
ESpin*:基于SPIN 的Eclipse模型检测环境
2013-02-22 08:10黄志球阚双龙
计算机工程与应用 2013年7期
吕 威,黄志球,陈 哲,阚双龙,魏 欧
南京航空航天大学 计算机科学与技术学院,南京210016
1 引言
随着软件在信息化社会中发挥的作用日益重要,人们对软件的正确性、可靠性、安全性等可信性质的要求也越来越高,关键系统中的软件失效不仅会导致生命财产的重大损失,甚至会带来严重的社会问题。对于复杂的并发系统和实时系统,由于系统运行本身存在着不确定性,传统的测试技术并不能充分保证其安全性,这时基于数学公式的形式化验证方法[1]就成为解决此类问题的重要途径。模型检测(Model Checking)[2-3]作为形式化验证的主要方法之一,以其较高的自动化程度,近年来得到了学术界[4-5]和产业界[6-7]的广泛关注。
SPIN[8-9]是由美国贝尔实验室开发的一款著名的分布式系统模型检测工具,目前已经成功应用于协议验证[10]、数据通讯、软件验证及最优规划等领域。尽管SPIN 提供了对其建模语言Promela 的静态语法检查命令,但由于其并没有集成一个高效的开发环境,这种静态检查在复杂模型的建立中,存在明显的滞后性。而且随着SPIN 版本的更迭,其语法检查命令和返回结果的格式发生了巨大变化,使得以往通过调用其自身命令实现的语法错误反馈并不具有版本通用性。
本文通过对SPIN 内核和Promela 文法[9-11]的进一步研究,在Eclispe 平台上设计实现了一个基于SPIN 的易扩展的模型检测环境——ESpin。该环境通过一个优化了的代码分区算法和可迅速支持SPIN 升级的文法分析器,构造了一个高效、易扩充的Promela 编辑器。编辑器除了支持Promela 的全部语法规则外,还提供了包括实时语法反馈、关键字高亮、大纲视图、代码折叠、代码提示、代码补全在内的多种功能,提高了复杂模型的建模效率。此外,ESpin还为用户提供多种运行模式和特有的向导、配置界面,简化了模型检测的操作过程。
2 背景
2.1 SPIN 和Promela 建模语言
SPIN(Simple Promela Interpreter)[9]是美国贝尔实验室开发的经典分布式系统模型检测工具。它以进程为建模单位,通过进程异步组合和系统空间穷举验证等方式,模拟系统运行,验证系统是否满足指定的时序逻辑(LTL)和属性规约,并在不满足时输出错误轨迹,对错误进行定位。
Promela(Process or Protocol Meta Language)作 为SPIN 的采用的形式化建模语言,用来描述待测系统中各组件的自动机模型。完整的Promela 模型由进程、消息通道和变量组成[9],其中进程刻画系统中并发实体的行为,消息通道和变量用来定义进程运行的环境。
2.2 Antlr和GNU Bison 工具
Antlr(Another Tool for Language Recognition)[12]是LL(k)文法的语法分析器生成器,通过让用户自定义词法分析器和语法分析器的规则,生成相应的词法分析器和语法分析器的程序。它为Java、C++、C#等语言提供了一个通过语法描述来自动构造自定义语言的识别器、编译器和解释器的框架。
