
基于MapReduce的量子蚁群算法
2013-07-19 08:44:40贾瑞玉李亚龙
计算机工程与应用 2013年19期
贾瑞玉,李亚龙
安徽大学计算机科学与技术学院,合肥 230601
基于MapReduce的量子蚁群算法
贾瑞玉,李亚龙
安徽大学计算机科学与技术学院,合肥 230601
1 引言
随着信息和通信技术的快速发展,计算模式经历了把任务集中交付给大型处理机的模式,基于网络的分布式任务处理的模式,发展到了按需处理的云计算[1]模式。许多智能算法可以在云计算系统实现分布式计算,从而充分利用云计算系统的强大计算能力。
蚁群算法最早由意大利学者Dorigo M于1991年提出,该算法具有较好的寻优能力和较强的鲁棒性,并成功地用于TSP求解、工件排序、背包问题、车辆调度等多目标组合优化问题[2-6]。量子进化算法(QEA)[7]是KuK-Hyuan Han等人于2002年提出的,是一种基于量子理论的进化算法。它吸收了量子计算[8]中的叠加态、相干性和纠缠性等思想,使得量子算法突破了传统算法的极限,表现出更好的性能。该算法以其独特的计算性能成为研究的热点,引起国内外众多学者的研究兴趣,并取得了许多研究成果。量子蚁群算法则将量子计算和蚁群算法相结合,把量子计算中的态矢量和量子旋转门引入到蚁群算法中,采用量子旋转门及最优解对信息素更新,加快了算法的收敛速度并且避免了早熟收敛。量子蚁群算法已成功地求解出许多NP难题,文献[9]使用量子蚁群算法对0-1背包问题(0/1 knapsack problem)进行求解,并用数值实验说明了其有效性;文献[10]分析了量子蚁群算法的优缺点,提出一种新的量子蚁群算法用于求解旅行商问题(Traveling Salesman Problem,TSP),并设计了一种量子交叉策略,避免搜索陷入局部最优,进一步提高了量子蚁群算法的性能。但量子蚁群算法对这些问题的求解是在串行环境下进行的,国内尚没有利用云计算将量子蚁群算法并行化的研究。
Google提出的MapReduce编程模型,允许用户方便地在数据中心开发分布式应用程序,但是许多智能算法需要一种迭代的方式,并不遵循MapReduce的两个阶段的模式。文献[11]提出了一个具有层次处理阶段的MapReduce模型,可以自动地使遗传算法并行化。本文受此模型的启发,将QACA与MapReduce结合,实现了QACA在云环境中的并行化,并应用于0-1背包问题的求解;实验结果证明了其有效性与可行性。
2 MapReduce并行计算编程模型
2.1 MapReduce模型简介
受函数式语言中的Map和Reduce函数的启发,Google公司提出了MapReduce(映射-归并算法)的抽象模型,该模型可以使用户能够轻松地开发大型分布式应用程序。在该模型中,每个Map函数是独立的,并使用出现故障后重新执行的容错机制,可以很容易地实现大型并行化计算。Apache开源社区的Hadoop[12]项目用Java语言实现了该模型,同时也为云计算提供了一个开源实现平台。
MapReduce计算模型的核心是Map和Reduce两个函数,这两个函数均由用户编写。Map函数对用户输入的键值对(k/ν)进行计算并产生一系列中间键值对(k1/ν1)。MapReduce框架将关键字是k1的键值对聚合起来产生关于k1键的值集合list(ν1)传给用户定义的Reduce函数。Reduce函数再进一步处理、合并该中间键的值集合,最后形成一个相对较小的键值对集合list(k2,ν2)。
整个过程可用如下形式表示:

