
文本相似性在抄袭问题中的应用研究①
2013-03-19 00:18丁智斌霍豫宗
华北科技学院学报 2013年1期
丁智斌 霍豫宗 杜 念
(1.华北科技学院基础部,北京东燕郊 101601;2.广发银行股份有限公司,广东广州 510080)
0 引言
现在WEB中存在的可分析信息99%是以文本形式存在的,而WEB网页总量已达数百亿,每天新增的网页可以达到以千万计数的级别。WEB内容挖掘是指从网页或其描述中发现知识的过程,主要是根据网页本身的内容作资料挖掘,而其中的WEB文本挖掘是对文本集合的内容进行总结、分类、聚类、关联分析以及趋势预测等来实现文本内容的挖掘,是采用计算语言学的原理对文本信息进行抽取的研究和实践。
抄袭一直是学术界和文学界最为烦恼的问题。巨大的文章量使得人工判定完全无法实现,因此机器判定就必须使用到自然语言处理技术。而自然语言处理技术是文本挖掘中最复杂的技术,因为使计算机理解基本无结构可言的文本数据是一个非常复杂的过程。现在有基于概率模型和基于向量空间模型两种方式来表达文本并用于计算文本间的相似度。得到文本特征模型和优化文本特征模型是这方面的难点。本文提出不使用自然语言处理,从向量空间模型上构建标准化的文本特征模型。通过足够多的文本构建一个完善的特征词库,再通过特征词构成各个文本的特征模型。一个完善的标准化的文本特征模型就可以表达文本的准确含义。
1 文本相似性
在现实生活中,许多领域都不断产生海量数据,特别是海量的文本数据。怎样从这些数据中抽取和发掘有用的信息和知识已成为一个日趋重要的问题。由于这个原因,文本挖掘虽是一个新兴学科,但已成为一个引人瞩目、发展迅速的领域。
1.1 文本表示
文本表示是指用文本的特征信息集合来代表原来的文本。文本的特征信息是关于文本的元数据,可以分为外部特征和内容特征两种类型。文本的内容特征需要通过分析处理才能得到。目前,在信息处理领域,文本的表示方法主要采用向量空间模型(Vector Space Model,VSM)。向量空间模型主要用于文本内容特征的表示,一般使用词来代表文本的特征信息,并称每个词为一个特征项。向量空间模型的基本思想是以向量(ω1,ω2,…,ωn)来表示文本,其中ωi为第i个特征项的权重。可以选择字、词或者词组作为特征项。
文本特征提取主要是识别文本中代表其特征的词项。构成文本的词汇,数量是相当大的,因此,表示文本的向量空间的维数也相当大,可以达到几万维,因此需要压缩维数,这样做可以达到两个目的:一是提高运行速度;二是词汇对文本分类的意义是不同的,找出在某特定类中出现比重大而在其他类中出现比重小,即对文本分类贡献大的词汇。文本特征提取的算法如下:
(1)初始情况下,该特征项集合包括所有该类中出现的词。
(2)对于每个词,特征项ti与文本dj的互信息量为I(ti;dj)。
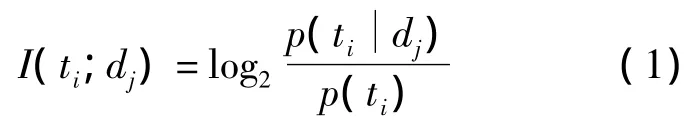