GNU Bison(简称Bison)[13]是属于GNU 项目的一个通用文法分析器生成器,它能够将一个LALR(1)上下文无关文法的描述,转换为一个可用做文法分析的C、C++或Java 解析器程序。在新版本中,Bison 还增加了对GLR(Generalized Left-to-right Rightmost)语法分析算法的支持。
由于Promela 语言在SPIN 的文法定义文件中被描述成LALR(1)文法,为了使构造的文法分析器与SPIN 的描述严格一致,并且可随着SPIN 的升级快速扩充,选用Bison为编辑器构造文法分析器。在词法分析时,因常与Bison搭配使用的Flex 工具[13]不支持Java 语言的输出,选用Antlr为其构造相应的词法分析器。这样经过词法分析和文法分析,文本中原本毫无意义的字符流就被整理构造成程序对应的符号表和抽象语法树,用以实现实时语法反馈和代码提示补全等功能。Promela 文法分析器的构造过程将在4.2 节详细描述。
2.3 相关工作
SPIN 作为一款著名的模型检测工具,在学术界[14-15]和产业界[16-17]都得到了广泛的应用,针对其的平台扩展、工具扩展和功能扩展等的研究工作也一直在进行。2005 年德国的Gerrit Rothmaier 团队首次实现了SPIN 工具在Eclipse平台的扩展[18];2009 年马里博尔大学的Tim Kovše 团队在Eclipse 平台上实现了SPIN 与st2msc(Spin Trail to Message Sequence Chart)的结合[19]。在后者的实现中,用户通过手动调用SPIN 的语法检查命令,解析返回的字符串,来判断建立的Promela模型是否存在语法错误。
这些工作存在着两个重要缺陷:(1)由于模型的复杂性,手动的语法检查不能及时地反馈出语法错误,存在明显的滞后性,为复杂模型的建立增加了难度;(2)随着SPIN版本的更迭,自身命令返回的语法检查结果在格式上发生了巨大变化,工具[19]在使用最新版本的SPIN 时,不仅不能正确标记出模型中语法错误的位置,反而会导致Eclipse 平台的崩溃。
为了避免类似问题,在ESpin 环境的设计实现中,为编辑器构造了一个通用的代码分区算法,用来提高文本样式化的效率,并依据SPIN 中对Promela 文法的定义[9],构造了一个可随SPIN 升级快速扩充的文法分析器,消除了SPIN版本变化对环境造成的影响。同时利用文法分析产生的符号表和抽象语法树,实现了实时的语法反馈和更为精确的代码提示补全等功能。
3 ESpin 模型检测环境
3.1 设计思想
Eclipse 平台[20]是开放的富客户端开发平台,它的所有功能集成都以扩展点的形式存在。在其标准API[21]的基础上实现了其对SPIN 工具的支持,提供了包括Promela 编辑器在内的一整套模型检测环境——ESpin。
在ESpin 环境中,对Eclipse 平台现有的10 个扩展点进行了扩充,以适应模型检测工作的需要,提供了Promela 语言的建模环境,以及SPIN 的配置、运行、模拟、验证等基本操作。为了降低功能模块之间的耦合性,将ESpin 环境主体划分为4 部分:(1)外部数据导入模块;(2)Promela 编辑器模块;(3)可视效果优化模块;(4)模型检测运行模块。每个模块依据其功能特性选择不同的扩展点进行扩展,具体划分如图1 所示。
