
分组Apriori 在图书借阅系统中的应用研究
2013-07-20 09:40司贯中
微处理机 2013年2期
司贯中,刘 旸
(辽宁石油化工大学计算机与通讯工程学院,抚顺 113001)
1 引言
数据库技术和网络技术的快速发展,带来了信息量的爆炸式增长,这些海量数据给人们带来便利的同时,也产生了一些新的问题[1]:①信息数量的增长和对信息的消化能力不匹配,导致信息难以消化;②海量信息中存在大量的虚假无用垃圾信息,对信息的有效利用造成障碍;③信息的组织形式和存储格式没有统一标准,难以统一处理;④信息安全很难得到切实保证。面对这种“信息爆炸、知识贫乏”的困境,如何才能够能获取海量数据背后隐藏的知识、提高数据的利用率呢?正是在这种背景下,数据挖掘技术应运而生,它具有强大的生命力,迅速在各个领域得到成功应用。数据挖掘[2]即从大量的、不完全的、有噪声的数据中,挖掘出隐含的、事先未知的、潜在的对决策者有用的信息和知识的过程。
数据挖掘技术[3]可以粗略地分为统计分析、分类、聚类、关联规则、决策树以及神经网络。其中关联规则挖掘是数据挖掘的一个重要分支,它通过使用机器学习技术从复杂的、不精确的大量数据中推导其真正含义,并能够检测提取出数据中的趋势和模式。
2 Apriori 算法
2.1 关联规则基本模型
IBM 公司Almaden 研究中心的R.Agrawal[4]首先提出关联规则模型,并给出了求解算法,随后相关学 者 提 出 了SETM 和Apriori 算 法,其 中,Apriori是关联规则算法的基础,也是最经典的算法之一。
设I={I1,I2,...,Im}为所有项目的集合,D 表示事务数据库,事务T是一个项目子集(T⊆I)。每一个事务都用唯一的事务标识TID 来表示。设A是一个由项目构成的集合,称为项集。事务T 包含项集A,当且仅当A⊆T。关联规则是形如X⇒Y的蕴含式,其中X 和Y是项集,且X⊂I,Y⊂I,X∩Y=Ø。X 称为规则前项(通常也叫左项),Y 称为规则后项(通常也叫右项)。关联规则X⇒Y的支持度s是数据库中包含X∪Y的事务占全部事务的百分比,它是概率P(X∪Y)。关联规则X⇒Y的置信度c是包含X∪Y的事务数与包含X的事务数的比值,它是条件概率P(Y|X)。
在进行关联规则数据挖掘之前,由用户预先设定最小支持度阈值(min_sup)和最小置信度阈值(min_conf)。那些支持度大于等于min_sup 并且置信度大于等于min_conf的规则称为强关联规则。如果某些项集的支持度大于等于设定的最小支持度阈值min_sup,称这个项集为频繁项集(也称为大项集,Large Item Sets)。所有的“频繁k-项集”组成的集合一般记为LK。
关联规则挖掘过程主要包含两个阶段:第一阶段先从数据集中找出所有的频繁项集,它们的支持度都大于等于最小支持度阈值min_sup;第二阶段由这些频繁项集产生关联规则,计算他们的置信度,删掉那些置信度小于最小置信度阈值min_conf的关联规则。
2.2 Apriori 算法原理和算法描述
性质1:频繁项集的子集必为频繁项集。
性质2:非频繁项集的超集一定是非频繁的。
Apriori 算法利用性质1,通过已知的频繁项集来构成更大的项集,并将它称为潜在频繁项集。然后计算潜在频繁项集的支持度。具体实现过程如下:
(1)从头到尾扫描整个事务数据库D,计算每一个1 项集的支持度,从而得到频繁1 项集构成的集合L1。
(2)连接:若p,q∈Lk-1,p={p1,p2,...,pk-2,pk-1},q={q1,q2,...qk-2,qk-1},当1≤i p k-1时,p1=qi,当i=k-1,qk-1≠pk-1,则p∪q={p1,p2,...pk-2,pk-1,qk-1}是潜在频繁k 项集的集合ck中的元素。
(3)剪枝:潜在k 项集的某个(k-1)子集不是Lk-1中的成员时,该潜在频繁项集不可能是频繁的(见性质2),所以从Ck中删掉。
(4)扫描事务数据库D,计算Ck中各个项集的支持度。
(5)将Ck中不满足最小支持度阈值的项集删除,形成由频繁k 项集构成的集合Lk。
(6)迭代循环,重复上面的步骤(2)-(5),直到不能产生新的频繁项集的集合为止。
2.3 Apriori 算法实现
整个算法由两部分组成:Apriori 算法和Apriori-gen 算法[5]。

3 基于分组技术的Apriori 改进
