
基于Relief-SBS特征选择算法的入侵检测方法研究
2013-03-27 07:21杨云峰
河池学院学报 2013年2期
杨云峰
(河池学院 计算机与信息科学系,广西 宜州 546300)
1 概述
互联网爆炸式的发展给人们生活带来了很大的便利,并被广泛应用于各种领域,人们在享受互联网进步成果的同时,也面临着其带来的威胁。网络安全与互联网相伴相生,入侵检测作为网络安全的焦点技术,可以追溯到1980年,即J.A[1]在研讨技术报告中首次提出的。此后,不断有学者和研究人员深入研究和完善入侵检测模型和应用技术手段,例如,1990年,Heberlein[2]开发的NSM系统(Network Security Monitor),通过捕获ICP/IP分组,直接把局域网上的网络信息作为审计数据来源进行检测。2007年,M.R[3]团队提出的系统是基于误用检测代理的分布式入侵检测,它通过Drools规则引擎和Snort配合使用,提高系统可扩展性。2008年,Aly El-Semary[4]主要针对入侵检测动态日志问题,通过Apriori算法结合Kuok算法,动态产生模糊逻辑规则。2009年,Ya-Liding[5]等人提出的Apriori算法的神经特征搜索算法能有效提高检测效率。
随着网络技术和存储技术的迅猛发展,对入侵检测技术的性能要求也越来越高,本文在仔细分析统计相关性的特征选择算法(Relief)的基础上,结合顺序后向搜索算法,形成基于Relief-SBS特征选择算法,将其应用在入侵检测上,实验表明该方法能够提高入侵检测的效率。
2 数据采集和预处理
入侵检测的第一步是数据收集,如果收集的数据延时大、数据不完整,或是发生错误导致收集到错误的数据,入侵检测性能就会下降甚至无意义。根据信息采集的不同,主要有两种数据源:第一种是利用系统日志数据作为数据源,第二种是利用网络数据作为数据源。基于实验的局限性,难收集到各种攻击数据,所以本实验采用目前入侵检测研究最广泛使用的标准数据集—KDD99[6]数据集作为数据源,并采用kddcup.data_10_percent_corrected作为训练集,corrected作为测试集。
KDD99数据集中的样本特征共41维,主要包含的类型是:基本特征、内容特征、时间流量特征和主机流量特征等四类。由于本文实验中采用的分类器为支持向量机,其仅能处理数值型数据,标准数据集中的原始数据含有名词的离散型特征,因此要进行预处理,预处理主要有如下三步:
