
一种基于分类置信度差异性的协同训练算法
2013-07-16 06:00:04武永成
湖北民族大学学报(自然科学版) 2013年1期
武永成
(荆楚理工学院计算机工程学院,湖北荆门 448000)
在真实世界的许多问题中通常存在大量的未标记样本,但有标记样本则比较少.研究如何利用少量已标签样本和大量的未标签样本来提高学习性能的半监督学习(semi-supervised learning)已成为当前机器学习的重要研究领域之一[1].在各种半监督学习算法中,协同训练算法[2](co-training)是最流行的一种.在协同训练过程中,两个分类器分别从未标记样本中挑选出若干标记置信度较高的样本进行标记,并把标记后的样本加入另一个分类器的有标记训练集中,以便对方利用这些新标记的样本进行更新.协同训练的目的是,通过相互提供未知的信息,使得两个分类器的准确性都得以提高.研究表明,协同训练过程中,两个分类器的差异性越大,则最终协同训练的效果越好[3].最初的协同训练利用的是同一样本的两个不同视图之间的差异性[2].但在实际应用中,很难得到两个不同的视图.于是,不需要两个不同视图的协同训练算法被进行了广泛研究[4-5].
本文在对现有协同训练算法中分类差异性分析的基础上,提出了一种基于分类置信度差异的新的协同训练算法,.通过在12个UCI数据集上实验证明,该方法取得比具有代表性的协同训练算法更好的性能.
1 协同训练算法及其扩展
Bllum和Mitchel使用的co-training[2]要求必须满足两个前提条件:①每个视图必须是充分的,即在每个视图上学习器都可以学习得到一个分类器;②在确定类别(class)的前提下,视图之间是相互独立的.标准协同训练算法co-training使用的两个视图是自然生成的.如对于电子邮件的分类问题[2],两个视图中一个视图来自于邮件的头(email head),另一个视图来自于邮件的体(email body),它们从两个不同的方面对邮件的特征进行了描述.对于许多实际问题,并不存在上述相互独立且冗余的视图,即不满足Bllum和Mitchell在标准协同训练算法中提出的两个前提条件,此时co-training往往达不到预期的效果[6].因此在许多实际应用领域,标准协同训练算法co-training是不能使用的.为了能够利用标准协同训练算法,最直接的方法是对单视图的样本数据进行视图分割(即:将一个数据集合分成两个数据集合),人工地生成两个视图.文献[6]使用了该视图分割的方法,它是随机分割的,它没考虑标准协同训练算法中必须满足的两个前提条件.Goldman和Zhou首先提出了一种单视图的协同训练算法,即statistical co-training[4].与标准的协同训练算法不同,它的训练样本只有一个视图,但它使用两个不同的监督算法,一个是ID3(一种常见的决策树分类算法),另一个是HOODG(一种构造决策图的算法).ZHOU Zhi-hua等提出的tri-training[7]算法是通过增加集成的思想,将co-training算法进行扩展.该算法采用3个分类器进行学习,采用投票方式,如果2个分类器对无标记数据进行预测的结果一致,则将它加入第3个分类器的有标记样本集合进行训练.tri-training算法的最大特点是不需计算分类时的概率.在算法 co-fores[8]中,ZHOU Zhi-hua等对 tri-training进行扩展.分类器的个数为N(N≥3),分类的准确性对于Tri-training来说,有所提高.随之带来的问题是,因为采用投票(majority voting)方式,N个分类器的数据逐渐趋于相似,这反过来削弱了分类器的多样性(the diversity of classifiers).为保持分类器的多样性,co-forest中采用了Random Forest[9]集成学习方法(ensemble learning),而没采用Bagging集成学习方法.
2 基于分类置信度差异的协同训练算法
上述不同协同训练算法的一个共同点是:它们都利用了协同训练过程中各个分类器之间的差异性.学习过程中分类器之间差异越大,则提供给对方的信息越重要,越能提高最终协同学习的效果.表1对各种协同训练算法中分类差异性产生方法进行了小结.

