
改进的遗传算法在优化BP网络权值中的应用
2013-07-20 02:33姚明海
计算机工程与应用 2013年24期
姚明海
1.渤海大学信息科学与技术学院,辽宁锦州 121013
2.东北师范大学数学与统计学院,长春 130024
改进的遗传算法在优化BP网络权值中的应用
姚明海
1.渤海大学信息科学与技术学院,辽宁锦州 121013
2.东北师范大学数学与统计学院,长春 130024
神经网络是随着神经生物学的发展而发展起来的一个领域,人工神经网络(Artificial Neural Network,ANN)是在人类对其大脑神经网络认识理解的基础上构造的能够实现某种功能的神经网络。由于人工神经网络具有高度的并行性、分布式存储、自适应学习能力等特点,已经广泛应用于模式识别、人工智能、预测、评价、信号处理及非线性控制等领域[1-3]。其中以BP神经网络的应用最为广泛。BP神经网络具有网络结构简单、工作状态稳定及自学习能力等优点。尽管如此,仍然存在着一些问题。如学习算法的收敛速度慢、易陷入局部极小值等问题。而遗传算法恰恰能够解决这些问题。遗传算法既可以避免陷入局部最小,又可以加快收敛速度。但是,以标准遗传算法[4]、小生境遗传算法[5]、量子遗传算法[6]、混合遗传算法[7]为代表的经典模型在遗传操作方面,先通过选择算子从父代群体P(t)中选择出具有相同特征的染色体构成交配池,然后交配池中的染色体通过交叉操作生成新的群体P(t+1),最后用新群体P(t+1)淘汰父代群体P(t)。也就是说,经典模型在迭代运算过程中,只有属于同代的染色体才有可能进行交叉操作。但是,从遗传学的角度来看,同代染色体遗传操作产生的后代不一定就具有遗传优势,交叉产生的新种群中不一定有优于父代染色体群中的最优个体。相反,很可能造成算法的过早收敛。因此,本文提出新的交叉操作过程。从初始种群开始对最优的染色体进行保存,通过保存的父代最优染色体与子代进行交叉操作,然后在保存的父代最优染色体和新产生的种群中选择最优的个体进行保存。从而保证最优染色体始终参与遗传操作。这样在满足选择算子约束的条件下,保证了遗传操作是围绕最优个体进行的,提高了算法的搜索速度。从实验结果来看,同代交叉的约束条件在很多情况下会使群体的多样性迅速降低,从而使遗传算法过早丧失了进化的能力。而采用父代最优个体参与遗传操作的方法很好地避免了传统算法中存在的这些问题。
1 BP神经网络
BP网络是一种多层的网络[8],一般由一个输入层,一个或多个隐含层(也称中间层)和一个输出层构成。各层之间实行全连接,同一层内的神经元无连接,图1表示了仅具有一个隐含层的三层BP神经网络结构图。输入层节点数为n,隐层节点数为l,输出层节点数为m(各层的节点数可以根据实际样本的情况进行设定)。输入为X=(x1,x2,…,xn)′,输入层到隐层的权值为W1=(w1ij)n×l,隐层阈值为B= (b1,b2,…,bl)′,隐层到输出层的权值为W2=(w2ij)l×m,输出层阈值为S=(s1,s2,…,sm)′,输出为Y=(y1,y2,…,ym)′。
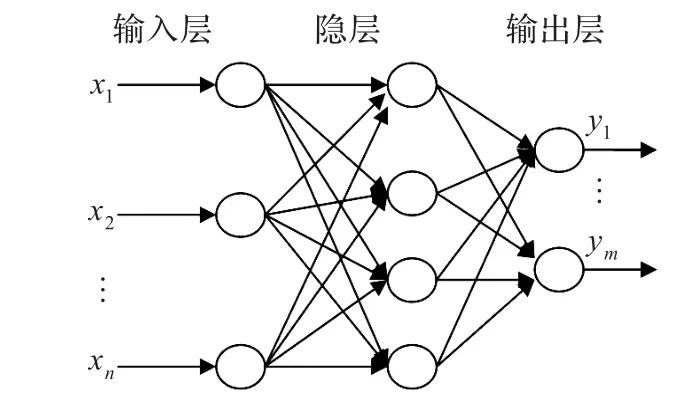
图1 三层网络结构
BP神经网络中隐层神经元转移函数一般有阶跃函数、准线性函数、Sigmoid函数和双正切函数等,本文采用的转移函数为Sigmoid函数。其表达式如下:

