
基于向量相似度的招聘就业双向推荐模型
2013-07-19 01:57刘兴林吴明芬刘利伟
中国科技信息 2013年21期
刘兴林 吴明芬 刘利伟
五邑大学计算机学院,广东 江门 529020
引言
当前我国就业形势越来越严峻,随着我国诸多教育政策的不断推出与执行,社会的飞速发展这个大的背景下,高等教育的生源越来越广泛,高等教育为了国家政策和社会的需要不断地扩招[1],2013年新增就业大学生达699万,这导致就业的力越来越大。尽管每年的毕业生在增多,但仍然存在一些企业出现招工难的问题,这里主要的问题是招聘不到合适的人才。据调查统计,江门市劳动力资源在数量上较为丰富,然而就业结构不太合理,劳动力文化素质普遍偏低,高端技术型工种人才较短缺,“招工难”与“就业难”问题并存[2]。
为解决就业存在的各种问题,结合当前江门市的就业形势,我们设计了基于向量相似度的招聘就业双向推荐模型,为应聘者和企事业招聘搭建了一个桥梁,找到各自合适的岗位和人才。该模型在投入应用后,取得了较好的成效。
1 相关工作
当前就业推荐采用的方法主要有层次分析法[3,4],数据挖掘[5],聚类分析[6],随机游走[7]等。
层次分析法由T. L. Saaty[8]首次,是定量和定性分析相结合的多目标决策方法,它能够有效地分析目标准则体系层次间的非序列关系,便于综合测决策的判断和比较,多用于社会、经济和管理等方面。陈玉峰等[3]根据农民工的特征,采取不同的信息收集方式来采集农民工基本信息特征及操作信息并利用ID3算法进行了相关计算,在此基础上,引入层次结构模型设计方法,提出了更符合农民工特征的用户模型及其表示方法,能更有效地实现农民工就业岗位的快速推荐。高晓霞等[4]利用层次分析法建立了高职学生就业推荐综合测评模型,通过对定性因素加以量化并构造判断矩阵,进行一致性检验,给出了一种公开、公平的开展高职学生就业推荐的方法。层次分析法的应用较为广泛[8-10],文献[3]和文献[4]将该方法应用于就业推荐,对就业工作起到了较好的促进作用,但层次分析法模型较为复杂,在构造就业推荐模型时需要大量的权重设置和计算,因此在效率上有所限制。
陈玉峰等[5]前面的研究基础上,深入分析数据挖掘理论与农民工的主要特征要素,采用决策树模型中的ID3算法,对样本进行整理、转换以及分类,构建了一个基于数据挖掘的农民工就业推荐系统,从海量的信息中发现规律和知识,为企业单向推荐相关技术人才。
李晶等[6]将聚类分析应用于就业推荐,将应聘者和招聘企业数据通过相关度处理,使用改进粒子群优化的聚类分析算法,实现招聘企业与应聘者的相互推荐.解决了推荐信息无用、杂乱等实际问题。这种方法将招聘方和应聘方同等处理,忽略了从双方各自更关注的信息角度出发考虑问题,比如对于应聘者,在向其推荐企业时,显然在同等条件于待遇高的企业要优先推荐,反过来,对于招聘方而言,则希望将薪酬要求低的应聘者优先推荐。
吴迪等[7]设计并实现了一个基于随机游走的就业推荐系统,通过比较应届和往届毕业生基本特征,并结合基于随机游走模型的PageRank算法获得的各个企业的“求职指数”,将招聘企业排序后推荐给每一名毕业生。经实际数据测试,该系统能有针对性的为毕业生推荐相关企业,有较好的效果。
在上述研究中,主要是单向的推荐,采用层次分析法在运行效率上有所欠缺,为更高效的解决就业双向推荐的问题,我们提出了基于向量相似度的招聘就业双向推荐模型,该模型将就业意向和招聘信息看成一条向量,抽取两者共有的重要因素作为组成向量的分量,并对其进行量化,通过计算它们之间的相似度来实现双向推荐。
2 基于向量相似度的招聘就业双向推荐模型
基于向量相似度的招聘就业双向推荐模型分以下四个步骤进行。
2.1 筛选
由于实际的招聘应聘数据量达到50万以上,为了降低模型的计算量,提高运算效率和准确率,在进行双向推荐时对求职意向和招聘信息进行了筛选,主要进行以下筛选操作。
(1)空值筛选
考虑到某些信息填写不完够整,系统会对大部分数据根据求职者信息和企业登记信息进行自动填写,但有些数据无法补充完整,模型在运行时则将这部分空值数据过滤掉,以保证进行模型数据的完整性。
(2)资格筛选
资格筛选主要考虑的是发布的求职意向和招聘信息是否过期,另外也要将已经求职成功和招聘成功的记录过滤掉。
(3)条件筛选
条件筛选是对所在的求职意向作招聘进行筛选,若为求职者推荐岗位,则以求职者个人的信息为标准,对招聘信息进行筛选;若为企业推荐求职者,则以招聘企业的要求为标准,对求职者进行筛选。条件筛选的主要有以下几个方面:对工种,按工种编码先使用商用细类代码进行完全匹配筛选,若无数据再回退使用前4位进行部分匹配筛选;对学历进行覆盖筛选,对求职者而言,以求职者的学历对招聘企业进行筛选时,筛选出学历招聘要求等于或低于求职者学历的招聘信息,反之则筛选出等于或高于企业学历要求的求职者。
2.2 向量的生成
每条招聘信息或求职意向生成一个向量,该向量的各分量为招聘企业或求职者的各个条件,所有招聘信息或求职意向各自形成一个向量集。如,企业招聘信息向量:招聘(工种,学历,职称,年龄,性别,薪酬,住宿要求,工作地点,…),个人求职信息向量:求职(工种,学历,职称,年龄,性别,薪酬,住宿要求,工作地点,…),可以看到两个向量的各个分量是一一对应的。生成向量时考虑到企业和求职者的实际情况以及双向所注重的因素,本模型向量只采用了工种,学历,职称,年龄,性别,薪酬,食宿要求和工作地点这8个分量。
为便于算法模型描述,将上述向量进行形式化:
2.3 向量量化
2.3.1 量化规则
为企业推荐求职者时以企业招聘信息向量为标准向量,其各个分量的值设为1,对于筛选出来的个人求职信息向量集,其每个向量的每个分量的取值范围为[0,1],完全不匹配取值0,完全匹配或不限制取值为1。对个人求职而言,以个人求职信息向量为标准向量,其各个分量的值设为1,对于筛选出来的企业招聘信息向量集,其每个向量的每个分量的取值范围为[0,1],完全不匹配取值0,完全匹配或不限制取值为1。
对向量各分量(建立映射表)逐一进行量化,各分量量化值为预设值(可根据模型运行情况调整),在充分的实验基础之上,考虑按工种为各分量设定不同的量化值。各分量量化基本规则如下。
(1)工种
以工种编码作为量化的基础,向企业推荐求职者和向求职者推荐岗位均采用以表1数据作为量化的依据。

