
基于代理模型的分布式聚类算法
2013-06-23 09:42彭利标
电子设计工程 2013年17期
田 野,彭利标
(天津理工大学 中环信息学院,天津 300380)
聚类算法是大规模数据处理应用中的一个非常重要的研究领域,现阶段聚类分析算法的应用的非常广泛,其目标是在没有先验知识的前提下,以数据对象之间的相似程度为根据将数据聚合成若干不同的簇,使同一个簇中的数据对象尽可能相似,不同簇中的数据对象差别尽可能的大[1]。由于聚类算法可以应用于事先未知的情况,所以特别适合无需人工干预的挖掘过程。而且聚类算法作为数据挖掘系统中的一个重要部分,既可以作为一个单独的工具挖掘数据库元素分布的深层信息,也可以作为先进数据挖掘算法的一个预处理步骤[2]。
分布式数据挖掘的研究是近几年提出的一个新的研究领域,旨在解决当前分布式的环境下,提供从数据的海洋中获取感兴趣的知识的有效的途径,也是目前解决在Internet中发现知识的最佳方法之一,应用前景非常广阔。从广义上讲,分布式环境中应用的数据挖掘都可称为分布式数据挖掘[3]。实际上,很多研究人员都已经展开研究,对分布式的关联规则算法,分布式分类算法,以及分布式聚类算法等的研究已经取得了一些成果。但必须注意到的是,无线和有线通信技术以及计算机技术的飞速发展,使分布式计算环境在各个领域广泛存在,现有的大多数聚类方法在数据量小、集中的情况下是有效的,对于大规模数据的、分布式的数据处理不能很好的适应。分布式聚类技术的研究虽然已经有了发展,但现阶段分布式聚类的研究还属于数据挖掘领域里一个比较前沿的新方向,其研究还处于基础性阶段,有很多问题亟待解决。
1 基于代理的分布式聚类模型
从体系架构上来讲,目前的分布式数据挖掘系统采用两类模型[4]:C/S模型和基于代理(agent-based)模型。其中基于代理的挖掘模型的特点是分布式数据挖掘系统的局部数据聚类分析需要在每个数据站点使用一个或多个代理来进行,并与其他的代理进行通讯,在该过程中需要一个具有指导性代理的适配器来协助整个挖掘[5]。由于传统的代理挖掘模型最终仍需要将局部的所有结果集中到一个中心站点执行,而中心站点的内存不一定能满足庞大数据量的要求,即便是满足足够内存同时也会带来较大的通讯开销。 图1描述了一个基于代理的分布式数据挖掘模型的结构。这种基于代理的结构能够将庞大复杂的计算任务分配给代理系统,客户端可以从复杂的逻辑处理中解放出来,只关心聚类的结果,而不必去关心聚类的具体细节,大大提高了模型的聚类效率和可移植性。
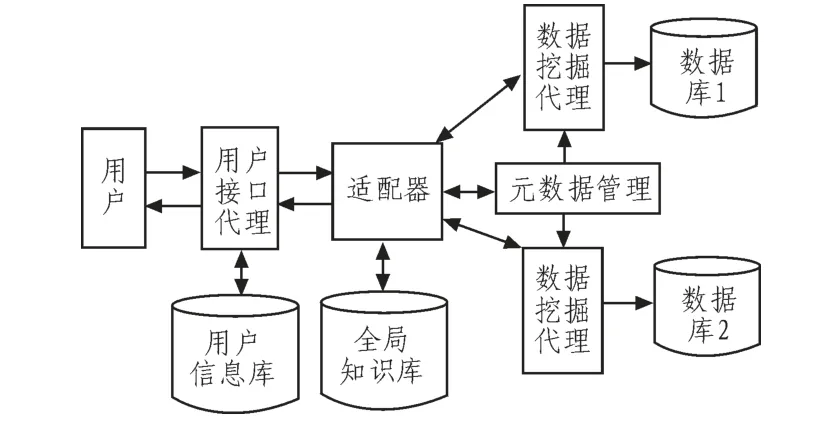
图1 基于代理的分布式数据挖掘模Fig.1 Agent-based distributed data mining model
目前,在基于代理的聚类模型中存在一种增量集成的分布式数据挖掘模型(II DDM),这种模型的本质是通过利用增量学习的思想,集成两个站点的聚类结果,根据得出的局部结果,集成他们的增量。II DDM模型的设计思想是基于模型伸缩性的考虑,此模型对于任何数量的数据源都具有较好的伸缩性。典型的模型结构如图2所示,在该模型中使用多个移动代理知识集成器增量的组合,得出的每两个站点的挖掘结果,一般而言将小的局部站点聚类结果迁移到更大的局部站点结果中去,从而优化结果集[6]。
