
基于最大后验估计的无监督聚类算法
2013-07-19 08:44:04赵晨阳翟少丹佀洁
计算机工程与应用 2013年19期
赵晨阳,翟少丹,佀洁
1.西北大学数学系,西安 710127
2.西北大学信息与技术学院,西安 710027
基于最大后验估计的无监督聚类算法
赵晨阳1,翟少丹1,佀洁2
1.西北大学数学系,西安 710127
2.西北大学信息与技术学院,西安 710027
混合模型为密度估计和聚类提供了一个严密的框架,基于有限混合模型的聚类方法受到了越来越多的重视和关注。有限混合模型为一大类随机现象建立统计模型提供了一个基于数学的方法,并可以广泛应用于监督的和无监督的聚类算法中[1]。但是,在基于混合模型的聚类过程中仍然存在多方面的问题,例如:如何去估计混合模型的参数;当多元高斯分布的斜方差矩阵是正定时,EM算法的迭代过程虽然可以保证似然函数良好的单调性,但是并不能保证该矩阵的正定性。
Figueiredo和Jain提出了一种基于MML准则的无监督的EM算法(MML-EM)[2],很好地解决了EM算法的局部收敛以及确定分类个数的问题。但是,MML-EM算法在估计方差矩阵时会出现奇异,从而导致最大似然估计失败。
提出一种新的基于最大后验估计的聚类算法,在EM算法中将MLE替换为MAP估计,并用一种改进的BIC准则(MBIC)作为模型评价的标准[3],且将此MBIC与模型参数估计同时处理,从而集成了MML-EM算法中的优势。数值实验表明,MAP-EM算法能很好地避免奇异情况的发生,同时可以防止模型选择出现失败。
1 混合模型聚类算法基本原理
基于有限混合模型聚类的原理是采用若干个概率分布的混合模型去拟合数据,其中每一分布描述一个类的特点,从而实现聚类[4]。相比于其他聚类算法,基于模型的聚类算法能够更灵活地在多种概率模型中选择合适的模型。
在基于模型的聚类中,数据x=(x1,x2,…,xn)被看做来自一个混合分布,则混合分布的密度函数可以表示为:

EM算法[5-6]是求参数极大似然估计的一种重要算法。文献[7]详细讨论了如何运用EM算法估计高斯混合模型的参数,在这里仅给出参数的更新公式:

利用上式就可以实现EM算法,得到Θ的极大似然估计。
2 一种新的基于MAP估计的聚类算法
提出用MAP估计代替MML估计,很好地避免了协方差矩阵陷入奇异,并且增大了模型选择的成功率。用MBIC作为模型评价的标准,将模型评价与模型参数估计同时处理,从而增加了模型选择成功的概率。同时选取一个大于模型真实类数的作为初始分类数目,降低了EM算法对初始值的敏感度[8]。
2.1 MAP-EM算法参数选取
样本数据Y=(y1,y2,…,yn)的Bayesian密度函数表示为:
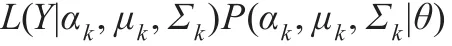
其中,L是混合似然函数,P是参数αk、μk、Σk及θ的先验概率。
2.1.1 参数μ、Σ的选取
文献[9-10]讨论了先验分布的选取问题。经验贝叶斯的方法[11]建议μ、Σ应服从的先验分布,分别为正态分布和负威沙特分布。
假设μ0、k0、ν0和Λ0对于每一分支是相同的,因此对于一个多元高斯混合模型,其正态-负威沙特先验分布为:
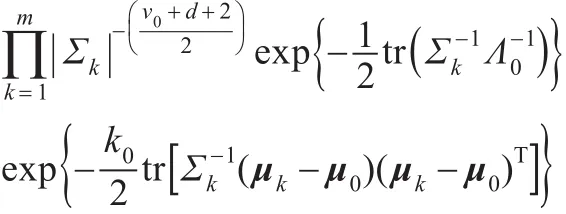
根据先验分布可得到后验均值和后验方差(推导过程见文献[3])。
2.1.2 参数αk的选取
