
基于改进粒子群算法的云计算任务调度算法
2013-07-19 08:43张陶于炯杨兴耀廖彬
计算机工程与应用 2013年19期
张陶,于炯,杨兴耀,廖彬
新疆大学信息科学与工程学院,乌鲁木齐 830046
基于改进粒子群算法的云计算任务调度算法
张陶,于炯,杨兴耀,廖彬
新疆大学信息科学与工程学院,乌鲁木齐 830046
1 引言
IBM公司于2007年底宣布了云计算计划[1-2]后,云计算吸引了众多人的关注,并迅速成为产业界和学术界研究的热点。众多云计算供应商都根据自己企业业务推出相关的云计算战略,投入巨资部署各自的云计算基础架构。研究机构也提出各种原型系统[3-4],并提出了超过20种以上的“云”的定义[5]。当前,云计算服务可分为3个层次:(1)基础设施即服务(IaaS)。如IBM的“蓝云”计算平台,Amazon的弹性云计算(EC2)服务、存储服务(S3)和SimpleDB[6],以及Sun的云基础设施平台(IAAS)。(2)平台即服务(PaaS)。如Google AppEngine[7]、Apache Hadoop、Microsoft Azure等。(3)软件即服务(SaaS)。如Salesforce公司的客户关系管理服务。
云计算是网格计算、分布式计算、并行计算、效用计算、网络存储、虚拟化等先进计算机技术和网络技术发展融合的产物,具有普遍适用性。云计算技术的发展,一直与大规模任务调度密切相关。因此,依靠云计算环境如何对大规模任务进行高效调度,是一个非常重要的研究方向。本文提出了一种基于双适应度粒子群算法(Double Fitness Particle Swarm Optimization,DFPSO)的云计算任务调度算法,并设计了适用于云环境下任务调度问题的编码、适应度函数、位置速度更新策略。仿真实验取得了理想的调度结果,表明了本文算法在该问题中具有较好的应用前景。
在云计算环境中,一个大规模的计算任务的处理必须进行分布式并行处理。首先要将一个逻辑上完整的大任务分解成若干个子任务,系统根据任务的信息采用适当的策略把不同的任务分配到不同资源节点上去运行。当所有子任务处理结束,则完成整个大任务的一次处理,最后将处理结果传给用户。目前的云计算环境中大部分采用Google提出的MapReduce[8-10]编程模型。如图1,一个并行处理任务由多个Map任务和多个Reduce任务组成,任务的执行分为Map阶段和Reduce阶段。在Map阶段,每个Map任务对分配给它的数据进行计算,然后按照Map的输出key值将结果数据映射到对应的Reduce任务中;在Reduce阶段,每个Reduce任务对接收到的数据做进一步聚集处理,得到输出结果。
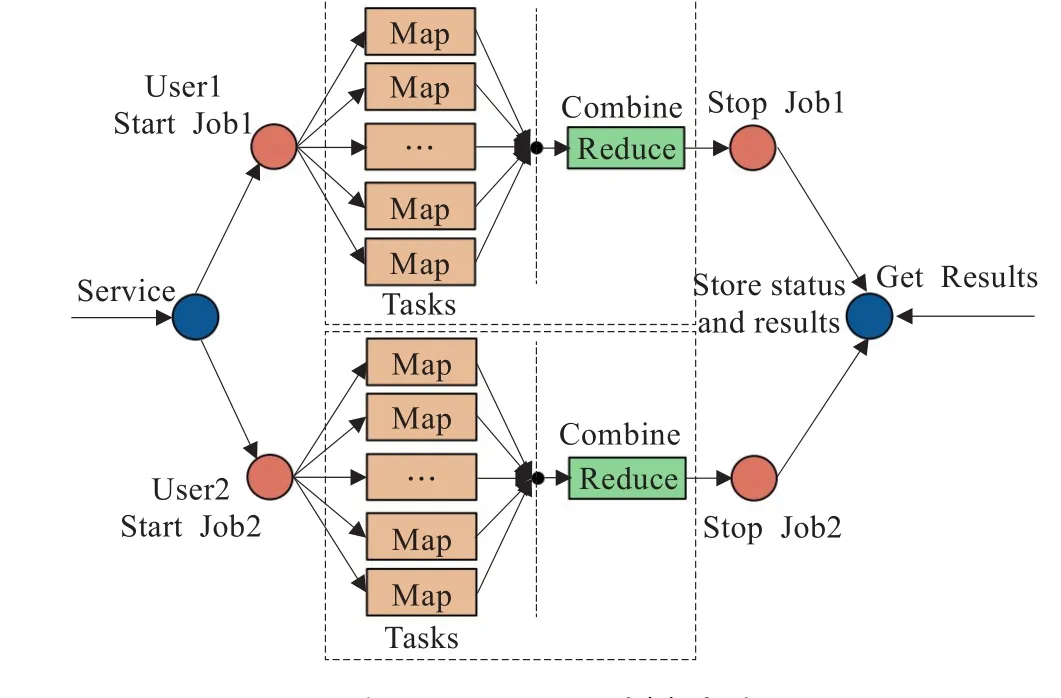
图1 MapReduce运行机制