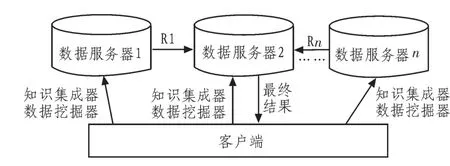
图2 典型的II DDM模型Fig.2 II DDM model
增量集成分布式数据挖掘模型工作过程一般可分为以下3个阶段。1)准备阶段,首先,客户端向需要执行数据聚类任务的服务器广播移动代理数据挖掘器和移动代理知识集成器;2)聚类分析阶段,在每个局部站点的数据服务器上执行数据对象的聚类分析,生成该站点的局部聚类结果集;3)集成阶段,在数据服务器上执行增量集成技术将小的局部站点聚类结果迁移到更大的局部站点结果中去,以此来减小局部站点间的结果迁移代价。
2 II DDM模型存在的问题
分析II DDM模型,可以知道,该模型不但继承了一般多代理模型之间可以协作执行任务、彼此进行信息传递的特点,从而完成复杂的大规模数据挖掘任务。还继承了移动代理系统的独立自主性,这是由移动代理本身的特点决定的。移动代理系统可以在自己的生存周期中自行控制挖掘的起点和终点,实时掌握自身的运行状态,并且能够在新的节点中从挂起状态自动恢复并继续运行。
与传统的基于移动代理模型不同的是,II DDM模型本质上并不是向集成代理传递所有获得的数据服务器局部聚类结果,而是通过控制服务器聚类结果之间不断的从小到大的迁移,来进行增量的集成,直到最后将一次集成得到的结果传递给客户端。可以说这种方式克服基于传统移动代理的挖掘模型的不足,它所具备对任意数量的数据站点具有伸缩性的优点。
正是由于II DDM模型上述的那些优点,使它非常适合应用于分布式聚类系统。但是,传统的基于代理的分布式数据挖掘模型,仍然存在着需要将全部的局部站点聚类结果集中到一个服务器上进行聚类的缺点,服务器的性能成为整个系统的瓶颈。改进的II DDM模型虽然在某种程度上缓解了这个矛盾,但是其实质也是通过个体式合作方式来进行代理间的协作,且是串行集成的工作模式。客户端要执行聚类任务的过程中不可避免的被要求与全部需要执行挖掘任务的服务器进行通信,还要将挖掘代理以及集成代理广播给所有相应的数据服务器,对整个网络的带宽要求很高,时间开销也很大。不仅如此,在挖掘任务执行之后,相应的服务器又需要将结果集全部反馈给客户端。经过上面的分析,可以想象的到当站点数量非常庞大时,通讯开销也会是难以接受的,而且存在响应效率大大降低的可能性,可见这种有赖于个体式的合作方式自身存在一定的不足。
沿着这个思路,在本章基于II DDM模型的,引入层次的设计思想,提出一种新的基于代理的层次式增量集成分布式数据挖掘模型,记作HII DDM。该模型是利用分治策略将复杂的大问题分解成小问题进行解决,以此来克服II DDM模型个体合作方式的不足。在实际应用中可以根据站点服务器的分布、局域网络带宽等来将整个系统划分为若干子系统。每个子系统在利用II DDM模型进行学习之后,生成一个模型,新的模型将作为整个系统的数据节点,再利用II DDM模型进行学习生成最终的模型。用这种层次式的方法生成最终的模型较前面两种传统的模型而言具有更好的伸缩性,执行起来更加高效,并有效降低网络通信。最后,基于本章提出的新模型提出一种新型的分布式聚类算法。为是解决站点数量庞大的数据挖掘问题提供了一个新的思路。
3 层次式增量集成分布式聚类模型的设计与实现
将分层的思想引入之后,可将层次式增量集成分布式聚类模型整体工作过程划分为4个阶段。
