
基于敏感元组的聚类匿名数据发布
2013-05-13 05:41刘海
湖南文理学院学报(自然科学版) 2013年4期
刘 海
基于敏感元组的聚类匿名数据发布
刘 海*
(浙江金融职业学院 经营管理系, 浙江 杭州, 310018)
在数据发布的过程中, 为了保护个人隐私常需对所有准标识符进行泛化操作, 而实际涉及到个人隐私相关敏感属性元组是非常少的. 据此, 从这些涉及个人隐私的敏感属性的元组出发, 将剩余大量仅涉及非敏感属性元组依据敏感属性值不同进行分组, 最后对分组中元组以计算与个人隐私属性相关敏感属性距离的方式, 选取距离最短的元组进行泛化, 其余元组并不进行泛化, 通过这种方式, 提高了数据的利用率, 并有效减少信息的损失.
隐私保护; 数据发布;匿名; 泛化; 聚类
近年来, 许多与个体相关的数据包括人口统计数据、患者医疗数据等需要进行公开发布, 有的是供各类科研机构进行数据分析和预测使用, 还有就是由于政策导向的要求. 这些发布的数据可能被存储或者处理, 为了保护某些个体的隐私, 传统的方法仅仅进行个体身份识别属性的隐匿或者加密, 单纯采用这种方法隐私保护效果很差, 窥探者可以通过发布数据集中的准标识符与外部表进行连接等操作, 从而推断出个体希望保护的敏感属性. 据美国统计局的一份统计资料显示, 只要获得1位美国公民的性别、年龄和邮政编码, 则87%美国公民的身份就能够被确认. 针对发布数据产生信息效益的同时如何对个体隐私信息有效保护这一问题, 许多学者提出了隐私保护的模型及匿名化的方法. P.Samarati和L. Sweeney[1]在2002年率先提出了匿名模型, 该模型能保证发布中的数据有条元组在准标识符上是一致的, 从而该模型能够避免数据表和表之间的连接攻击, 但该模型容易受到背景知识攻击和同质攻击. Machanavajjhala[2]在2006年针对匿名模型的缺点, 提出了l-多样性模型, 要求在每一个分组中的敏感属性个数要大于l个, 从而避免同质攻击. 后来一些学者也提出了改进的模型, N. LI[3]在2007年提出了-closeness模型, 在每个匿名分组中的敏感属性的不仅要具有l-多样性而且敏感属性在每个分组中的分布与其在全表中的分布差异要小于. 杨晓春[4]等在2008年提出了面向多敏感属性的隐私保护方法, 该方法利用多维桶技术, 并分别设计了最大桶优先、最大单维容量优先及最大多维容量等优先算法来解决数据发布过程中的隐私泄漏问题. Wong R[5]在2009年提出了(,)匿名模型, 该匿名模型通过限定簇中敏感属性出现的频率均小于的方式来达到敏感属性的多样性, 降低概率攻击的可能性从而实现隐私保护. Mingqiang Xue[6]等在2012年提出利用位图集及组内循环相关部分隐匿等方式实现数据的隐私保护. Tiancheng Li[7]在2012年初提出了Slicing方法, 其将准标识符和敏感属性进行切片, 切片内保持属性之间关系, 切片外属性之间关系打乱的方式来处理隐私保护数据发布.
以上的这些模型, 考虑得相对比较周全, 但一般而言, 发布数据集中的敏感属性中涉及到隐私的属性是非常少的, 需要进行保护的也仅仅是这些属性, 比如在医疗信息表中, 仅仅需要保护的是癌症、爱滋病等相关元组信息, 其余大量元组敏感属性为普通感冒、头痛等疾病, 并不需要进行保护. 本文从需要保护的敏感属性出发, 依托数据集本身特点, 通过将不需要隐匿敏感属性的元组按敏感属性值不同进行分组, 并依据的大小不同, 从每个分组中分别寻找元组来组成匿名组的方式来提高匿名组中的匿名多样性, 利用计算每个分组中元组和需匿名敏感元组最短距离的方式, 来降低泛化程度, 提高数据的利用率.

表1 原始数据表T
1 相关概念
在数据发布的过程中, 一般可以按照数据的属性将数据划分为四种类型: ①个体识别属性. 其可以显式表示出个体身份特征的属性, 如姓名、身份证号码等, 这些属性在数据发布前, 一般已经被隐匿或删除, 如表1中的姓名. ②准标识属性. 一个准标识属性是由一组属性构成的属性组, 且能够通过连接运算标识出数据表中的个体信息, 如表1中的属性组{Age, Zip, Sex}. ③敏感属性. 指的是与个体敏感信息相关的属性, 包括: 薪水、疾病等, 如表1中的Disease. ④其它属性. 描述个体的一些其它信息.

