
3D Perception Algorithms:Towards Perceptually Driven Compression of 3D Video
2013-05-23 07:48RuiminHuRuiZhongZhongyuanWangandZhenHan
ZTE Communications 2013年1期
Ruimin Hu,Rui Zhong,Zhongyuan Wang,and Zhen Han
(National Engineering Research Center for Multimedia Software,School of Computer,Wuhan University,Wuhan 430072,China)
Abstract In this paper,we summarize 3D perception-oriented algorithms for perceptually driven 3D video coding.Several perceptual effects have been exploited for 2D video viewing;however,this is not yet the case for 3D video viewing.3D video requires depth perception,which implies binocular effects such as con f licts,fusion,and rivalry.A better understanding of these effects is necessary for 3D perceptual compression,which provides users with a more comfortable visual experience for video that is delivered over a channel with limited bandwidth.We present state-of-the-art of 3D visual attention models,3D just-noticeable difference models,and 3D texture-synthesis models that address 3D human vision issues in 3D video coding and transmission.
Keyw ords 3D perception;3D visual attention;3D just-noticeable difference;3Dtexture-synthesis;3Dvideo compression
1 Introduction
3 D TV provides an immersive visual experience,and the development of 3D TV technologies has hastened.New video formats such as multiview and multiview plus depth(MVD)were designed for 3D perception[1].3D introduces new requirements,such as disparity adaptation between different display screens,2D to 3D conversion,3D error concealment,and 3D rendering.All of these require 3D video perceptual processing algorithms[2].The huge amount of 3D video data also has created challenges in compression and storage.Many proposed 3D video compression algorithms exploit the statistic redundancy of the 3D video;however,codingperformance is improved by increasingthecomputational complexity,which eventually creates a bottleneck.Because human eyes are the final receivers of a stereoscopic scene,human perception plays a part in designing high-efficiency coding algorithms for 3Dvideo.
Integrating human visual perception into the general 2D video coding framework is an open issue[3].In[4],structure similarity and content saliency information was incorporated into the distortion metric,and 10.14%bit rate was saved with similar subjective perception.In[5],details of many perception-based coding methods are discussed.2D perception-based coding algorithms are mature;however,3D perception-based coding algorithms are in still in their infancy.In[6],a novel depth coding method was proposed.The authors took into consideration the fact that distortion around object edges leads to serious artifacts.In[7],the authors highlighted the importance of incorporating the quality of synthesized color video into the distortion metric when encoding the depth video.The 3D perception model should integrate the specific visual perception difference between 2Dand 3D.In this paper,we analyze the features leading to perception difference for 3D and review existing works in which 3D perception is integrated into thecodingframework.
The main difference between 3D and 2D perception is depth perception;stereoscopic vision is created via binocular cues such as conflicts,fusion,and rivalry[8].Binocular conflict arises from inherently ambiguous sensory signals.Although 3D perception still exists when binocular conflict occurs,visual switching between left eye and right eye is uncomfortable[2].Visual attention models can relieve discomfort by reducing the conflict in salient regions.Two images shot from different angles are displayed for each eye.When two monocular images have different luminance or contrast but sharea common polarity,the fused average of the two monocular components leads to binocular fusion[8].Binocular rivalry occurs when dissimilar monocular stimuli are presented to the corresponding retinal locations of the two eyes[9].Because these binocular cues exist,the visual attention regions are shifted,and the just-noticeable-difference values in 3D video are different to those for 2Dvideo human perception.For a comfortable 3DTV experience,3D perception coding algorithms attempt to show those binocular effects accurately.Bandwidth is another critical factor that affects 3D TV experience.Depth-image-based rendering(DIBR)has been proposed to synthesize the virtual videos of different perspectives and save bit rate in 3D video encoding.However,there may be holes in the synthesized video because the occluded regions in the original view become visible in the synthesized view[10].Approaches based on texture synthesis and texture masking are taken to recover holes in the synthesized video[11].
In section 2,we give an overview of state-of-the-art 3Dperception modelsand briefly discusstheusefulnessof thesemodels briefly.In section 3,we describe some 3D visual perception algorithms that perform well.In section 4,we analyze and compare the previously discussed 3D perception models.Section 5 concludes the paper.