(1)重新对原始数据的类别标签进行归类。
(2)把离散型特征转换成连续数值型特征。原来取值为0或1的离散型的特征值不变,取值为名词的,根据所有特征分为多个子特征,并确保不同记录之间的同一离散型特征差异相等。
(3)数值归一化。设max和min是训练集中某一特征的最大值和最小值。设归一化后的数值范围为[new_min,new_max],则由原值u到新值v的映射关系为:

一般情况下,归一化后的数值范围可以有[-1,+1]和[0,1]两种选择。本文选择[0,1]作为归一化后的数值范围。
数据预处理后,数据集的特征共计118维特征,如表1、2所示,每个特征名称前面都有一个唯一的标号。完成了数据预处理后,数据集满足了后续分类器的输入要求,为特征选择和分类做好了准备。

表1 预处理后的KDD99数据集的基本特征
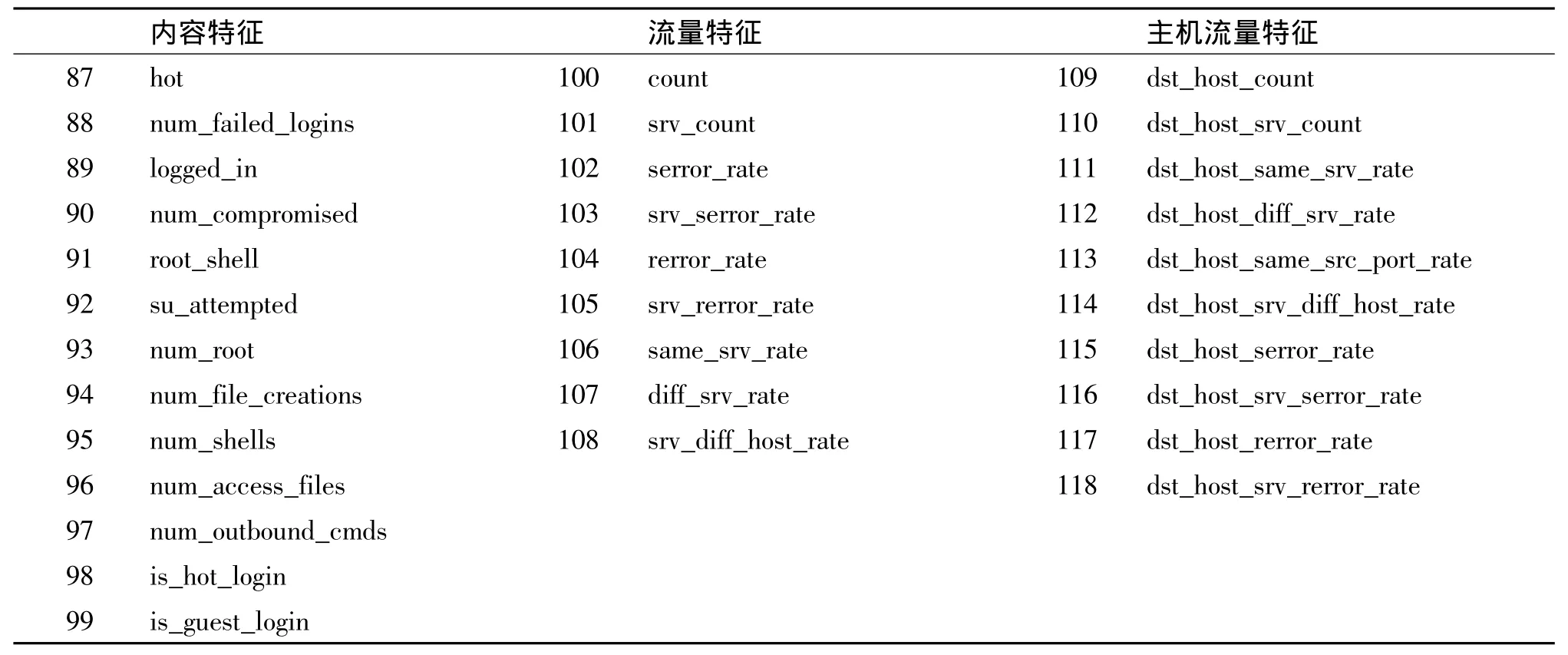
表2 预处理后的KDD99数据集的内容、流量、主机流量特征
3 基于Relief-SBS的特征选择算法描述
本文的特征选择算法是在分析综合统计相关性的特征选择算法(Relief)与顺序后向搜索算法的基础上形成的。Relief算法是基于统计相关性的特征选择算法,是由Kenji Kira和Larry Rendell提出的,当初是为了解决两类分类中多个特征相互关联与作用的问题[7]。其原理是依特征对近距离样本的区分能力来评估特征,就是好的特征应该能够使同一类别的样本之间互相靠近,不同类别的样本之间相互远离。顺序后向搜索算法是在特征子集中进行搜索时根据方向不同划分的特征选择算法。基于Relief与顺序后向搜索的特征选择算法在每一轮迭代后去除一个特征,并在每一轮迭代中,采用Relief算法的结果作为特征的评估标准。
算法流程如下:

输入:训练数据集Train;初始特征集 T0={Fj,j=1,2,…,N}及其对应权值 D[1…N];分类器函数:λ=Classifier(训练集,特征集),λ为分类正确率;Relief算法函数:D[1…N]=Relief(Train,T),D 按从大到小排序。初始化:Tbest=T0;λbest=Classifier(Train,T0);D[1…N]=0;for(i=1;i< =N-2;i++){D[1…N-i+1]=Relief(Train,T);//对训练集 Train执行 Relief算法将特征权值最小的特征去除;获得新的特征子集 T={Fj,j=1,2,…,N-i},其对应权值为 D[1…N-i];λ =Classifier(Train,T);if(λ<λbest)break;Tbest=T;λbest=λ;}输出:特征子集Tbest中的特征。
