
Estimating Reduced-Reference Video Quality for Quality-Based Streaming Video
2013-05-23 07:48LuigiAtzoriAlessandroFlorisGiaimeGinesuandDanieleGiusto
ZTE Communications 2013年1期
Luigi Atzori,Alessandro Floris,Giaime Ginesu,and Daniele D.Giusto
(Department of Electrical and Electronic Engineering,University of Cagliari,Cagliari09123,Italy)
Abstract Reduced-reference(RR)video-quality estimators send a small signature to the receiver.This signature comprises the original video content as well as the video stream.RRquality estimation provides reliability and involves a small data payload.While significant in theory,RR estimators have only recently been used in practice for quality monitoring and adaptive systemcontrol in streaming-video frameworks.In this paper,we classify RRalgorithms according to whether they are based on a)modeling the signal distortion,b)modeling the human visual system,or c)analyzing the video signal source.We review proposed RR techniques for monitoring and controlling quality in streaming videosystems.
Keyw ords reduced-reference quality estimation;video streaming;adaptiveratecontrol
1 Introduction
T he paradigm of internet anywhere,any time and the diffusion of powerful end-user multimedia devices such as smartphones,tablets,networked gaming consoles,and e-book readers have led to the proliferation of new multimedia services.Such services include social TV,immersive environments,mobile gaming,HDTV over mobile,3D virtual worlds,electronic books and newspapers,social networking,and IPTV applicationstonamejust afew.
Services such as smartphone multimedia apps and electronic newspapers and magazines have already achieved market success.This success has been achieved because the whole design process—from content production to service activation,content consumption,and service management and updating—has been user-centered.The quality of user experience,perceived simplicity of accessing and interacting with systems and services,and concealment of complex underlyingtechnologies determine thesuccess or failure of these novel services.
Optimizing and managing quality of experience(QoE)is crucial for the successful deployment of future services and products.While this may seem straightforward,it is difficult to do in real end-to-end systems and networks.QoE is difficult to model,evaluate,and translate.For more than a decade,researchers have not been able to fully deal with QoE because of itsdynamic end-to-end nature acrossa rangeof networks,systems,and devices.
Assessing video quality is an important part of managing QoE because video is the most important type of content in many multimedia services.Full-reference(FR)methods are used when the full availability of the reference signal is assured.This happens when designing new systems(e.g.for coding,transmission,and processing content),where FR techniques are used to analyze the effect of algorithms on the quality perceived by theend user[1].
Unfortunately,it is impossible in practice to compute these metrics at the receiver because end-users do not have access to the original frames at their terminals.As an alternative to FR methods,no-reference(NR)and reduced-reference(RR)methods have been proposed in the literature.These allow quality to be estimated at the decoder,where there is no reference signal.In NR methods,distortion of the received frames is estimated only from the reconstructed video available at the receiver or from parameters extracted from the transmitted bitstream,and the original video is not accessed.NR methods are the best choice in a broadcasting scenario because no extra data is added to the bitstream.However,NR metrics are quite complex to develop,and without any information about the reference signal,it is difficult to determine which part of the received signal is distortion and which part is the reference signal.In RR methods,a small signature of the original content is added to the video stream and sent to the receiver.At the content-producer side,a compact feature vector is extracted and transmitted to the receiver,where it is used to estimate the visual quality of the received video stream.To produce perceptually significant estimates,the receiver approximates the quality metric between the original and received streams.The feature vector is assembled in such a way that it contains sufficient information to estimate the FR metric.The availability of this side information at the receiver allows for a significantly better estimation of the received videoquality in an NRscenario.Thetrade-off isamoderateincreasein required bandwidth.
In this paper,we analyze techniques that have been proposed for quality monitoring and system control for streaming video.In section 2,we describe reference generalized schemes.In section 3,we discuss RR techniques and how they can be used in reference scenarios.Proposed methods can be categorized according to whether they are based on modeling the signal distortion,modeling the human visual system,or analyzing the video signal source.In section 4,we discuss the use of these techniques for quality monitoring and control in practical streaming video streaming systems.We also discuss recently proposed approaches for 3D video.Section 5 concludesthepaper.
2 Generalized Frameworks
We categorize RR systems as those related to measuring the quality of multimedia content and those that implement an RR quality measure in order to control the transmission bitrate or other streamingparameters.
In the former,RR quality assessment(RRQA)is used to predict quality degradation in either an image or video sequence where there is incomplete information about the reference signal.Thisprediction isgiven in the formof a set of RR features.RRQA is useful for monitoring quality in real-time visual communications over wired or wireless networks.Fig.1 shows a generalized RRQA framework that includes a feature extraction process at the sender side and a feature extraction/quality analysis process at the receiver side.Typically,the extracted RR features(side information)have a much lower data rate than the visual data and are ideally transmitted to the receiver through an ancillary channel[2].Although the ancillary channel is often assumed to be error-free,it may be merged with the distortion channel[3]-[7].In such a case,the RR features would need stronger protection than the multimedia data during transmission.This protection might be achieved by stronger error-protection coding.Data is often hidden or watermarked in order to merge the features data into the media content.At the receiver side,the difference between the features extracted from the reference and the distorted images or image sequences is the quality degradation.Fig.2 shows the RRquality assessment framework when only the distortion channel is present.

▲Figure1.Generalized RRframework for quality assessment.
Fig.3 shows the framework for video rate control based on RR quality metrics when typical contention-based wireless channels are used.The framework comprises a mobile station client that communicatesthrough a wirelesslink with the video server.The server may be either amobilestation or afixed system that is connected through a wired network to the access point(AP)of the wireless channel.In the later,we assume the wired part of the network is a high-throughput channel.The main subcomponents of both the server and client systems are shown in the figure.A typical video streaming scenario includes a video source,display,channel transceiver,encoder,decoder,and the buffers for each of these.The proposed architecture also comprises a rate-control module at the client side and a visual quality estimator at both the server and client sides.The rate-control module is the key component.In order to adjust the source bit rate,it monitors the channel throughput,playback buffer occupancy,and quality of thereceived signal computed by the visual quality estimators.The underlying encoder is capable of adjusting its encoding parameters to meet the required rate,which is computed by the rate-control algorithm.