2 3D Perception Algorithms
Achieving high-quality 3D TV is a hot research topic.As well as bandwidth and processing steps,depth perception also affects human 3D visual experience.3D perception models are used to address human visual issues such as disparity adaptation between different display screens,2D to 3D conversion,3D error concealment,and 3D rendering[2].Existing 3D perception models explain binocular effects from the angle of subjective experimentation and modeling.Here,we describe the current statusof the3Dperception models.
2.1 Just-Noticeable Difference Modelsfor 3D Video
Just-noticeable difference(JND)models for 3D images have recently been proposed to accurately estimate redundancy in visual perception.A depth JND model proposed[12]demonstrated why human beings are not sensitive to varied depth values.With the development of 3D image processing technologies,the depth JND model,which only measures the depth perception difference,is not sufficient.A 3Dimage JNDmodel for describing the total stereoscopic perception is necessary.In[13],a binocular JND(BJND)model was proposed to describe the basic binocular vision properties of asymmetric noises in paired stereoscopic images.This was the first binocular JND model in which luminance adaption and contrast masking were taken into account.The model was verified in a formal psychophysical experiment,and the results showed that the JND values could be accurately obtained using the model.However,the model was constructed on the assumption that the disparity was zero;therefore,the model was not suitable for normal binocular stereo images with nonzero disparity.In[14],a joint JND(JJND)model wasproposed toseparately measurethe sensitivity difference of occlusion and non-occlusion regions,taking into account the fact that occlusion regions at the object edges are more visually sensitive.This model addressed the problem caused by ignoring disparity,and more accurate JND values were assigned for human visual perception.However,JND values are affected by differing human visual sensitivity to different stimuli[15].Usingdepth intensity as theonly influencing factor does not result in precise visual sensitivity.Depth intensity and depth contrast,both of which significantly affect human visual perception,need to be explored when building a 3Dimage JNDmodel.
2.2 3D Visual Attention Models
Region-of-interest algorithms can guide bit rate allocation during 3D video coding.Depth perception plays an important role in 3D video viewing,and this probably affects the location of the region of interest.In[16],the saliency region was determined using the scene depth derived from 2D saliency algorithms.According to the center-surround mechanism,a saliency map was created by extracting low-level features from the images.The depth map was treated as another low-level feature and was linearly integrated into the overall saliency model.However,the model was not validated by standard subjective experiments,and did not refer to the binocular effect.In[17],binocular rivalry in 3D perception is discussed.Directly adapting 2D saliency algorithms for use in 3D video introduces new problems;therefore,a region-of-interest map based on a hierarchical model can be generated from basic and special features[17].Although the model gives the displacement of the region of interest based on binocular effects,the response of each eye is treated independently.A perceptual model for disparity is given in[18];however,it is more accurate to calculate visual saliency based on depth perception.Wang constructed a model for quantifying depth bias for free viewing of still stereoscopic video[19].In[20],a bottom-up visual saliency model was proposed for 3D video.The 3D visual hierarchical model was extended by treating the depth map as an extra clue.Depth was incorporated into the saliency map that was built by integrating color,orientation,and motion contrast features.
However,in this model,binocular rivalry,binocular combination,or binocular conf lict were not taken into account.The author demonstrated the model by using eye tracking to analyze stereoscopic filmmaking[21].The eye tracking mechanism allows the model to be compared with ground-truth results from 3D visual saliency models.In[22],a saliency model was created by solving the temporal coherence problem in 3D visual perception.However,in this paper,we focus on spatial consistency in 3Dsaliency models.
2.3 Texture-Synthesis Models
MVD or multiview video(MVV)generates a greater amount of data for transmission and storage compared with conventional 2D video.To address this problem,3D video coding needs to have high compression efficiency.However,the difference between the 3D and 2D video features makes it difficult to use 2D encoding algorithms for 3D video.In general,it is advantageous to use the depth video to assist in the coding of the color video.
