
采用SVR模型进行嵌入率估计的隐写分析方法
2013-07-11 09:35孙子文
计算机工程与应用 2013年5期
孙子文,李 慧
江南大学 物联网工程学院,江苏 无锡 214122
采用SVR模型进行嵌入率估计的隐写分析方法
孙子文,李 慧
江南大学 物联网工程学院,江苏 无锡 214122
随着信息技术的快速发展,隐写术作为信息隐藏的重要分支,得到了快速的发展和广泛的应用。隐写分析是隐写术的对抗技术,并成为了信息隐藏领域的一个研究热点。目前有多种隐写分析算法能够有效地检测出隐写图像[1-3],但研究不止于此,隐写分析进一步检测嵌入信息的长度,最终提取隐写信息。目前只有少数文献[4-9]提出了能估计嵌入信息才长度的隐写分析算法,而且多数是针对专用隐写术的专用隐写分析算法[4-7]。
针对±k隐写算法,Fridrich等采用建模思想,应用高通滤波器和最大似然准则法估计秘密信息的长度[4]。结果显示该方法能准确估计JPEG隐写图的秘密信息长度。Jena等提出了针对LSB隐写的隐写分析算法[5],根据改进的差分图像直方图的统计结果建立方程,进一步计算LSB隐写图像的嵌入率,结果表明该方法比RS分析法和其他一般差分图像直方图方法更有效。Yu等研究了基于QIM的隐写算法,发现隐写图像的直方图跳跃点随着嵌入量变化,跳跃点间的间距随着量化步长变化,据此提出能检测隐写算法和估计隐写信息长度的方程[6]。Yang等针对MLSB隐写算法提出了新的能估计嵌入信息长度的隐写分析算法,根据位平面的重要性的优先级依次对隐写图的每层位平面用SPA算法估计信息嵌入改变率,得到的估计值比典型的SPA算法更准确[7]。
Fridrich等采用辨别统计函数估计秘密长度的思想[8]提出了能估计嵌入率的通用隐写分析方法。根据隐写图的极值点:净图s(0)和最大嵌入量的隐写图s(mmax)等求得辨别统计函数s(m)的相关参数,用s(m)的值估计嵌入信息的长度。Fridrich等结合文献[2]中的特征,利用线性最小二乘回归(Ordinary Least Square Regression,OLSR)和支持向量回归(Support Vector Regression,SVR)分别学习图像特征和相关嵌入改变率之间的映射关系并建立模型[9],并得到隐写长度。
为提高建模效率和估计值准确性,本文提出了采用新的特征提取方法和应用多重交叉验证法,改进文献[9]算法,得到新的可估计嵌入信息长度的通用隐写分析算法。从隐写图中提取全面反映分块离散余弦变换(Block Discrete Cosine Transform,BDCT)系数矩阵的块内、块间系数相关性的特征作为输入自变量,相关隐写图的嵌入改变率作为输出变量;结合SVR训练隐写图的特征和嵌入改变率,并利用多重交叉验证法寻找SVR的最优参数,建立隐写图特征和嵌入改变率的最佳映射模型。仿真结果显示:改进的隐写分析方法能准确估计不同容量的F5、outguess和MB隐写的信息嵌入改变率;特征的提取速度快、维数少,节省了建模时间。