1)准备阶段,在这个阶段客户端将移动代理数据挖掘器和移动代理知识集成器广播给每个子系统,而不是直接分给数据服务器;2)聚类分析阶段,在这个阶段每个子系统选择合适的聚类算法在节点间执行聚类任务,生成局部挖掘的结果;3)子系统集成阶段,移动代理知识集成器利用增量集成技术在各个子系统上并行进行结果集成,生成子系统的挖掘结果;4)全局集成阶段,移动代理知识集成器利用增量集成技术集成各个子系统生成的局部聚类结果,生成全局聚类模型并传递给知识集成器客户端。其结构图见图3所示。
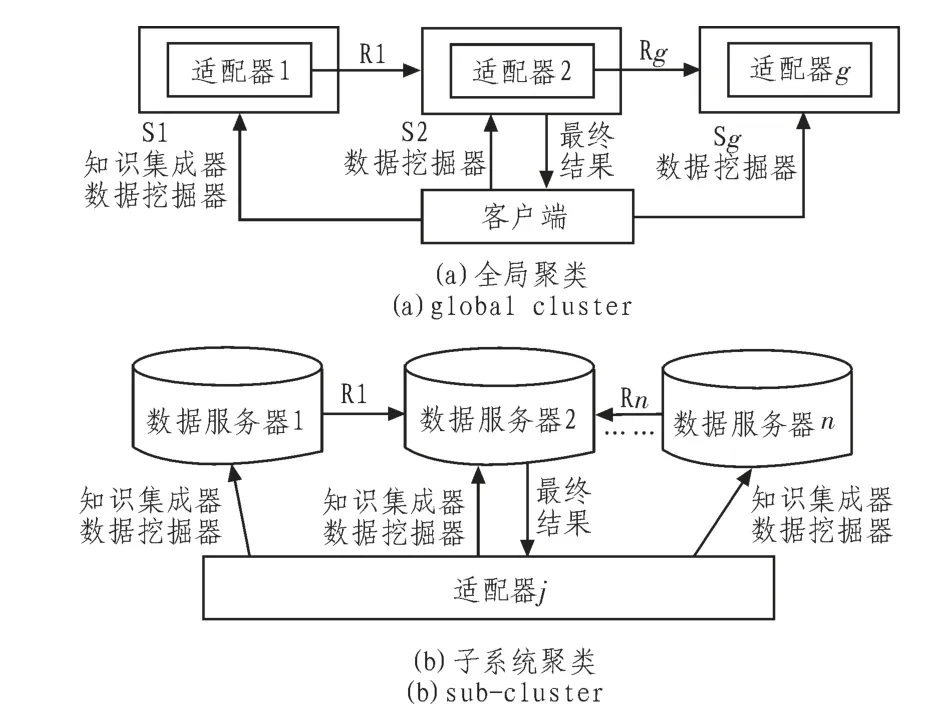
图3 HII分布式数据挖掘模型整体结构图Fig.3 HII distributed data mining models overall structure
在层次式增量集成分布式数据挖掘模型中,第一层为子系统层,该层为每个子系统设计一个适配器来充当子系统的客户端,向相应的子系统中需要进行聚类任务的数据服务器分配数据挖掘器;在聚类任务执行完毕后,各个数据服务器再将得到的局部聚类结果反馈回适配器。第二层为由小系统组成的大系统层,即全局聚类层,在这一层适配器又充当集成服务器和通信代理的角色,传递和集成各子系统的局部聚类结果,最终将全局的聚类结果送回给整个系统的客户端。
将分层的思想引入基于代理的分布式聚类模型中,是提高分布式聚类模型伸缩性,高效性的有效途径。但是如何划分系统的层次才能使整个系统运作更易实现、更加高效,是一个非常关键的问题。绝大多数实际应用中网络节点的地理分布特征不是随意的分布在不同地方,而是在几个地方集中分布,节点间连接方式多样化,连接带宽差异化。例如,用高速的局域网连接在同一个地点或同一组织中分布的节点,会比用远程网、互联网甚至无线网连接的不同地点间或不同组织中分布的节点,在网络传输的安全性、传输的速率方面高的多,而在通信代价方面却低得多。因此,在设计分布式聚类模型时,应该尽量在局域网内完成聚类的通讯和计算,尽可能的减少广域网间的网络通讯。
沿着这个设计思路,将系统划分的方式定为,分布在一个地点或若干个相近地点的节点作为一个子系统。这样,各个子系统可以高效执行聚类运算,提高子系统数据挖掘的效率,将子系统之间的通信工作交给专业的、强大的代理系统执行,从而使整个系统的执行效率大大提高,通讯代价最大程度的降低,系统的安全性也得到明显改善。
假设一个分布式系统由P个节点组成,全部的P个节点在g个站点间集中分布(这里有一个隐含的假设前提是每个站点内部的节点是由高速局域网连接的),设在第i个站点中的节点数目为ni,则有个节点按照所在站点进行划分,并组成一个相应的子系统,记作S1,S2,…,Sg。基于网络分布、带宽和安全性方面的实际考虑,根据这个定义对分布式系统进行划分旨在做到子系统内的节点紧耦合,子系统间是松耦合。当然这个划分规则不是一成不变的,可以根据实际情况灵活选择。如果某个子系统的节点数量达到了一定的程度,也可以根据实际情况将同一站点的节点再分为若干子系统;另一方面,如果几个站点的节点数量足够的小,且不同站点间的网络连接速度足够的快,也可以将相应的几个站点的节点集成一个子系统。
根据规则划分好子系统之后,采用II DDM模型进行聚类分析。模型中的数据挖掘算法可以采用DK-Dmeans算法,当然也可以根据实际情况选取其他的分布式聚类算法,此模型具有很好的灵活性。在各个子系统上通过一遍遍历数据后根据增量集成规则建立子系统模型,如图4所示。