由于云计算可扩展性和动态性的特点,任务量和资源的数量是相当庞大的,系统每时每刻都要处理海量的任务。因此在MapReduce编程模型下,如何对众多的子任务进行调度是个复杂的问题。不好的任务分配策略势必会增加任务的执行时间,降低整个云的性能以及用户的使用满意度。目前的一些较为典型的任务调度算法多是以总任务完成时间作为调度目标(makespan),没有太多地考虑任务的平均完成时间,这样势必会造成许多潜在的优良粒子的丢失。因为当任务平均完成时间较小时,使找到更小的任务总完成时间成为了可能。因此,本文提出了DFPSO,对云计算中的任务调度策略进行了改进,较大限度地提高了云计算任务调度的效率和用户满意度。
本文主要讨论当子任务数量远大于资源数量时的调度策略,如何获取资源信息、子任务的分解方法不在讨论范围内,不做详细论述。在同一个资源上执行的子任务遵循FCFS原则。
2 采用双适应度粒子群算法的任务调度
和遗传算法(Genetic Algorithm)、蚁群(Ant Colony Algorithm)一样,作为一种群智能算法[11]的粒子群优化PSO算法[12],是1995年由美国社会心理学家Kennedy和电气工程师Eberhart提出来的仿生优化算法,来源于对鸟类和鱼类觅食过程的模拟。传统PSO算法在求解云计算任务调度这个大规模的、实时的问题上有着天然的优势。参照MapReduce编程模型,为得到任务总完成时间和任务平均完成时间都较短的调度结果,本文在传统粒子群优化算法基础上做了一些改进,增加了一个适应度,用两个适应度来选择种群,即双适应度粒子群算法——DFPSO。
2.1 问题编码
目前粒子的编码方式可以分为直接编码(基于问题直接对粒子的位置速度进行编码,一个粒子对应问题的一个可行解)和间接编码两类。本文采用间接编码方式,对每个子任务占用的资源进行编码,编码长度取决于子任务数量,这样一个粒子实际上对应着一个任务分配策略。
设有Task个任务,Resource个资源,每个任务又分为若干个子任务(SubTask),且任务划分的子任务总数SubTask大于资源数Resource,即SubTask>Resource。
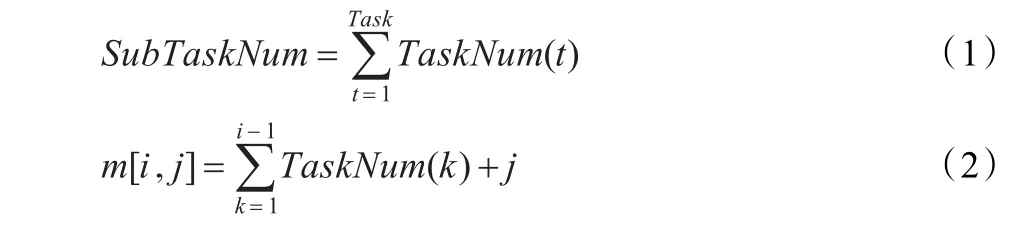
式(1)是子任务的总数量,其中TaskNum(t)为第t个任务所含子任务的个数。
式(2)是对子任务的编码,此时采用顺序法,即按任务顺序进行编码。第i个Task中的第j个SubTask的序号是m[i,j]。
当Task=3,Resource=3,SubTask=10时,粒子(3,2,2,1,3,2,3,1,1,2)即为一个可行的调度策略。如表1的粒子编码所示,其中任务、子任务对(2,5)表示第2个任务中的第3个子任务序号是5;子任务、资源对(1,3)表示把子任务1分配到资源3上执行。

表1 粒子编码示例
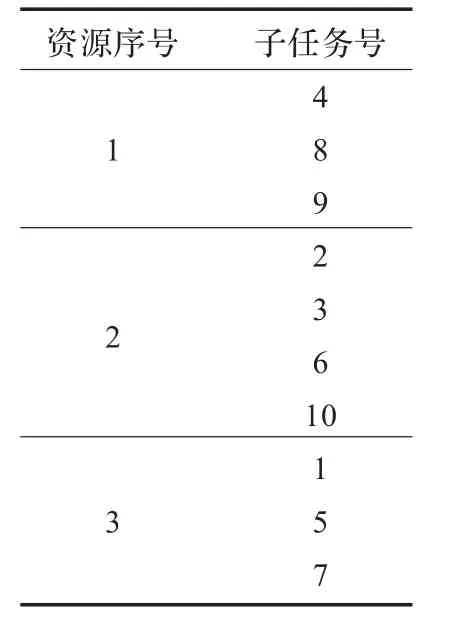
表2 粒子解码示例
之后是对粒子的解码,得到资源上的SubTask分布情况。如表2所示,其中资源1上执行的子任务是{4,8,9},资源2上执行的子任务是{2,3,6,10},资源3上执行的子任务是{1,5,7}。