1 本文隐写分析算法
隐写图的有效特征随嵌入改变率的变化而变化,从而可根据图像特征估算隐写图的信息嵌入改变率。本文通过SVR建立图像统计特征和嵌入改变率之间的映射模型实现隐写分析。
1.1 SVR模型用于隐写分析原理
SVR的目标是寻找一个能准确预测目标变量分布的平面[10]。设有一组训练数据:S={(x1,y1),(x2,y2),…,(xm,ym),xi∈Rn,yi∈R},其中xi表示输入特征,yi表示特征所对应的目标回归值,m为样本数目。将训练数据输入SVR,得到线性映射函数:
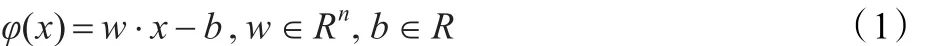
对每个xi而言,如果φ(xi)和 yi的值相近则认为函数φ(x)能从x预测y值,此w即为SVR所要寻找的预测平面。
本文隐写分析方法的主要思想是:利用SVR找到一个满足隐写图样本特征和嵌入改变率之间映射关系的函数。其中 xi=f(ci)表示第i个隐写图样本ci的特征,yi为ci的嵌入改变率,yi∈[0,1],SVR寻找满足式(2)的映射函数:
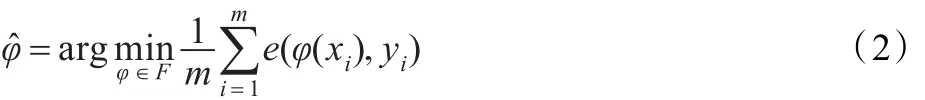
其中,e是损失函数,描述预测值和真实值误差的一个度量,F是关于φ的函数组。
ε-SVR是一种最常用的支持向量回归,它将问题(2)转化为下列问题:

其中ε≥0,用来表示允许SVR预测值与实际值最大的差距值。
SVR将图像特征从Rd空间模型映射到更高维向量空间Γ,将特征与嵌入改变率之间的非线性关系映射成线性关系,但样本内积计算繁琐,核函数能巧妙避免维数灾难,有效地解决这个问题。
假设验证所得的最优化函数组为:F={φ(x)=w·φ(x)-b|w∈Γ,b∈R},那么核函数k(x,x′),φ(x)和空间Γ满足:对于∀x,x′∈Rd,k(x,x′)=φ(x),φ(x′)Γ成立,其中<·,·>Γ是指在Γ空间的点积运算。高斯核函数(4)是常用的核函数之一:

为简单求得式(4)的优化函数,误差函数必须是凸函数,ε-insensitive损失函数(5)和Huber损失函数(6)是常用的误差函数:
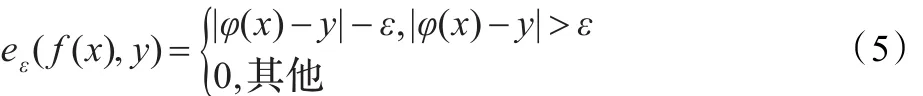
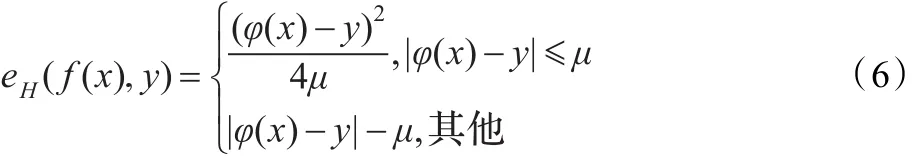
经测试,ε-insensitive损失函数和Huber损失函数的结果接近,选择其中之一即可。特征的有效性和参数的选取决定SVR回归预测的效果。
1.2 特征提取
