
基于内容的发布/订阅系统的元数据索引和过滤
2013-02-09 08:02李永锋王惠临
计算机工程与设计 2013年9期
李永锋,王惠临
(中国科学技术信息研究所,北京100038)
0 引 言
随着新闻组和RSS等信息聚合的发展,基于内容的发布/订阅系统得到广泛重视,RSS是Web 2.0的重要内容之一,同时也给发布/订阅系统提出了许多挑战。信息资源越来越丰富,而人们所需要信息是有限的,人们接收和处理信息能力也是有限的,导致了发布/订阅范型的产生。这种系统能够很好地支持有选择的消息分发,从海量的信息中,例如时事报道,电子图书,网络广告,股票报价,天气预报消息等等,为用户提供个性化的内容递送。发布/订阅是一种异步的通信范型,用户订阅消息,当有符合条件的消息发布时,系统通知用户。发布订阅平台为新发布的消息寻找相匹配的订阅,然后把该消息转发订阅者。同一用户可以同时是发布者和订阅者。
早期用户通过预先定义好主题发布和订阅事件,NNTP新闻组就是这类基于主题的发布/订阅系统的代表。通过主题来分类事件的方式过于粗糙,用户经常收到冗余的数据,虽然这些数据属于订阅的主题。最新的系统是基于内容的。在基于内容的系统中,用户可以直接对事件的内容形式做限制,从而获取精确的信息。
随着网络资源的迅速增加,人们需要对这些海量的网络资源进行有效地管理。元数据是管理这些资源的有效方法。元数据是 “关于数据的数据”或者 “关于信息的信息”。一个资源的元数据被认为是这个资源的语意。元数据是保证这些资源在未来能够容易被使用的关键。应用最广泛的元数据标准有Dublin Core[2]和 MARC[12]等等。针对元数据的发布/订阅系统为管理各种资源的内容提供有效的能力。例如,在网上书店,一个用户可以通过对电子文档的元数据的限制来订阅电子文档,例如 “title= ‘Green on Greens’&coverage= ‘17thcentury’”,当书店的进货包括这样的文档内容的时候,系统就准确通知用户。
需要注意的是,发布/订阅系统与数据库查询的区别。传统的数据库为这些场景设计的:数据库中已经保存有大量的数据,用户可以通过设置查询条件 (例如用SQL语句)去寻找需要的数据。但是发布/订阅范型刚好反过来,系统中保存的是大量的用户订阅 (类似于查询条件),数据流入系统和订阅相匹配,如果匹配,则通知订阅者。
这篇论文的主要贡献如下:
(1)本文设计了新颖的索引结构对订阅进行分组索引,消除了一个订阅因为包含多个谓词而造成的多次索引、计数和比较。
(2)我们设计了新的基于分组的过滤算法,该算法通过缓存谓词匹配结果使得谓词匹配结果得以在订阅过滤过程中传播,取得了很高的过滤性能。
(3)通过全面的实验,以及对算法详细的空间时间复杂度分析,证明了算法的有效性。实验表明,我们的系统可以有效处理达上百万订阅的工作量。同时,实验中通过提取词干和消除停用词,极大提高系统的查全率和精度。
1 相关工作
早期的发布/订阅系统是基于主题的,广泛应用的有Network News Transfer Protocol[11],IBM 的 MQSeries[4],google 的 google reader[9], 和 Microsoft 的 Biz Talk Server[6]。现在基于主题的发布/订阅系统方面的研究,主要集中在 P2P环境下[8]。
基于内容的发布/订阅系统允许过滤消息内容。基于内容的过滤使用户可以精确表达个性化要求。公开发表的文献中提出了不少关于内容的过滤算法。结合几种数据结构,使用针对应用的缓存,针对应用的查询处理,系统[3]可以达到很高的负载和速度。在文献 [1]中,系统设计用来根据XPath或XQuery表达式去过滤XML文件。XPath可以用来描述一棵树结构的路径模式,但是路径模式不允许进一步用关系算子进行限制,而这个在我们的系统中已经其它非XML系统中是可以做到的。Tai[7]把语意引进了发布/订阅系统。OPS[10]是一个基于本体的发布/订阅系统,系统中的事件和订阅都用RDF图来表示。Keidl[5]提出了一个分布式元数据系统,它是在关系数据库上实现的,但是不能扩展到上百万个订阅的情形或者很高事件吞吐量的情形。