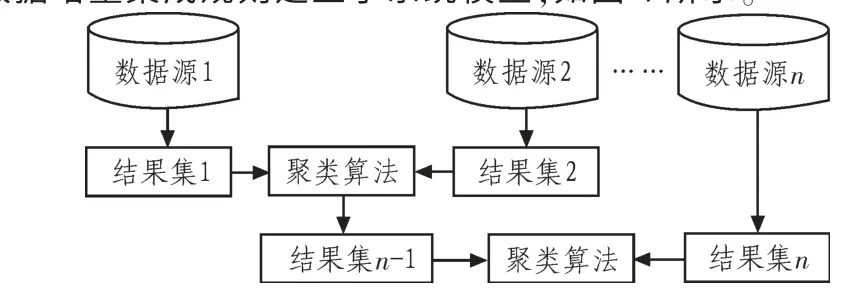
图4 HII子系统Sj聚类模型Fig.4 HII subsystem Sj clustering model
在子系统模型建立之前的准备是根据客户端的数据挖掘请求来决定需要进行聚类的子系统。之后客户端会将移动代理数据挖掘器和移动代理知识集成器发送给需要进行聚类分析的子系统的适配器,再由适配器分发给其所在系统的服务器。该子系统中,每个数据服务器执行挖掘任务,将得到的聚类结果的聚簇中心点以及相应簇的大小反馈给适配器,适配器会对得到的信息进行比较,然后发送控制命令,将较小的聚类结果迁移到更大聚类结果的服务器上,并在更大结果的服务器上执行集成。迭代执行上述步骤,直到所有的聚类结果被迁移到一个服务器上得到最终的聚类结果。最后这个服务器将聚类结果发送给适配器。
在本章提出的模型中,全局模型的建立并不是将局部模型的聚类结果进行简单了累加,由于是分层的思想,所以在整个系统的第二层,即全局聚类层,也和子系统一样,通过增量集成模型建立全局模型,与子系统模型不同的是在第二层的聚类模型中,子系统充当了数据源的角色。这样就可以明显的看出,引入分层的思想后,克服了II DDM模型串行的、个体协同合作执行方式的弊端,在全局聚类的这一层是并行的合作方式。全局聚类的模型如图5所示。
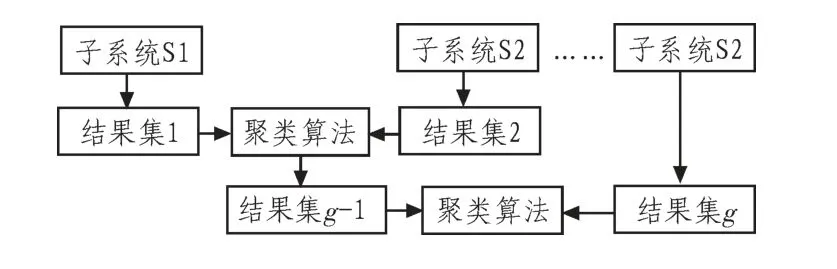
图5 HII全局聚类模型Fig.5 The HII global clustering model
全局模型和子系统模型的工作过程几乎是一样,只不过在这一层适配器是将将生成结果大小送给客户端,由客户端发送将小的聚类结果迁移到大的聚类结果的适配器上的控制命令,之后在驻留有大的聚类结果的适配器上执行子系统聚类结果的集成。上述步骤迭代执行,直到所有适配器聚类结果被集成到一个适配器中。此适配器将最后一次集成的结果发送给客户端。在整个系统模型的聚类过程中,由于是并行的执行,各个子系统可能由于网络带宽,网络延时等问题造成不能同步完成聚类计算。这是,整个系统的聚类就会出现协同问题,解决这个问题的方法是,可以在客户端发送控制命令的同时也发送一个时间戳给各个子系统,这样就可以保证是同一次迭代的结果被集成代理进行集成了。
4 基于HII模型的分布式聚类算法
在上一节中完成了HII DDM模型的设计和建立,现在在建立好的模型基础上,来实现基于该模型的分布式聚类算法。根据模型的划分规则,将分布在多个站点的数据库划分为若干子数据库,并且在每个子数据库中选择一个性能好的服务器充当适配器,模型中可以应用多种分布式算法,在本节选择上一章的DK-Dmeans算法,下面是新算法的描述。
基于HII DDM的分布式聚类算法:
第一层对子系统j:


实际上,基于HII DDM模型的分布式聚类算法由于采用了层次式增量集成的方式,其算法的开销也应该分为两层来计算。根据模型的工作过程,在子系统聚类层,时间的开销包括以下几个方面,1)适配器向数据服务器传送挖掘器和集成器的时间;2)子系统各个站点执行K-means聚类算法的时间;3)服务器之间的通信时间;4)增量集成的时间;5)向适配器传递最后结果的时间。