2 改进的遗传算法
到目前为止还没有任何证据能证明同代遗传比隔代遗传更好,并且同代遗传很容易降低种群的多样性,使整个算法过早丧失进化能力。因此,本文提出了一种改进的遗传算法。即:采用隔代遗传的方式,在初始染色体池T中选择最优染色体Tmax,然后通过Tmax与初始染色体池中的染色体进行交叉,产生新的种群。在新种群中对所有染色体进行排序,选择最好的染色体Tmax'与Tmax进行比较,如果优于Tmax则用Tmax'替换Tmax。同时,在新的种群中选择较好的部分生成新的染色体池T′,用T′替换原有染色体池T。在该迭代过程中要根据一定的概率对部分染色体进行变异操作。如此迭代,直到满足结束条件为止。
2.1 染色体编码
遗传算法采用编码来代替问题参数,在所有的实际问题表示方式与编码位串之间必须构成一一对应关系,同时在运算过程需要进行多次编码和解码操作。针对BP神经网络的权值优化问题,本文采用的是实数编码的方式,对网络中每一层的权值和阈值进行编码。将表示BP网络权值和阈值的多维矩阵W1,B,W2,S采用一维矩阵的形式表示,这里,染色体的每一个基因代表网络中的一个权值或阈值。以图1的三层网络机构为例,其编码形式如下:

2.2 产生初始种群和局部最优染色体Tmax
BP神经网络的初始权值取均匀分布的(-1,1)之间的随机数小数。染色体长度为L=W1+B+W2+S+1。每条染色体的最后一位为该染色体的适应值,在遗传操作中,该位不参与交叉、变异等操作。这里使用初始种群函数Initalizega()来生成初始染色体池和局部最优染色体Tmax。具体函数如下:

这里T为初始染色体群,Tmax为初始染色体群T中的最优染色体,Psize为初始种群的规模,aa为染色体中每个基因的取值范围,gabpEbal为适应度函数。
2.3 选择算子
遗传算法中的选择是指在整个群体中寻找适应度较高的个体去生成初始的交配池。最常用的选择方法有适应比例选择、最佳保留选择、排序选择和期望值选择。本文采用的是适应比例选择,利用个体的适应值与整个群体的平均适应值的比例进行选择。先计算群体中每个个体的适应值,然后看该适应值在总群体适应值中所占的比例,所占的比例越大被选中的概率就越大。反之,概率就越小。
对于给定的规模为n的群体P={a1,a2,…,an},个体aj∈P的适应值为f(aj),其选择概率为:
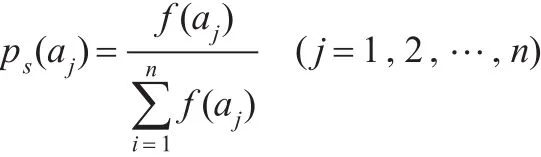
2.4 适应度函数gabpEbal()
遗传算法是通过适应度函数来进行模拟生物的“适者生存”机制的。在遗传算法中通过适应度函数计算个体的适应值,通过个体的适应值大小来体现个体在群体中的差异程度,进而确定该个体有没有权利作为父本进行新一代的遗传操作。遗传算法的适应度函数(本文中是针对BP神经网络的性能评价函数)也是遗传算法指导搜索的唯一标准,它的选取是算法好坏的关键。适应度函数要能有效地指导搜索沿着面向优化参数组合的方向,逐渐逼近最优解,并能保证不会导致搜索不收敛和陷入局部最优。针对BP神经网络,训练误差越小则染色体越优。所以,本文采用所有个体与对应的所有目标样本的误差平方和的倒数作为染色体的适应值。具体函数如下:[fitness]=gabpEbal(T),这里fitness为染色体的适应值。在计算神经网络的输出值时,对每个染色体进行解码,计算神经网络中对应神经元的各个权值W1,W2和阈值B,S,按公式(4)计算出每个样本的对应网络输出值矩阵Y。