The video sequences can be generated in real time or retrieved fromavideoarchive.When avideoframehasbeen coded,it is segmented into one or more packets that are then delivered to the medium access control(MAC)layer and transmitted over the wireless link.In the proposed architecture,the receiver monitors the times at which it receives packets from the server.The interarrival time is the time needed for the server to conquer the channel in a multiaccess, contention-based network and to transmit the whole packet.These interarrival times are stored and processed so that information about network performance can be extracted.The received flow can be affected by errors that have not been corrected by theforward-error correction(FEC)mechanismbecausethemechanismhaslimited error-correction capabilities.
3 Reduced-Reference Quality Assessment
The general RRQA frameworks described in section 2 allow free selection of RR features,which is one of the main challenges in RRQA algorithm design.RR features should efficiently summarize the reference image,be sensitive to a variety of distortions,and relate to the visual perception of image quality.RR features should balance the data rate with accurate predictions about image quality.High data rates support the transmission of much information about the reference image,and may lead to moreaccurate estimation of image quality degradations.However,such data rates negatively affect transmission.Lower data rates make it easier to transmit RR information,but the quality estimation is less accurate.The maximum allowed RR data rate is often given in practical implementations.When evaluating the performance of an RRQA system,consideration should be given to the tradeoff between accuracy and RRdatarate.

▲Figure2.Generalized RRframework for quality assessment with onetransmission channel only.

▲Figure3.Generalized RRframework for ratecontrol.
There are three different but related types of RRQA algorithms:those based on signal distortion model,those based on the human visual system(HVS),and those based on signal source analysis.The latter two types can be used for general-purpose applications because the statistical and perceptual features being used are not limited to any specific distortion process.These two typesare somewhat different to HVS,which is tuned for efficient statistical encoding of natural visual environments[8],[9].In the following subsections,each algorithm is consigned to a best-fitting category,but many of these algorithms are based on a combination of models.For example,HVSconsiderations are often embedded in the other types of algorithmspreviously listed.