2.2 MapReduce处理阶段
在MapReduce计算模型中,整个作业的计算流程包含5个阶段。
(1)Input阶段:用户输入的数据会被自动切分成m个数据分片(splits)并被转换为(k/ν)的形式分配给m个Map任务,每个Map任务会被分派到集群的某一台机器上运行,这些Map任务在不同的机器上是并行执行的,对每一个Map任务都要指明输入/输出的路径和其他运行参数。
(2)Map阶段:使用Map函数中用户定义的Map操作对(k/ν)键值对进行处理后,以list(k1,ν1)键值对形式输出。
(3)Shuffle阶段:在调用Reduce函数之前会对Map任务处理完成的数据进行分割,具有相同关键字的键值对合并在一起形成(k1,list(ν1)),每一个(k1,list(ν1))就会分配到一个Reduce任务,每个Reduce任务也是被分派到集群中的某一台机器上,这样在整个Hadoop集群中就会有多个Reduce任务并行执行。
(4)Reduce阶段:此阶段对每一个唯一的ki键值对执行用户定义的Reduce函数,Reduce任务执行完成后,输出结果list(k2,ν2)。
(5)Output阶段:此阶段把Reduce输出结果写入到输出目录的文件中。
3 量子蚁群算法(QACA)
下面结合0-1背包问题来说明量子蚁群算法。0-1背包问题描述为:给定n个物品和1个背包,物品i的重量是wi(i=1,2,…,n),其价值为νi,背包的容量为c,现从这n个物品中选出若干个放入背包,使得放入的物品重量不超过c,且总价值达到最大。使用蚁群算法求解0-1背包问题时,某一物品上聚集的信息素越多,则该物品被选择的概率就越大。在QACA中,对蚂蚁在物品上聚集的信息素进行量子比特编码,采用量子旋转门更新蚂蚁携物品的量子比特,聚集在物品上的信息素更新转变成量子位概率幅的更新。
量子蚁群算法流程[9]:

为了使算法初始搜索时所有状态以相同概率出现,A(0)中所有的αi,βi(i=1,2,…,m)取值均为1/2。
步骤2设定各参数α、β、ρ的值,最大迭代次数NMAX,当前迭代次数t=0,信息素τi(0)=1。
步骤3每只蚂蚁独立地构造一个解。蚂蚁k(k=1,2,…,n)随机选择一个物品i装入背包,然后按概率计算剩余的各个物品被选择的概率来选择物品放入背包,直到背包不能再装入物品。物品被选择概率如公式(4)所示:

式(4)中,τi(t)表示第t次迭代时物品i所含信息素的量,启发函数ηi(t)表示物品i单位质量的价值,即ηi(t)=νi/wi,α和β分别表示物品所含信息素的量和物品单位质量价值的权重,J(k)为蚂蚁k没有选择的物品的集合;信息素更新方程:

其中,Δτi(k)表示蚂蚁k在第i个物品上留下的信息素的量,Q为一常数,ρ为信息素的挥发性(0≤ρ<1)。
步骤4若n只蚂蚁都构造完成各自的解,则转步骤5;否则转步骤3。
步骤5记录本次迭代中m只蚂蚁构造出来的最优解。
步骤6应用量子旋转门规则[13]更新A(t)。
步骤7若满足结束条件,即t>NMAX,输出最优解;否则t=t+1,转步骤3。
4 基于MapReduce的量子蚁群算法(MQACA)
对于0-1背包问题,QACA的时间复杂度为O(NMAX·m·n),计算量主要集中在步骤3,蚂蚁独自求解的过程。MQACA算法用MapReduce来完成种群每一代进化的过程。Map完成蚂蚁的独立求解过程,其中蚂蚁家族的索引号作为键,蚂蚁的最优解和量子信息作为值,这一部分可以并行操作;Reduce表达求得较优解和更新量子蚂蚁信息过程,输出信息转换为Map输入的格式作为下一代Map函数的输入,进入下一代循环。
4.1 MQACA算法的步骤
具体步骤如下:
步骤1初始化种群,产生键值对(k/ν),以文件形式存放于Hadoop文件系统,k表示蚂蚁家族的索引,ν表示蚂蚁的解和量子信息。
步骤2 Map函数接收(k/ν),计算每个量子蚂蚁的适应度值,产生中间结果list(k1,ν1),k1表示蚂蚁家族的索引,ν1表示本家族单个蚂蚁求得的解和量子信息。
步骤3 Reduce函数接收Map函数产生的键值对list(k1,ν1),应用量子旋转门规则更新量子蚂蚁及全局信息素,判断是否达到最大代数,如果是则输出最优值;否则保存最优值同时输出list(k2,ν2),k2表示蚂蚁家族的索引,ν2表示蚂蚁的解和量子信息。将list(k2,ν2)保存在Hadoop文件系统中,进入下一次循环。
4.2 Map阶段
Map函数的主要功能是蚂蚁家族中的各成员独立生成解,输出本家族每个蚂蚁的解,形成list(k1,ν1)中间结果。Map函数如函数1所示。
函数1 MQACA的Map函数