2 数据模型
元数据是机器可以理解的信息。它是 “关于数据的数据”。总的来说,元数据用来描述别的数据的集合,这个集合称为资源。元数据抓住了资源最重要的信息,例如资源怎么收集的和怎么处理的,使得以后的用户能够理解这些细节。从这种意义上说,元数据是保证资源在未来继续存在的关键。元数据很有用。在搜索系统中,元数据使得用户能快速定位自己需要的数据。用元数据的查询可以使用户省去大量人工的复杂的过滤操作。试想这样一个场景,如果没有我们试图在没有书目管理和电脑查询系统辅助的图书馆查找一本书有多困难。在数目和电脑查询系统里面存有的信息本质上就是关于这些书的元数据。在我们的系统中,元数据是作为发布语言。应用最广泛的元数据标准有Dublin Core和MARC。本文实验采用的是Dublin Core标准。
从这些标准中抽象出来,在我们的系统中,一个事件表示为二元组 (域,数据项组)的集合,其中属性有唯一的属性名,数据项组可以有一个或多个数据组成。属性包含三类,一是数值型的,一类是字符型的,一类是分类型的。这里说明一下分类型属性,分类型属性用来描述层次结构,这一点在元数据中很常见。分类的域是枚举类型的,域中的元素被组织成层次结构,例如在一个学校的图书馆,根据主题书籍可以分为哲学,历史,技术等等种类,其中历史又可以分为通用的,欧洲的,亚洲和非洲等等子种类。我们把事件集合中的一个元素叫做一个段。例如,{(Title,“A Guide to Growing Roses”), (description, “Describes process for planting and nurturing different kinds of rose bushes”),(date,“2001—01—20”),(format,“image”)}就是一个简单的事件。其中 (format,“image”)就是一个段。
一个订阅是三元组 (属性,算符,关键字数组)的集合,其中对于值为字符类型的属性来说,算符只有,表示包含,对于值为数值型的属性,算符可以为<,>及=,表示通常意义下的数学关系语意。在现实应用中,订阅的三元组集合的大小不会超过5。和搜索系统类似的,订阅是用来限制事件的各个属性及其取值。例如, (title,,“Harry Potter”)∧ (year,>,2000)就是一个常见的订阅。在以下,我们把订阅中的一个三元组叫做一个谓词。
为了确定事件和订阅之间的关系,我们给出以下定义:
谓词匹配:给定一个谓词p= (attributei,opi,valuei)和一个段s= (attributej,setjof values),s匹配p当且仅当①attributei=attributej,并且②对于valuei,s中存在valuej∈setjof values,使得valuejopivaluei成立。
例1:段 (year,2006)满足谓词 (year,>,2000)。因为 “year”= “year”并且2006>2000。
订阅匹配:给定一个订阅s=p1∧p2∧……∧pn,和一个事件e= {seg1,seg2,……,segm},e匹配s当且仅当对于s中的任意pi,e中存在segj使得segj满足pi。
例2:事件 {(Title,“Harry Potter and the chamber of secrets”),(year,2006), (creator, “J.K.ROWLING”)}匹配订阅 (title,contains,“Potter”)∧ (year,>,2000)。
3 过滤算法
在发布/订阅系统中,核心的一个问题就是如何有效的把数据流和订阅匹配。这个问题定义如下:
过滤过程:给定订阅集合D= {s1,s2,……,sn},当一个元数据e流入的时候,返回匹配的订阅集合Ds={si|e满足si,si∈D}。
3.1 未分组过滤算法