3.1 Reduced-Reference Based on Image Distortion Modeling
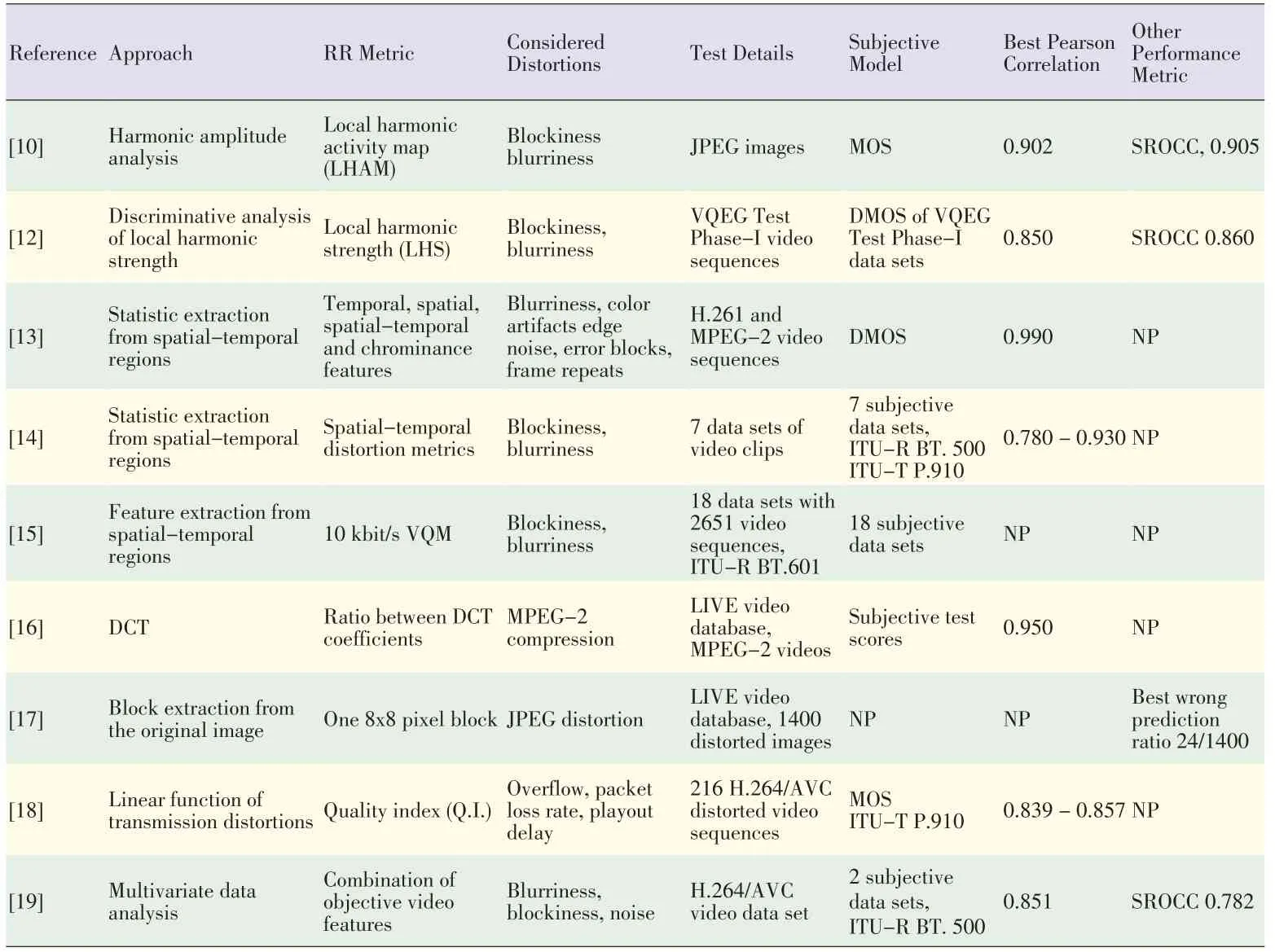
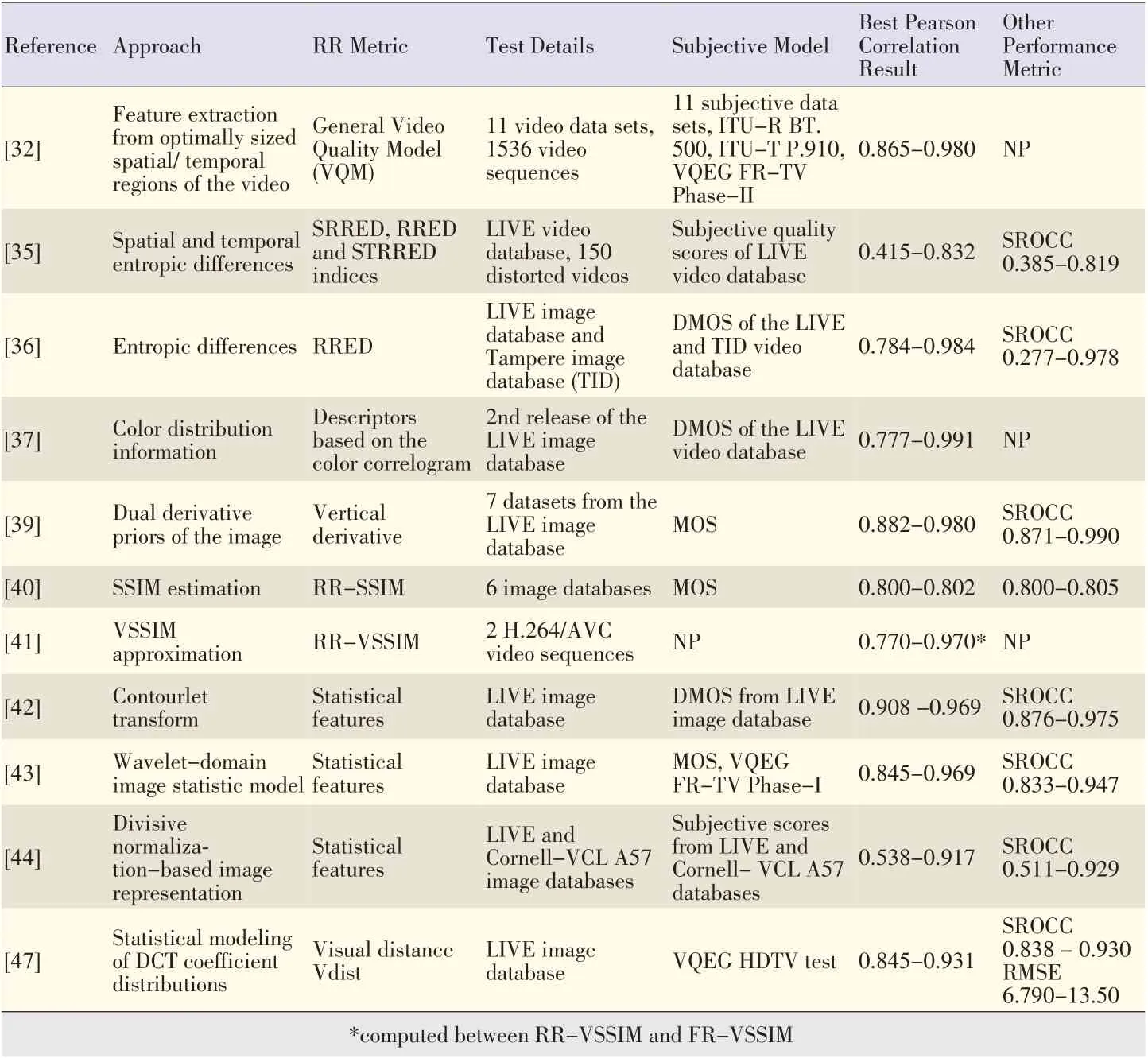
Algorithms based on image-distortion modeling are mostly developed for specific application environments.These algorithms provide useful,straightforward solutions when there is sufficient knowledge about the distortion process that the image or image sequence has undergone.When the distortion is standard image or video compression,a set of typical distortion artifacts,such as blurring,blocking or ringing,may be identified.Then,image features that are particularly useful for quantifying these artifacts can be determined[10],[11].In[12],the tool for measuring compressed video quality is based on harmonic strength analysis of transmitted and received pictures at the edge.This analysis is needed to determine gain and loss information about the harmonics.The proposed metric is designed to detect blocking and blurring artifacts.The detected edges of the image are used to further process the image and extract different side information.In[13]-[15],a set of spatial and temporal features was effective for measuring distortion in standard compressed video.However,such features are limited in their generalization capability. In[16],a simple measure was designed for the perceptual qualities of MPEG-2 coded sequences.The tool uses the ratios of discrete cosine transform(DCT)coefficients.In[17],JPEG compression was considered.One block from the original image was used as an RR and was inserted over the whole image using digital watermarking.In[18],a quality index was used to evaluate perceived quality when watching video sequences on a tablet.The index was based on the results of subjective video quality assessments.In[19],artifacts(such as blurring and blocking)of the AVC/H.264 coded video sequence were determined and measured by the objective features.The measurements of these artifacts were combined into a single measurement of overall video quality.The weights of single features and the combination of these features were determined using methods based on multivariate data analysis.Generally,these methods cannot be applied beyond the distortions they are designed to capture.Table 1 shows the RR approaches discussed in this section.In the last two columns,a single value is the best performance with a combination of parameters,and a range shows the minimum and maximum performance for different datasets.