为了增强环境的扩展性,降低不同检测工具对整体环境的影响,为ESpin构建了一个特殊的即插即用(Plug-and-Play)架构。在这种架构下,检测工具与其建模语言的编辑器被直接关联起来,作为一个可插拔的部分集成到环境中,而与环境的其他特性相对分离。当需要在环境中使用其他检测工具(如SMV)时,只要提供其对应建模语言的编辑器,便可在现有环境基础上,通过挂载的方式,轻松实现对其他工具的支持(如图2 所示)。这种即插即用的架构,降低了环境对SPIN 的依赖,使其不局限于单一工具,因而具有较强的扩展能力,有助其成为Eclipse 平台下通用的模型检测环境。
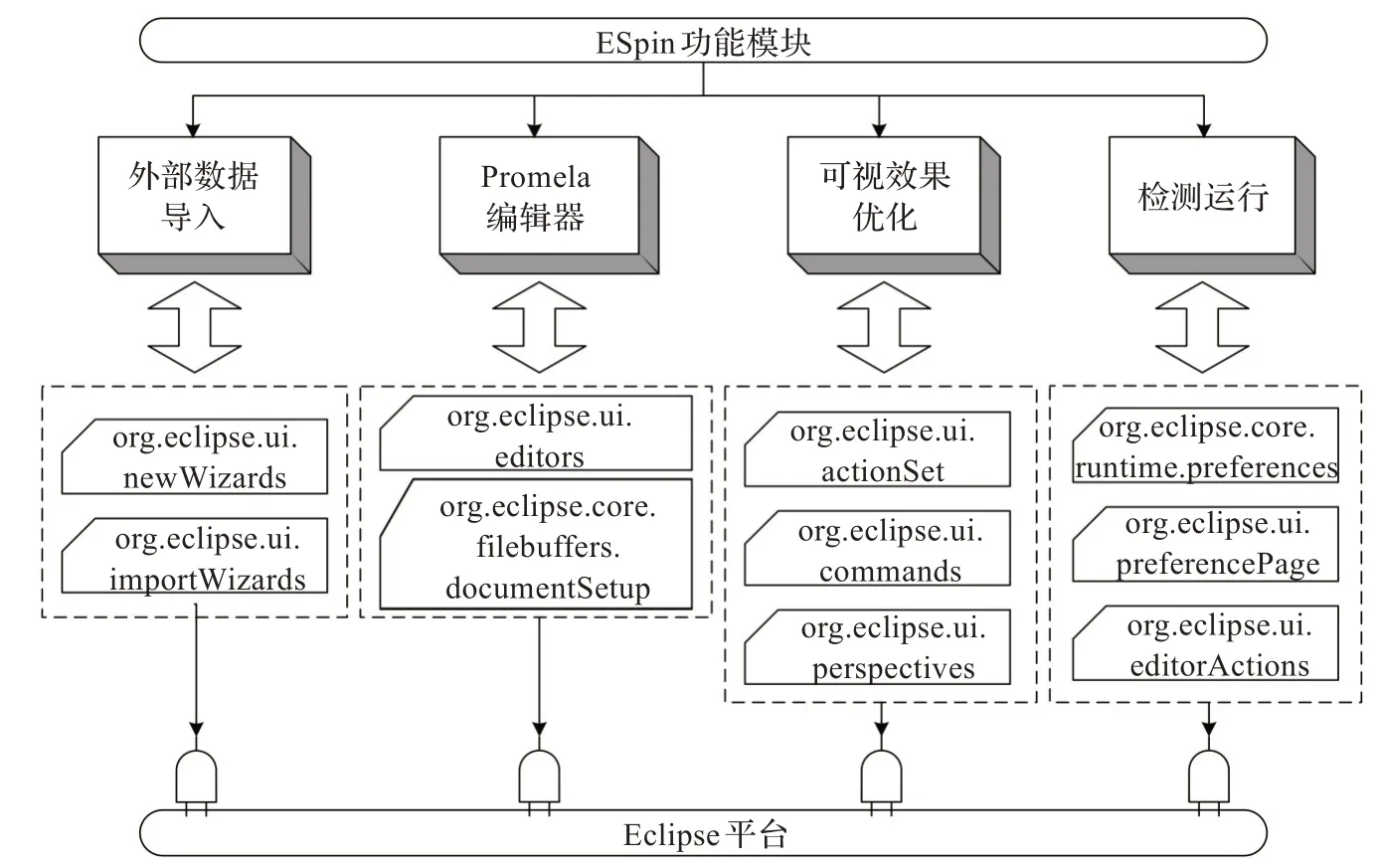
图1 ESpin 功能模块与扩展点图
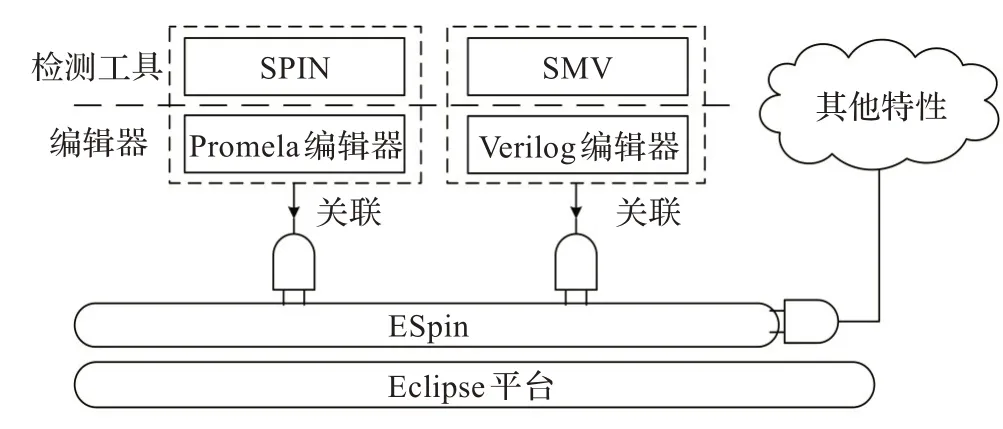
图2 ESpin 的即插即用架构图
3.2 主要特性
正如前文所述,在Eclipse 平台上实现的ESpin 模型检测环境,主要包含以下7 个方面的特性:
(1)支持检测工具和编辑器的快速扩展;
(2)不受SPIN 升级的影响,可随其升级快速扩充,迅速实现向上兼容;
(3)支持Promela语言(6.0 版本)的全部语法和关键字,包括模型内部的LTL 公式等特征;
(4)编辑器能实时反馈模型中的语法和语义错误,并准确标记出错误存在的位置;
(5)支持关键字高亮,大纲视图,代码折叠,代码提示,代码补全;
(6)提供了SPIN 的运行、验证接口和另外两种简捷的运行模式;
(7)设计了一套ESpin 工程特有的透视图和配置页面,新增了ESpin 工程和Promela文件的新建、导入向导。
在ESpin 环境中,用户可以直接调用SPIN 的模拟和验证功能,运行的结果将在Eclipse 控制台打印出来。除常规模式之外,还提供了两种更为简捷的运行模式——运行(Run)和复杂运行(Verbose Run),使初学者也可以轻松使用,而不需要繁琐的设置。当然,同样允许SPIN 的资深用户,在环境的配置页面对其模拟和验证的各项参数进行精确的设置,更加高效地进行模型的检测工作。为了简化环境的设置过程,ESpin 还允许用户自由地导入和导出自己的配置,以便在不同的主机上使用。ESpin 环境主要界面如图3 所示。
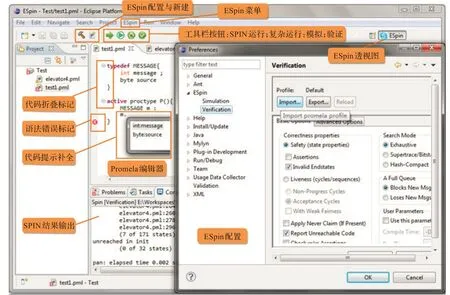
图3 ESpin 环境主要界面图
4 Promela 编辑器
在模型检测的过程中,大量工作都围绕着抽象的系统模型展开,一个功能全面、界面友好的编辑器能够大大提高用户的建模效率,使之更加专注于检测本身。尽管之前的工作都提供了各自的Promela 编辑器,但是由于实现方式的原因,其文本的样式化和语法错误的反馈都存在明显的滞后性,不能满足复杂模型的建模需要。而且随着SPIN的升级,利用其自身命令实现语法反馈的工具[19]甚至会导致Eclipse平台的崩溃。
为了避免类似问题,实现更加高效准确的代码样式化和语法反馈等功能,在Promela 编辑器的构建中,设计实现了一个通用的代码分区算法和一个可随SPIN 升级快速扩充的文法分析器,有效消除了SPIN版本变化对ESpin环境的影响。本章将对该代码分区算法和Promela文法分析器进行详细介绍,并就功能和效率方面与同类工作进行细致比较。