本文使用ETC[13]矩阵记录任务的执行时间,ETC[i,j]表示子任务i在第j个资源上执行的时间。

式(3)是完成所有任务的总时间,其中,Resource(r,i)是第r个资源执行该资源上第i个子任务所用的时间,n为分配到此资源上的子任务个数。
式(4)是第t个任务完成的时间。其中,res(j,i)是子任务i分配的资源上执行该资源第j个子任务所用的时间,k为第t个任务的第i个子任务在被分到的资源中的位置。
式(5)是每个任务平均完成时间。
2.2 粒子群体初始化

2.3 适应度函数
对应每个粒子的分配方案,都有一个用于衡量粒子优劣的适应度。代表任务分配最优解的粒子具有最优的适应度,而适应度函数作为相应的评价函数要能有效地反映出每一个粒子与问题最优解粒子之间的差距。
任务调度较为典型的多是以任务总完成时间作为调度目标,传统的PSO算法用任务总完成时间来定义适应度函数。为了提高算法的收敛精度,也是找到实际最优解所必需的,DFPSO算法考虑任务总完成时间的同时也考虑到了任务的平均所用时间。即定义两个适应度函数:

TaskTime(t,i)为在第i个粒子中完成第t个任务所用的时间。
本文采用类似遗传算法中选择(Selection)的思想,优选适应度高的粒子。任务总完成时间和任务平均所用时间越短的粒子,适应度值越大,越容易被选择。通过这样的选择,种群中即有总任务完成时间较短的粒子,又有任务平均所用时间较短的粒子,为进化出下一代较优秀的粒子提供了优良的基础。
2.4 粒子位置与速度的更新
粒子群算法中,只有当粒子的当前位置与所经历的最好位置相比具有更好的适应值时,其粒子所经历的最好位置才会唯一地被该粒子当前的位置所替代[14-15]。第i个粒子经历过的最好位置(有最好适应度)记为pbi=(pbi1,pbi2,…,pbin),在整个群体中,所有粒子经历过的最好位置记为gb=(gb1,gb2,…,gbn)。s代表群体的大小。分别用式(6)、(8)得出的两个适应度计算pb、gb:
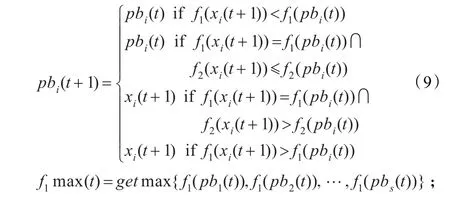
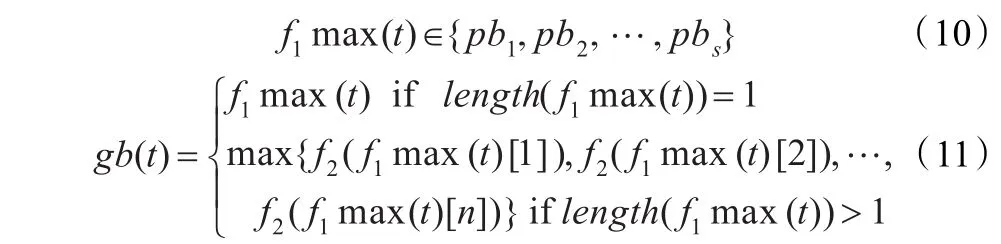
每一代粒子根据下面公式更新自己的速度和位置,首先利用粒子自身的最佳飞行位置pb[16]作用于当前位置,然后根据群体最佳位置gb对当前粒子位置进行调整。
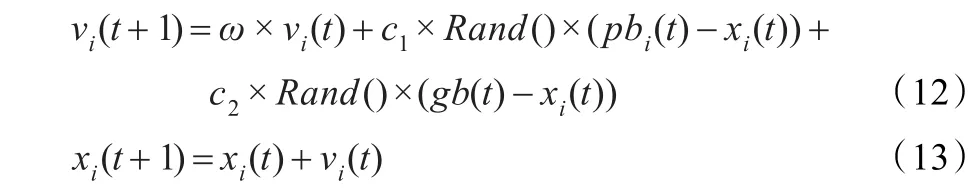
其中,t表示迭代次数;ω为惯性权重,使粒子保持运动惯性,防止算法的早熟收敛;c1和c2是学习因子[17];Rand为[0,1]之间的随机数。迭代过程中,粒子的速度和位置都限制在特定的范围内[18-19],同时pb和gb不断更新,最后输出的gb就是全局最优解。
3 仿真实验与分析
3.1 仿真实验环境及算法设置