3.2 Reduced-Reference Based on Human Visual System Modeling
The second type of algorithm isbased on modeling the HVS.Perceptual features that exploit computational models of low-level vision are extracted.These features are used to achieve a reduced description of the image and are not directly related to any specific distortion system.RRQA methods built on these features could be engineered for general purposes.
▼Table1.RRapproachesbased on signal distortion modeling
They may also be trained on different types of distortions and produce a variety of distortion-specific RRQA algorithms under the same general framework.
These methods are good for JPEG and JPEG2000 compression[20],[21].In[22],an objective quality RRmetric wasproposed for color video.Because the size of the RR data is based on 12 features per frame with limited complexity,the metric is suitable for low-bandwidth transmission.The metric relies on psychovisual color space processing according to high-level HVS behavior.It also uses time-delay neural networks(TDNN).The quality criterion in[23]relies on extracting visual features from an image represented in a perceptual space.These features can be compared with perceptual color space,contrast sensitivity,psychophysical sub-band decomposition,and masking effect modeling used by the HVS.Then,a similarity metric computes the objective quality score of a distorted image by comparing the distorted image's extracted features with those extracted fromtheoriginal.The performanceisevaluated using three different databases and is compared with the results obtained using the three full reference metrics.The size of the side information can vary.The main drawback of this metric is its complexity.The HVSmodel,which is an essential part of the proposed image quality criterion,introduces a high degreeof computational complexity.
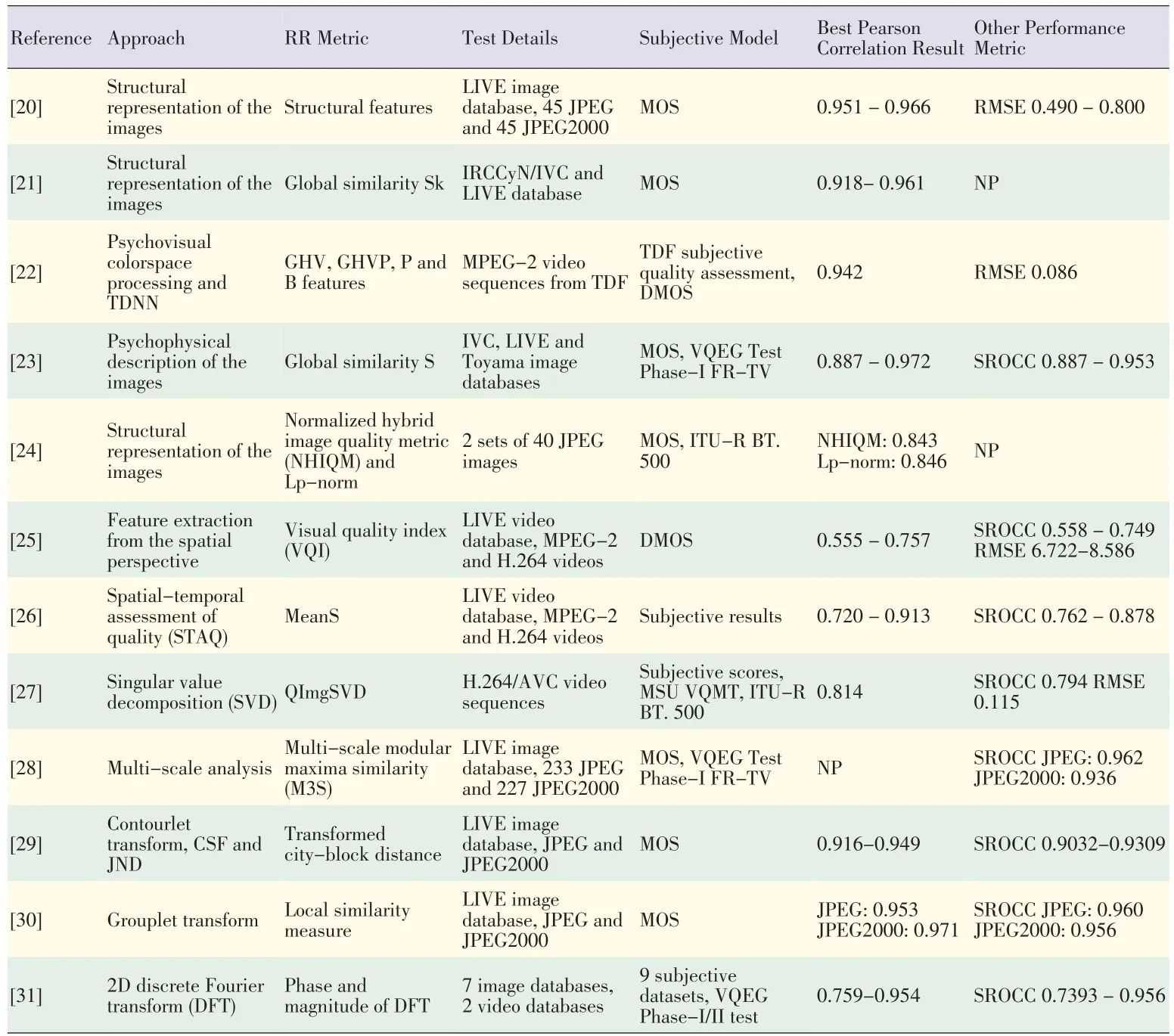
In[24],a metric for RR objective perceptual image quality was proposed for use in wireless imaging.Specifically,a normalized hybrid image quality metric(NHIQM)and perceptual relevance weighted Lp-norm were proposed.HVSis trained to extract structural information from the viewing area.Image features are identified and measured according to the extent to which individual artifacts are present in a given image.The overall quality measure is then computed as a weighted sum of the features.The authors of[24]did not rely on public databases for performance evaluation but performed their own subjective tests.In[25],RR video quality was assessed by exploiting the spatial information loss and the temporal statistics of the interframe histogram.First,the change in energy of each encoded frame was measured,and the texture-masking property of the HVS was simulated.A generalized Gaussian distribution(GGD)function was then used to capture the natural statistics of the interframe histogram distribution.The distances of the histograms of the original and distorted images were modeled using the GGD functions and were computed using the city block distance measure.Finally,the spatial and temporal features were merged.In[26],the authors proposed a method that takes advantage of the HVSsensitivity to sharp changes in video.First,matching regions are determined in consecutive frames.Then,the quality of the matching regions is computed.Last,the quality of the video is calculated according to the parameters gathered in the spatial and temporal domains and using the motion activity density of the video as a controlling factor.In[27],a new metric was designed that combines the singular value decomposition(SVD)and HVS.Different singular valueswereextracted according to the characteristics of the video sequences.These values were used as the reference features.By comparing the original singular value(SV)with the processed value,different distortion types can be reliably measured.Furthermore,because the metric can reduce the bandwidth requirements of the system,it is suitable for measuring video quality in wireless applications.In[28],an RRQA metric was developed using a multiscale edge presentation technique in the wavelet domain.Multiscale decomposition techniques accurately simulate the psychological mechanisms of the HVS,which depends heavily on edges and contours to perceive surface properties and understanding scenes.In[29],the authors exploited contourlet transform,contrast sensitivity function(CSF),and Weber's law of just noticeable difference(JND)to define a new RRQA method.The contourlet transform is used to decompose images and extract features to mimic the multichannel structure of the HVS.The proposed framework is consistent with subjective perception values,and the objective assessment results accurately reflect the visual quality of images.This framework outperforms the standard PSNR and wavelet-domain image statistic(WDIS)metrics.In[30],a grouplet-based RRQA metric was proposed that makes use of the grouplet transform to efficiently characterize the image featuresand orientations.Then,the extracted features of the reference and distorted images were compared for quality.In[31],the authors proposed an algorithm based on the phase and magnitude of the 2D discrete Fourier transform.The phase and magnitude of the reference and distorted images were compared so that a quality score can be computed.However,the HVS has different sensitivities to different frequency components,so the frequency components are non-uniformly binned.This process also leads to reduced space representation of the image and opens up RR prospects for the proposed scheme.The phase usually conveys more information than the magnitude,so only the phase is used for RR quality assessment.Table2 showsthe RRapproachesdiscussed in thissection.