αk的先验分布通常选为Dirichlet分布,即

2.2 MAP-EM算法分支删除策略
将分支个数起始于一个大于模型真实的类数mmax,在迭代的过程中,一些分支的混合比率αk会收缩至0,采取的处理方式是将其删除。这种竞争的方法能够有效避免EM算法收敛于参数空间边界的问题[2,12]。
在EM算法的M步直接应用公式可能会导致算法失败:当mmax非常大时,将会发生所有分支都会被删除的情形。为了避免这一问题,MAP-EM算法采用一种Componentwise EM(CEM)方法:如果一个分支收缩到0,那么立即重新分配它的概率质量给其他的分支,以增加其他分支幸存的机会。
2.3 MAP-EM算法参数的初始化
由于选择了一个大于模型真实类数的mmax作为初始分类数目,有效地降低了基本EM算法对初始值的依赖程度。具体如下:
(1)选择一个大于模型真实类数的mmax作为初始分类数目。
(2)在数据集中随机抽取mmax个点作为聚类中心。

2.4 MAP-EM算法流程
(1)令模型分支数m=mmax,并指定一最小分支数mmin;给定一个判断EM算法是否收敛的阀值。按照2.3节方法,分别初始化混合比率α0、均值μ0和协方差矩阵Σ0。
(2)令i=1,根据文献[2]中的方法计算MBICi的值。令k=1。
(4)若k≤m,转到(3);否则,令i=i+1,重新计算MBICi的值。
(5)若满足EM算法的收敛条件,更新max(MBICi)所对应的参数为最优参数;否则,令k=1,转到(3)。
(6)若m到达mmin,输出最优解;否则,删除最小αk所对用的分支,重新分配其概率质量给其他分支。并令i=i+1,计算MBICi的值,转到(3)。
2.5 MAP-EM算法时间复杂度
MAP-EM算法将模型选择与参数估计同时进行,因此它的时间复杂度由两个部分决定。
MAP-EM算法采用MBIC准则进行模型选择,所以其时间复杂度为O(d2),其中kmax为最大分类数,d为分支数。参数估计由改进的EM算法完成,则复杂度为O(MNE),其中M为混合分布的分支数,N为样本数,E为EM算法迭代次数。因此,MAP-EM算法的时间复杂度为O(Md2NE)。
3 实验性能及对比分析
实验采用两组不同类型的测试数据集,一组是按照文献[2]中根据给定参数生成1 000个随机数据,另一组数据是来从UCI机器学习库中的Iris和Zoo两个基准数据集。表1中给出了数据集和它们的一些简单特征。文中的数值实验均在R语言(www.r-project.org)2.6.1环境下实现。
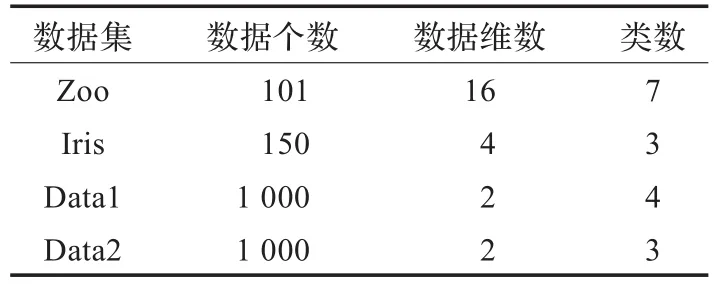
表1 实验数据集说明
3.1 实验1
图1所示的是文献[2]中数据集(Data1)的聚类结果,图(a)为MAP-EM算法对数据集中1 000个随机数据聚类的结果,图(b)是MML-EM算法的聚类结果。实验结果表明MAP-EM算法和MML-EM算法都能选择出最优的模型,并且得到较好的聚类效果,同时具有很好的鲁棒性。
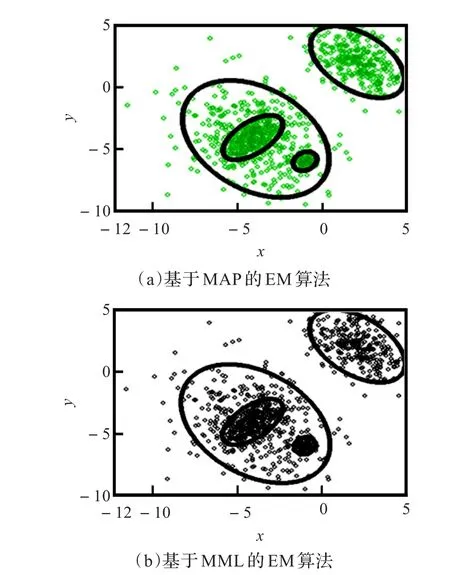
图1 两种聚类算法比较
3.2 实验2
图2所示的是文献[2]中的第二个数据集(Data2)的损失函数变化。Data2是一种分支间相互重叠的数据,而在重叠度较大时,MML-EM算法会因为协方差阵趋于奇异,无法保证算法能够正确收敛[13],从而导致算法失败(图2)。
