阶估计值:考虑F1(p)偏离MOA1(p)程度超过ε的概率(选择了向量r1,r2,…,rt)。将和值F1(p)t/π分成t项。于是,可以得出结论,偏离均值程度超过εt/π的概率最大为2e-2(εt/π)2/t。如果让t>ε-2π2ln(n),则该概率最大为2/n2。因此,所有n个一阶矩估计值达到最大误差ε的概率为1-O(1/n)。大;对MOA2(p),估计值F2(p)的基本成功概率只有3/4。然而,将二阶矩估计步骤重复s2=O(lb(1/δ))次,为各点设置中位离群分值,成功概率可提高到1-δ,其中δ>0,见文献[12]。

根据文献[14],使用以下切尔诺夫限,有:
最后,应该解释一下在等式(3)求解最终估计值F2(p)使用AMS sketch时引入的误差。估计值的方差最大为8MOA2(p)2。求取s1个sketch的均值,方差最大值被降低到8MOA2(p)2/s1。根据Chebychev不等式,F2(p)偏离期望值MOA2(p)程度达到MOA2(p)的概率最大为:
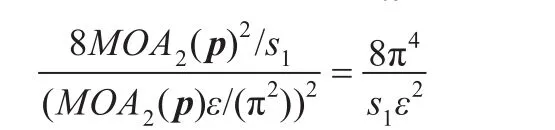
对s1>32π4/ε2,该概率小于1/4。可以证明,该偏离与F2(p)偏离2ε的情况相对应。如上所述,通过将估计过程重复s2次,可以让失效概率呈指数下降。
5 实验
所有算法用C++算法实现,利用合成和真实数据集,依托2.67 GHz core i7、3 GB RAM Windows平台进行。
5.1 数据集
为保证比较的公平性,使用与ABOD算法相同的合成数据生成方法[5]。生成的高斯数据包括5个平等加权的数据群,这些数据群正常点的均值和方差均随机生成,利用全维空间均匀分布作为离群点。对每个合成数据集,均生成与高斯数据群相独立的10个离群点,并利用不同规模和维度的合成数据集对各种算法进行性能评估。
选用3个实际数据集(Isolet,Multiple Features and Optical Digits),这3个实际数据集是UCI机器学习库为分类和机器学习任务设计的[15]。Isolet包括字母表26个字母的发音数据,其他两个数据集由手写数字(0~9)数据组成。对每个数据集,选择具有共同行为的某种类别的所有数据点作为正常点,从另一类选择10个数据点作为离群点。例如,选择Isolet数据集C,D,E类别都有“e”声的点作为正常点,选择Y类别10个点作为离群点。同样地,由于形状类似,选择Multiple Features 6,9类及Optical Digits 3,9类数据作为正常点,0类的10个数据点作为离群点。需要指出的是,很有可能部分离群点位于内点覆盖区域。因此,无法准确分离所有离群点。但是,希望本文算法能够将离群点划入顶级数据点范围。
5.2 估计精度

图25 个数据集基于随机投影的估计值的偏离误差
这一节讨论精度实验,以评估本文算法的可靠性。如第4章所述,如果随机投影次数t=O(lbn)和AMS Sketchs1s2足够大,则数据集任意点p的估计值,偏离期望值程度超过ε的概率最大为δ。请注意,F2(p)是基于AMS Sketch的二阶矩估计值,而F′2(p)只考虑了随机投影。开始时,通过实验来评估只基于随机投影的估计值精度。在概率δ=0.1条件下考察了F1(p)和F′2(p)偏离期望值的程度ε。设t范围[100,1 000],选取含有1 000个点的合成数据集Syn50(50维)和Syn100(100维),及3个真实数据集(Isolet,Mfeat,Digit)进行实验。