在Relief-SBS算法中,分类器函数——Classifier(训练集,特征集)的选择是比较灵活的。本文使用的分类器是支持向量机。
4 实验结果与分析
4.1 实验方案
为了更有利于全面考察特征算法的性能,检测的结果同支持向量机结合起来,并采用了C-SVM和ν-SVM两种支持向量机作为对特征子集进行评估的分类算法,特征提取上为了比较,还使用预处理后得到的全部特征118维进行实验,所以形成了四种方案:(1)全部特征+C-SVM;(2)Relief-SBS特征选择+CSVM;(3)全部特征+ν-SVM;(4)Relief-SBS特征选择+ν-SVM。
Relief-SBS特征选择+C-SVM算法在第65轮迭代后中止,也就是总共去除了原特征集118维特征中的64维特征,保留了54维特征,如表3所示。Relief-SBS特征选择+ν-SVM的算法第70轮迭代后中止,也就是总共去除了原特征集118维特征中的69维特征,保留了49维特征,如表4所示。
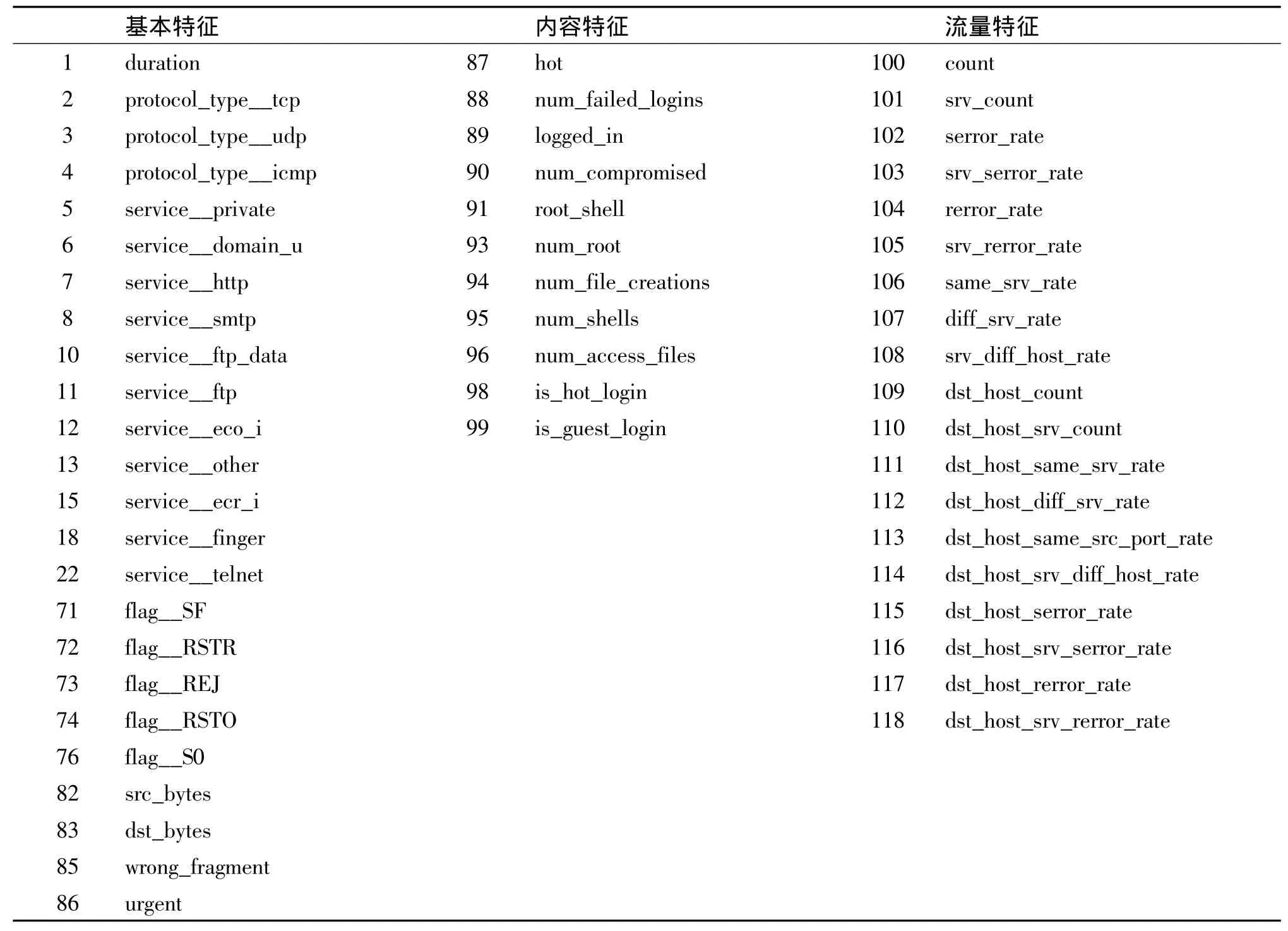
表3 采用C-SVM评估的Relief-SBS特征选择后保留的特征子集(54维)

表4 采用ν-SVM评估的Relief-SBS特征选择后保留的特征子集(49维)

表4(续)
4.2 实验性能评价指标
本实验通过检测率、虚警率、样本平均代价三个指标作为入侵检测系统的性能评价指标。对于入侵检测系统,检测率越高越好,虚警率越低越好,样本平均代价越低越好,但是很难达到检测率与虚警率同时达到最优的目标,这也是入侵检测研究的重点之一。因为实际的网络环境中,正常的样本数庞大,攻击的样本比例小,所以极低的虚警率也可能产生大量的误报警。
检测率=正确检测出来的攻击样本数/攻击样本总数。
虚警率=误判为攻击的正常样本数/正常样本总数。
其中,Cost(i,j)是标准数据库KDD99入侵检测竞赛在对不同的分类器的分类结果进行评价与比较后所给出的错分代价矩阵。每一行是正确类别:即样本实际类别,即“正确类别”;每一列是输出类别:即样本被分类器分配的类别,矩阵元素表示错分代价。本文将其作为与其它研究比较性能的基准。
CM(i,j)是指分类器输出的混淆矩阵(Cofusion Matrix),每一行是样本实际类别,每一列是样本被分类器分配的类别,矩阵元素代表分类器对应类别输出的样本数。