表1 工种量化表
(2)学历
在对学历进行量化时,分两种情况,一是向企业推荐求职者,二是为求职者推荐岗位。
向企业推荐求职者时,采取以下原则:在其他条件相同的情况下,优先向企业推荐高学历的求职者。根据这个原则设定表2数据作为向企业推荐求职者时匹配向量的量化依据。
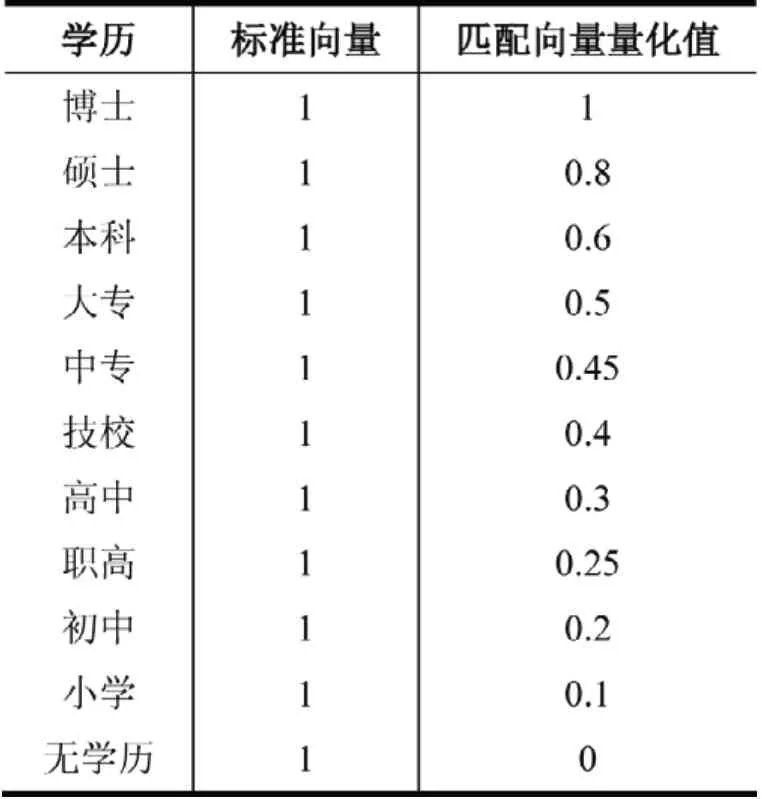
表2 推荐求职者学历量化表
若向求职者推荐岗位,则在满足招聘条件的前提下,优先向求职者推荐最接近求职者学历的企业,比如,求职者的学历为本科,则筛选出来的企业对学历要求为本科及以下的所有招聘信息,在向求职者推荐时将学历要求为本科的排在前,其他学历依次往后排。
在量化时,参照表2的匹配向量量化值,采用公式1对企业招聘信息学历要求进行量化。