为了找到所有符合的订阅,最直观的方法是每到一个事件,把它和系统中的每个用户订阅进行比较。这种方法在订阅数量很大的时候,开销是很大的。最坏的情况,这种算法的时间复杂度为其中Cp代表匹配一个谓词的时间开销。这种方法并没有考虑系统中订阅的谓词间的依存关系。例如,如果1000个订阅都包含有一个相同的谓词,这个系统并不知道这个信息,所以对这个谓词将评估1000次。
所以,应该把订阅中相同的谓词考虑进去。我们把各个不同谓词作为订阅的索引。当系统中含相同谓词的订阅很多的时候,这个方法可以节省大量的比较时间,因为它避免了对一个相同谓词的重复评估。我们把这个方法叫做未分组过滤算法。下面我们用e代表新来的一个事件。用matchingPred保存和事件e相匹配的谓词。用matching-Subs保存和e相匹配的订阅。下面描述这个算法,以便和我们后面的算法对比。
未分组过滤算法:match(e)
输入:事件e= {(attribute1,set1of values),…… ,(attributen,setnof values)}
输出:候选匹配订阅集合matchingSubs
(1)matchingPred←
(2)matchingSubs←
(3)循环 对每个属性attributei∈e
(4) 循环 对每个值v∈setiof values
(5) matchingPreds← matchingPreds+ Pi.search (v)
(6)循环 对于每个p∈matchingPreds
(7) 循环对于每个s∈pred_to_subs[p]
(8) s.count+ +
(9)循环 对于系统中的每个s
(10) 如果s.count==s.nb_pred则 matching Subs←matchingSubs∪ {s}
(11)返回matchingSubs
未分组过滤算法可以大概分为两步。第一步,算法从索引结构中查找所有和事件e匹配的谓词。第二步对和这些匹配的谓词相关的订阅进行验证。时间开销也分为谓词匹配时间和订阅匹配时间两部分组成。算法的时间复杂度其中Csearch在索引中找一个关键词的平均时间代表事件中属性的总个数,Nval代表事件中单个属性关键字的平均个数,Cadd是作一次加法计数的开销,Psat是和事件e相匹配的谓词的集合,Np是每个订阅满足要求的谓词的平均数目,Ccomp是比较一次的时间,而代表系统中订阅的总数。
未分组过滤算法的空间开销主要有索引,指针链表和订阅。诸如Trie,AVL和B树等索引结构的空间复杂度不会超过系统中不同谓词的数目。索引结构中的指针链表的大小和谓词的总数相等。而且,每个订阅只在一个地方存放。所以空间复杂度是和系统中谓词的数量成正比的。
3.2 基于分组的传播过滤算法
相对于直观的方法,未分组过滤算法取得了很大的进步。但是我们进一步分析可以发现,过滤时间的很大一部分是消耗在对谓词的计数上了。我们可以通过限制需要验证的订阅的数目来减少这个时间。我们其实不必要对订阅中的每个谓词都索引,我们只需在每个订阅中选择其中一个最不常用的谓词对订阅进行分组索引。只有该谓词符合新来的发布事件的时候,这个订阅的其它谓词才需要被进一步验证。索引结构如图1所示。为了加快剩余谓词的验证速度,我们为新来的事件建立一个谓词匹配结果位串,用来记录谓词的验证结果,每个谓词对应其中的一位,以下用pred_map标识。初始时,所有pred_map位为0,当有新事件流入的时候,匹配好的谓词对应在pred_map中的位置1,其它为0。在验证整个订阅到时候,我们通过pred_to_group,从pred_map为1的单元反向找到订阅,这个谓词是已经被验证过的,这些订阅可能和事件相匹配。这些订阅根据谓词的数目进行分组,以加快匹配速度,同一组的订阅具有相同数目的谓词。
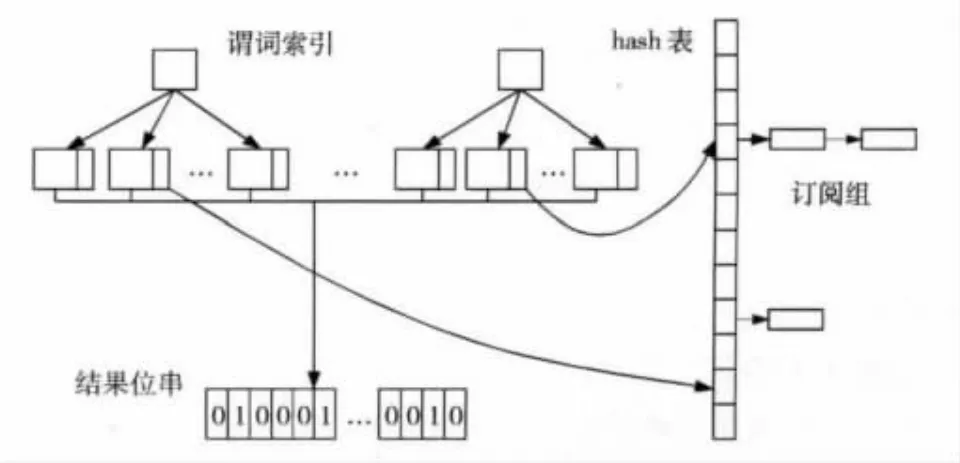
图1 基于分组的订阅索引结构
基于分组的传播过滤算法match(e):
输入:事件e= {(attribute1,set1of values),……,(attributen,setnof values)}
输出:候选匹配订阅集合matchingSubs
(1)matchingPred←