4.3 实验结果
根据设计的实验方案,实验中选取用于支持向量机训练与测试的参数C的取值包括:2-1、21、23、25、26、27、28、29、210、211、212、213、214、215、216共 15 种,σ 的取值包括:20、2-1、2-2、2-3、2-4、2-5、2-6、2-7、2-8、2-9、2-10共11种,它们取值的组合构成了一个网格。每种组合在训练集上进行交叉验证,表5列出实验时部分组合结果,得知当C=29,σ=2-4时全部特征+C-SVM取得了最高的检测率与最低的平均代价,当C=216,σ=2-3时Relief-SBS特征选择+C-SVM取得了最高的检测率与最低的平均代价,将最好结果的组合作为最优参数对支持向量机进行训练,然后进行测试。得到最终实验数据如表6所示。
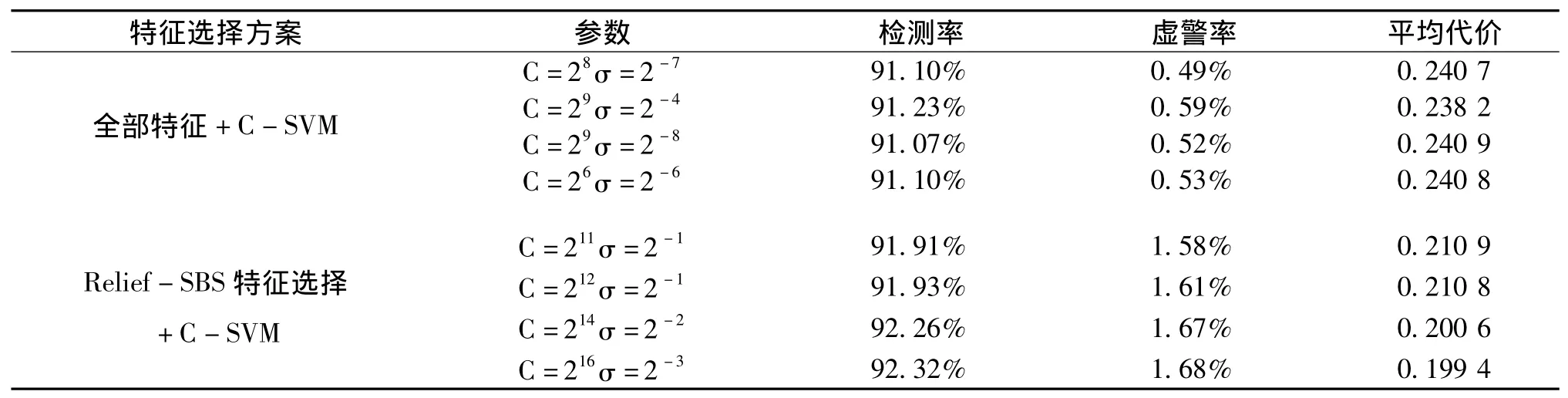
表5 全部特征、Relief-SBS特征选择分别与C-SVM在测试集上的性能
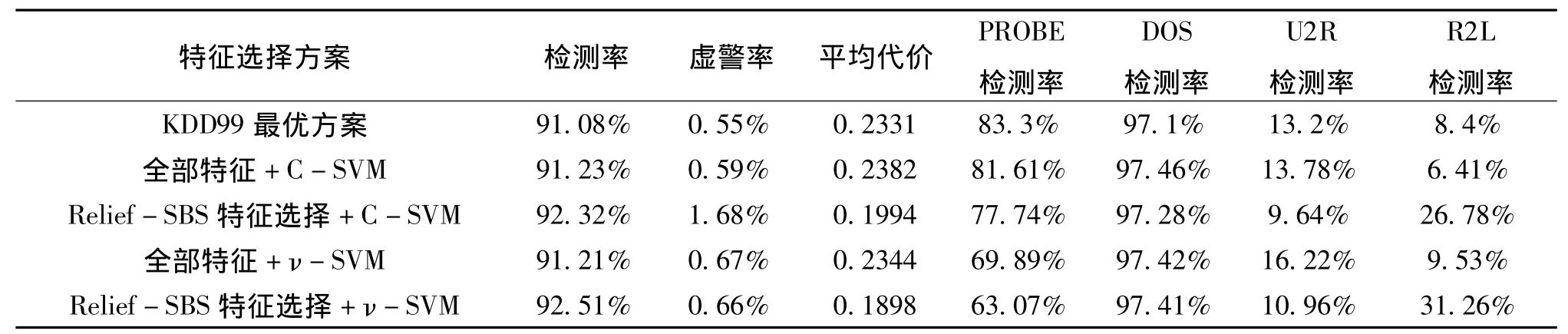
表6 支持向量机C-SVM与ν-SVM在测试集上的性能综合比较
4.4 结果分析
由表5、表6可以看出,基于全部特征和C-SVM的性能与基于全部特征和ν-SVM的性能差别不大,基于Relief-SBS特征选择+ν-SVM的性能略优于基于Relief-SBS特征选择+C-SVM的性能。基于Relief-SBS特征选择+C-SVM的性能及基于Relief-SBS特征选择+ν-SVM的性能都优于KDD99最优方案。可见,本文提出的Relief-SBS特征选择算法与两种支持向量机分类器结合起来都能够有效地促进分类性能的提高,也充分地说明了本文的特征选择算法的有效性和可靠性,它为入侵检测技术这一长期目标提供相关技术支持。
[1]Anderson JP.Computer Security Threat Monitoring and Surveillance[R].Fort Washington,PA:James P.Anderson Co,1980.
[2]Heberlein LT,Dias GV,Levitt KN,et al.A network security monitor[C].California:IEEE Computer Society Press,1990:296-302.