典型的JPEG隐写算法会造成对DCT系数之间相关性的破坏,因此提取DCT系数相关性的特征能有效反映隐写带来的变化。DCT系数的块内和块间三向差分数组分别描述块内块间的系数相关性作为特征和建模的输入变量[1]。特征提取方法步骤如下:
(1)将JPEG图像从RGB模型转换到YcBCr模型,读取Y分量并进行8×8分块DCT变换,对各系数取绝对值。
(2)每个8×8DCT系数分块取前21个低频AC系数的绝对值分别沿横向、纵向和zigzag方向扫描生成3个一维数组,由一维数组生成差分数组,得到3个二维差分数组。
(3)分别采用水平光栅、垂直光栅和zigzag扫描的方式扫描各BDCT块系数绝对值,生成水平块间、垂直块间和zigzag方向块间的二维差分数组。
(4)对各方向的块内和块间的二维差分数组进行阈值处理,并求状态转移矩阵,取状态转移矩阵的下三角作为特征。
1.3 参数选取
ε-SVR准确地预测目标值,要求调节好两个参数:惩罚因子C和高斯核函数的核宽度g。关于参数的优化选取,目前还没公认的最好方法,常用的方法是让C和g分别用网格法在一定范围内按步长取值,用多重交叉验证法验证训练集的预测值,选取均方误差(MSE)最小时的参数作为最优参数。
网格法的表达式如式(7)所示:

其中cbase,gbase分别表示网格选值的基数,[cmin,cmax],[gmin,gmax]分别用于限定C和g的取值范围。
多重交叉验证法能有效避免SVR欠学习和过学习的发生。它将原始训练数据平均分成K组,每一组都分别做一次验证集,其余K-1组则作为训练集。
1.4 性能指标
为从数据上获知预测值的准确度,三个误差函数:绝对值误差(8)、方差(9)和绝对中值偏差(10)作为衡量预测值准确性的指标。

1.5 算法步骤
本文提出的实现能估计嵌入率的隐写分析方法主要包括建立模型和测试两部分,步骤如图1所示。
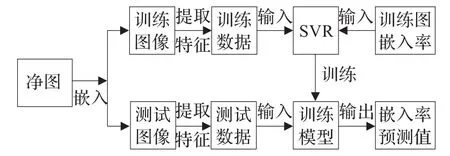
图1 隐写分析器的建模和测试过程图
(1)提取特征。根据1.2节的特征提取方法提取训练图像特征和测试图像特征。
(2)预测模型。将训练特征进行归一化预处理,并将其作为自变量,相关训练图像的嵌入改变率作为因变量,输入到SVR中用多重交叉验证法寻找最优参数C和g并进行回归建模,得到隐写分析模型。
(3)检验模型。将归一化后的测试图像特征输入模型中,得到预测结果φ(x),用1.4节的准则计算φ(x)与真实值Y之间的误差,判断估计值是否准确。
2 仿真结果及分析
从Jpeg-testing库[11]随机选取选取200幅净图作为载体图像,利用F5、outguess和MB隐写工具[12-14]将不同长度的信息嵌入到净图中,得到隐写图作为测试对象。对于F5 和MB隐写算法,本文采用的嵌入改变率为 p1={0.05,0.10,…,0.50},对于outguess隐写算法,p2={0.05,0.10,0.15},共得到13组隐写图像,并对每组图像提取块内块间相关性特征[1],一半特征用作训练数据,另一半特征用作测试数据。