Apriori 算法的优点[6]是显而易见的,它以递归迭代为基础生成频繁项集,思路简单,容易实现。但同时也暴露了致命的缺点[7]:①对数据库的频繁扫描,在每一次循环中都要扫描数据库,这造成相当大的I/O 开销;②产生了大量的潜在候选项集。
针对Apriori 算法的不足,着力从两个方面来改善这个算法,提高算法执行的效率。针对缺点一,采取数据库分组的方法减少扫描数据库记录的次数,减小了I/O 开销。对于缺点二,我们采取先剪枝再连接的方法;经典Apriori是先连接再剪枝,而分组Apriori 算法是先剪枝再连接,相当于减小了连接前的基数,删掉了那些非频繁项集,所以能够有效的减少连接次数,从而增强了算法效率。
3.1 算法思想
(1)数据库分组压缩
在数据库进行第一次扫描的时候,对每个项的出现次数进行计数,产生1-项候选集C1,然后根据事务中项的最大数对事务数据库D 进行分组,也就是说有i个项的事务集合记为Di,从而把事务数据库D 分为了N个组D1,D2,...,DN(N是包含最大项的个数)。当由频繁1-项集L1产生候选2-项候选集C2,对C2的每个候选项计数时,不必扫描整个数据库D,而是只扫描D2到DN。以此类推,每次扫描的记录数都在减少。
(2)先剪枝再连接
在Lk-1与自身进行连接时,对于符合条件l1[j]=l2[j ](j=1,2,...,k- 2)且l1[k-1]p l2[k-1]的l1和l2,需要先判断{l1[k-1],l2[k-1]}是否在l2中,再决定是否进行连接操作。要判断{l1[k-1],l2[k-1]}是否在L2中,需要扫描L2。本算法在生成L2的时候对L2进行了再次划分,L2i1,L2i2...L2im,其中L2ij(j=1,2,...lm)中的元素{A,B}满足A=ij,这样在判断{l1[k-1],l2[k-1]}是不是在L2中时,只需要扫描L2i1[k-1]。
3.2 算法流程
输入:I 基本项目集合
D //事务数据库
s //支持度阈值
输出:L 频繁项集
(1)扫描数据库D,把事务中项的数目等于J的事务放入DJ中,同时对C1所有项出现的次数进行计数,然后和最小支持度阈值进行比较,决定哪些项需要删除,生成频繁1-项集L1。
(2)把频繁1-项集L1中满足条件l1[1]p l2[1]的l1和l2连接,生成2-项候选集C2。从D2开始一直扫描到Dm,对C2中出现的每项进行计数,将满足最小支持度并且第一项为ij的放入L2IJ。
(3)对于L2IJ中所有满足条件(l1[2]p l2[2]的l1和l2,将它们的第二项组成项集{l1[2],l2[2]},然后扫描L2l1[2],判断{l1[2],l2[2]}是否在l2l1[2],如果在,就连接l1和l2,将结果放入候选的3-项集C3中,否则不进行连接操作。
(4)对于频繁(k-1)-项集LK-1中符合条件的所有l1[j]=l2[j](j=1,2,...,k-2)且(l1[k-1]p l2[k-1])的l1和l2,将它们的K-1 项组成基集{l1[k-1],l2[k-1]},然后再扫描L2l1[k-1],判断{l1[k-1],l2[k-1]}是不是在L2l1[k-1],如果在,就连接l1和l2,并将结果放入k-项候选集CK中,如果不在,不进行连接操作。
(5)从DK扫描到DM,对k-项候选集CK中所有项出现次数计数,把大于等于最小支持度min_sup的项放入LK。
(6)一直循环重复第四步和第五步,直到不能产生新的频繁项集为止,此时,算法结束。
4 分组Apriori 算法在图书借阅系统中的应用
数字化图书馆[8-9]相比于传统的图书馆,给人们带来了更多的时空便利,人们不再需要花费大量的时间到巨大的图书馆中查找借阅自己感兴趣的图书,只需要一台电脑和一个能接入互联网的网络就可以解决这个问题,登陆数字图书馆,就可以方便的查询和借阅。数据挖掘技术应用到数字化图书馆后,使数字图书馆更加智能化、高效化、个性化。从某种意义上说,数字化图书馆让每个人都可以拥有一个定制的属于个人的小型图书馆。
分组Apriori 算法引入到图书个性化推荐系统,该系统工作流程如下:数据预处理模块对图书馆借阅历史信息数据库提取原始数据,并对原始数据库进行预处理;数据挖掘模块利用引入的分组Apriori算法对数据进行挖掘,得到的结果存入关联数据库;读者登陆数字化图书馆,打开查询页面,输入自己感兴趣的信息,查找到所需求的图书,当点击这些图书时,这时图书推荐系统给读者推荐相关的图书供读者选择。图书推荐模型工作流程如图1 所示。