同子系统时间开销的分析过程一样,全局聚类层的时间开销包括以下几个方面,1)客户端发送挖掘器和集成器的时间;2)适配器之间的通信时间;3)增量集成时间;4)适配器向客户端最后传递结果的时间。综上所述,本算法的时间开销=子系统聚类执行时间+全局聚类执行时间。
5 结束语
本章首先分析了基于代理的II DDM聚类模型的优势与劣势,在此基础上将分层思想引入,提出了在基于代理的层次式增量集成的分布式数据挖掘模型HII DDM,其核心思想是,将整个系统划分为两层。在子系统层根据所有数据节点,用II DDM模型生成相应子系统的聚类结果;在全局聚类层,再用II DDM模型生成整个系统的聚类结果。分层后克服了原模型个体合作和串行工作方式的缺点。之后在HII DDM模型的基础上提出了基于该模型的分布式聚类算法。基于此模型的算法不但继承了传统的基于代理模型算法在健壮性和高效性而且还很灵活,文章中是基于两层模型的算法,但不仅限于两层,在更大规模或数据库更分布的情况下,还可以分为更多层。分层模型是改善超大规模数据集的伸缩性和效率问题的非常有效的途径。
[1]HAN Jia-wei,Kamber M.数据挖掘概念与技术[M].范明,等译.北京:机械工业出版社,2008.
[2]Hand D,Mannila H.数据挖掘原理[M].张银奎,等译.北京:机械工业出版社,2007
[3]Januzaj,Brecheisen S,Kriegel H P,et al.Visually mining through cluster hierarchies[C].Proc.Of SIAM Int’l Conf.on Data Mining Orlando,2011.
[4]Johnson E,Kargupta H.Collective Hierarchical clustering from distributed heterogeneous data[J].Computer Science,2010(1759):221-244,2010
[5]Kargupta H,Huang W Y,Sivakumar K,et al.Distributed clustering using collective principal component analysis[J].Knowledge and Information Systems,2011,3(4):422-448.
[6]Charu C,Agrawal,Philip S.Yu.Finding generalized project Clusters in High-dimensional spaces[C].SIGMOD Conference,2010:70-81.
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
铁道通信信号(2020年3期)2020-09-21
趣味(数学)(2018年12期)2018-12-29
铁道通信信号(2018年8期)2018-11-10
现代营销(创富信息版)(2018年8期)2018-09-08
科学与财富(2017年24期)2017-09-06
舰船科学技术(2017年5期)2017-06-19
电脑爱好者(2016年22期)2016-12-16
轻兵器(2015年20期)2015-09-10
中国火炬(2014年1期)2014-07-24