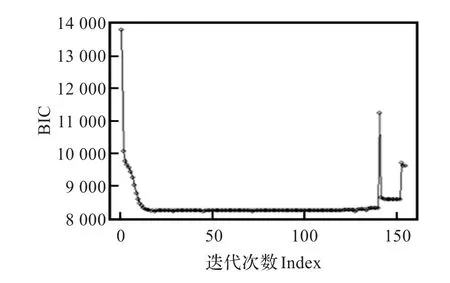
图2 Data2 BIC变化
对于数据集2,MAP-EM算法首先假设参数服从一个先验分布,因此即使每个组成函数不接近任何样本,它们都会有一个小的概率值[13],这样就防止了方差和概率值的估计失败。这种方法不但能够防止方差阵陷入奇异,还能够选择出最优的模型(图3(a))。在数据集有严重重叠的情况下,MAP-EM通过删除后验概率最小的分支避免了参数收敛于参数空间的边界。同时将模型选择与模型的参数估计同时处理,在一定程度上扩大了对M的搜索范围。使得MAP-EM算法在避免协方差矩阵趋于奇异而导致EM算法的失败的同时,能够达到良好的聚类效果(图3(b))。

图3 基于MAP-EM算法聚类结果
3.3 实验3
对UCI数据集Iris和Zoo,分别采用MML-EM和MAP-EM进行测试的结果见表2。从表中的实验结果可以看出,在聚类的质量上MAP-EM算法效果明显优于MML-EM算法。虽然Zoo数据集中的数据具有严重的重叠区域,但是MAP-EM算法依然具有良好的聚类效果。
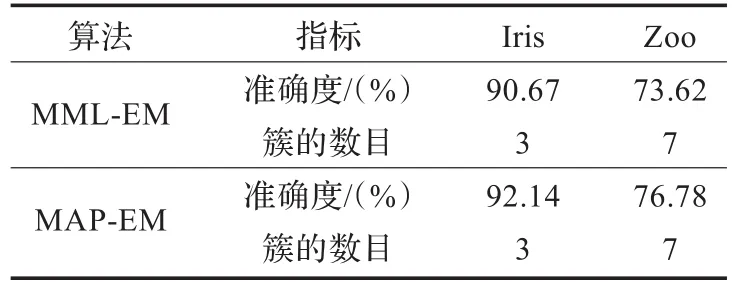
表2 MML-EM算法与MAP-EM算法比较
4 小结
针对EM算法的一些缺陷,提出在算法流程,先验分布的选取,模型选择等方面的一系列改进。首先,MAP-EM算法基于最大后验估计,可以有效地避免聚类过程中协方差矩阵陷入奇异的状况。其次,采用一种竞争的机制,使得在参数估计的同时淘汰后验概率最小的分支。另外,将参数估计与模型选择相结合,有效地扩大了模型选择的范围。大量数值实验证明,改进后的算法具有良好的聚类效果。
由于MAP-EM算法采取淘汰后验概率最小分支的策略,当数据在参数空间中分布不均匀,同时有过于密集区域和稀疏区域时,一些较为稀疏的区域可能会因为后验概率过小而被删除,使得算法陷入局部最优。如何在此类情况下找到一个全局最优解,也是下一步需要研究的问题。
[1]Constantinopoulos C,Likas A.Unsupervised learning of Gaussian mixturesbasedonvariationalcomponentsplitting[J].IEEE Transactions on Neural Networks,2007,18(3):745-755.
[2]Figueiredo M,Jain A K.Unsupervised learning of the mixture models[J].IEEETransonPattern AnalysisandMachine Intelligence,2002,24(3):381-396.
[3]Fraley C,Raftery A.Bayesian regularization for normal mixture estimation and model-based clustering[J].Journal of Classification,2007,24:155-181.
[4]Ketchantany W,Derrde S,Martin L,et al.Pearson-based mixture model for color object tracking[J].Machine Vision and Applications,2008,19(5/6):457-466.