5 算法性能评测
实验采用的事务数据全部来之于某高校的图书馆借阅信息数据库,以读者的一次借阅行为作为一个事务数据。那些只有一个数据项的事务直接舍弃(一位读者一次只借一本书没有任何研究意义),经过数据清洗后得到有效借阅记录。Apriori 算法和分组Apriori 算法均用JAVA 语言在Eclipse 下实现,其中经典Apriori 算法采用的是开源数据挖掘平台WEKA[10]源码。实验环境:CPU(Pentium R 2.0G),MEMORY(DDR2 2G),操作系统(WINDOWS XP)。
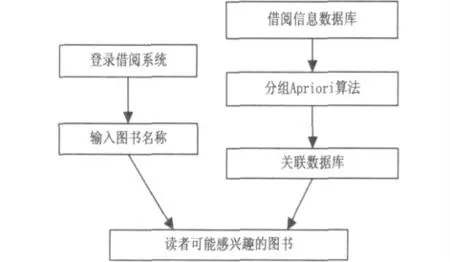
图1 图书个性化推荐模型
实验一:采用50000个有效的事务项,在不同各支持度下对两种算法进行比较,得到的实验结果如图2 所示。在支持度比较小的情况下,两种算法的运行时间相差较大,随着支持度取值的不断增加,两种算法的运行时间差别较小。这是因为较高的支持度下,候选项集急剧减少,两种算法扫描数据库的开销都相对较小。
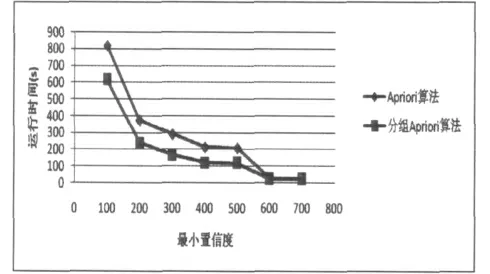
图2 不同最小支持度下两种算法的运行时间
实验二:取固定的最小支持度0.002,事务数据集分别采用1W、2W、3W、4W、5W,两种算法运行的时间如图3 所示。
综上实验和分析算法原理,分组Apriori 算法在事务分组特别多的情况下效果相当良好,在数字图书馆借阅系统中,读者至少借一本,最多可以借15本(高校最多借阅量情况不同),读者所能借阅的书籍最大数数目越大,则分组Apriori 算法效率越能得到体现。
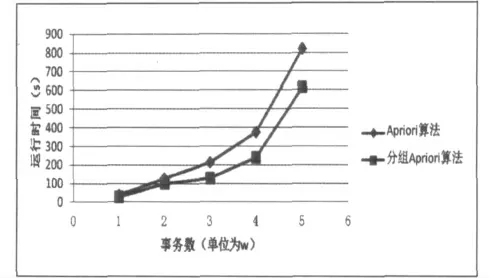
图3 不同事务数据量下两种算法的运行时间
6 结束语
个性化服务是数字化图书馆不可避免的主流趋势。分析了关联规则挖掘经典算法Apriori的算法思想和流程,提出使用分组技术对原算法进行改进。将分组Apriori 算法应用到数字图书馆的借阅系统中,对不同读者需求的图书进行智能推荐。
[1]George M.Marakas,著.数据仓库、挖掘和可视化:核心概念[M].敖富江,译.北京:清华大学出版社,2004.
[2]李宝东,宋瀚涛.数据挖掘语言研究现状及发展[J].计算机工程与应用,2003(6):62-64.
[3]胡艳翠.基于关联规则的数据挖掘算法研究[D].大连:大连海事大学,2009.
[4]Agrawal R,Imielinsi T,Swami A.Mining association rules between sets of items in large database[R].the 1993 ACM SIGMOD conference,Washington D.C,USA,1993.
[5](美)Pang-Ning Tan,Michael Steinbach,Vipin Kumar,著,数据挖掘导论[M].范明,范宏建,译.北京:人民邮电出版社,2006.
[6]刘以安,羊斌.关联规则挖掘中对Apriori 算法的一种改进研究[J].计算机应用,2007,27(2):418-420.
[7]毛国君,段立娟.数据挖掘原理与算法[M].北京:清华大学出版社,2005.
[8]鲍静.关联规则挖掘及其在图书流通数据中的应用研究[D].合肥:合肥工业大学,2007.
[9]尤凤英.数据挖掘技术及其在数字图书馆中的应用[J].办公自动化杂志,2007(9):51-52.
[10]于辰云,刘旸,周金枝.基于插件技术的数据挖掘平台设计与实现[J].2010,30(2):46-49.
猜你喜欢
中国交通信息化(2022年10期)2022-11-17
大众投资指南(2021年35期)2021-02-16
河南水利年鉴(2020年0期)2020-06-09
天津科技大学学报(2018年4期)2018-08-22
华中师范大学学报(自然科学版)(2017年6期)2017-12-26
大连理工大学学报(2017年5期)2017-09-20
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
智能系统学报(2013年1期)2013-01-28
中南民族大学学报(自然科学版)(2011年2期)2011-02-07