4.1 通用的代码分区算法
对任何编辑器来说,都希望它能根据代码的结构对文本进行必要的修饰,快速标记出关键字和注释等不同类型的内容。为实现这一过程,过去的工具往往都采用了重复扫描的方法:在输入事件发生时,立即扫描整个文本,记录全部关键字的位置,再用状态机排除位于注释和单双引号内的关键字,最后得到需要样式化的部分。这种重复扫描的方式,虽然很容易理解和实现,但是当模型较为复杂以及代码长度较大时,其处理速度必然会随之降低。而且由于对编辑器的输入大多都在文档的尾部连续进行,这种“先挑后拣”的策略本身就会造成大量的重复操作,降低了样式化的效率。
为了解决此类问题,为编辑器设计了一个通用的代码分区算法。该算法不仅适用于Promela 编辑器,而且可以在大多数同类编辑器中使用。为了更清晰地描述算法过程,首先需要对用到的名词概念进行必要的说明。
(1)字符组(Token):用来存储域和单词符号的数据结构,包含所存字符串的内容、类型,以及在编辑器中的位置等信息。
(2)文档(Document):编辑器中文本的全部内容,本质上是一个字符串。
(3)域(Field):由文档分解而成,具有多种类型。文档被完全划分为多个域,这些域互不相交,没有重叠。全部的域构成了整个文档。一个域使用一个字符组存储。
(4)单词符号(Symbol):由域依照扫描规则扫描而得。单词符号可以是单词、数值、符号和空格等。一个单词符号使用一个字符组存储。
(5)扫描规则(Rule):将域分解为单词符号的规则,用来识别域中特定的一组单词或符号。
在构造的代码分区算法中,把域定义为5 种类型:单行注释域(Single-Line-Comments Field)、多行注释域(Multi-Line-Comments Field)、字符域(Char Field)、字符串域(String Field)和代码域(Code Field),用以满足大多数语言样式化的需要。不同类型的域与不同的扫描器(scanner)相互绑定。为了在一次扫描中识别出更多的单词符号,扫描器可以同时拥有多种扫描规则。这些规则包括:单词规则(WordRule)、字符规则(CharRule)、数值规则(NuberRule)和空格规则(WhitespaceRule)等。
具体的算法步骤描述如下:
(1)为对编辑器的操作创建一个编辑器事件(DocumentEvent)并判断其类型,若是打开,转步骤2,若是输入,转步骤3,若是关闭,转步骤9。
(2)启动文档分割器(FastPartitioner)扫描整份文档,将文档分解成多个不同类型的域,返回这些域的字符组(List<Token>),转步骤4。
(3)根据输入的位置,启动文档分割器对输入所在的域和其后所有域进行扫描,更新受到输入影响的域(List<Token>),并将其返回。
(4)查看器(SourceViewer)启动外观协调器(PresentationReconciler)。
(5)外观协调器使用一个状态机,根据域的类型,把得到的字符组分配至对应的扫描器。
(6)扫描器启动扫描线程,依照各自的扫描规则,识别域中的关键字,返回扫描结果即单词符号的字符组(List<Token>)。
(7)启动样式修复器(DefaultDamagerRepairer),为第(6)步产生的字符组按照预设的文本样式(TextPresentation)进行修饰。