[3]Mosqueira-Rey E,Alonso-Betanzos A.A Misuse Detection Agent for Intrusion Detection in a Multi-agent Architecture[J].Agent and Multi-Agent Systems:Technologies and Applications,2007:466-475.
[4]Aly El- Semary,Janica Edmonds,Jesus Gonzalez-Pino.Applying data mining of fuzzy association rules to network intrusion detection[C].UK:University of London press,2006:100-107.
[5]Ya-Li Ding,Lei Li,Hong- Qi Luo.A novel signature searching for intrusion detecting system using data mining[C].United States:IEEE Transaction on SMCB,2009:122-126.
[6]Charles Elkan.KDD'99 Classifier Learning Contest[EB/OL].[2012-10-06].http://www-cse.ucsd.edu/users/elkan/clresults.html.
[7]Kononenko I.Estimating attributes:analysis and extensions of RELIEF[C].United States:Morgan Kaufmann,Publishers,1994:171-182.
猜你喜欢
电子制作(2017年23期)2017-02-02
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
西北工业大学学报(2015年4期)2016-01-19
新校长(2016年8期)2016-01-10
智能系统学报(2015年4期)2015-12-27
商事法论集(2014年1期)2014-06-27
电测与仪表(2014年15期)2014-04-04
中国中医药现代远程教育(2014年16期)2014-03-01
振动工程学报(2014年4期)2014-03-01