2.5 交叉算子
遗传算法中交叉操作的目的是为了能够在下一代产生新的个体。通过交叉重组操作,遗传算法的搜索能力得以飞跃地提高。在遗传算法中将染色体进行交叉重组是获取新的优良个体的主要方法。同时交叉操作对遗传算法的质量也具有非常重要的影响。因此本文选取父代最优解Tmax与子代染色体池进行交叉操作,从而避免算法过早丧失进化能力。常用的交叉方法有一点交叉、两点交叉、多点交叉和一致交叉等,本文采用的是多点位单基因交叉的方式。具体算法如下:

2.6 变异算子
变异运算中变异率通常取pm=0.1,在单个染色体为Ti=(ti1,ti2,…,tiL-1)上随机选择第k个基因tik,对tik加一个小的扰动,实现染色体的变异。由于采用了最优个体Tmax保留的策略,所以在变异运算中,可以加大在当前最优个体附近进行搜索的概率以求得更优解,而不用担心破坏已经存在的优良染色体。因此,取种群中较好的一部分染色体进行变异操作。
3 数据预处理及算法流程
3.1 数据的归一化处理
在数据计算中样本的属性具有多样性,某些属性之间量级上有较大的差异,这些数据的不均衡将导致在网络训练过程中,部分属性特征不能被充分体现,甚至可能会导致网络的不收敛。因此,在进行网络训练和识别之前,需要对原始数据进行适当的预处理,使其更适合于神经网络的训练。这里采用的是数据归一化的方法。该方法就是将训练样本的输入数据和目标数据进行变换,让数据分布在[-1,1]的区间上。归一化函数采用的是premnmx()函数。具体公式:
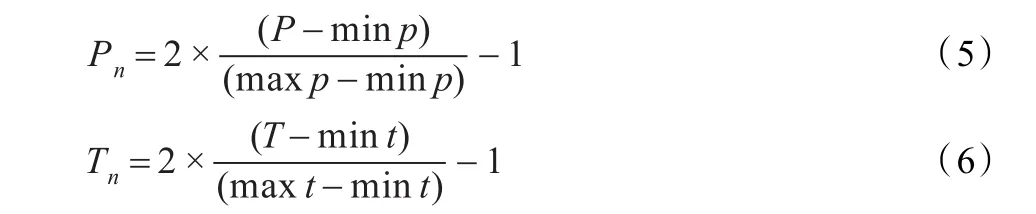
这里,P为原始的输入数据,maxp和minp分别是P中的最大值和最小值,Pn为经过归一化处理后的输入数据。T为原始的目标数据,maxt和mint分别代表目标数据T中的最大值和最小值,Tn为经过归一化处理后的目标数据。
3.2 算法基本流程及基本框架
改进遗传算法优化神经网络权值基本流程如图2所示。

图2 算法流程图
算法框架:
(1)给定样本数据对数据进行归一化处理。
(2)建立网络。
(3)根据网络神经元数量确定编码长度。
(4)初始化群体,选择局部最优染色体Tmax。
(5)调用适应度函数,评价网络性能,满足约束条件退出并保存网络。
(6)数据交叉操作,并保存最优染色体。
(7)利用适应比例法选择染色体。
(8)判断是否进行变异操作。
(9)返回到(5)。
4 仿真实验