There are structural similarities between the depth image and color image,which means that objects at the same location in the images share the same motion information.In[23],a method of sharing motion information between the depth video and texture video was proposed.The motion vector of the texture video was split and recombined for motion compensation in the depth video.However,the method results in only slightly better coding performance in low-bitrate scenarios.In[24],view synthesis prediction was proposed for multiview video coding,and rate distortion was optimized to guide the coding process.This optimization was based on view synthesis prediction and was shown to improve coding gain.Depth image-based rendering was done to synthesize the virtual videos of different perspectives and to reduce the coding bit rate.Encoding bit rate is reduced by increasing decoding complexity.Occluded regions in the original videos are properly displayed in the virtual videos.In[25],a novel non-parametric texture-synthesis-based approach was proposed to fill the holes in the synthesized video.The method takes into account the statistical dependencies of a sequence by a background sprite,and unknown regionsarerecovered usingtheimagecontent.
3 Detailsof Some Algorithmsthat Perform Well
Here,we describe state-of-the-art models for 3D perception.3D visual attention models can be integrated into the encoding framework as the guide for bit-rate assignment.3D JND models are frequently used to filter encoding distortion.Models based on texture synthesis are proposed to fill the holes in synthesized video that arise a result of texture masking.The 3D-perception coding algorithms accurately describe binocular effects.
3.1 Just-Noticeable Difference Algorithms
In the conventional 2D JND model in[26],luminance adaptation and contrast masking are non-linearly summed by weight to obtain the JNDs.The luminance adaptation describes the visibility threshold in terms of background luminance(Weber's law)[27].Contrast masking arises because the visibility of a spatial object can be reduced in the presence of a neighboringobject:
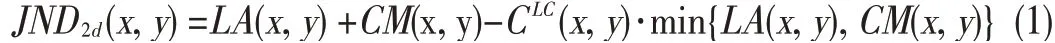
where JND2d(x,y)is the 2D image JND;LA(x,y)and CM(x,y)are the visibility thresholds for luminance adaptation and contrast masking,respectively;and CLC(x,y)is the effect of overlapping of two factors for 0<CLC(x,y)≤1.The factors of the 2D JND could also work in the 3D-image JND.A joint JND(JJND)model wasbuilt on theassumption that theocclusion introduces stronger depth perception and leads to smaller JNDs.Therefore,the JNDs were calculated by dividing the image into occlusion and non-overlapped regions[14].The 3D JND model is shown in Fig.1[9]and isgiven by
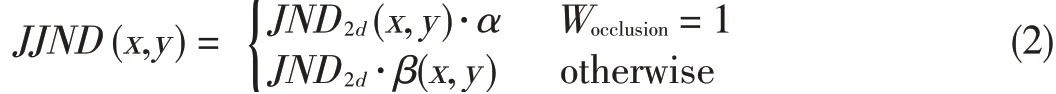
whereαis set to 0.8,andβ(x,y)derives from the depth of a pixel[14].When the pixel belongs to an occluded area,Wocclusion=1.The method used to judge whether a pixel is in an occluded areaisdescribed in[28].
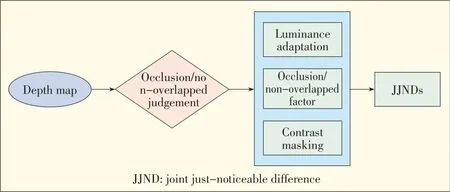
▲Figure1.JJNDmodel.
3.2 Building the Depth Saliency Model
The visual attention values of video content are calculated by simulating the human visual perception mechanism in traditional 2D video saliency models.The prominent difference between 2D and 3D imaging is depth perception.Depth affects saliency by making the pop-out areas of a 3D image more attractive to the human eye than concave regions and by making areas with inconsecutive depth or higher depth contrast more attractive to the human eye.All of these areas are more visually stimulating[20].The depth saliency model in[20]is used to obtain the depth saliency map,which is the same size as the original image,and each pixel of the map corresponds to each depth attention value.First,we calculate the depth from the horizontal disparity map.Then,the depth intensity and depth contrast are weighed to obtain the final depth saliency map(Fig.2).