3.3 Reduced-Reference Based on Signal Source Modeling
The third type of algorithm is based on modeling natural image statistics.Because the reference image is not available in a deterministic sense,these models are often based on capturing a-priori low-level statistical properties of natural images.The basic assumption behind these approaches is that most real-world distortions disturb image statistics and make an image unnatural.This unnaturalness can be measured using models of natural image statistics and can be used to quantify degradation of the image quality.The model parameters provide a highly efficient way of summarizing the image information; thus, these methods often lead to RRQA algorithmswith low RRdatarates.
The Institute for Telecommunication Sciences/National Telecommunications and Information Administration(ITS/NTIA)developed a general video quality model(VQM)that,because of its performance,was selected by both ANSI and ITU as a video quality assessment standard[32].However,the model requires a massive RR data rate to calculate the VQM value,and this prevents it from being used as an RR metric in practical systems.Spatial-temporal features and regions have been considered for trading-off between correlated subjective values and side-information overhead[13].The proposed algorithm continually measures quality by extracting statistics from sequences of processed input and output video frames.These extracted statistics are communicated between the transmitter and receiver using an ancillary data channel of arbitrary bandwidth.Finally,individual video quality parameters are computed from these statistics.A low-rate RR metric based on the full reference metric was developed by the same authors[15].The video quality monitoring system uses RRQA feature extraction techniques similar to those in the NTIA general VQM.A subjective data set was used to determine the optimal linear combination of the eight video quality parameters in the metric.In[33],an image quality assessment scheme using distributed source coding was proposed.The RR feature extractor comprises whitening,which is based on spread spectrum,and Walsh-Hadamard transform(WHT).The focus on reducing the bitrate of the feature vector by using distributed Slepian-Wolf source coding.In[34],an RR video quality measure was combined with a robust video watermarking approach.At the sender side,both intra-and inter-frame RR features are calculated using statistical models of natural video.The encoded features are embedded into thesame video signal using a robust angle-quantization-index,modulation-based watermarking method.At the receiver side,the RR features are extracted and decoded from the distorted video and are used to predict the perceptual degradation of the videosignal.
▼Table2.Comparison of RRapproachesthat arebased on modeling the HVS
In[35]and[36],the differences between entropies of the wavelet coefficients of the reference and distorted images were used to measure changes in the image information.The algorithm is flexible in terms of the amount of side information required from the reference,which may be as little as a single scalar per frame.In[37],used a color distribution was used to evaluate the perceived image quality.Descriptors based on the color correlogram were used to analyze alterations in color distribution that occur because of distortion.In[38],an RR approach was proposed to measure temporal motion smoothness of a video sequence.By examining the temporal variations in local phase structures in the complex wavelet transform domain,the proposed measure can detect a wide range of well-known distortions.In addition,the proposed algorithm doesnot require costly motion estimation and has a low RR data rate.Thismakes it much better for real-world visual communication applications.In[39],natural images were very specifically distributed in the gradient domain,so the authors measured the changes of image statistics in this domain.These changes in image statistics correspond to the degree and types of image distortion.The proposed method can be used for all distortion types.In[40]and[41],an RRQA method based on estimating the structural similarity index(SSIM)was proposed.In[42],the authors proposed an effective RRQA metric using statistics based on the divisive normalization transform(DNT)of the contourlet domain.The marginal histogram of the contourlet coefficients in each sub-band are fitted by Gaussian distribution after DNT.The standard derivations of the fitted Gaussian transform and fitted error are extracted as feature parameters.