(3)对于该类中所有的词,依据上面计算的互信息量排序。
抽取一定数量的词(互信息量大的词)作为特征项。具体需要抽取多少特征项,目前没有很好的解决方法,一般采用先定初始值,然后根据试验测试和统计结果确定最佳值,一般初始值定在几千左右。
1.2 文本相似度计算
相似的文本具有相似的关键词或相对词频,因此,可以基于关键词向量或关键词相对词频向量来计算一组文本的相似度,然后可以利用文本相似度对文本进行分类。
T是文本与词的相关矩阵,其中tij表示第i篇文本与第j个词的相关程度,tij的取值范围为[0,1]。相关矩阵中的行描述一篇文本的特征,称之为文本特征向量,列表示每个特征项与文本集的相关程度。

利用文本与词的相关矩阵可以分析文本间的相关性。相关性的大小可以用相关系数S来度量,第i篇文本与第j篇文本的相关系数可以表示为Sij。
计算相关系数的方法有多种,其中,余弦系数法最为常用。余弦系数法的公式为:
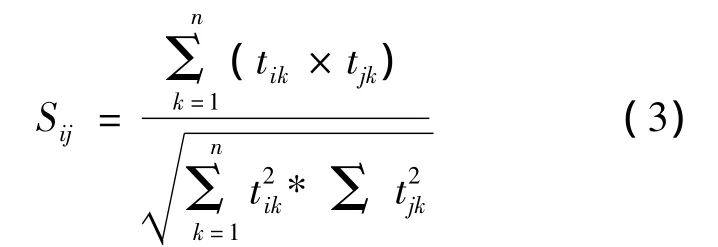
设d1和d2为两个文本特征向量,它们的余弦相似度定义以可以表示成如下形式:
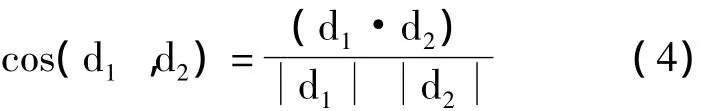
其中d1·d2为标准向量乘积,分母中的是向量di的模。
和余弦相似度计算方法类似的有Jaccard相似度计算方法,其公式为:
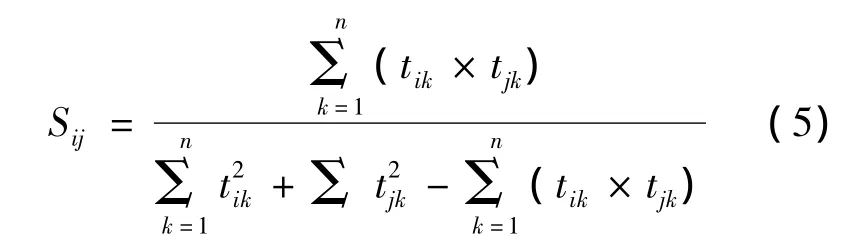
设d1和d2为两个文本特征向量,它们的Jarcard相似度定义以可以表示成如下形式:
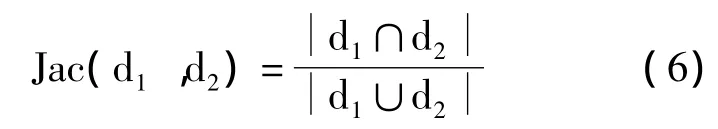
2 抄袭行为判定程序的设计与实现
2.1 程序设计
现在抄袭行为大致可以分为四种。
第一种是完全照抄。这种行为简单而且粗暴,易于被机器发现。已经是很少使用的抄袭手段。
第二种是部分抄。这种行为较上一种行为较为高级,文章中部分的句子是从他人的文章中抄袭过来的。这种抄袭行为不太常见,也容易被机器发现。
第三种是“借”。这种行为较上一种行为更高级,抄的可能只是他人文章中的单个句子,这些句子可能散落在整个文章之中,也可能只出现在部分重要段落之中。这种抄袭行为较常见,不太容易被机器发现。即便发现,也有可能因为抄袭的句子数量较少,低于判断标准而不做追究。
第四种是改。这种行为最难被发现。因为大部分计算机技术方法都是以字或词来判定相似性的,没有利用自然语言处理的方法来进行判别。所以对同义替换或改写等这些手段无法识别。
针对前三种抄袭行为的判定没有必要用到复杂的文本特征,本文设计了一个将文本转化为一个简单的字符串集合来进行相似比较的功能来实现简单的抄袭行为判断。其设计思想是将文本转换为一个简单的字符串集合,这个字符串集合的单位是短句,即以逗号来进行结尾的句子。在设计过程中对单位进行了多次重定义,最后定义为最开始设计的短句。尽管以短句作为单位会有一些因句子过短而存在的错误,但通过对代码的修正获得了改进。运行过程如图4.1所示。