其中,为求职者学历按上表对应的量化值, 为企业学历要求按上表对应的量化值。
(3)职称/技术等级
对职称和技术等级进行量化时,参照表3进行。

表3 职称/技术等级量化表
由于当前系统中并没有填写该字段信息,模型实际运行时将该分量设为0,即不考虑该分量对推荐的影响。
(4)年龄
当向企业推荐求职人员时,考虑到在其他条件相同的前提下,企业更期望招聘年轻些的求职者,因此在量化时将更年轻的求职者量化为较高的值,年龄大的求职者量化较低的值,采用公式2对求职人员的年龄进行量化。
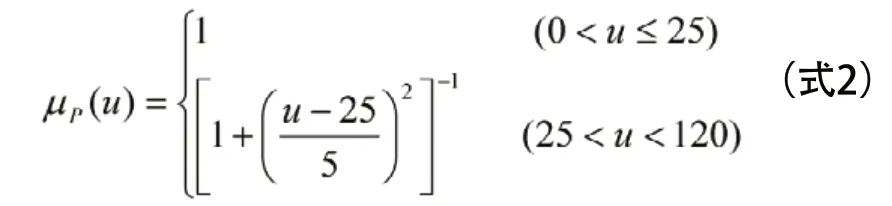
式2表示,不大于25岁的人,对子集“年轻”的隶属函数值是1,即一定属于这一子集;而大于25岁的人,对子集“年轻”的隶属函数值按来计算,例如对40岁的人,隶属函数值
当向求职者推荐招聘岗位时,采用区间量化的方案进行量化。设年龄的取值集合为U={50岁,45岁, 40岁 ,35岁,30岁, 25岁},模糊集“年青”可表示为:
A=0/50岁+0.1/45岁 + 0.3/40岁 + 0.5/35岁 + 0.9/30岁 +1/25岁,若年龄介于(50,45)之间,则量化为一个(0,0.1)间的一个值,其他以此类推。
(5)性别
对性别进行量化时,分别采用表4和表5量化值进行量化。