图3 传统算法适应值曲线(wine)
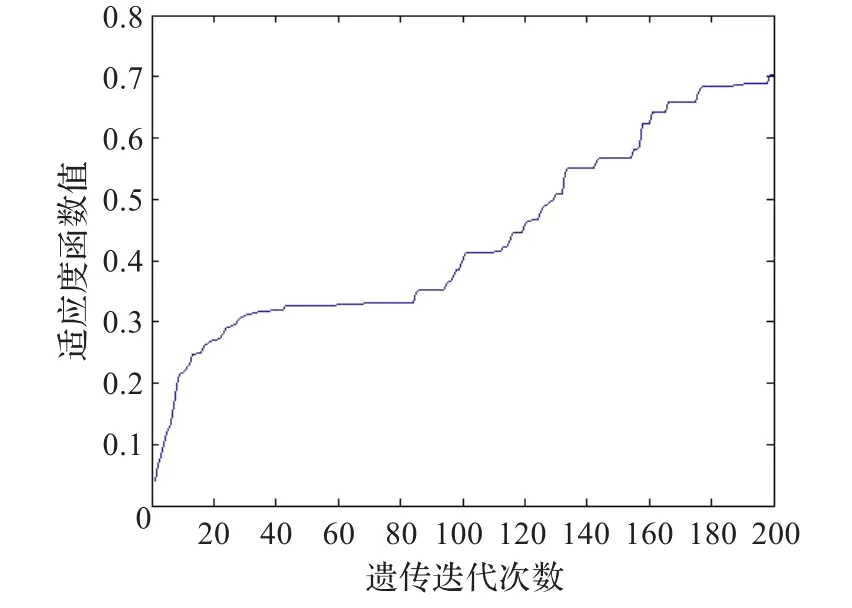
图4 改进算法适应值曲线(wine)
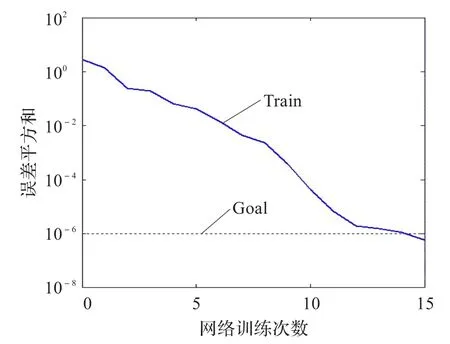
图5 传统算法网络训练(wine)
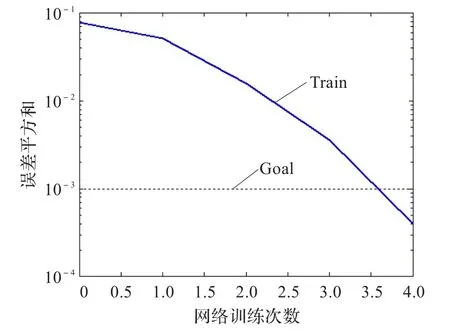
图6 改进算法网络训练(wine)

图7 传统算法适应值曲线(letter)
为了检验算法的性能,本文采用UCI数据库[9]中标准数据集wine、letter-recognition、glass和yeast数据集进行了算法验证,并在相同迭代次数下对传统算法与改进算法的适应度函数值进行了比较(实验环境:CPU为Celeron1.6,内存1 GB,操作系统Windows XP,编程语言Matlab2009)。
实验1采用的是wine数据,由于数据量较少,所以网络训练的收敛速度较快。如图3和图4所示分别是在迭代200次时传统算法与改进算法的适应值变化曲线。从适应值的变化来看改进算法明显优于传统算法,在同样迭代200次时,改进算法的适应值达到了0.7左右,而传统算法仅达到0.2左右。图5和图6为两种算法的网络收敛次数曲线,相同条件下改进算法的网络训练次数明显低于传统算法。
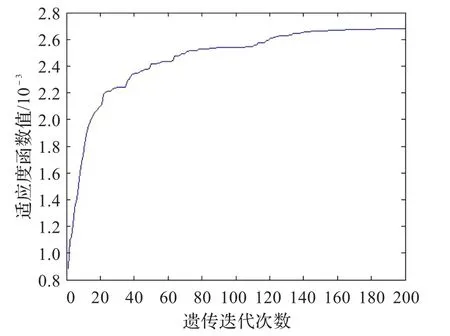
图8 改进算法适应值曲线(letter)
实验2采用的是letter-recognition数据,从26类数据中选取每类200个样本进行训练。如图7和图8所示分别是在迭代200次时传统算法与改进算法的适应值变化曲线。传统算法和改进算法的网络训练效果如图9和图10所示。
实验3采用的是glass数据。适应值变化曲线及网络训练效果如图11~14所示。
实验4采用的是yeast数据。适应值变化曲线及网络训练效果如图15~18所示。
5 小结
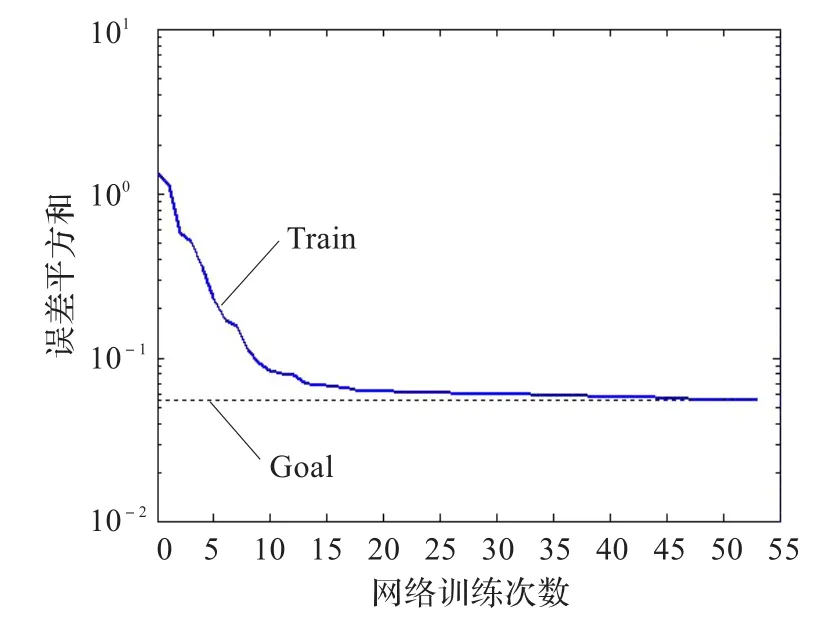
图9 传统算法网络训练(letter)