[5]Dempster A P,Laird N M,Rubin D B.Maximum-likelihood from incomplete data via the EM algorithem[J].J R Statist Soc,1997,39:1-38.
[6]茆诗松,王静龙,濮晓龙.高等数理统计[M].北京:高等教育出版社,1998:427-440.
[7]Bilmes J A.A gentle tutorial of the EM algorithm and its applicationtoparameterestimationforGaussianmixtureand hidden Markov models[R],ICSI Technical Report,1997:97-021.
[8]Ruan Lingyan,Yuan Ming,Zou Hui.Regularized parameter estimation in high-dimensional Gaussian mixture models[J]. Neural Conputation,2011,23(6):1605-1622.
[9]Tadjudin S,Landgrebe D.Covaraince estimation for limited training samples[J].Geoscience and Remote Sensing Symposium,1998,37(4):123-128.
[10]Friedman J F.Regularized discriminant analysis[J].Statist Soc,1989,84:17-42.
[11]Rayens W,Greene T.Covariance pooling and stabilization for classification[J].Computational Statistics and Data Analysis,1991,11:17-42.
[12]Figueiredo M,Jain A K.Unsupervised selection and estimation of finite mixture models[J].Pattern Recognition,2000,36:87-90.
[13]Ma Jinwen,Xu Lei,Jordan M.Asymptotic convergence rate of the EM algorithm for Gaussian mixtures[J].Neural Computation,2000,12:2881-2907.
ZHAO Chenyang1,ZHAI Shaodan1,SI Jie2
1.Department of Mathematics,Northwest University,Xi’an 710127,China
2.School of Information and Technology,Northwest University,Xi’an 710027,China
When EM method is used to estimate the maximum likelihood of models,the method will fail because of the covariance matrix become singularity matrix.This paper replaces the Maximum Likelihood Estimation(MLE)by a Maximum a Posteriori(MAP)estimator.By using the improved BIC criterion and the model parameter estimation at the same time,it can enlarge the area of model selection.The algorithm is effective to avoid singularity in the iterations,and uses the improved BIC criterion and the model parameter estimation at the same time.Finally,the R simulation results show that the proposed algorithm decreases the calculation,and improves the accuracy of the cluster,it also has strong robustness.
mixture model;EM algorithm;Maximum a Posteriori(MAP);model selection;clustering
传统的基于EM算法的聚类方法,当模型的某个高斯分量的协方差矩阵变为奇异矩阵时,会导致聚类失败。提出在聚类过程中用最大后验估计(MAP)来代替极大似然估计(MLE);将一种改进的贝叶斯信息准则(BIC)与模型参数估计同时处理,扩大了模型选择的搜索范围。该算法有效地避免了协方差矩阵在迭代中陷入奇异,并将参数估计和模型选择同时进行。通过R软件进行仿真分析,结过表明改进的算法在减少计算量同时,提高了聚类的准确度,并具有鲁棒性。
混合模型;EM算法;最大后验估计(MAP);模型选择;聚类
A
TP311
10.3778/j.issn.1002-8331.1201-0190
ZHAO Chenyang,ZHAI Shaodan,SI Jie.Unsupervised clustering algorithm based on Maximum a Posteriori.Computer Engineering and Applications,2013,49(19):131-134.
国家自然科学基金(No.10771169)。
赵晨阳(1984—),女,博士研究生,主要研究方向为数据挖掘;翟少丹(1984—),男,硕士研究生,主要研究方向为人工智能。E-mail:starstaryang@163.com
2012-01-18
2012-04-26
1002-8331(2013)19-0131-04
CNKI出版日期:2012-07-03http://www.cnki.net/kcms/detail/11.2127.TP.20120703.1628.039.html
猜你喜欢
哈尔滨工业大学学报(2022年5期)2022-04-19 13:26:28
工程数学学报(2020年3期)2020-07-06 07:38:40
学生天地(2019年28期)2019-08-25 08:50:54
长治学院学报(2019年2期)2019-07-24 07:14:04
数学物理学报(2018年1期)2018-03-26 08:16:36
雷达学报(2017年6期)2017-03-26 07:53:04
统计与决策(2017年2期)2017-03-20 15:25:22
数学物理学报(2016年5期)2016-08-24 07:38:48
系统工程与电子技术(2016年2期)2016-04-16 05:17:08
华东理工大学学报(自然科学版)(2014年5期)2014-02-27 13:49:31