表1 各种协同训练算法中分类差异性产生方法Tab.1 Taxonomy of SSL algoritih ms
本文提出的算法与statistical co-training算法很相似,也是一个视图,两种不同的基础分类算法.但比其更简单,采用了一种使分类置信度差异性最大的策略,避免了statistical co-training在对无标记数据标记时所做的复杂的判断.首先,从无标记集合U中随机选u个无标记样本放在集合M中(这u个数据从U中删除).然后,使用基础算法1和2,利用有标记训练样本集合L,训练得到两个分类器h1和h2.利用h1和h2,对集合M中的无标记数据进行分类,并记下分类的置信度(概率).对于M集合中那些分类类别相同(标记相同)、且分类置信度差异最大的无标记数据,给它们加上新预测的标记,并将它们添加到集合L中,即:使得L集合得到扩充.然后不断循环,使得L集合不断扩大,并在其上训练得到跟好的分类器h1和h2,直到程序规定的循环次数到达或者是U中的数据小于u时,程序结束.其算法如下.


3 实验
实验中用到12个UCI数据集[10].数据集的相关信息如表2所示.这些数据集都不满足标准协同训练的两个必要条件.对于每个数据集,25%的数据作为测试样本,其余的则作为训练样本,也就是:L∪U.L∪U组成的训练样本中,无标记数据的比例分别设为80%,60%.循环次数K设为30,M的大小为70,n的值设为4.采用的基础训练算法为决策树算法(J4.8)和朴素贝叶斯(NB).标准协同训练co-training作为比较算法.由于标准协同训练需要两个视图,随机地对表2中的数据进行了视图分割,将每个数据集分成具有两个视图的数据集.初始状态时的错误率是指:没有利用协同训练的思想,即根本没有利用无标记数据,而直接用基础算法(NB)在有标记训练样本上训练得到分类器,然后对该分类器进行测试得到的分类错误率.最好状态时的错误率是指:利用协同训练的思想,即利用有标记数据和无标记数据,经过协同训练,得到一个分类器并进行测试得到的分类错误率.improve=(initial-best)/initial.实验的相关结果如表3和表4所示.

表2 实验中用到的UCI数据集Tab.2 Enperimental UCI data sets
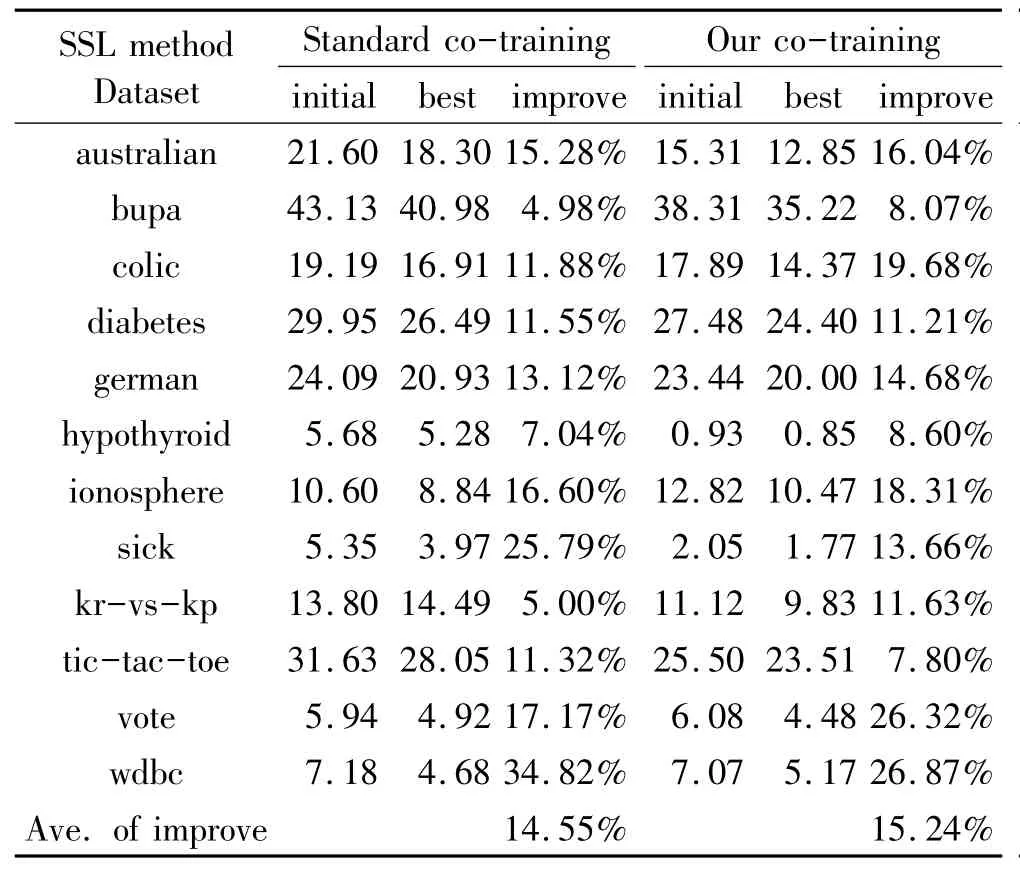
表3 无标记数据的比例在80%时,初始状态、最好状态下的分类错误率及相应的增长率Tab.3 Test error rates of the initial and best models and the relative improvements of under 80%unlabeling rate

表4 无标记数据的比例在60%时,初始状态、最好状态下的分类错误率及相应的增长率Tab.4 Test error rates of the initial and best models and relative improvemets of under 80%unbabeling rate
从表3和表4看出,协同训练的方法对于标准协同训练算法,在不同的无标记率下,都有较高的提高率,12个数据集上的平均提高率分别为15.24%和15.09%.而且,在80%的无标记率下,算法比标准的协同训练算法在8个数据集上的提高率都高;在60%的无标记率下,算法比标准的协同训练算法在9个数据集上的提高率都高.实验中的基础学习算法只用到J4.8和朴素贝叶斯.进一步的研究需在别的基础学习算法如人工神经网络和KNN(k-nearest neighbors classifier)等上展开.但总的来说,本文提出的基于分类差异性最大化的协同训练算法在解决半监督问题上是有效的.
4 结束语
协同训练是半监督学习中的一个热点.协同训练的本质是利用各个分类器之间的差异性进行相互学习,从而提高性能.论文分析了各种协同训练算法差异性的不同点,提出了一种基于分类置信度差异性的协同训练算法.实验验证了算法的有效性.半监督学习协同训练过程中,随着训练不断进行,自动标记示例中的噪音会不断积累,其负作用会越来越大.如何发现和处理这些噪音数据,将有待进一步研究.