图10 改进算法网络训练(letter)
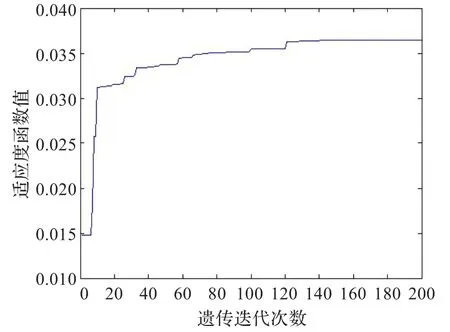
图11 传统算法适应值曲线(glass)

图12 改进算法适应值曲线(glass)

图13 传统算法网络训练(glass)
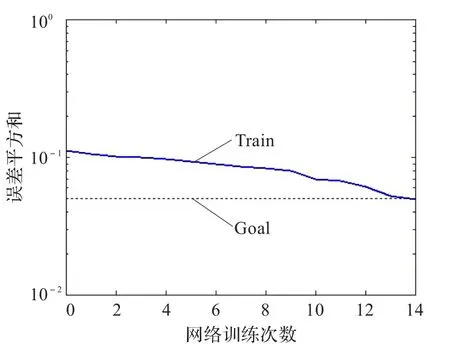
图14 改进算法网络训练(glass)