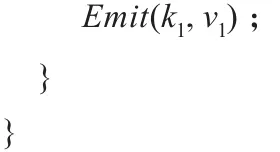
4.3 Reduce阶段
Reduce函数接收Map函数输出的键值对,其主要功能是分解出各个蚂蚁家族成员的解和值,求出其中的最优解和最优值,然后使用量子旋转门规则更新蚂蚁家族中各成员的量子信息,根据公式(5)对信息素文件进行更新,判断是否满足终止条件,如果是则输出最优解和最优值;否则将输出键值对list(k2,ν2)保存在Hadoop文件系统中,k2是蚂蚁家族索引ν2是更新后的解和量子蚂蚁信息。Reduce函数如函数2所示。
函数2 MQACA的Reduce函数

5 数值实验和分析
5.1 实验环境
本文使用了3台计算机搭建Hadoop集群(如图1),1台机器作为Master,2台机器作为Slave。每台节点硬件配置如下:Pentium®Dual-Core CPU,2.80 GHz,2 GB内存,板载Marvell Yukon Gigabit Ethernet网卡控制器。软件配置如下:Linux Ubuntu 10.04,JDK1.6.0.31,Hadoop 0.20.2,eclipse-SDK-3.7.2,Master上部署Hadoop的NameNode和JobTracker,Slave上部署TaskTracker和DataNode。
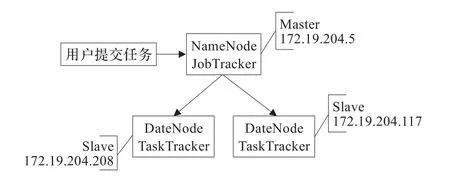
图1 实验Hadoop集群

图2 两个集群下加速比对比
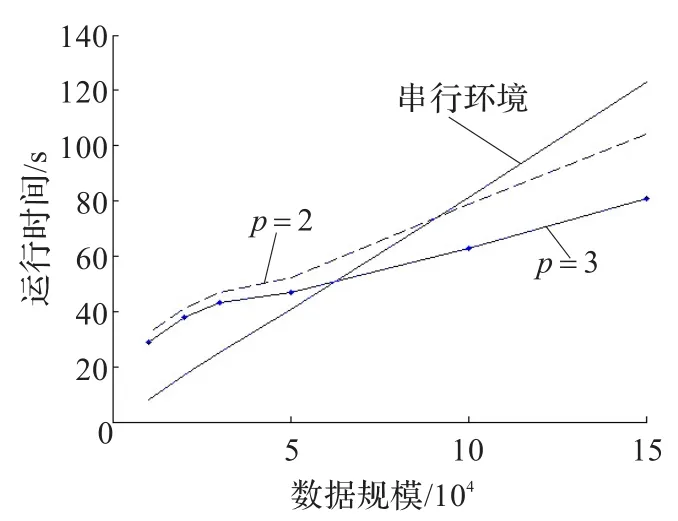
图3 两个集群及串行环境下运行时间对比

图4 两个集群下并行效率对比
5.2 集群加速比和效率
加速比是同一个任务在单处理器系统和并行处理器系统中运行消耗的时间的比率,用来衡量并行系统或程序并行化的性能和效果以及扩展性。根据加速比的一般公式,即串行程序执行时间与并行程序执行时间的比值,定义如下加速比和效率。
并行加速比:

式(7)中,n为种群规模,F(n)表示用串行机求解该问题所需的时间,m1和m2分别是同时运行Map和Reduce的数量,M(n,m1)和R(n,m2)分别表示在MapReduce过程中Map和Reduce所花费的时间,G(n)为完成任务所必须的运算时间之外所消耗的时间,如任务部署、排序、通信传输时间等。
并行效率:

式(8)中,p为集群中处理器的个数,当加速比S接近于p时,效率接近于1,影响并行效率的因素很多,如集群中机器之间的网络传输时间,集群运行任务部署时间等。
5.3 实验结果分析
5.3.1 串并行比较实验
实验内容为比较Hadoop集群中两个运算节点与QACA算法的串行实现,在同样种群规模下处理相同问题的解的质量。实验中,取α=1,β=5,ρ=0.9,Q=1,集群中每个节点及串行环境中群体规模m=10,随机生成各种不同规模的0-1背包问题实例。实例生成方法:各νi和wi在1~100内随机生成,背包容量c=1/3(w1+w2+…+wn)。实验情况见表1。
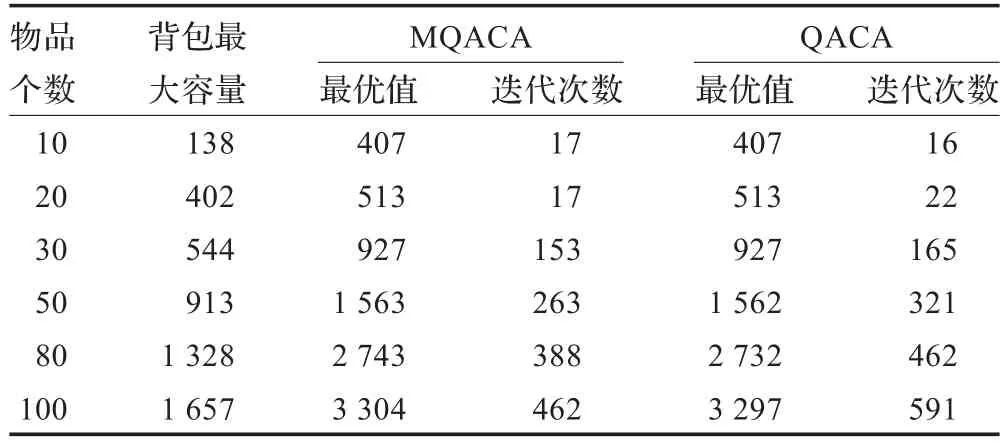
表1 实验结果比较
在MQACA中,每一次迭代后不同节点所求得的解都会经过Reduce函数处理,增加集群中节点之间的交互,加速算法的收敛。表1为MQACA与QACA对于不同规模的背包问题分别独立运行50次所得到的结果,从表1可以看出,随着问题规模的增大,MQACA的解的质量和收敛速度都有较好的表现,表明了MQACA求解背包问题的可行性。
5.3.2 集群加速比性能实验
选择100个物品的背包问题,在搭建的Hadoop集群环境下进行MQACA算法的集群加速比性能实验,数据规模为10 000到200 000。对每个问题分别在节点数为2和节点数为3的集群中进行实验,集群中节点数代表集群中处理器的个数,用p表示;串行环境求解时间是在单机环境下,根据种群规模求解所得到的时间,并行环境求解时间是在集群中根据种群规模求解所得到的时间,实验结果如图2~图4所示。
分析图2、图3,随着数据量的增大,并行程度越高,并行加速比相应的越大,当计算数据规模较大时,处理器数由2增加到3运行时间也相应的缩短,说明并行程度直接影响MapReduce执行时间。从图4可以看出,集群中处理器的个数越多,集群部署耗费的时间也相应增加,并行效率越低,但总体并行效率是随着数据规模的扩大而上升的,根据数据规模选择合适的处理器数可获得较好的并行效率。上述结果也体现出在处理大规模数据方面,MapReduce相对于传统串行环境的优势。
6 结束语
本文在Hadoop云环境中,应用MapReduce将量子蚁群算法并行化,提出基于MapReduce的量子蚁群算法,并用0-1背包问题验证了该算法在处理大规模数据的有效性。今后,将进一步对MQACA算法参数调优方面进行研究,提高算法性能,并设计新的MQACA算法来解决更为实际的问题。
[1]李莉,廖剑伟,欧灵.云计算初探[J].计算机应用研究,2010,27(12):4419-4422.
[2]郭平,鄢文晋.基于TSP问题的蚁群算法综述[J].计算机科学,2007,34(10):181-184.
[3]朱庆保,扬志军.基于变异和动态信息素更新的蚁群优化算法[J].软件学报,2004,15(2):185-192.
[4]王欣盛,马良.工件排序的改进蚁群算法优化[J].上海理工大学学报,2011,33(4):362-366.
[5]冀俊忠,黄振,刘椿年.基于变异和信息素扩散的多维背包问题的蚁群算法[J].计算机研究与发展,2009,46(4):644-654.
[6]刘霞,扬超.最小-最大车辆路径问题的蚁群算法[J].解放军理工大学学报,2012,13(3):336-341.
[7]Han K H,Kim J H.Quantum-inspired evolutionary algorithm with a new term ination criterion[J].IEEE Transactions on Evolutionary Computation,2004,8(2):156-169.
[8]Han K H,Kim J H.Genetic quantumalgorithm and its application to combinatorial optimization problem[C]//Proceedings of the 2000 IEEE Congress on Evolutionary Computation,2000: 1354-1360.
[9]何小锋,马良.求解0-1背包问题的量子蚁群算法[J].计算机工程与应用,2011,47(16):29-31.
[10]李絮,刘争艳,谭拂晓.求解TSP的新量子蚁群算法[J].计算机工程与应用,2011,47(32):42-44.
[11]Chao Jin,Vecchiola C.MRPGA:an extension of MapReduce for parallelizing genetic algorithms[C]//Proceedings of the IEEE 4th International Conference on Science,2008:214-221.
[12]White T.Hadoop权威指南[M].周敏奇,王晓玲,金澈清,等译.北京:清华大学出版社,2011.