为了评价和分析本文算法的性能,实验是采用Matlab产生ETC[13]矩阵,首先用CloudSim[20]对传统PSO算法和具有双适应度的PSO算法进行了云环境下的仿真实验,继而在相同的仿真平台下对此两种算法进行横向对比。实验测试各运行100次,取100次实验的平均结果作为作图的数据。

表3 算法主要参数
通过多次实验并参考文献[21-22]的参数调整策略,两种算法参数按表3设置,可以在较短的时间内取得优质解。
其中,每个任务划分成的子任务个数范围为[30,70],各个子任务的预计完成时间在[1,60]区间上随机产生,单位为s。算法终止条件为:(1)达到最大迭代次数tmax;(2)连续60次总任务完成时间与任务平均完成时间都没有变化。
3.2 实验结果和性能分析
图2~图7为云计算环境下,基于传统PSO的任务调度算法和本文提出的基于DFPSO的任务调度算法在任务总完成时间和任务平均完成时间两个方面的对比。
图2和图3中任务数Task=50,其迭代过程可看出PSO算法和DFPSO算法的前期迭代过程基本一致,得出的任务总完成时间和任务平均完成时间相差不大。随着粒子迭代更新次数的增大,两种算法所得到的任务总完成时间和任务平均完成时间都在不断地减小,且DFPSO算法所得调度结果在任务总时间和任务平均完成时间上要小于传统PSO算法。

图2 Task=50时的任务总完成时间
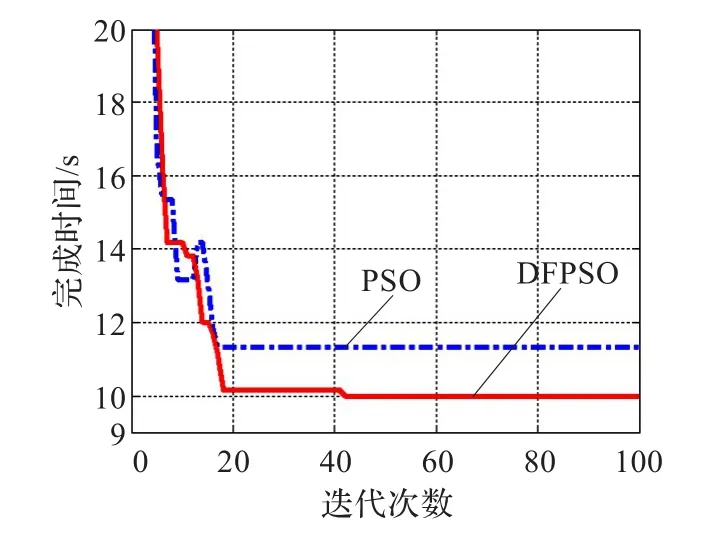
图3 Task=50时的任务平均完成时间
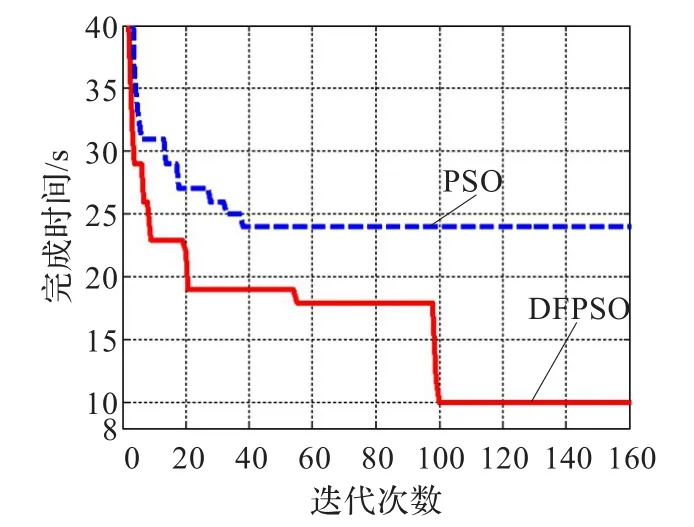
图4 Task=100时的任务总完成时间

图5 Task=100时的任务平均完成时间
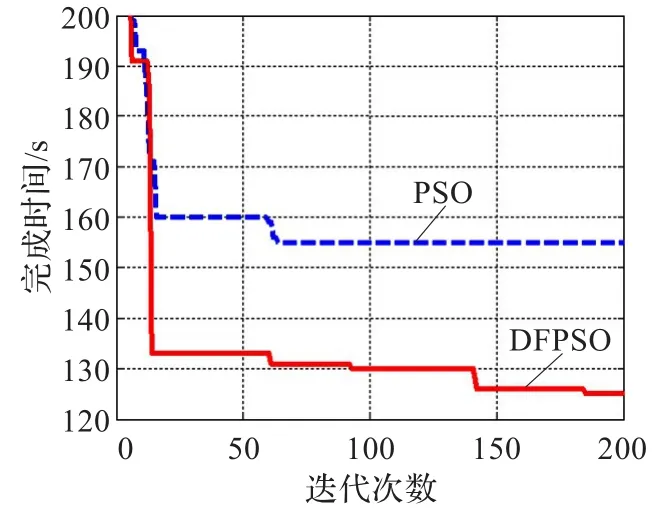
图6 Task=500时的任务总完成时间
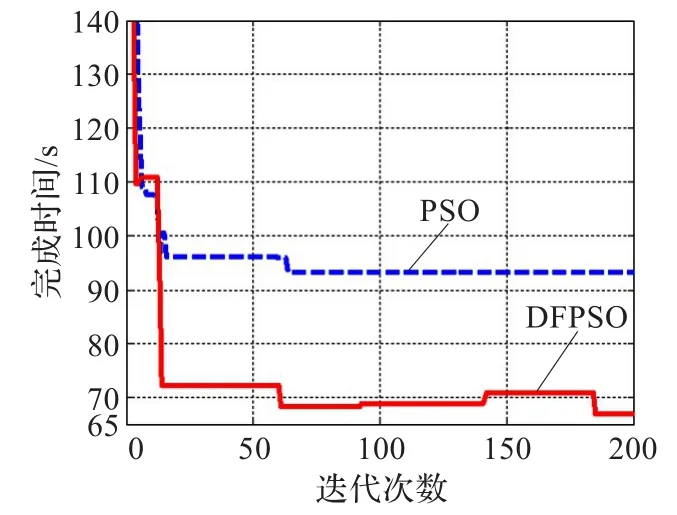
图7 Task=500时的任务平均完成时间

图8 优化效果总体对比图
当任务数Task增加到100时,通过比较图4与图5,可以看出两种算法所得到的任务总完成时间和任务平均完成时间的差距拉大。
其中传统PSO算法收敛速度很快,迭代到40次后,由于任务总完成时间和任务平均完成时间都没有任何变化,传统PSO算法收敛于自己的最优调度结果,但所得任务调度结果的任务总完成时间和任务平均完成时间都较大。DFPSO算法所得任务调度结果的任务总完成时间和任务平均完成时间,分别比传统PSO算法所得调度结果优化了14 s和11 s,从而验证了在传统PSO算法中多加入一个适应度的有效性。
计算资源数量Resource不变,任务数Task继续增加到500,从图6和图7可以看出,两种算法所得调度结果的任务总完成时间和任务平均完成时间的差距随之达到30 s和28 s。随着任务数量加大,通过DFPSO算法进行任务调度,得到了任务总完成时间和任务平均完成时间都更小的调度结果,充分地利用了现有云资源,提高了任务调度的效率。