利用libsvm工具箱[14]实现基于SVR的隐写分析。归一化的训练特征作为输入变量,高斯核函数作为核函数,ε-insensitive为误差函数,C和g的基数和范围:gbase=10,cbase=2,[cmin,cmax]=[-5,5],[gmin,gmax]=[-10,10],步长为0.1。
2.1 参数有效性
仿真结果证明,提出的隐写分析算法能准确估计隐写图的嵌入改变率。如F5隐写图的嵌入改变率为0.15,训练和测试样本数量均为50时,交叉验证法选择最佳参数时二维和三维变化曲线分别如图2和图3所示,得到最佳参数C=0.630 96,g=0.535 89,此时所得的最小交叉验证均方误差CVmse=0.076 268。
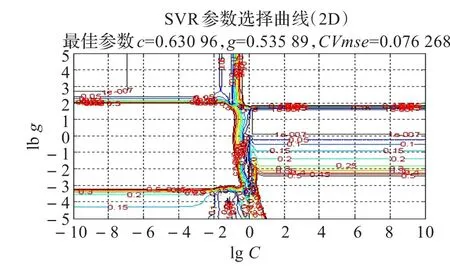
图2 参数选择平面图
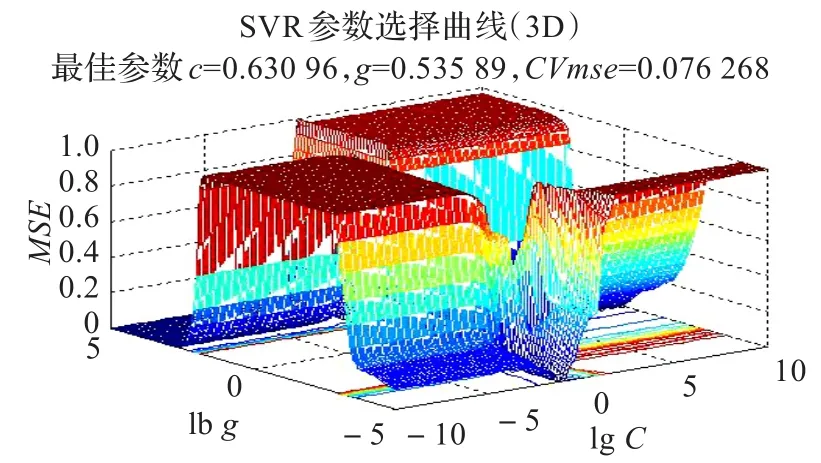
图3 参数选择3D图
经过测试,在最佳参数条件下的估计值比随机选取参数时所得的估计值效果好。利用嵌入改变率为0.15的F5隐写图训练样本建立隐写分析模型,然后分别估计训练样本和测试样本的嵌入改变率,预测结果如图4所示。
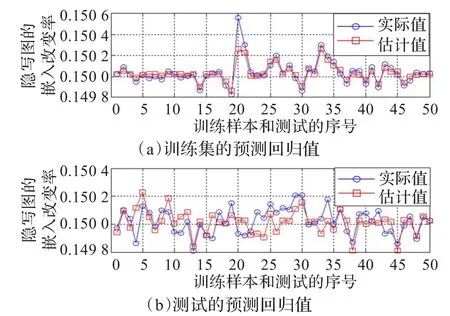
图4 F5训练集和测试集的预测回归曲线
由于最佳参数(C,g)在训练集的多重交叉验证回归预测中选定,测试集中的特征未参与建模,参数(C,g)的“最佳”是相对于训练集而言的,所以测试集的预测估计值不如训练集的效果好。如图4所示,训练集关于嵌入改变率的回归预测值曲线和实际嵌入改变率的曲线相对拟合度高、相关性强,测试集的回归预测值曲线和实际值的曲线拟合度不如训练集的高,但预测值都在真实值的附近。
2.2 检测性能
本文13组隐写图的训练样本和测试样本均为100,根据本文方法分别对13组隐写图进行建模和测试,用1.4节的性能指标验证F5、outguess和MB测试样本的估计值,所得误差值分别如表1、表2和表3所示。
分析表1中数据可知,对于F5隐写图,随着其嵌入改变率的增加,绝对误差和方差两种误差值未呈现递增反而减少,预测值的准确率增加。
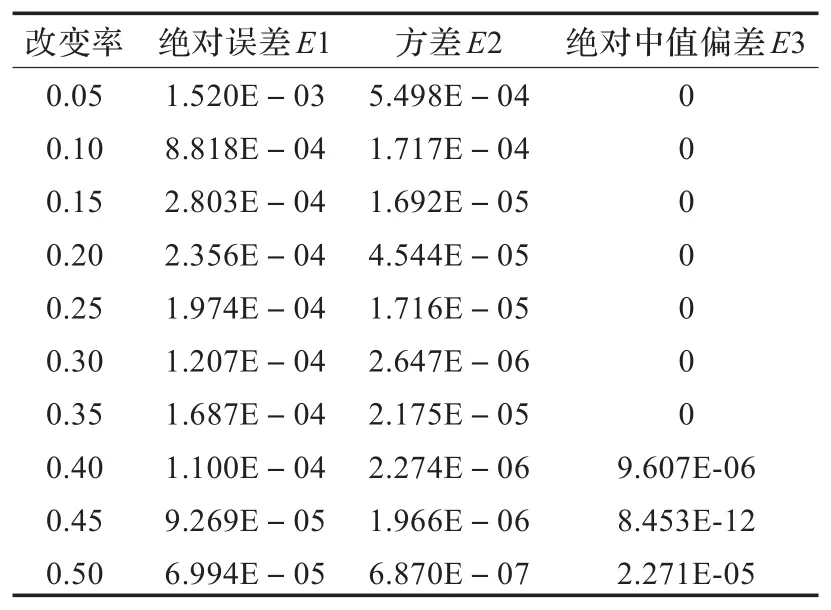
表1 F5测试样本的估计误差值
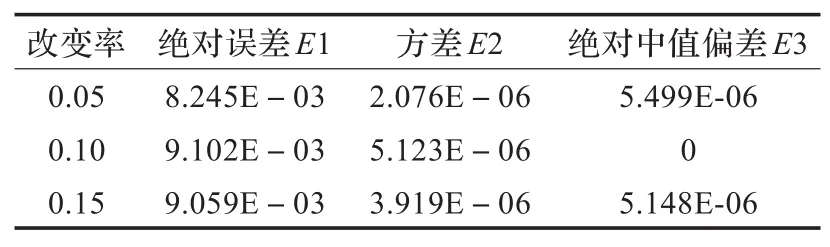
表2 outguess测试样本的估计误差值
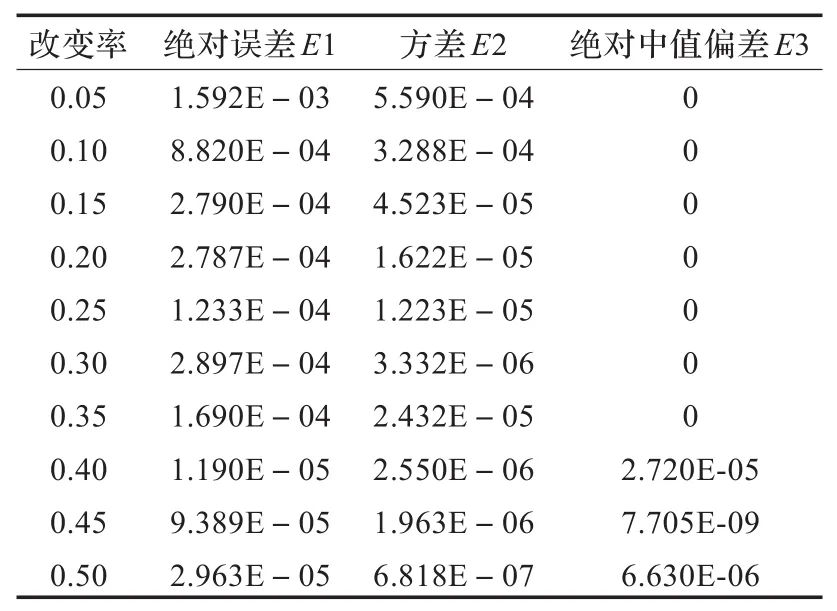