表4 向企业推荐求职者性别量化表

表5 向求职者推荐岗位性别量化表
(6)薪酬
当向企业推荐求职者时,从企业招聘角度出发考虑,仅就薪酬这个因素而言,会优先考虑对薪酬期望值更低的求职者,因此在向企业推荐求职者时,将开出薪酬更低的求职者排在前面,因此构造以下量化规则。
设企业薪酬最低值为aavg,求职者薪酬要求最低值为:a1,a2,…,an,令M=max(a1,a2,…,an), m=min( a1,a2,…,an),则企业薪酬为标准向量,其值为1,求职者薪酬按公式3进行量化。

若6e 为负数,则令其为0。
当向求职者推荐岗位时,分析求职者对薪酬的心理期望,显然会更优先考虑开出薪酬更高企业,因此在向求职者推荐岗位时,将开出薪酬更高的企业排在前面,因此构造以下量化规则。
11月26日,机电一体化专家博泽中国太仓新生产基地举行了开业庆典仪式。博泽太仓新工厂总建筑面积达7.3万 m2,总投资额达14亿元人民币。新工厂将生产近全系列博泽产品,包括车门系统、玻璃升降器、门锁模块、座椅系统、座椅导轨、座椅电动机等。客户涵盖国内外知名整车制造商,包括福特、吉利、捷豹路虎、大众、沃尔沃等。此外,新工厂分为一期和二期,目前一期工厂已投入使用,二期工厂正在建设之中。未来,二期工厂大部分是用于座椅的垂直生产,包括冲压、喷涂、激光焊接和整椅的组装产线等。随着二期的落成,至2024年工厂预计将拥有1 600多名员工,年营业额将突破58亿元人民币,规模列博泽亚洲第一。
设求职者薪酬要求的最低值为aavg,企业薪酬最低值为:a1,a2,…,an,令M=max(a1,a2,…,an), m=min( a1,a2,…,an),则求职者薪酬为标准向量,其值为1,企业薪酬按公式4进行量化。
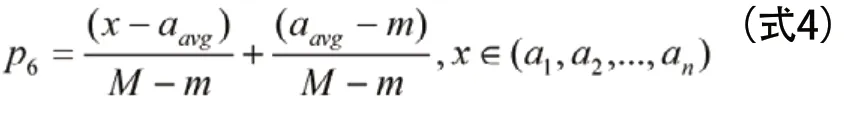
(7)食宿要求
当向企业推荐求职者时,从企业招聘角度出发考虑,仅就住宿要求这个因素而言,会优先考虑对食宿要求越低的求职者,因此在向企业推荐求职者时,将食宿要求越低的求职者排在前面,建立以下映射表(表6)进行量化。
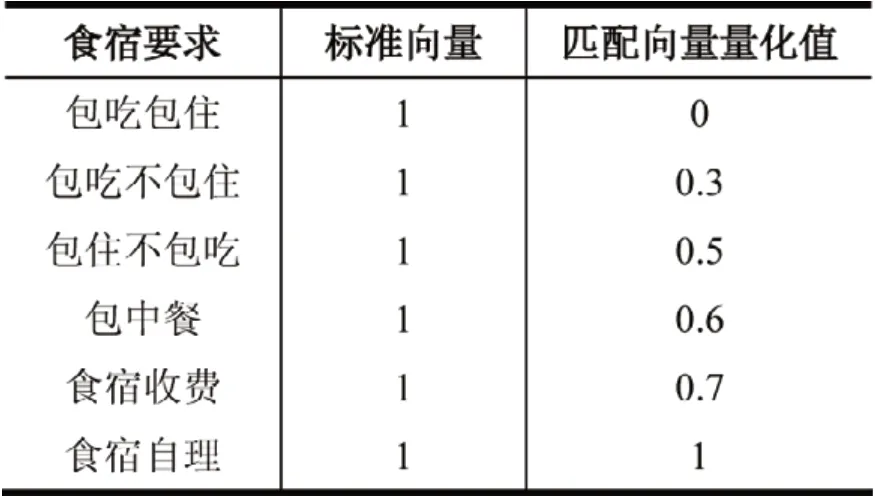
表6 向企业推荐求职者食宿要求量化表
当向求职者推荐岗位时,分析求职者对食宿要求的心理期望,显然会更优先考虑能够解决住宿问题的企业,因此在向求职者推荐企业时,将住宿条件更好的企业排在前面,建立以下映射表(表7)进行量化。