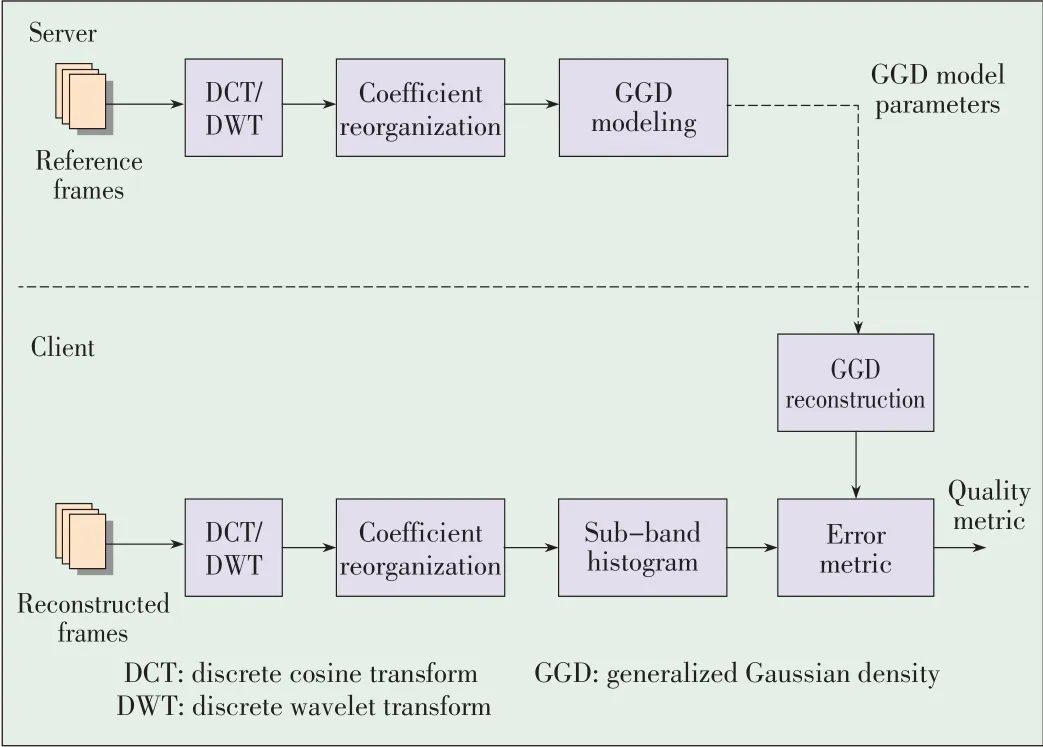
In[43]and[3],the marginal distribution of the wavelet sub-band coefficients was modeled using a GGD function.GGD model parameters are used as RRfeatures to quantify the variations of marginal distributions in the distorted image.This general-purpose approach has been successful because it does not require any training and has a low RR data rate.However,it still performs reasonably when tested with a wide range of image distortion types.In[44],the model was further improved by employing a nonlinear divisive normalization transform(DNT)after the linear wavelet decomposition.This improves quality prediction,especially when images with different distortion types are mixed together.In[24],results were compared with the RR metric and peak signal-to-noise ratio(PSNR).In[45]and[46],the perceived video quality was estimated on a frame basis.This perceived video quality is the distance between the distribution of DCT coefficients at the receiver side and the generalized GGD-modeled distribution of the same coefficients of the original signal,based on the framework presented in [47].Fig.4 shows a block diagram of the GGD-based technique.
At the server(transmitter)side,the reference frames are first transformed using DCT or discrete wavelet transform(DWT).Then,the transform coefficients may be spatially rearranged so that those representing similar frequencies often are grouped in a dyadic way.Subsequently,a GGD function is used to model the coefficient distribution of each frequency sub-band:
▲Figure4.GGD-based techniquefor estimating video quality.
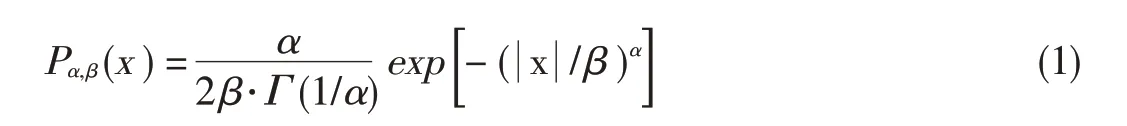
whereΓ(·)isthegamma function andαandβaretheparameters of the GGD model.Fig.5 shows an example of the GGD modeling.Only a few parameters are sent to the receiver for each frequency sub-band.These parameters are oftenα,β,and the city block distance between the actual sub-band distribution and its GGDapproximation.At the receiver side,the received frames undergo similar processing;however,the GGD modeling is substituted by the distortion metric.Such an estimate is generally derived from the linear combination of the differences between the actual distribution of transform coefficients from the distorted frame and the distribution modeled by the received GGDparameters.Table3 showsthe RRapproachesbased on signal sourcemodeling.