表2 匿名化表T*
定义1(等价类): 一个等价类是由若干个元组构成的集合, 这些元组在准标识符上具有相同的属性值. 例如, 在表2中Bob和Ales其在准标识符Age上具有相同的年龄范围[19, 20], Zip上均为[12 k, 20 k], Sex上均为M.
定义2(数据泛化): 在不违背原有语义的基础上, 使用相同的抽象属性值来代替多个元组中的不同属性值. 例如, Bob的年龄为20, 我们可以将其年龄泛化为[18, 25]的一个年龄范围, 通过泛化使得数据的范围更广, 相应的数据精度也降低了.
定义3(数值属性泛化的信息损失): 为泛化后属性范围和泛化前属性范围的比值计算信息损失. 用如下式1来计算.QI[1]和QI[2]分别表示等价类中1元组的第个属性和2元组的第个属性. 例如, 在表2中Bob的年龄泛化为[19, 20], 则可以计算该数值属性泛化的信息损失为: (20-19)/(45-19) = 1/6 = 0.17.


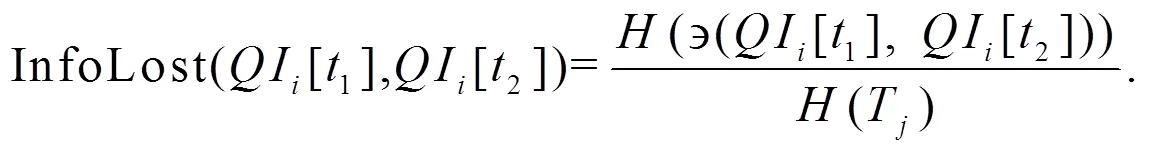
定义5(元组失真度): 元组在准标识符属性集上, 数值属性泛化的信息损失和分类属性泛化的信息损失之和, 用式(3)计算.表示等价类中属性组的个数,w为第个属性的权重. 等价类中每个属性组对元组间距离的影响是不同的, 所以可以为每个属性组设置一个权重, 来反映属性对元组信息损失的影响.

2 算法
算法的基本前提假设: 敏感属性有且只有一个. 敏感属性和其他属性之间是可区分的. 敏感元组在数据表中所占比例很低. 输入: 待发布的数据表{1,2,3, …,QI,}, 敏感值集合, 匿名参数, 权重矢量. 输出: 满足隐私保护要求的发布表*

2.1 正确性分析
对于*而言, 每个匿名组的元组数均为, 一则: 对于每一个匿名组中仅有一个元组属于敏感元组; 二则: 对于匿名组实现了最大化的敏感元组差异性; 三则: 剩余的非敏感属性元组并不需要进行泛化. 通过这种方式: ①降低了需要匿名的元组个数, 仅仅是在匿名组中的元组需要进行匿名运算, 减少了信息损失; ②通过选取对匿名元组而言最近的元组进行泛化操作, 降低了泛化高度, 同样也减少了信息损失.
2.2 复杂性分析
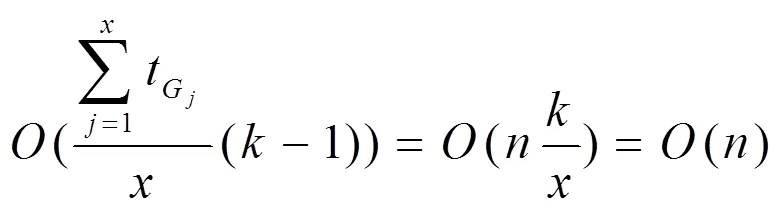
3 实验及结果分析
实验环境为: 2.67 GHz Pentium CPU, 2 G内存, windows XP操作系统, 程序使用C语言, 在C-Free 5.0平台上实现, 实验采用来自UCI machine learning repository的Adult标准数据集, 该数据集共有48 842个记录, 首先删除数据集中Age、Workclass、Martial-status、Race、Education属性有为空的元组, 然后选取Adult数据库中前3万条数据记录作为实验数据, 以年龄、工作阶层、婚姻状况和种族作为准标识属性, 并以Education作为敏感属性进行试验, 见表3.
选取Preschool作为需要隐匿的Education属性中的敏感属性, 该属性共有41条, 其余15个敏感属性数均远远大于41, 本文在2个方面进行比较.