表7 向求职者推荐岗位食宿条件量化表
(8)工作地点
当前模型仅对江门地区的工作地点进行量化,根据行政区域编码的匹配度来进行量化。行政区域编码共10位,其中前6位编码及表示的地区如下:440703(蓬江区),440704(江海区),440705(新会区),440781(台山市),440783(开平市),440784(鹤山市),440785(恩平市),编码中第7-8位表示镇及街道,第9-10位表示村。
建立表8对工作地点进行量化(为企业推荐求职者和为求职者推荐岗位均按该表进行量化)。

表8 工作地点量化表
2.3.2 量化实例
系统随机生成20万条求职信息和10万条招聘信息,用于模型测试用。模型在量化时,按推荐求职者和推荐岗位来采用相应的量化规则进行量化,下面给出一组量化实例。
(1)向企业推荐求职者
从数据库中抽取招聘编号为“1”的招聘信息,如表9所示。

表9 编号为“1”的招聘信息
由于数据库中存储的各字段内容为相应的编码,因此表9中给出也是相应的编码(以下同),代表不同的含义(性别列中值为3表示男女不限)。在为该招聘推荐求职者时,该招聘记录向量为标准向量,除“职称/技术等级”分量外各分量均量化为1,即招聘向量1(工种,学历,职称,年龄,性别,薪酬,住宿要求,工作地点)量化为E1(1,1,0,1,1,1,1,1)。
模型为该招聘信息筛选推荐出以下求职者,如表10所示,相应的,各字段给出的也是编码(以下同)。

表10 为“1”号招聘筛选推荐出的求职者信息
模型按2.3.1节的量化规则对求职者信息进行量化,得到表11所示的量化结果。

表11 求职者信息量化结果
为尽可能区分各求职者与招聘要求之间的差距,表11中的量化结果按四舍五入的规则取四位小数。
(2)向求职者推荐岗位
从数据库中抽取求职编号为“1”的求职者信息,如表12所示。

表12 求职编号为“1”的求职者信息
在为该求职者推荐岗位时,该求职信息向量为标准向量,除“职称/技术等级”分量外其余各分量均量化为1,即求职向量1(工种,学历,职称,年龄,性别,薪酬,住宿要求,工作地点)量化为P1(1,1,0,1,1,1,1,1)。
模型为该求职者筛选推荐出以下岗位信息,如表13所示。
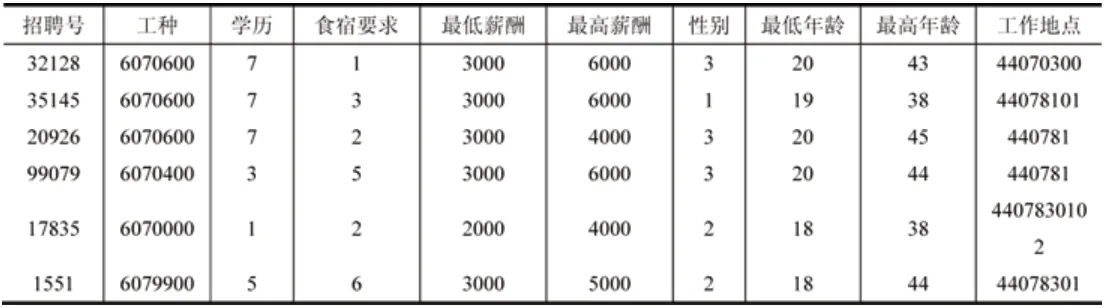
表13 为“1”号求职者筛选推荐出的岗位信息
模型按2.3.1节的量化规则对岗位信息进行量化,得到表14所示的量化结果。