图2(a)和图2(b)显示了误差概率δ=0.1条件下,估计值F1(p)和F′2(p)偏离期望值的程度(ε)。通过这两个估计值,求得了方差估计值,并考察了在δ=0.1条件下与期望值的偏离程度,见图2(c)。虽然理论分析表面,要让ε比较小,随机投影数量t必须要足够大,对5个数据集的实验数据表面,如果t很小,可以准确估计所有点的角度方差。在t=600时,5个数据集的90%的点,其一阶矩、二阶矩和方差估计值偏离期望值的最大误差分别为0.035,0.08,0.015。当t增加到1 000时,5个数据集的90%的点,其方差估计值偏离期望值的最大误差为0.01。因此,如果数据集的离群点和边界点的VOA差异较大,基于随机投影的VOA估计方法也可以取得较好的离群点检测效果。
为了对AMS Sketch带来的误差进行定量分析,利用AMS Sketches,并将所有数据集的参数设置为t=1 000,s1=7 200,s2=50,e=0.1,然后考察方差估计值的误差概率δ。具体来说,计算出数据集p点数量,基于AMS Sketch的方差估计值偏离期望值VOA(p)的误差将超过εVOA(p)。表1给出了5个数据集方差估计值的误差概率。

表1 5个数据集基于AMS Sketch的方差估计值的误差概率
很显然,合成数据集的误差非常小,而真实数据集的误差非常大,尤其是Isolet。这是因为使用AMS Sketch会导致数据集所有点的方差被过高或过低估计。为了保证本文离群点检测近似算法的可靠性,分析了SimpleVOA强力算法和FastVOA近似算法间的离群分级精度。离群分级精度被定义为|A∩B|/m,其中A和B分别是SimpleVOA和FastVOA算法返回的级别最高的m个点。图3显示了SimpleVOA和FastVOA算法的离群分级精度,其中m范围为10~100,横坐标是指顶级数据点数目,纵坐标是指分级精度。
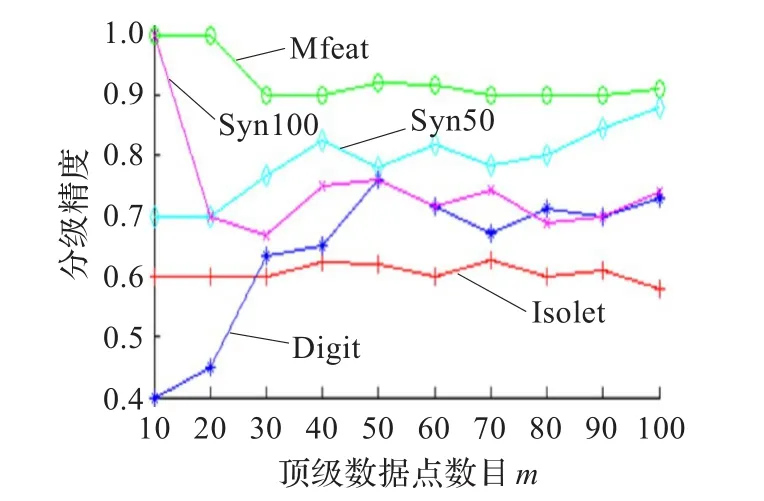
图3 SimpleVOA和FastVOA算法的离群分级精度
依据图2的离群分级精度分析结果表明,FastVOA算法在所有数据集合情况下的精度都非常高。不管m范围如何,2个合成数据集和Multiple Feature数据集的分级精度都比较高;而其他数据集当m<30时精度一般,当m>40时精度较高。虽然AMS Sketch会导致方差被过高或过低估计,FastVOA的数据点分级性能仍然出色。
5.3 有效性
很显然,本文方法直接处理角度方差(VOA),而文献[5]方法计算距离加权的角度余弦方差。本节实验将证明两个离群数据检测指标的有效性。用该两个指标来评估强力算法(SimpleVOA和ABOD)和近似算法(FastVOA and FastABOD)的离群分级质量。为了公平起见,使用精度检索图来评估各算法的最大似然离群点检测性能。精度水平是指算法判定的数据集离群点中真实离群点的数量,在各精度水平,定义检索率为算法判定的数据集离群点中真实离群点的百分比。