表3 Adult数据库部分数据描述
3.1 信息量损失比较
将值分别取4、7、10、13查看信息的损失, 从图1中可以看出随着K值的增加, 泛化的元组平均信息的损失也逐渐增加, 一方面信息损失的比例在增加, 这是因为随着值增加, 泛化的元组数也增加, 显然会带来更多的信息损失. 另一方面信息损失随着值增大, 增加不多, 是因为泛化元组及其属性总数从656(41 × 4 × 4)到2 132(41 × 4 × 13)远小于测试数据集中元组及其属性总数1 920 000(30 000 × 4 × 16).

图1 不同K值的信息损失
3.2 执行时间的比较
将值分别取4、7、10、13查看信息的损失, 从图2中可以看出随着值的增加, 程序的运行时间也逐渐增加, 在= 13时候其运行时间是= 4时候的接近5倍, 其原因是: 一方面, 每进行一次聚集, 需要搜索的元组数在= 13时候是= 4的3倍, 另一方面, 一次生成多个不同的随机数的时间随着值增加也显著增大.

图2 不同K值的运行时间
4 总结
在隐私保护数据发布的研究过程中, 仅仅简单的对敏感属性进行泛化处理及隐匿操作, 会造成不必要的大量数据的信息损失及极低的数据处理效率. 模型通过先对数据集中的数据进行分析, 选取部分数据进行泛化, 一方面, 能够满足匿名数据集中差异程度最大化; 另一方面, 在保证了数据匿名要求的同时, 最大限度地保留原有数据的属性.
[1] Sweenty L.-anonymity: a model for protecting privacy[J]. International Journal on Uncertainty. Fuzziness and Knowledge-based Systems, 2002, 10(5): 557—570.
[2] Machanavajjhala A, Gehrke J, Kifer D. l-Diversity:Privacy beyond-anonymity[A]. Proc of the 22nd International Conference on Data Engineering[C]. USA: IEEE Press, 2006: 24—36.
[3] Li N H, Li T C, Venkatasubramani S. t-closeness:privacy beyond k-anonymity and l-diversity[A]. ICDE 2007: Proceedings of the 23rd International conference on Data Engineering. Washington[C]. DC: IEEE Computer Society, 2007: 106—115.
[4] 杨晓春, 王雅哲, 王斌, 等. 数据发布中面向多敏感属性的隐私保护方法[J]. 计算机学报, 2008, 31(4): 574—587.
[5] WONG R, LI J, FU A,et al. (,)-anonymous data publishing[J]. Journal of Intelligent Information Systems, 2009, 33(2): 209—234.
[6] Xue M Q, Panagiotis K, Chedy R, et al. Anonymizing Set-Valued Data by Nonreciprocal Recoding[J]. The 18th ACM Data SIGKDD International Conference on Knowledge Discovery and Data Mining KDD, 2012, 12: 1050—1058.
[7] Li Tiancheng. Slicing: A New Approach for Privacy Preserving Data Publishing[J]. IEEE Trans Knowl Data Eng, 2012, 24(3): 561—574.
On anonymous data publishing based on sensitive tuple cluster
LIU Hai
(Management Department, Zhejiang Financial College, Hangzhou 310018, China)
During the process of data publishing, in order to protect personal privacy, data owner often has to generalize all the quasi-identifier, but in fact the tuple involving personal privacy is very few. So our method starts from the tuples, then divides the remainder into groups according to different sensitive attribute value. Finally, our method selects one tuple per group which is shortest to the tuple involving personal privacy for generalization. The rest tuples need not to be generalized. In this way, our method has improved the utilization rate of the data and reduced the loss of information effectively.
privacy preservation; data publishing;-anonymous; generalization; cluster
10.3969/j.issn.1672-6146.2013.04.015
TP 309.2
1672-6146(2013)04-0060-04
email: feelnice_cn@126.com.
2013-09-09
浙江省教育厅2012年度高校科研项目(Y201224136)
(责任编校:刘刚毅)
猜你喜欢
计算机应用(2022年8期)2022-08-24
电脑报(2021年14期)2021-06-28
党员生活(2020年2期)2020-04-17
计算机系统应用(2020年8期)2020-03-22
计算机与生活(2019年5期)2019-07-18
铁道通信信号(2018年10期)2018-12-06
吉林大学学报(理学版)(2018年2期)2018-03-29
中国美术馆(2016年6期)2017-01-19
图书馆(2014年3期)2014-12-25
中国石油企业(2014年4期)2014-11-30