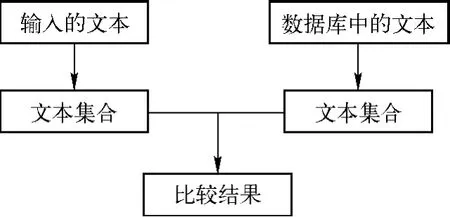
图1 运行过程
基于文本特征的判定实现是一种系统的判定过程,主要针对的是上面提及的第四种抄袭行为。由于是从整个文本含义去判断,这种判定取决于文本含义的准确程度。最终的计算结果将用两种方法去计算。一种是利用余弦相似度来计算,另一种是利用Jaccard相似度来计算。以余弦相似度为例给出计算过程的关键代码如下:

本文采用基于B/S的环境来进行开发,将用户分为普通用户和管理员,如图2所示。普通用户只拥有判断文章是否抄袭的功能,而管理员还拥有对用户、角色、角色权限、功能菜单、被比较文章的管理功能。用户之间的区分是通过用户所扮演角色来实现,每个角色有着属于自己的菜单,从而实现不同用户的不同界面。
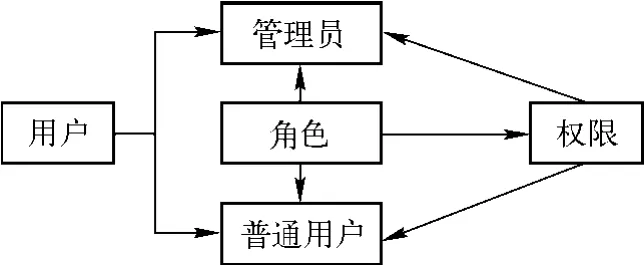
图2 用户管理示意图
2.2 基于文本相似度判定抄袭行为的实验效果
本文略去了从文本提取文本特征的过程,侧重点放在文本相似度的计算过程。在这里将文本特征标准化,用四个方面的特征来表示一篇文本。本文采用标准化文本特征向量的方法,这种方法是构建文本指纹,由于获得文本含义和文本分类是不同层次的,尽管优化文本特征维数有利于给文本分类,但复杂的文本特征才能完整地表示文本的含义。文本指纹和传统文本特征不同,文本指纹可以向下划分到词,即通过机械学习获得每个词在多个领域的值来构成一个词库。每个词都有着自己的指纹,通过统计词的指纹来获得文本的指纹。图3,4是特征值计算的初步模拟结果,测试数据在四个方面上的特征值均为1。
从结果上看,Jaccard相似度得到的结果偏小。这是两个相似度计算公式之间的不同所造成的。但是两者间的变动趋势却是几乎相同的,也就是说只要取不同的判定标准完全可以得到对抄袭行为相同的判定。不过这只是对文本特征的一个简单模拟而已,实际中文本特征的维数可能有成千上万,在这里我将文本特征扩充到8维再进行测试。在这里扩充的另外4维是互不相关的,亦即这多篇文章只有前4维相关。程序改进后的运行结果分别如图5,6所示。
对比图5与图6,Jaccard相似度对维数的敏感度没有余弦相似度那么明显,但还是有相当幅度的降低。在理想化扩充了维数之后,相似度结果明显降低,证明了给文本指纹设计一个足够大的维数是必须的。文本指纹和传统的文本特征是不同的,文本特征可能是万维的。文本指纹却可以给出一个标准,使得文本特征可以更好地保存和被程序反复利用。
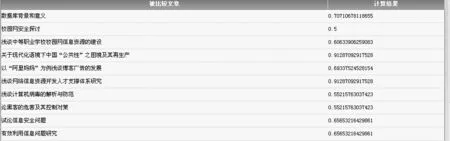
图3 余弦相似度计算结果

图4 Jaccard相似度计算结果
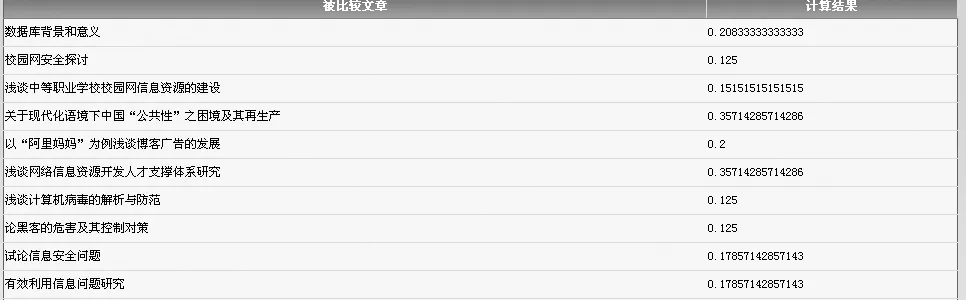