图15 传统算法适应值曲线(yeast)
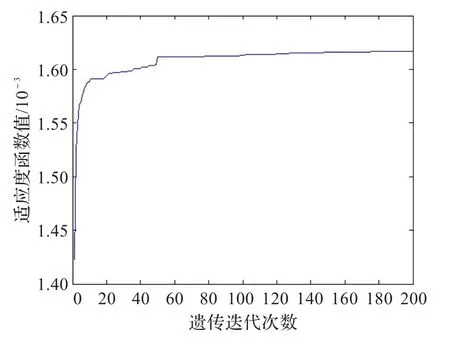
图16 改进算法适应值曲线(yeast)
遗传算法在优化问题的处理上应用非常广泛,用遗传算法优化神经网络权值问题也非常普遍。但是,大多数的遗传算法都避免不了同代交叉所导致的过早收敛问题,本文提出的改进遗传算法避免了这种问题。将该算法的全局搜索优势与BP神经网络收敛速度快的优势相互结合,更好地提高了BP神经网络的收敛速度,加快了网络的训练进程。为解决一些分类和主成分分析等实际问题提供了一种较好的方法。从实验的效果也可以看出,该算法对样本量较大的数据效果更为明显。该方法在处理连续数据效果非常好。但是,在处理离散数据方面还存在一些问题,还需要进一步的改进。
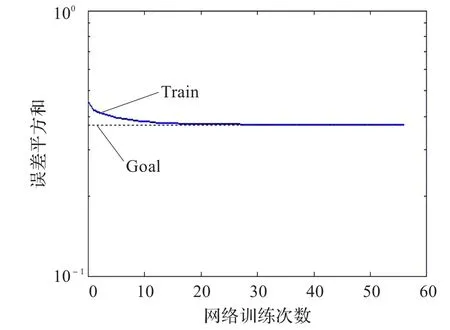
图17 传统算法网络训练(yeast)
图18 改进算法网络训练(yeast)
[1]张毅,杨建国.基于灰色神经网络的机床热误差建模[J].上海交通大学学报,2011,45(11):1581-1585.
[2]黄伟,何晔,夏晖.基于小波神经网络的IP网络流量预测[J].计算机科学,2011,38(10):296-298.
[3]聂鹏,谌鑫.基于主元分析和BP神经网络对刀具VB值预测[J].北京航空航天大学学报,2011,37(3):344-367.
[4]任昊南.用遗传算法求解TSP问题[D].济南:山东大学,2008.
[5]Jelasity M,Dombi T.GAS,a concept on modeling species in genetic algorithm[J].Artificial Intelligence,1998,99(1):1-19.
[6]Han K H,Kim J H.Quantum-inspired evolutionary algorithms with a new termination criterion,Hεgate,and two-phase scheme[J].IEEE Trans on Evolutionary Computation,2004,8(2):156-169.
[7]Tsai C F,Tsai C W,Tseng C C.A new hybrid heuristic approach for solving large traveling salesman problem[J].Information Sciences,2004,166(1):67-81.
[8]徐璘俊,杨建刚.基于多层神经网络的洗钱风险评估方法[J].计算机工程,2011,36(22):181-183.
[9]Merz C J,Murphy P M.UCI repository of machine learning databases[EB/OL].[2012-03-01].http://www.ics.uci.edu/~mlearn/ MLRepository.html.
YAO Minghai
1.College of Information Science and Technology,Bohai University,Jinzhou,Liaoning 121013,China
2.School of Mathematics and Statistics,Northeast Normal University,Changchun 130024,China
The characteristics of genetic algorithm and BP neural networks are compared.As evolutionary algorithm neural network and genetic algorithm have same goal but they have different methods.The necessity of the combination genetic algorithm and neural networks is expounded.This paper puts forward a kind of improved genetic algorithm to optimize BP neural network weights,using the global random searching ability of genetic algorithm to make up the question that neural network is easy to fall into local optimal solution.At the same time,the crossover method of genetic algorithm is changed.The same generation does not cross.The parent and son are crossed.Genetic algorithm premature loss of evolutionary ability is averted.
genetic algorithm;neural networks;optimization;weight;optimal solution
对遗传算法和BP神经网络的特点进行了比较,作为进化算法神经网络与遗传算法的目标相近而方法各异。阐述了遗传算法与神经网络结合的必要性。提出了一种改进的遗传算法优化BP神经网络的权值,用遗传算法的全局随机搜索能力弥补了神经网络容易陷入局部最优解的问题。同时,在遗传算法中改变传统的同代交叉机制,采用父代与子代进行交叉,避免了遗传算法过早丧失进化能力。
遗传算法;神经网络;优化;权值;最优解
A
TP301.6
10.3778/j.issn.1002-8331.1204-0762
YAO Minghai.Application of improved genetic algorithm in optimizing BP neural networks weights.Computer Engineering and Applications,2013,49(24):49-54.
辽宁省教育科学规划项目(No.JG10DB129)。
姚明海(1980—),男,博士研究生,讲师,主要研究方向:模式识别和智能计算。E-mail:yao_ming_hai@163.com
2012-05-09
2012-06-28
1002-8331(2013)24-0049-06
CNKI出版日期:2012-08-01http://www.cnki.net/kcms/detail/11.2127.TP.20120801.1652.017.html
◎网络、通信、安全◎
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
初中生世界·八年级(2019年6期)2019-08-13
科学之谜(2019年3期)2019-03-28
科学之谜(2018年8期)2018-09-29
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
恋爱婚姻家庭·养生版(2016年9期)2016-09-07
小学生导刊(低年级)(2016年6期)2016-07-02
计算机工程(2015年8期)2015-07-03