表14 岗位信息量化结果
为尽可能区分各岗位信息与求职者要求之间的差距,表11中的量化结果按四舍五入的规则取四位小数。
2.4 相似度计算
在为企业推荐求职者,或为求职者推荐岗位时,需要计算他们之间的匹配度,匹配度根据2.3节的量化结果进行计算,即计算每条推荐向量与标准向量之间的相似度,然后按这个相似度从高到低排序,使得更符合的求职者或岗位能排在前面。
向量相似度的计算采用夹角余弦公式来计算,计算公式如式5所示。

其中分子和分母分别按公式6和公式7来计算。

就2.3.2节的例子(在本节已将相关的编码转换为对应的含义,这样便于分析比较匹配度结果),采用向量相似度计算公式来计算,向企业和求职者分别进行推荐,进行就业信息匹配,得到以下结果表15、表16、表17和表18所示结果。
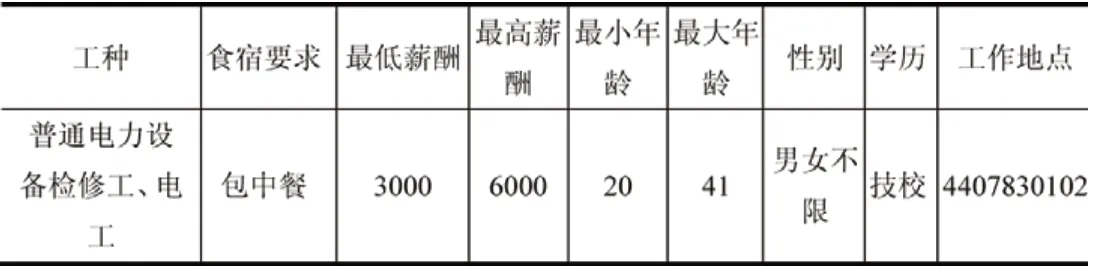
表15 招聘编号为“1”招聘信息

表16 “1”号招聘的推荐结果

表17 “1”号求职者信息

表18 “1”号求职者的推荐结果
由于测试数据是随机生成的,而算法在向企业推荐求职者时,在其他条件相等的情况下优先推荐推荐学历更高的求职者,因此会出现表16中博士、硕士去应聘电工这个工种的情况,实际情况不会出现这种现象。
从上述就业信息匹配实例来看,基于向量相似度的招聘就业双向推荐模型能较好实现招聘与应聘的对接,算法模型取得了较好的效果。
3. 实验结果分析与比较
本节实验主要考察模型的运行效率,模型的准确性在第2节已得到了验证。
3.1 测试数据集实验结果分析
模型实验测试在随机生成的20万条求职信息和10万条招聘信息数据集上进行,模型运行在以下配置的机器上:Windows7操作系统,CPU为AMD双核5000,2G内存,500G硬盘,从筛选、量化和相似度计算三个环节考察模型双向推荐的运行效率,共进行了6组实验,平均结果如表19所示。
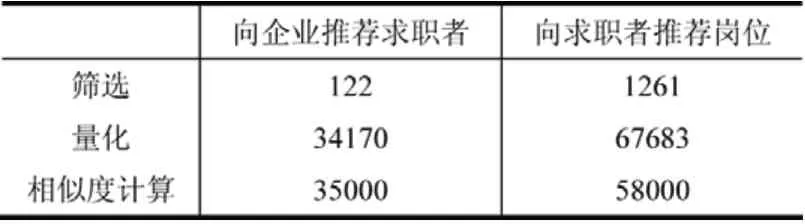
表19 测试数据集模型运行效率(单位:条/秒)
表19的结果显示,该模型大部时间消耗在筛选阶段,量化和相似度计算阶段取得了较好的运行效率。
3.2 实际数据运行结果分析
模型投入实际运行后,实际招聘应聘的数据规模约50万条。从筛选、量化和相似度计算三个环节考察模型双向推荐的运行效率。实际系统配置了IBM System X3850系列服务器(2颗Xeon E7-4807 1.86GH,16GB内存,4TB硬盘),硬件性能的提升也使模型的效率得到大幅度的提升。实际运行结果如表20所示。