[13]Han K H,Kim J H.Quantum-inspired evolutionary algorithm for a class of combinatorial optimization[J].IEEE Transactions on Evolutionary Computation,2002,6(6):580-593.
JIA Ruiyu,LI Yalong
School of Computer Science and Technology,Anhui University,Hefei 230601,China
The Quantum-inspired ant colony algorithm is a new algorithm which is based on the combination of ant colony optimization and quantum computing,and has better diversity and global search capacity.This paper aims at the parallelism of Quantum-inspired ant colony algorithm,uses cloud computing to parallel Quantum-inspired ant colony algorithm,makes it to meet the key/value programming model of MapReduce,puts forward MapReduce-based Quantum-inspired ant colony algorithm and runs the algorithm on Hadoop platform.Using 0-1 knapsack problem for test,with the expansion of data set,improvement of parallelism,MQACA exhibits good speed-up ratio and parallel efficiency,proves the feasibility of MQACA.
Quantum-inspired ant colony algorithm;cloud computing;MapReduce model
量子蚁群算法是在蚁群算法的基础上结合量子计算而提出的,该算法具有较好的全局寻优能力和种群多样性。应用MapReduce的key/value编程模型,将量子蚁群算法并行化,提出了基于MapReduce的量子蚁群算法(MQACA),并将其部署到Hadoop云计算平台上运行。对0-1背包问题的测试结果证明,随着数据规模的扩大和并行程度的提高,MQACA具有良好的加速比和并行效率。
量子蚁群算法;云计算;MapReduce模型
A
TP301
10.3778/j.issn.1002-8331.1302-0036
JIA Ruiyu,LI Yalong.Quantum-inspired ant colony algorithm based on MapReduce model.Computer Engineering and Applications,2013,49(19):246-249.
安徽省教育厅自然科学研究基金资助重点项目(No.2011A006)。
贾瑞玉(1965—),女,副教授,硕士生导师,主要研究方向为智能计算与数据挖掘;李亚龙(1989—),男,硕士研究生,主要研究方向为智能计算。E-mail:jiaruiyu267@yahoo.com.cn
2013-02-05
2013-05-07
1002-8331(2013)19-0246-04
CNKI出版日期:2013-05-29http://www.cnki.net/kcms/detail/11.2127.TP.20130529.1519.001.html
猜你喜欢
青少年科技博览(中学版)(2023年3期)2023-05-11 07:36:58
电脑爱好者(2020年18期)2020-09-26 14:53:01
小学科学(学生版)(2020年1期)2020-01-19 06:02:08
农民文摘(2019年11期)2019-11-15 01:03:48
科学大众(中学)(2019年2期)2019-04-08 02:26:40
摄影之友(影像视觉)(2017年10期)2017-11-07 02:37:15
作文周刊·小学一年级版(2016年42期)2017-06-06 22:16:15
电脑爱好者(2017年9期)2017-06-01 21:38:08
童话世界(2017年11期)2017-05-17 05:28:26
西安工程大学学报(2016年6期)2017-01-15 14:08:28