(8)修饰完成后,挂起扫描器、样式修复器和外观协调器,等待下一次操作,转步骤1。
(9)释放扫描器、样式修复器和外观协调器,关闭文档。
需要注意的是,在文档分割器分割文档时,会按照其域的类型,将分割结果放入5 个序列(List)。整个样式化流程如图4 所示。
这一算法的优势在于,编辑器只需要在文档打开时对其进行一次完整的扫描,而在之后的输入中,只要重新扫描其中的部分域,就可以实现整个文本样式化的更新。由于大多数情况下,对编辑器的输入都在其末尾连续进行,此时只要对位于文档的最后一个域进行再次扫描,就可以完成样式更新,因此能够大幅提高样式化的效率。而且,对大多数语言来说,只要为其中的代码域设立扫描器,用来区分其中的关键字和其他内容,就可以满足需要,此时当外观协调器发现需要更新的域中没有代码域时,整个过程就可以停止,从一定程度上节省了时间和空间的开销。同时,这种“分而治之”的策略能够完全排除文档中无意义位置(如注释中)关键字的干扰(因为不在同一个域中),也提高了代码样式化的精度。
4.2 Promela 文法分析器
在构造的Promela 编辑器中,仅仅依据代码结构,进行样式上的修饰显然是不够的,尤其是当模型较为复杂时,如果不能根据代码的内容动态反馈出语法方面的错误,建模必将会是个令人头痛的过程。
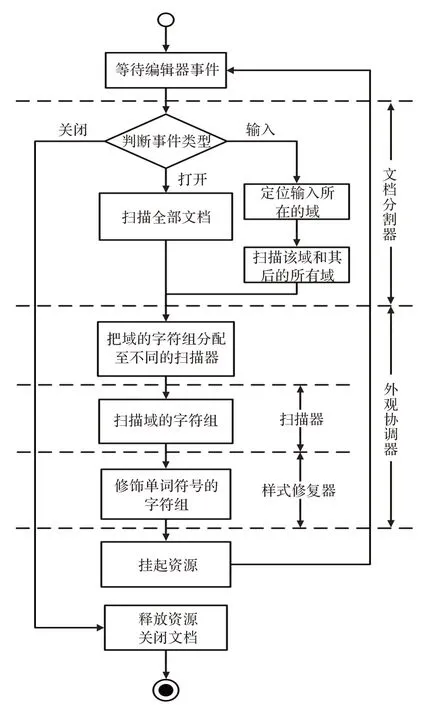
图4 文本样式化流程图
为了使编辑器具有这种能力,以往的工具大都采用了一种投机的方法:当需要检查语法错误时,手动调用SPIN提供的检查命令,并对返回的结果字符串进行解析,把解析得到的出错位置标记在编辑器中。很显然,这种手动调用的方式,存在两个重要缺陷:首先,在实际的建模工作中,手动调用具有明显的滞后性,不能及时地反馈语法错误;其次,随着SPIN 的升级,这种针对字符串的解析并不具有版本通用性。实际上,由于SPIN 版本的变化,工具[19]的字符串解析器不仅不能正确标记出语法错误的位置,反而会导致Eclipse平台的崩溃。
为了在建模过程中能够实时感受到存在的语法错误,并使这种能力不受SPIN 升级的影响,严格依照SPIN 的文法定义文件,为编辑器定制了一个特有的Promela 文法分析器,并依此实现了诸如实时语法反馈、代码提示等功能。
由于Promela 在SPIN 中被描述成LALR(1)文法[9],为了保证与定义的一致性,选用可接受该文法规则的Bison工具为编辑器构造文法分析器(如图5)。与常见的Flex 与Bison 的组合不同,因为Flex 不接受Java 格式的输出,该词法分析器由Antlr 工具构造。这种Antlr 与Bison 的组合可以直接接受SPIN 中的文法定义。在SPIN 升级时,如果Promela 文法没有改变,则编辑器可以直接保证向上兼容,而不需要任何改动;即使Promela 的文法被修改,也只要对文法分析器进行简单的扩充,便能迅速实现对新版本的支持,消除升级带来的影响。

图5 利用Bison 构造文法分析器