4 Useof RRQA in Streaming Video Applications
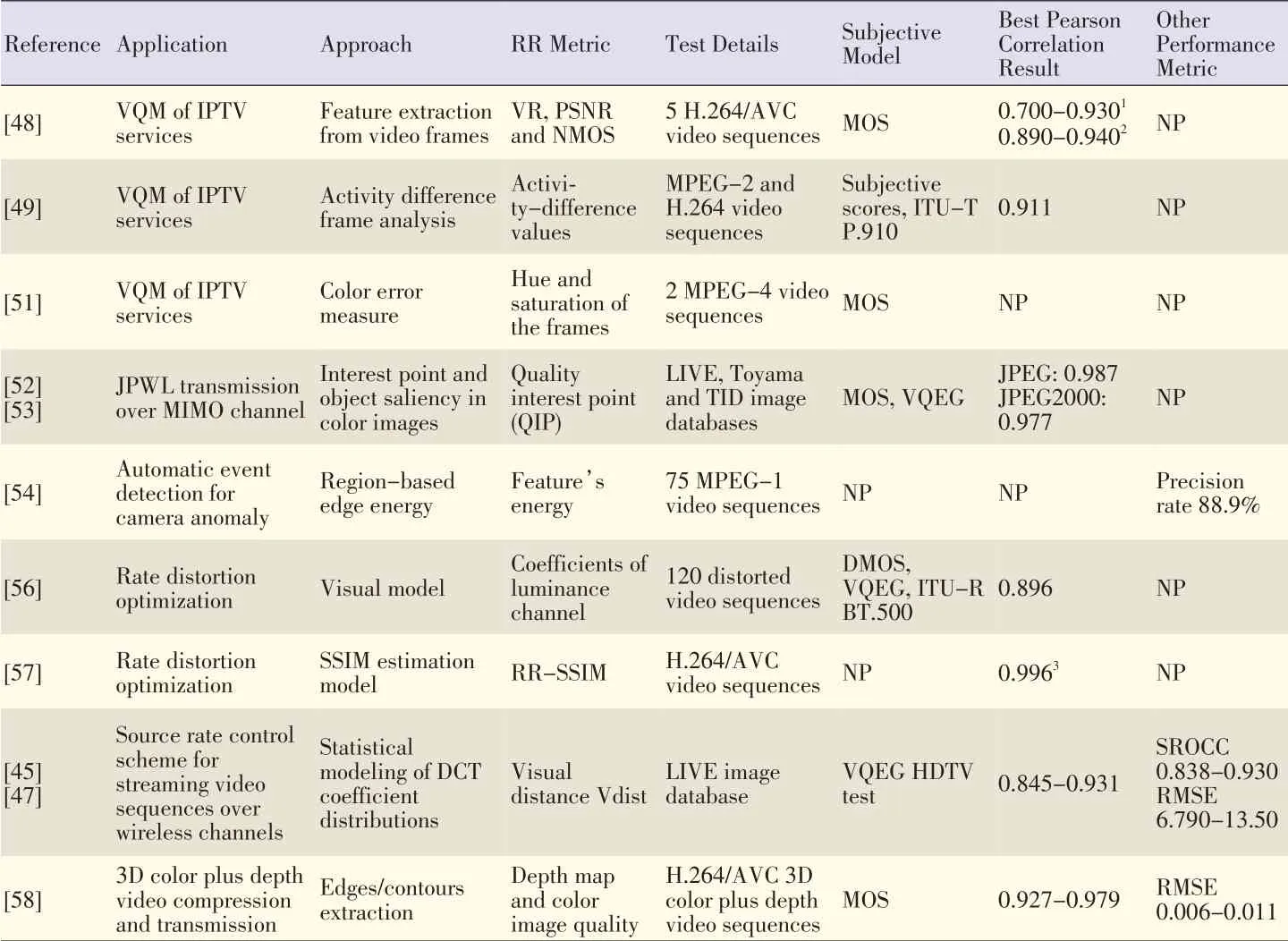
In this section,we give an overview of practical applications of RR metrics in streaming video frameworks.In some works,RR video quality estimation methods are used for video quality monitoring(VQM)of IPTV services.Complexity is one of the most important factors in VQM because of real-time constraints and hardware with limited capabilities.Set-top boxes,for example,have very limited computing and memory resources.RR methods are used because they allow feature information to be transmitted with very little resource consumption and low uplink bandwidth.In[48],a VQMscheme uses a modified version of PSNR(called networked PSNR)that is based only on the RRvisual rhythm data,which is used as feature information in the RR method.Two practical scenarios were proposed in which a quality monitoring server uses the proposed metric to evaluate the video impairments according to the packet loss experienced by the end user.In[49],an RR video quality estimation method makesuse of the difference in activity values between the original video and received video.Temporal sub-sampling and partial bit transmission of activity values help accurately estimate the subjective video quality,and only a small amount of extrainformation isneeded.
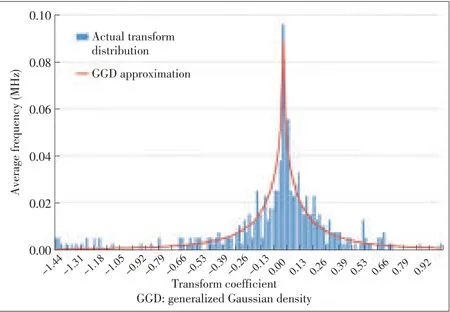
▲Figure5.Actual distribution of transform coefficientsand its GGD approximation.
In [50],real-time video sequence matching and RR assessing techniques are proposed for IPTV.After the processing procedures have been completed,the QoE indicators,such as edge,block,blur,color,and jerkiness,are measured by the proposed RR real-time video measurement methods in order to define the VQM metric.In[51],the authors discuss color error,which is one of the most common artifactsin compressed and transmitted video through the IP network.They propose an FR or RR quality-assessment method based on a color error measure in order to monitor the color quality in IPTV services.