通过图8可以得出结论,采用DFPSO算法对云中任务进行调度,有效地减少了任务总完成时间和任务平均完成时间,提高了用户的满意度。在云中资源不增加的情况下,随着用户任务数量不断的增加,DFPSO算法的综合调度性能也呈现上升趋势,进一步验证了DFPSO算法的有效性。
从以上实验结果反映出,传统PSO算法因为只重视总任务的完成时间,造成了一些潜在优良的粒子丢失。虽然提高了自己的收敛速度,但该算法在运行过程中由于无法有效跳出局部最优的搜索状态而过早地收敛到局部最优的任务调度结果上,得到的任务调度结果不论是任务总完成时间还是任务平均完成时间都较大。本文在传统的PSO算法的基础上增加一个适应度,最终形成了DFPSO算法。该算法由于同时考虑任务总完成时间和任务平均完成时间,需对每个任务进行计算,尽管在收敛速度上比PSO算法有所下降,但该算法的调度结果不但任务总完成时间短,任务的平均所用时间也短。因此,对于DFPSO算法和传统PSO算法的比较,从以一定收敛速度的损失来换取能够得到明显更优的调度结果的能力方面来说,DFPSO算法优于传统PSO算法。通过DFPSO算法进行任务调度可以找到明显更小的任务总完成时间,是一种云计算环境下的有效任务调度算法。
4 总结
在粒子群优化算法的基础上,针对云计算的编程模型,提出了一种具有双适应度的粒子群(DFPSO)算法的任务调度算法。本文算法在进行任务调度时不仅考虑总任务完成时间,同时也考虑到了任务的平均完成时间。仿真实验结果表明,本文算法对云计算环境下这种编程模式可以实现较为理想的任务调度结果。下一步工作,是如何在保证任务调度效率的同时提高此算法的收敛速度。
[1]Sims K.IBM introduces ready-to-use cloud computing collaboration services get clients started with cloud computing[EB/OL].(2007)[2011-12].http://www.ibm.com/press/us/en/pressrelease/ 22613.wss.
[2]Boss G,Malladi P,Quan D,et al.Cloud computing.IBM White Paper[EB/OL].(2007)[2011-12].http://download.boulder.ibm.com/ ibmdl/pub/software/dw/wes/hipods/Cloud_computing_wp_final_ 8Oct.pdf.
[3]Rochwerger B,Breitgand D,Levy E,et al.The reservoir model and architecture for open federated cloud computing[J].IBM Journal of Research and Development,2009,53(4):1-17.