由于SPIN 的开发团队在文法定义文件中,不仅规定了Promela 的文法规则,还为其设定了语义动作,因此在构造文法分析器时,需要对其中的动作进行改写,以适应文法分析的需要。图5 是根据SPIN 文法描述构造文法分析器的一段代码,用来接受proctype 的定义。在这段代码的中,Inst、proctype、Opt_priority、Opt_enabler 和body 都是非终结符。NAME、PROCTYPE 和D_PROCTYPE 是由Antlr 定义的token 类型的名称(以标识符命名)。大括号内的语句是改写的文法分析的动作。当前面的语句被识别,动作就被触发执行。在例子程序中,ErrorFind.CheckName 会先将NAME 声明为proctype 类型,然后查询符号表判断该符号是否已经被定义。如果已被定义,则在NAME 处报错;否则把该符号加入到PROCTYPE 类型的符号表中,并将NAME、decl、Opt_enabler 和body 节点添加到proc 节点下(ASTUtil.createNode)。图6 是根据SPIN 的文法定义文件构造的抽象语法树(限于篇幅仅展示部分),图5 的代码段构造了其中虚线围起来的部分(sequence即为body)。
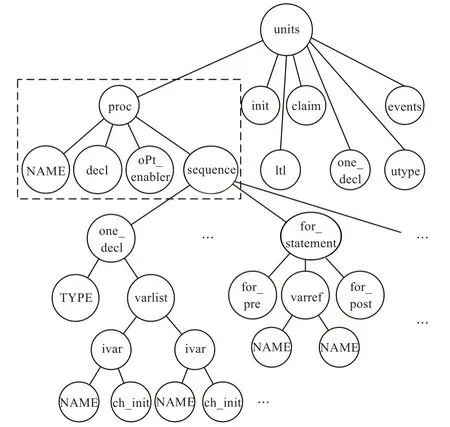
图6 根据定义构造的抽象语法树
实际上,制定的文法分析动作都包含了两方面的内容:一是检查有没有语法错误,二是构造相应的抽象语法树。构造语法树的过程相对简单,只需要建立节点和插入节点。而检查语法错误在不同的场合,则分为两种情况:(1)在变量定义时,需要检查所定义的符号(NAME)在符号表中是否已经存在,如果存在则报错,否则将其添加到所属类型的符号表中;(2)在变量引用时,同样检查所引用的符号在符号表中是否已经存在,不同的是,此时如果符号不存在则报错。为了加快符号表的检索效率,依照符号的类型将符号表分为3 张,分别记录系统类型(PROCTYPE)、自定义类型(USERTYPE)和变量类型(VARIABLE)的符号。因此在检查语法错误前,首先需要记录符号的类型和其他相关信息,然后才在相应的符号表中检索。具体的查错分析流程如图7 所示。
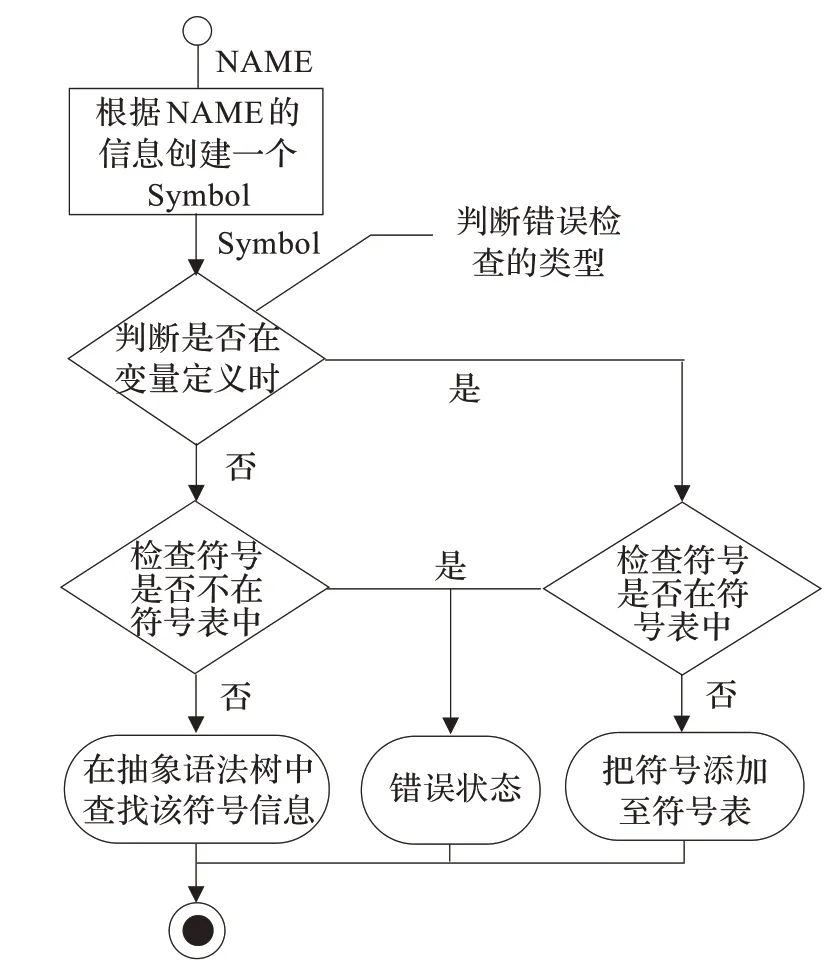
图7 查错分析流程图
至此,经过对Promela 字符流的词法和语法分析,构造出了程序对应的符号表和抽象语法树,编辑器许多基于内容的功能都可以依靠它们得以实现。以代码提示为例,当用户需要提示时,编辑器会解析文档结构,找出需要提示的符号名(如msg),然后在符号表中查找符号的类型(如自定义类型Message),通过对应类型的语法树节点,遍历查找所有的成员变量,生成建议列表并返回至编辑器显示出来。
4.3 与同类工作的比较
在ESpin 模型检测环境的实现中,通过采用上文描述的优化代码分区算法和针对Promela 语言构建的文法分析器,大幅提高了复杂模型代码样式化的效率,更为高效准确地实现了诸如代码提示、代码补全、实时语法反馈等编辑器功能,有效降低了复杂模型的建模难度,提升了建模过程的工作效率。
尽管Eclipse 平台为所有文件类型都提供了默认的文本编辑器,但该编辑器并不提供如样式化、代码提示等附加功能,因此在横向比较中加入了ESpin 与JDT(Eclipse 下Java 开发环境)的比较。在与同类模型检测环境的比较中,选取了功能较为全面的Eclipse Plug-in for Spin and St2msc Tools[14](EPSST),此工具同样基于Eclipse 平台开发,具有更强的可比性。ESpin 环境与原生Eclipse、JDT、EPSST 的功能性比较,如表1 所示。