生成4个合成数据集,数据规模1 000和5 000点,维度50和100维。观察到,当合成数据的规模上升时,离群点和边界点的VOA方差变大。因此,对5 000点合成数据集,更改了FastVOA的参数设置,以降低时间复杂度。尤其地,设置t=100,s1=1 600,s2=10。在5.2节其他数据集,也沿用相同的参数设置。FastABOD的样本规模设为0.1n[5]。需要指出,ABOD和FastABOD在4个合成数据集上的表现非常完美。这意味着,所有10个离群点刚好都被评为10个顶级点。因此,没有给出ABOD和FastABOD在合成数据集的实验结果。图4给出了合成数据集的精度检索图。图4(a)显示了强力算法(SimpleVOA1和SimpleVOA2)和近似算法(FastVOA1和FastVOA2)在2个数据集(50维,1 000和5 000个点)上的性能。在50维时,VOA对小规模数据效果不佳,但是在大数据规模时性能极佳,总共11个顶级点里包括了全部10个离群点。很显然,SimpleVOA性能越高,FastVOA性能越高。图4(b)给出了2个100维合成数据集实验结果。由于ABOF加权因子在高维数据中的作用有限,SimpleVOA和FastVOA的实验结果与ABOD、FastABOD相当,性能也很显著。

图4 4个合成数据集的精度检索图
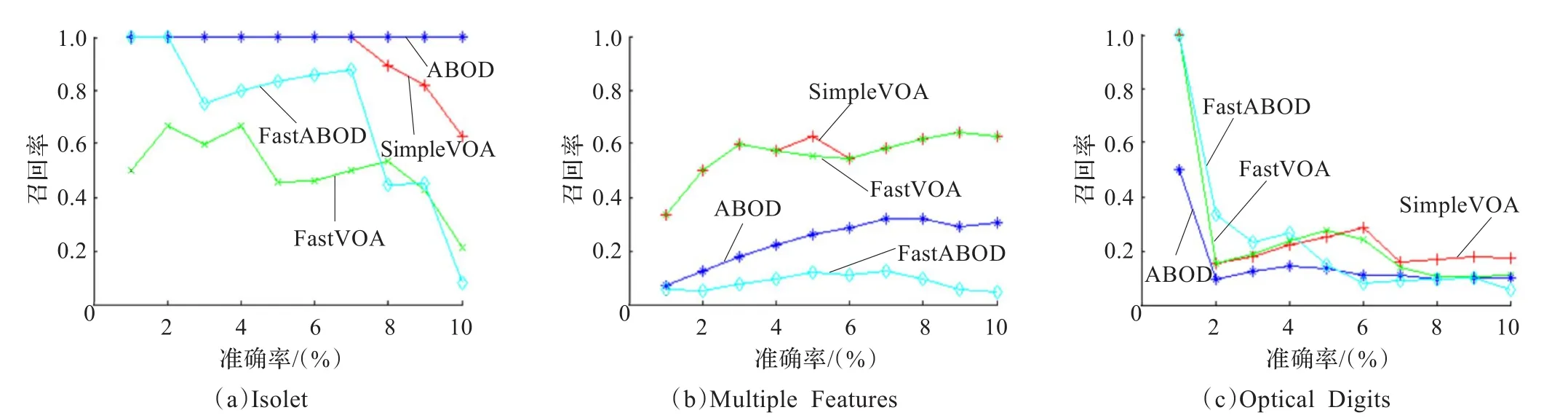
图5 3个真实数据集的精度检索图
图5显示了3个真实数据集的精度检索图。对Isolet数据集,SimpleVOA和ABOD的性能表现几近完美,10个和16个顶级数据点刚好包含了全部10个离群点。FastABOD的离群分级性能优于FastVOA,10个顶级数据点包含了7个离群点。然而,FastABOD和FastVOA两个算法在精度水平较高时性能欠佳。对Multiple Features数据集,SimpleVOA和FastVOA的性能表现非常出色,16个顶级数据点刚好包含了全部10个离群点,而ABOD和FastABOD算法性能欠佳。所有方法对Optical Digits数据集,离群点检测性能均不佳。尽管如此,基于VOA的方法性能明显优于基于ABOF的算法。
5.4效率
本节将对FastVOA,LB ABOD和FastABOD三种算法在超大维数据集上的运行时间进行比较。事实上,大部分高维数据集的离群点难以事先准确判定。因此,决定将这三个算法在合成数据集上运行。数据集规模10 000~100 000个点,维度100~1 000维,各算法运行时测量CPU运行时间。
很显然,LB ABOD和FastABOD的运行时间为O(dn2),FastVOA的计算时间主要依赖于参数t,s1,s2。如5.3节所示,对超高维合成数据集使用FastVOA算法时,即使将参数设置得非常小,也不会影响精度。因此,设置FastVOA算法的参数为t=100,s1=1 600,s2=10,FastABOF的样本规模设为0.1n。需要指出的是,0.1n的值当数据集规模增大时也会变得非常大。相反,FastVOA只需要很少量的随机投影和AMS Sketch规模。如3.4.4节分析,FastVOA的总体运行时间为O(tn(d+lbn+s1s2))。按照以上所述参数设置,FastVOA的总体运行时间主要由AMS Sketch计算时间(O(ts1s2n))决定。
图6(a)显示了100维10 000~100 000点数据集时Fast-VOA,LB ABOD和FastABOD算法的CPU时间(ms),图6(b)显示了100~1 000维20 000点数据集时的CPU时间。很显然,FastVOA的运行时间随着数据集的规模呈线性增长,与维数无关。相反,LB ABOD和FastABOD计算时间与数据规模呈二次方关系,与维数成线性关系。

图6 FastVOA,LB ABOD和FastABOD算法的CPU时间比较