In[52],a quality of interest points(QIP)RR metric,described in[53],was used for JPEG 2000 wireless(JPWL)transmission over MIMOchannels.Depending on the object's saliency,the interest points can predict a variation in the image.In the proposed scheme,QIP is used as a layer selector that is able to detect any reduction in the perceived quality while decoding an additional layer.All the possible configurations are decoded with JPWL robust decoder,and each configuration is evaluated by QIP giving a score from 0(very bad quality)to 1(excellent quality).Finally,the configuration with the best QIPscore has the best QoE.Beyond basic quality assessment,RRQA metrics have been used in other scenarios.In[54],the authors propose a technique that uses image analysis to automatically detect camera anomalies.The technique allows good image quality in surveillance videos by correcting the field of view.The technique involves first extracting RR features from multiple regions in the surveillance image.Then,abnormal events in features are detected by analyzing image quality and field-of-view variations.Events are detected by statistically calculating accumulated variations in the temporal domain.In[55],the authors consider modeling the visibility of individual and multiple packet losses in H.264 videos.They propose a model for predicting the visibility of multiple packet losses and demonstrate its performance with dual losses(two nearby packet losses).To extract the factors affecting visibility,an RR method is used because it accesses the decoder's reconstructed video(with losses)and factors extracted from theencoded video.
▼Table3.Comparison of RRapproachesthat arebased on modeling thesignal source
In the literature,there are very few works on the implementation of an RR quality measure for controlling the transmission bitrate or other streaming parameters.There are two works the describe the implementation of RR measures in a process commonly known as rate-distortion optimization(RDO),which is used to convey the sequence of images with minimum possible perceived distortion within the available bitrate.In[56],the authors describe a computationally efficient video-distortion metric that can operate in FR or RR mode.The metric guides an RDOrate-control algorithm for MPEG-2 video compression.Specifically,it is used to generate spatial distortion maps that are summed into macroblock-level and frame-level distortion scores in order to optimize the frame rate allocations for an MPEG-2 video coder.The coded sequences produced by the algorithm have fewer visible macroblock edges(blockiness),and the textured areas are sharper.Furthermore,the proposed metric is well correlated with subjective scores.In[57],the proposed RDO scheme is based on a novel RR statistical SSIMestimation algorithmand a source-side-information combined-rate model for H.264/AVC video coding.The adaptive Lagrange multiplier method was used at both frame and macroblock levels to select the best coding mode and achieve the best-rate SSIMperformance.Experimentsshowed that the proposed scheme significantly reduces the rate but maintains the same range of SSIM values.Compared with the RDO scheme,visual quality also improved.In[45],a scheme is proposed for controlling the source rate in streaming video sequences.The scheme relies on RR quality estimation and is the only one of its kind mentioned in the literature.The server extracts important features of the original video,and then these features are coded and sent through the channel along with the video sequence.They are then used at the decoder to compute the actual quality.The observed quality is analyzed to obtain information about the effect of the source rate for a given system configuration.At the receiver side,decisions are made on the optimal encoding rate to maximize the perceived quality at the user side.The rate is adjusted on a per-window basis to compensate low-throughput periods with high-throughput periods.This eliminates abrupt changes in video quality caused by sudden variations in the channel throughput.RRQA optimizes user-perceived video quality from the actual signal that is affected by all possible impairments.Experiments show that the RRquality metric allows perceived quality at the decoder side to be accurately estimated.It also correlates with other FR metrics.Three methods for evaluating the performance of the proposed algorithm in transmitting video sequences are compared:transmission at constant bitrate,control of the starvation probability,and the proposed method.The proposed method gives the best overall resultsfor all quality metricsand is second best at avoiding occurrences of starvation.The proposed method is also applicable to any channel conditions and coding settings and does not require any a-priori knowledge of system configuration or transmission conditions.
Video quality metrics have only very recently been used to assess 3D video quality,and this field deserves a particular attention.Exploiting immersive video implies the transmission of huge amounts of data because of the multichannel nature of such a format and high video resolutions.RRQA becomes even more interesting because it theoretically allows for a reliable measuring of quality at the receiver side and adds littleside information to the video data.3D video data has great redundancy that can be used to optimize the extraction of relevant features.From a technical perspective,3D RRQA differs from the other approaches in that it combines both intraframe and interframe aspects with depth information in order to extract RR features for quality assessment[58],[59].Table 4 summarizes the RRQA approachesused in streamingvideo.
5 Conclusion
In this paper,we have reviewed reduced-reference(RR)quality metrics and categorized them according to whetherthey are based on modeling the signal distortion,modeling the human visual system,or analyzing the video signal source.We have reviewed studies on the implementation of RR techniques in practical systemsto monitor and control quality in streaming video systems.
▼Table4.Comparison of RRapproachesused in video streaming applications
RR methods do not require full access to reference signals;they only need a small amount of information in the form of a set of extracted features.These methods are ideal for evaluating the quality of multimedia content at the receiver side—at the far end of the communication chain.Because of they are not complex and have a low features data rate,they can be used for quasi real-time or streaming video applications.On the other hand,their reliability in several implementations can be an issue.RRQA algorithms also fail to given an integrated estimate of subjective factors such as user device,environment conditions,and interface perception,all of which are typical in QoE approaches.Future work will probably be done on integrating sensor data produced by user devices in order to provide a more accurate and robust estimate of perceived quality.Further work isalsoneeded on applicationsrelated to3Dimages and video sequences so that RR features can measure the quality of such multimedia content while balancing the data rate of RRfeatures with accurate quality prediction.

- ZTE Communications的其它文章
- QoE Modeling and Applicationsfor Multimedia Systems
- Methodologiesfor Assessing 3D QoE:Standardsand Explorative Studies
- 3D Perception Algorithms:Towards Perceptually Driven Compression of 3D Video
- New Member of ZTECommunications Editorial Board
- Human-Centric Composite-Quality Modeling and Assessment for Virtual Desktop Clouds
- Assessing the Quality of User-Generated Content