从表1 可以看出,ESpin 环境由于具备针对Promela 语言的文法分析器,编辑器功能更加全面,针对代码内容的分析更加完善。目前,ESpin 环境支持的实时语法、语义反馈类型包括:(1)不符合文法规范的错误语句;(2)类型引用错误;(3)重复定义;(4)由作用域引起的跨界引用错误;(5)LTL 规约公式错误。在后续版本中,将增加对trace 不唯一,进程数过多等语义错误的实时标记,以及对未被引用变量和不可达程序段等警告类型的动态反馈,继续加强编辑器对Promela语言的支持,优化用户的建模体验。
性能方面,分别对1 000行、5 000行和10 000行的Promela代码(JDT 对应为Java 代码)初次样式化时间和样式化维护时间进行了统计,统计结果如图8所示。结果表明,与EPSST“先挑后拣”的策略相比,ESpin 通过采用优化的代码分区算法,大幅减少了其在样式化维护方面的开销,尤其是当模型规模较大时,这一性能提升十分显著。与JDT 相比,由于ESpin 扫描规则相对简单,且暂未对注释域进行二次扫描,代码规模适中时,性能略好于JDT。值得说明的是,JDT 采用的代码分区算法仅适用于Java 语言,具有很强的语言局限性,与本文描述的通用分区算法有本质区别。原生的Eclipse 平台由于只提供简易的文本编辑器,而不具备代码样式化的功能,此处不参与比较。
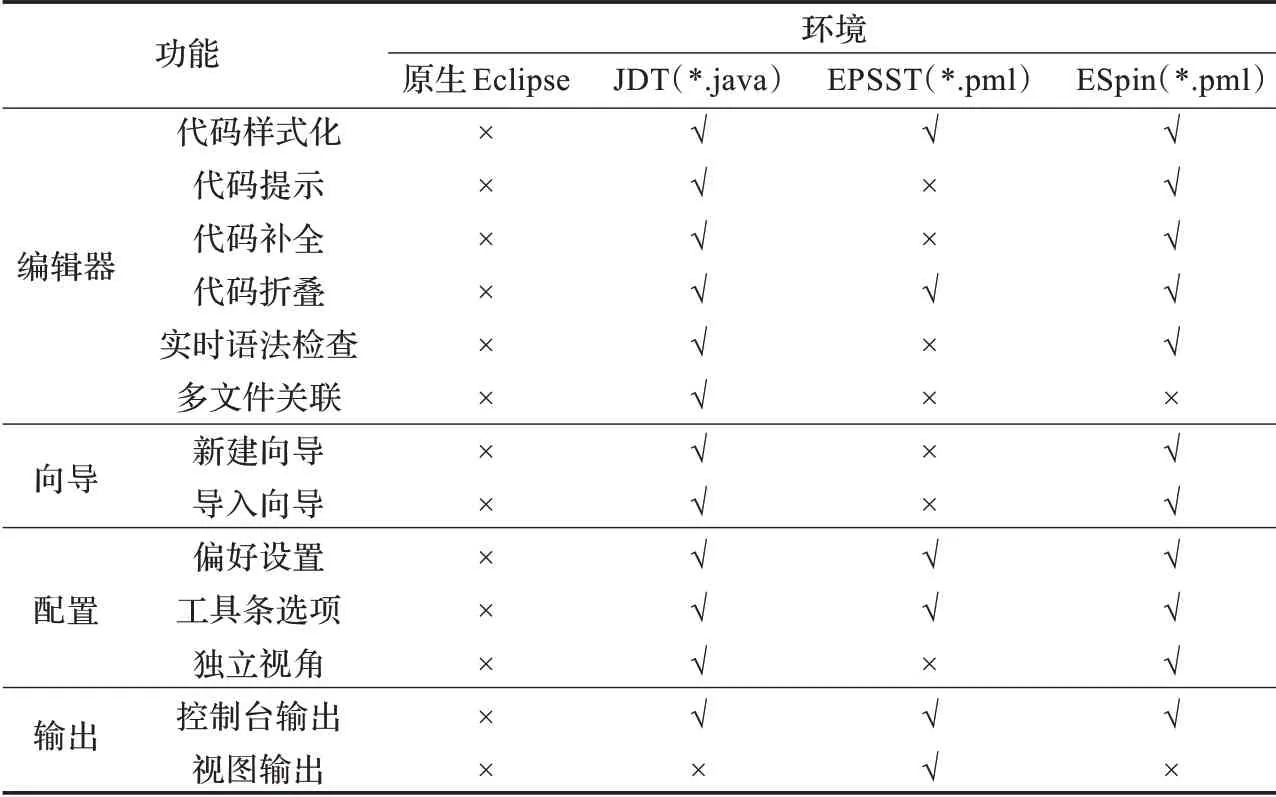
表1 ESpin 环境与原生Eclipse、JDT、EPSST 的功能性比较
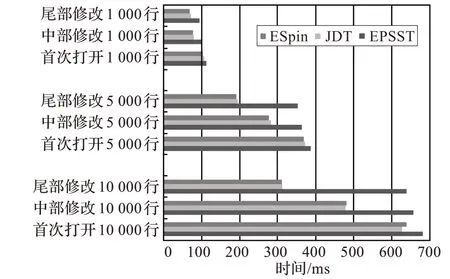
图8 代码样式化时间比较
此外,还在ESpin 环境中测试了在文档尾部输入时其代码样式化与语法检查更新的时间开销,以及总的响应延迟,如图9 所示。结果表明,ESpin 环境完全可以胜任较大规模的复杂模型建模工作。
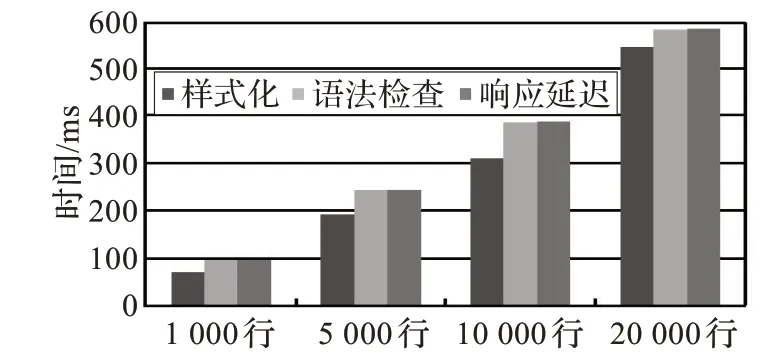
图9 ESpin 代码样式化与语法检查更新效率
5 结束语
本文在Eclipse 平台上设计并实现了一个基于SPIN 的模型检测环境——ESpin。该环境采用独特的“即插即用”架构,提供了一个功能全面、界面友好的Promela 建模和检测环境,提高了复杂模型的建模效率。环境中集成的Promela 编辑器,通过一个优化了的代码分区算法和可随SPIN 升级快速扩充的文法分析器,更为高效准确地实现了包括代码样式化,实时语法反馈,代码提示补全在内的多种功能,消除了SPIN 升级对环境带来的影响。此外,环境还为用户提供了多种运行模式和特有的向导配置页面,使初学者也能轻松使用。
在下一步的工作中,将继续完善编辑器对多Promela文件交互方面的支持,为SPIN 不同的运行模式增加新的图形界面,使用户更加直观地感受运行时的数据交互情况。
致谢感谢南京航空航天大学软件质量保障与测试技术研究生主题创新实验室对本研究课题的大力支持。
[1] Holzmann G.Formal software verification:how close are we?[J].Formal Techniques for Distributed Systems,2010(1).