In the first step,a stereo-matching algorithm based on color segmentation is used to calculate the disparity map that repre-sents the relative depth between the two views.The vertical disparity is assumed to be zero.The next step is to translate thedisparity map intoadepth map:
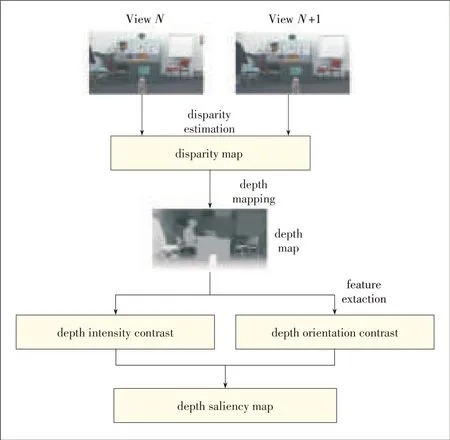
▲Figure2.Generation of thedepth-saliency map.

where F isthe focal length of the camera,B is the baselinedistance between adjacent cameras,disp is the disparity of the corresponding object in the neighbor view video,and Z is the depth value of the distance between the object and camera in the scene.
The depth saliency can be calculated using(3).The intersection of the two cameras creates a zero-disparity plane that is the default screen for 3D TV.The pop-out objects correspond to negative disparity,and the concave objects correspond to positive disparity.Depth is inversely proportional to disparity.Then,depth is quantized as an 8-bit value,where 0 is the farthest object and 255 is the nearest object.The degree of saliency decreases monotonically with the distance of the objects;the nearer theobjects,the moresensitivethehuman visual perception.Therefore,the depth ismapped into the range between aminimumand amaximumvaluethrough non-linear quantization[29]:

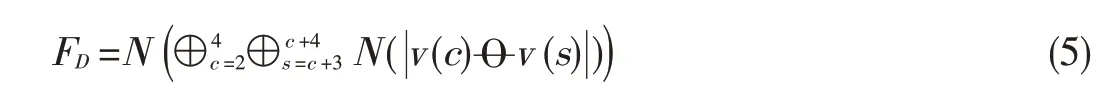
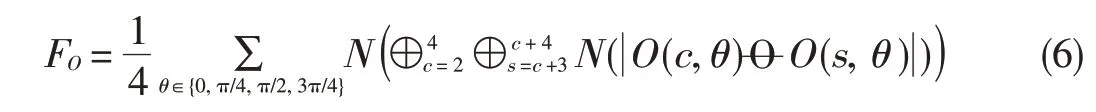
where N(.)normalizes the values into a fixed range.The depth contrast and depth orientation maps are then summed with weightstocreatethefinal saliency map:

Thismodel was built with on assumption that the pop-out regions of the 3D image attract more attention than the concave regions,and the area with inconsecutive depth or higher depth contrast is more attractive to the human eye.In[31],the model exploits the special visual characteristics of a 3D image;however,the results are not compared with the ground-truth.
3.3 Building a Texture-Synthesis Model
For additional viewing perspectives,depth image-based rendering(DIBR)is proposed to synthesize the virtual video from the original color image and corresponding depth image.Unknown areas in the original images become visible in the virtual images.The texture-synthesis model is used to recover the unknown areas in[11],holes are classified according to size.Small holes are reconstructed via Laplace cloning,which is 10 times faster than texture synthesis.Holes larger than 50 samples are filled using patch-based texture synthesis in which the statistical properties of pixels of the known neighboring areas are calculated.Content in unknown areas is derived from known areas,and the filling position is deduced by a priority term.Two aspectsof the algorithmin[32]areimproved in[11].The gradient is also obtained for initialized content,and filling occurs from background areas to foreground areas Finally,the best-matched patch for the current hole is sourced from neighboring patchesby minimizing thecost function:
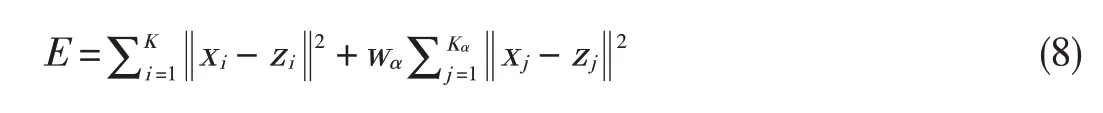
where E is the cost energy,xiis a patch in known regions,and ziis a patch in the hole area.The number of patches belonging to known areas is K,and the number of patches belonging to known holes is Kα.The weight factor of the patches in holes is wα.Post-processing is incorporated into the texture-synthesis framework tomakethepatch transition smooth.Texturesynthesis allows for ameliorative virtual video based on texture masking.However,patch-based texture-synthesis algorithms have higher computational complexity.