表3 MB测试样本的估计误差值
由表1至表3的数据可知,各组测试样本预测值的三种误差值都低于10-3阶,文献[9]得到的绝对误差是10-3阶,两种方法得到的估计准确率接近。
本文提出的改进的量隐写分析算法仿真速度快。本文采用的马尔可夫特征提取较快、维数较少、减少了运算量,文献[9]中结合文献[2]的特征采用SVR建模仿真需要一天的运行时间,采用本文的特征只需两小时,大幅度缩短了运算时间。
3 结论
能估计隐写图中嵌入信息长度的通用隐写分析是隐写分析领域一个较新的思想,本文提出的隐写分析算法有以下优点:(1)该分析算法通过图像特征和嵌入改变率之间的映射模型估计新隐写图的嵌入改变率,而且不针对某一种隐写算法,实现了隐写分析的通用性;(2)用于隐写分析的特征提取快,而且用该特征得到的估计值与真实值基本拟合,误差小;(3)算法模式简单,较直观,易于实现,而且已证实基于SVR的回归分析是一种有效的预测方法。
[1]孙子文,纪志成.基于离散余弦变换域的块相关性和马尔可夫模型的图像隐写分析[J].信息与控制,2009,38(5):602-607.
[2]Pevny T,Fridrich J.Merging Markov and DCT features for multi-class JPEG steganalysis[C]//Proc SPIE Electronic Imaging,Security,Steganography,and Watermarking of Multimedia Contents IX.San Jose,CA,USA:SPIE,2007:1-13.
[3]冯帆,王嘉祯,刘会英,等.基于PCA和希伯特包络分析的盲隐写分析算法[J].计算机工程与应用,2011,47(4):93-96.
[4]Fridrich J,Soukal D,Goljan M.Maximum likelihood estimation of length of secret message embedded using±K steganography in spatial domain[C]//Proc of Electronic Imaging,Security,Steganography,and Watermarking ofMultimedia Contents VII.San Jose,CA:SPIE,2005:328-340.
[5]Jena S K,Krishna G V V.Blind steganalysis:estimation of hidden messagelength[J].International Journal of Computers,Communications&Control,2007:149-158.