最后,从FastVOA适宜并行处理角度来讨论其高效性。利用支持多平台内存共享和多处理器C++编程的Open Multi-Processing API(OpenMP)来并行处理3.4.3节算法2、3的随机投影向量for循环。在4核Core i7机上运行并衡量了并行加速效果。表2给出了100维10 000点合成数据集时FastVOA算法的近线性并行加速效果。

表2 FastVOA并行加速效果
6 结论
本文提出了一种基于随机投影的数据点角度方差估计算法,同时提出一种可靠的离群评分来检测高维离群现象。通过将随机投影与乘积域AMS Sketch相结合,本文近似算法的计算时间与数据集规模呈近线性关系,且适宜并行处理。本文还对近似质量作了理论分析,以保证近似算法的可靠性。基于合成数据和真实数据的实验表明,本文在对超高维数据集进行离群点检测时具有可拓展性强、效果好、效率高等特点。
[1]Wheeler R,Aitken S.Multiple algorithms for fraud detection[J]. Knowledge-Based Systems,2000,13(2):93-99.
[2]贺玲,蔡益朝,杨征.高维数据空间的一种网格划分方法[J].计算机工程与应用,2011,47(5):152-153.
[3]Angiulli F,Pizzuti C.Outlier mining in large high-dimensional data sets[J].IEEE Transactions on Knowledge and Data Engineering,2005,17(2):203-215.
[4]Papadimitriou S,Kitagawa H,Gibbons P B,et al.Loci:fast outlier detection using the local correlation integral[C]//Proceedings 19th International Conference on Data Engineering,2003:315-326.
[5]Kriegel H P,Zimek A.Angle-based outlier detection in highdimensional data[C]//Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2008:444-452.
[6]Charikar M S.Similarity estimation techniques from rounding algorithms[C]//Annual ACM Symposium on Theory of Computing,2002:380-388.
[7]Indyk P,McGregor A.Declaring independence via the sketchingofsketches[C]//ProceedingsoftheNineteenth Annual ACM-SIAM Symposium on Discrete Algorithms,2008:737-745.
[8]Knox E M,Ng R T.Algorithms for mining distance-based outliers in large datasets[C]//Proceedings of the International Conference on Very Large Data Bases,1998:392-403.