[2] Merz S.Model checking:a tutorial overview[J].Modeling and Verification of Parallel Processes,2001,2067:3-38.
[3] Jhala R,Majumdar R.Software model checking[J].ACM Computing Surveys(CSUR),2009,41(4).
[4] Chen Z.On the generative power of ω-grammars and ω-automata[J].Fundamenta Informaticae,2011(2):119-145.
[5] Chen Z,Motet G.Nevertrace claims for model checking[C]//Proceedings of the 17th International SPIN Workshop on Model Checking Software,2010:162-179.
[6] Chen Z,Motet G.Methodology and experience for designing safety-related systems in IEC 61508[C]//Proceedings of the 4th Conference on Dependa-Bility,2011:57-64.
[7] Chen Z,Motet G.Towards better support for the evolution of safety requirements via the model monitoring approach[C]//Proceedings of the ACM/IEEE 32nd Conference on Software Engneering(ICSE2010).[S.l.]:IEEE Computer Society Publishers,2010:219-222.
[8] Holzmann G J.The model checker SPIN[J].IEEE Transactions on Software Engineering,1997,23(5):279-295.
[9] Holzmann G J.The SPIN model checker:primer and reference manual[M].[S.l.]:Addison-Wesley,2004.
[10] Chen Z,Zhang D,Zhu R,et al.A review of automated formal verification of ad hoc routing protocols for wireless sensor networks[J].Sensor Letters,2012(12).
[11] Holzmann G J.Promela language reference[J].Bell Labs,1997(5).
[12] Parr T,Lilly J,Wells P,et al.ANTLR reference manual[R].MageLang Institute,2000-01.
[13] Levine J.Flex & bison[M].[S.l.]:O’Reilly Media,Inc,2009.
[14] Jiang K,Jonsson B.Using SPIN to model check concurrent algorithms,using a translation from C to Promela[D].Uppsala,Sweden:Uppsala University,2009.
[15] 徐丙凤,胡军,曹东,等.T-CBESD:一个构件化嵌入式软件设计模型验证工具[J].小型微型计算机系统,2010,31(11).
[16] Havelund K,Lowry M,Penix J.Formal analysis of a space-craft controller using SPIN[J].IEEE Transactions on Software Engineering,2001,27(8):749-765.
[17] De Vries R G,Tretmans J.On-the-fly conformance testing using SPIN[J].International Journal on Software Tools for Technology Transfer(STTT),2000,2(4):382-393.
[18] Rothmaier G,Kneiphoff T,Krumm H.Using Spin and Eclipse for optimized high-level modeling and analysis of computer network attack models[J].Model Checking Software,2005,3639:903-904.
[19] Kovše T,Vlaovič B,Vreže A,et al.Eclipse plug-in for spin and st2msc tools-tool presentation[J].Model Checking Software,2009,5578:143-147.
[20] Clayberg E,Rubel D.Eclipse:building commercial-quality plug-ins(Eclipse)[M].[S.l.]:Addison-Wesley Professional,2006.
[21] Help-Eclipse Platform[EB/OL].[2012-07-01].http://help.eclipse.org/.
猜你喜欢
西部蒙古论坛(2021年4期)2021-03-02
阅读(科学探秘)(2019年6期)2019-10-17
党的生活·党员电教与远程教育(2019年1期)2019-03-06
铁道通信信号(2018年7期)2018-08-29
分析化学(2018年12期)2018-01-22
科技经济市场(2017年5期)2017-09-16
High Technology Letters(2017年2期)2017-06-27
High Technology Letters(2016年3期)2016-12-05
学生天地(2016年26期)2016-06-15
电子设计工程(2015年4期)2015-02-27