[4]Nurmi D,Wolski R,Grzegorczyk C,et al.The eucalyptus opensource cloud-computing system[C]//Proceeding of the Crid,2009:124-131.
[5]Armbrust M,Fox A,Griffith R,et al.Above the clouds:a berkeley view of cloud computing,Technical Report No.UCB/EECS-2009-28[R].USA:UC Berkley,2009:1-25.
[6]Amazon SimpleDB[EB/OL].(2011-08-10)[2011-12].http://aws. smazon.com/simpledb/.
[7]Barroso L A,Dean J,Holzle U.Web search for a planet:The Google cluster architecture[J].IEEE Micro,2003,23(2):22-28.
[8]Jeffrey D,Sanjay G.MapReduce:simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[9]Dean J,Ghemawat S.Distributed programming with MapReduce[M]//Oram A,Wilson G.Beautiful Code.Sebastopol:O’Reilly Media,Inc,2007:371-384.
[10]Jeffrey D,Sanjay G.MapReduce:simplifed data processing on large clusters[C]//Proceedings of the Conference on Operating System Design and Implementation(OSDI),San Francisco,USA,2004:137-150.
[11]Eberhart R C,Kennedy J.A new optimizer using particles swarm theory[C]//Proc of the 6th Int’1 Symp on Micro Machine and Human Science.Nagoya:IEEE Inc,1995:39-43.
[12]Bratton D,Kennedy J.Defining a standard for particle swarm optimization[C]//ProceedingsoftheIEEESwarmIntelligence Symposium,Honolulu,HI,2007:120-127.