[9]Wang Y,Parthasarathy S,Tatikonda S.Locality sensitive outlier detection:a ranking driven approach[C]//IEEE 27th International Conference on Data Engineering(ICDE),2011:410-421.
[10]Breunig M M,Kriegel H P,Ng R T,et al.LOF:identifying density-based local outliers[J].ACM Sigmod Record,2000,29(2):93-104.
[11]Muller E,Schiffer M,Seidl T.Statistical selection of relevant subspace projections for outlier ranking[C]//IEEE 27th International Conference on Data Engineering(ICDE),2011:434-445.
[12]Alon N,Matias Y,Szegedy M.The space complexity of approximating the frequency moments[C]//Proceedings of the Twenty-Eighth Annual ACM Symposium on Theory of Computing,1996:20-29.
[13]Braverman V,Chung K M,Liu Z,et al.AMS without 4-wise independence on product domains[C]//Proceedings of STACS’10,2008:119-130.
[14]Dubhashi D,Panconesi A.Concentration of measure for the analysis of randomized algorithms[M].Cambridge:Cambridge University Press,2009.
[15]Frank A,Asuncion A.UCI machine learning repository[EB/OL]. [2013-03-30].http://archive.ics.uci.edu/ml.
LI Qiao,ZHOU Yinglian,HUANG Sheng,MA Xiang
School of Information Science and Engineering,Hunan International Economics University,Changsha 410205,China
Outlier mining ind-dimensional point sets is currently one of the hot areas of data mining.The current outlier mining approaches based on the distance or the nearest neighbor result in the poor mining results.To solve this problem,this paper investigates the use of angle-based outlier factor in mining high dimensional outliers.It proposes a novel random projection-based technique that is able to estimate the angle-based outlier factor for all data points in time near-linear in the size of the data.Also,the approach is suitable to be performed in parallel environment to achieve a parallel speedup.It introduces a theoretical analysis of the quality of approximation to guarantee the reliability of the algorithm.The empirical experiments on synthetic and real world data sets demonstrate that the approach is efficient and scalable to very large high-dimensional data sets.
outlier data mining;angle;random projection algorithm;near-linear time;reliability;efficiency
d维点集离群数据挖掘技术是目前数据挖掘领域的研究热点之一。当前基于距离或最近邻概念进行离群数据挖掘时,在高维数据情况下的挖掘效果不佳,鉴于此,将基于角度的离群因子应用到高维离群数据挖掘中,提出一种新的基于随机投影算法的离群数据挖掘方案,它只需要用接近线性时间的方法就能预测所有数据点的基于角度的离群因子。该方法可以用于并行环境进行并行加速。对近似质量进行了理论分析,以保证算法的可靠性。合成和真实数据集实验结果表明,对超高维数据集,该方法效率高、可伸缩性强。
离群数据挖掘;角度;随机投影算法;接近线性时间;可靠性;效率
A
TP391
10.3778/j.issn.1002-8331.1305-0442
LI Qiao,ZHOU Yinglian,HUANG Sheng,et al.Random projection algorithm for outlier mining technology research. Computer Engineering and Applications,2013,49(24):122-129.
2011年湖南省教育厅科学研究项目(No.11C0784)。
李桥(1979—),讲师,主要研究方向:数据挖掘,嵌入式及应用;周莹莲(1974—),女,硕士,主要研究方向:社会网络,数据挖掘。
2013-05-31
2013-08-07
1002-8331(2013)24-0122-08
猜你喜欢
中学生数理化·高一版(2019年12期)2019-12-31
中国惯性技术学报(2019年6期)2019-03-04
当代石油石化(2018年1期)2018-08-10
中国钢铁业(2018年6期)2018-07-26
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
中国房地产业(2016年9期)2016-03-01
火控雷达技术(2016年3期)2016-02-06
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
西安交通大学学报(2014年8期)2014-04-16
上海电机学院学报(2014年3期)2014-02-28