[1]周志华.机器学习及其应用[M].北京:清华大学出版社,2007:259-275.
[2]Blum A,Mitchell T.Combining labeled and unlabeled data with co-training[C]//Proc of the 11th Annual Conf.on Computational Learning Theory(COLT 1998).Morgan Kaufmann,1998,pp.92-100.http://citeseer.ist.psu.edu/article/blum98combining.html.
[3]Zhou Z H,Li M.Semi-supervised learning by disagreement[J].Knowl Inf Syst,2010,24(3):415-439.
[4]Goldman S,Zhou Y.Enhancing supervised learning with unlabeled data[C]//Proceedings of the 17th International Conference on Machine Learning,2000:327-334.
[5]Zhou Y,Goldman S.Democratic co-learning[C]//Proceedings of the 16th IEEE International Conference on Tools with Artificial Intelligence(ICTAI’04),2004:594-202.
[6]Nigam K,Ghani R.Analyzing the effectiveness and applicability of co-training[C]//Proc of the 9th Int.Conf.on Information and Knowledge Management.New York:ACM,2000:86-93.
[7]Zhou Z H,Li M.Tri-Training:Exploiting unlabeled data using three classifiers[J].IEEE Trans On Knowledge and Data Engineering,2005,17(11):1529-1541.
[8]Li M,Zhou Z H.Improve computer-aided diagnosis with machine learning techniques using undiagnosed samples[J].IEEE Trans Syst Man Cybern,2007,37(6):1088-1098.
[9]韩家炜.数据挖掘概念与技术[M].北京:机械工业出版社,2004.
[10]Blake C,Keogh E,Merz C J.UCI repository of machine learning databases[http://www.ics.uci.edu/?mlearn/MLRepository.html],Department of Information and Computer Science,University of California,Irvine,CA,1998.
猜你喜欢
核科学与工程(2021年4期)2022-01-12 06:30:22
计算机应用(2018年5期)2018-07-25 07:41:26
电子测试(2018年1期)2018-04-18 11:52:35
中学生数理化·中考版(2017年6期)2017-11-09 02:46:46
非公有制企业党建(2017年10期)2017-11-03 02:26:27
现代兵器(2017年4期)2017-06-02 15:59:24
现代兵器(2017年4期)2017-06-02 15:58:14
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
轴承(2015年2期)2015-07-25 03:51:04