表20 实际数据集模型运行效率(单位:条/秒)
表20的结果显示,模型在实际数据集上亦能取得很好的运行效率。同时,从企业和求职者的反馈信息分析,模型能较好的实现招聘就业双向推荐,能为双向推荐最合适的岗位和人才,实现了双赢。
4 结语和下一步的工作
本文实现了一个基于向量相似度的招聘就业双向推荐模型,通过将招聘和求职信息转化为向量,并按不同规则对不同分量进行量化,采用夹角余弦公式计算向量间的相似度,并以此作为双向推荐的标准,模型在测试数据集和实验数据集上均取得了较好的效果。
进一步的工作主要有:1)优化各分量量化数值,目前模型采用的是经验值,在模型稳定运行后,需要根据实验情况来调整量化值,使用模型更为合理;2)考虑到在招聘和应聘的过程中,对各个分量有侧重,当前模型中各个分量的权重是一致,在后续的改进中将对各分量进行权重调整,以突出关键分量的重要性;3)优化模型算法,提高运行效率。实验结果和实际运行情况表明,模型在筛选阶段占用大量时间,直接影响了模型的效率,尽管由于机器性能的提升能提高效率,但仍需要不断优化模型,以适应大数据集的需要。
[1]李英. 浅析当今我国高校研究生就业现状[J]. 神州, 2013, (3): 240.
[2]柳彦君. 江门市劳动力资源与就业状况研究[J]. 北方经贸, 2012, (10): 38-40.
[3]陈玉峰, 张红燕, 敬松, 谢元瑰, 隆珂. 基于层次结构的农民工就业特征模型研究[J]. 中国农学通报, 2013, 29(11): 101-106.
[4]高晓霞. 层次分析法在高职学生就业推荐中的应用[J]. 读与阅杂志, 2010, 7(12): 46-47.
[5]陈玉峰, 张红燕, 敬松, 谢元瑰. 基于数据挖掘的农民工就业推荐系统构建[J]. 安徽农业科学, 2011, 39(33): 20896-20898.
[6]李晶, 张磊. 聚类分析在就业推荐中的应用[J]. 科技信息, 2010, (31): 149.
[7]吴迪, 周利娟, 林鸿飞. 基于随机游走的就业推荐系统研究与实现[J]. 广西师范大学学报: 自然科学版, 2011, 29(1): 179-185.
[8]Saaty T. L.. Modelinugn structuredde cisiopnr oblems-ththee ory of analytical hierarchies[J]. MathemaCtiocsm apnudt ers in Simiounla, 1t978, 20(3): 147-158.
[9]郭金玉, 张忠彬, 孙庆云. 层次分析法的研究与应用[J]. 中国安全科学学报, 2008, 18(5): 148-153.
[10]兰继斌, 徐扬, 霍良安, 刘家忠. 模糊层次分析法权重研究[J]. 系统工程理论与实践, 2006, (9): 107-112.
猜你喜欢
出版人(2022年11期)2022-11-15
英语文摘(2022年9期)2022-10-26
今日农业(2021年19期)2021-11-27
数学小灵通(1-2年级)(2021年10期)2021-11-05
疯狂英语·新悦读(2020年1期)2020-02-20
人大建设(2018年7期)2018-09-19
环球时报(2018-01-10)2018-01-10
新作文·高中版(2017年5期)2017-06-10
中国社会保障(2017年3期)2017-06-07
黄河黄土黄种人(2017年4期)2017-04-26