[13]Ali S,Siegel H J,Maheswaran M,et al.Representing task and machine heterogeneities for heterogeneous computing systems[J].Journal of Science and Engineering,2000,3(3):195-207.
[14]Clerc M,Kennedy J.The particle swarm-explosion,stability,and convergence in a multidimensional complex space[J].IEEE Trans on Evolutionary Computation,2002,6(1):58-73.
[15]Li N,Sun D B,Zou T,et al.An analysis for a particle’s trajectory of PSO based on difference equation[J].Chinese Journal of Computers,2006,29(11):2052-2061.
[16]Ratnaweera A,Halgamuge S K,Watson H C.Self-organizing hierarchical particle swarm optimizer with time-varying acceleration coefficients[J].IEEE Trans on Evolutionary Computation,2004,8(3):240-255.
[17]Parsopoulos K E,Vrahatis M N.Recent approaches to global optimization problems through particle swarm optimization[J]. Natural Computing,2002,1(2/3):235-306.
[18]Eberhart R,Shi Y.Particle swarm optimization:developments,applications,and resource[C]//Proceedings of the IEEE International Conference on Evolutionary Computation,Piscataway,NJ,2001:81-86.
[19]Said M,Ahamed A.Hybrid periodic boundary condition for particle swarm optimization[J].IEEE Transactions on Antennas and Propagation,2007,55(11):3251-3256.
[20]Calheiros R N,Ranjan R,Beloglazov A,et al.CloudSim:a toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithms[J].Software:Practice and Experience,2010,41(1):23-50.
[21]Chen G L,Guo W Z,Chen Y Z.A PSO-based intelligent decision algorithm for VLSI floor planning[J].Soft Computing,2010,14(12):1329-1337.
[22]李晓东,张庆红,叶瑾琳.基于仿真的优化的粒子群算法参数选取研究[J].计算机工程与应用,2011,47(33):30-35.
ZHANG Tao,YU Jiong,YANG Xingyao,LIAO Bin
School of Information Science and Engineering,Xinjiang University,Urumqi 830046,China
How to schedule tasks efficiently is one of the key issues to be resolved in cloud computing environment.A Double Fitness Particle Swarm Optimization algorithm(DFPSO)based on conventional Particle Swarm Optimization(PSO)is brought up for the programming framework of cloud computing.Through this algorithm,the better task scheduling not only shortens total task completion time and also has shorter average task completion time.Simulation results show that DFPSO is better than PSO, and the integrated scheduling performance is excellent,especially when the number of tasks increases.
task scheduling;cloud computing;Particle Swarm Optimization(PSO)algorithm;double-fitness
如何对任务进行高效合理的调度是云计算需要解决的关键问题之一,针对云计算的编程模型框架,在传统粒子群优化算法(PSO)的基础上,提出了一种具有双适应度的粒子群算法(DFPSO)。通过该算法不但能找到任务总完成时间较短的调度结果,而且此调度结果的任务平均完成时间也较短。仿真分析结果表明,在相同的条件设置下,该算法优于传统的粒子群优化算法,当任务数量增多时,其综合调度性能优点明显。
任务调度;云计算;粒子群算法;双适应度
A
TP311
10.3778/j.issn.1002-8331.1201-0022
ZHANG Tao,YU Jiong,YANG Xingyao,et al.Improved Particle Swarm Optimization algorithm for cloud computing task scheduling.Computer Engineering and Applications,2013,49(19):68-72.
国家自然科学基金(No.60863003,No.61063042);新疆大学博士科研启动基金(No.BS090153)。
张陶(1988—),女,硕士研究生,主要研究领域为云计算,网格与分布式计算;于炯(1964—),男,教授,博士,主要研究领域为网络安全,网格与分布式计算;杨兴耀(1984—),男,博士研究生,主要研究领域为数据库,网格与分布式计算;廖彬(1986—),男,博士研究生,主要研究领域为网格与分布式计算。E-mail:zt59921661@126.com
2012-01-09
2012-03-21
1002-8331(2013)19-0068-05
猜你喜欢
计算机仿真(2022年8期)2022-09-28
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
制造技术与机床(2019年4期)2019-04-04
测控技术(2018年7期)2018-12-09
疯狂英语·新读写(2018年3期)2018-11-29
中国塑料(2016年11期)2016-04-16
信息通信技术(2015年6期)2015-12-26
华东理工大学学报(自然科学版)(2015年4期)2015-12-01