[6]Yu Xiaoyi,Wang Aiming.Detection of quantization data hiding[C]//Proc of 2009 International Conference on Multimedia Information Networking and Security(MINES'09).Hubei:IEEE,2009:45-47.
[7]Yang Chunfang,Luo Xiangyang,Liu Fenlin.Embedding ratio estimating foreach bitplaneofImage[C]//LNCS 5806:Proc of Information Hiding.Heidelberg:Springer,2009:59-72.
[8]Fridrich J,Goljan M,Hogea D,et al.Quantitative steganalysis of digital images:estimating the secret message length[J]. ACM Multimedia Systems Journal,Special Issue on Multimedia Security,2003,9(3):288-302.
[9]Pevny T,Fridrich J,Ker A D.From blind to quantitative steganalysis[C]//Proc SPIE,Electronic Imaging,Media Forensics and Security XI.San Jose,CA:SPIE,2009:1-14.
[10]Smola A J,Schölkopf B.A tutorial on support vector regression[J].Statistics and Computing,2004,14(3):199-222.
[11]Rocha A,Goldenstein S,Scheirer W,et al.The Unseen challenge data sets[C]//CVPRW'08.Anchorage,AK:[s.n.],2008:1-8.
[12]Westfeld A.F5-a steganographic algorithm high capacity despite better steganalysis[EB/OL].(2001-05-10).http://www.inf. tu-dresden.de/~aw4/publikationen.html.
[13]Provos N.OutGuess universal stegano-graphy[EB/OL].(2001-10-12).http://www.outguess.-org/.
[14]Sallee P.Model-based steganography[C]//LNCS 2939:International Workshop on Digital Watermarking.Berlin:Springer,2004.
[15]Chang C C,Lin C J.LIBSVM:a library for support vector machines[EB/OL].[2010-09-02].http://www.csie.ntu.edu.tw/~cjlin/ libsvm.
SUN Ziwen,LI Hui
School of Internet of Things Engineering,Jiangnan University,Wuxi,Jiangsu 214122,China
In order to solve the problem that the majority of general steganalysis methods cannot estimate the secret message length,this paper proposes an improved general quantitative steg-analysis method that can estimate secret message length.132 dimensional features describing the correlations between DCT coefficients are extracted from stego images.Support vector regression is used to learn the mapping between feature vectors and the relative embedding change rates and construct steganalyzer model.Embedding rates are estimated through new feature sets and steganalyzer model.Simulation is performed on stego images embedded with F5,MB and outguess steganographic algorithms.The results of simulation reveal that the proposed quantitative steganalysis is feasible to estimate the embedding ratio of stego images in practice.
quantitative steganalysis;support vector regression;loss function;kernel function
为解决大多数通用隐写分析算法不能检测秘密信息长度的问题,提出了一种改进的能估计秘密信息长度的通用隐写分析方法。从隐写图中提取描述DCT域系数相关性的132维特征,用支持向量回归机学习图像特征和相应嵌入改变率之间的映射关系并建立模型,根据映射模型估计测试隐写图的嵌入改变率。使用典型的嵌入算法:F5、outguess与MB进行测验,仿真结果显示提出的秘密信息长度估计算法是切实可行的。
通用隐写分析;支持向量回归;损失函数;核函数
A
TP391
10.3778/j.issn.1002-8331.1107-0388
SUN Ziwen,LI Hui.SVR-based steganalysis method used for estimating embedding rate.Computer Engineering and Applications,2013,49(5):84-87.
中央高校基本科研业务费专项资金资助(No.JUSRP21131)。
孙子文(1968—),女,博士,副教授,主要研究领域为无线传感器网络技术及应用、信息安全、图像处理与模式识别;李慧(1986—),女,硕士。E-mail:sunziwen@jiangnan.edu.cn
2011-07-18
2011-08-30
1002-8331(2013)05-0084-04
CNKI出版日期:2011-11-14 http://www.cnki.net/kcms/detail/11.2127.TP.20111114.0947.042.html
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化·中考版(2021年3期)2021-07-22
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
数学小灵通(1-2年级)(2020年9期)2020-10-27
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
作文大王·低年级(2017年11期)2017-12-05
小学生学习指导(低年级)(2017年12期)2017-11-22
数学小灵通·3-4年级(2017年9期)2017-10-13