4 Performance Analysisand Comparison
The JNDmodel toleratesmoreadditional noisewithout sacrificing subjective image quality[33].Therefore,to evaluate the JND model accurately,the objective and subjective quality of the noise-injected image needs to be measured.Objective PSNRisused to calculate the amount of noise added to the images.In[12],JNDwasexperimentally measured,and it wasdetermined that a depth value change of 7%can result in noticeable difference.In[13],a JND model for 3D images is created by experiment.The model and experimental results are helpful for theoretical study;however,the view condition constraint limitsits applicability.
Compared to the 2D JND model in[26],the 3D JND model in[14]calculates visual perception more accurately.The PSNRof the images processed by themodel in[14]is,on average,1.03 dB lower than that of the images processed by the model in[26]when MOSscores are similar.This means that more noise can be added to the images guided by the model in[14].Therefore,for 3D images,the model in[14]could explore more vision redundancies while keeping the 3D images at a similar subjectiveperformancelevel.
In[17],the quality of the proposed model isnot quantitatively evaluated.However,saliency was shown to be accurate for several images for simple geometric objects[17].The problem with this model is that it is designed for one eye only and might not be suitable for binocular perception.The 3D saliency models are evaluated according to the efficiency of their bit rate allocation.The model in[13]can save more than 21.06-34.29%bit rate,which corresponds to 0.46-0.61 dB ROI PSNR gain with similar subjective video quality with as JMVM 7.0[33].The drawback of this method is that binocular effects are not taken into account.In[19],depth-bias feature is demonstrated using an eye-tracking experiment.Binocular effects are exploited while visual saliency is modeled and the saliency featureisdescribed accurately.
In[34],a method is proposed in which motion information is shared between depth and color images.This reduces encoding complexity to 60%that of existing algorithms,and 1 dB PSNR gain against encoding two sequences separately at low bit rates.In[24],a rate-distortion optimization algorithm was created for multiview video coding.The algorithm achieved 0.3-0.8 dB PSNR gain at low to medium bit rates.In[25],the motion vector was predicted using view synthesis prediction.This approach saves 3.86-9.32%more bit rate than MVC.However,the models previously mentioned cannot guarantee high codingefficiency at high bit rates.
5 Conclusion
Unlike 2D video,3D video has depth perception,which necessitates the development of 3D visual perception algorithms.New requirements include disparity adaptation between different display screens,2D to 3D conversion,3D error concealment,and 3D rendering.Considering that the final receivers of a stereoscopic scene are the human eyes,3D perceptual models have been exploited so that visually comfortable 3D video can be transmitted over a channel of limited bandwidth.In this paper,we focus on state-of-the-art of 3D perception algorithms and analyze their potential application in 3D video coding.Experimental results show that higher coding efficiency and more satisfying 3D TV experience can be achieved by properly integrating 3D perceptual models.However,extending 3D perception algorithms and effectively incorporating 3D perceptual models into video compression requires further exploration.

- ZTE Communications的其它文章
- QoE Modeling and Applicationsfor Multimedia Systems
- Methodologiesfor Assessing 3D QoE:Standardsand Explorative Studies
- New Member of ZTECommunications Editorial Board
- Estimating Reduced-Reference Video Quality for Quality-Based Streaming Video
- Human-Centric Composite-Quality Modeling and Assessment for Virtual Desktop Clouds
- Assessing the Quality of User-Generated Content