图5 改进后余弦相似度计算结果
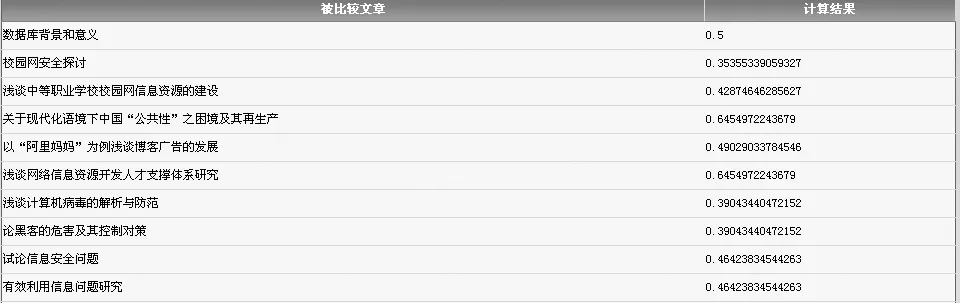
图6 改进后Jaccard相似度计算结果
3 结语
本文的设计方案是自然领域表示法,用一个词在多个自然领域的相关性来表达这个最简单文本的特征,把这个最简单文本的特征作为基础文本特征。然后在处理复杂文本的过程中将复杂文本分词生成一个词的集合,通过计算得到复杂文本的特征。如果基础文本特征足够好的话,这个生成的复杂文本特征就可以作为文本的指纹存在。文本指纹并不是传统意义上的文本特征,传统意义上的文本特征利于分类聚类。而对文章抄袭行为的判别是需要将每一个文本之间的不同都找出来,这就需要文本指纹,一个足够复杂的文本特征。本文对这个基础文本指纹的维数设计进行了探讨,结果证明使用这样的方法必须要有一个在维数的设计上足够好的基础文本特征。
[1] Ronen Feldman,James Sanger.The Text Mining Handbook[M].1st.Beijing:Posts& Telecom Press,2009
[2] 陈文伟.数据仓库与数据挖掘教程[M].第1版.北京:清华大学出版社,2006
[3] Bing Liu.Web Mining[M].1st.Beijing:Tsinghua,2009
[4] 苗夺谦,卫志华.中文文本信息处理的原理与应用[M].第1版.北京:清华大学出版社,2007
[5] 陆旭.文本挖掘中若干关键问题研究[M].第1版.安徽:中国科学技术大学出版社,2008
[6] 宋炜,张铭.语义网简明教程[M].第1版.北京:高等教育出版社,2004
[7] 费小栋,赵克,李亚涛,刘靖.名词聚类在自然语言处理系统中的应用[J].计算机工程与科学,2009,31(8):133-136
[8] 袁正午,李玉森,张雪英.基于属性的文本相似性计算算法改进[J].计算机工程,2009,35 (17):4-6
[9] 董振东,董强.面向信息处理中的词汇语义研究的若干问题[J].语言文字应用,2001,31 (14):27-32
猜你喜欢
数学物理学报(2022年4期)2022-08-22
小哥白尼(趣味科学)(2021年11期)2021-02-28
小天使·一年级语数英综合(2020年10期)2020-12-16
数学物理学报(2020年3期)2020-07-27
数学年刊A辑(中文版)(2018年2期)2019-01-08
中学数学杂志(高中版)(2016年6期)2017-03-01
福建中学数学(2016年7期)2016-12-03
自动化学报(2016年8期)2016-04-16
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
职业技术(2015年8期)2016-01-05