(2)matchingSubs←
(3)循环 对每个属性attributei∈e
(4) 循环 对每个值v∈setiof values
(5) matchingPreds← matchingPreds+Pi.search (v)
(6)循环 对于系统中的每个谓词p
(7) 如果p∈matchingPreds则pred_map[p]=1否则pred_map[p]=0
(8)循环 对于每个p∈matchingPreds
(9) 循环 对每个家族fi∈pred_to_group[p]
(10) 循环j=1 to i
(11) buf←
(12) 循环 对于每个s∈fi
(13) 如果pred_map [s.predj]==1则buf←buf∪s
(14) fi←buf
(15) matchingSubs←matchingSubs+fi
(16)返回matchingSubs
基于分组的传播过滤算法包括谓词验证和订阅匹配。算法的时间复杂度为Nval+CreadbPsatNsv),其中Csearch代表在索引结构中查询一个关键字的平均时间开销,是事件中属性的总数,Nval代表事件中每个属性关键字的平均数目,Csetb代表在pred_map设置一个标志位的时间,Creadb是验证pred_map一位的时间,Psat是和事件匹配的所有谓词,Nsv是在比较中验证的平均谓词数目。
基于分组的传播过滤算法的空间开销主要有索引结构,指针链表和订阅几部分所组成。诸如Trie,AVL,B+树的索引结构空间开销都不会超过系统中不同谓词的总数。对比未分组过滤算法,指针链表的大小和系统中订阅的数量相同,而未分组过滤算法和系统中谓词的总数相同。pred_map的大小是和系统中不同谓词的数目一样多的。而且,每个订阅只需要一个存储单元,所以整个系统的空间复杂度和系统中谓词的大小成正比。
3.3 提取词干和消除停用词
元数据经常包含自然语言来描述资源。例如,Dublin Core元数据标准推荐了15域用来描述一个资源,MARC也包含了诸多域表示资源的不同属性例如作者,出版信息等。经常出现这种情况,用户订阅中出现一个词,但是在事件中没有这个词,而是这个词的其它形式。比如说英文里面的复数,动名词,过去式都是语法变化的例子,这些变化阻碍了订阅和事件之间的匹配。为了部分解决这个问题,我们用这些词的词干来代替这些词,词干就是消除这些词的前后词缀后留下的部分。例如cook就是一个词干,它从cooker,cooking,cooked,和cooks中提取出来。词干提取对于提高过滤算法的性能是有好处的,因为它们把一个词的多种形式合为一个。而且,提取词干可以减少索引结构的差距,因为有相同词干的词被一个词干所代表了。提取词干可以大大提高系统的查全率。
我们注意到,在订阅和事件中太常出现的词,往往没有什么区分度。事实上,如果一个词在80%以上的订阅和事件中出现的话,它对于过滤是没有用的。这样的词叫停用词。我们不把停用词当作索引关键字。比如说汉语中的“的”,“了”,“是”等等,英语中的冠词,介词以及连词都是停用词的候选。消除停用词可以减少索引结构的大小,而不影响过滤精度。
我们对词干的提取和停用词的消除是在一个新的事件发布或者一个新的订阅进入系统的时候进行的。在基于分组的传播过滤算法中,提取词干和消除停用词会影响pred_map数组,因为订阅中的词变化的时候,必然引起谓词的变化。
提取词干算法:stemming(e)
输入:一个订阅s或者一个事件e
输出:s或者e的词干
(1)循环 对每个itemi∈s或者e
(2) 如果itemi是字符型属性的值
(3) 则用取itemi的词干代替它
(4)返回s或者e的词干
消除停用词算法:stopper(e)
输入:一个订阅s或者一个事件e
输出:s或者e的词干
(1)循环 对每个itemi∈s或者e
(2) 如果itemi是字符型属性的值并且itemi是个停用词
(3) 则从e或者s中删除itemi
(4)返回不再有停用词的s或者e
4 实验评估
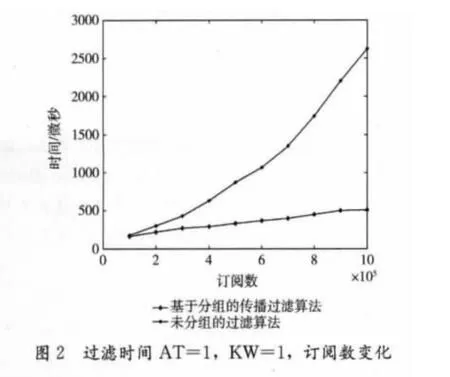
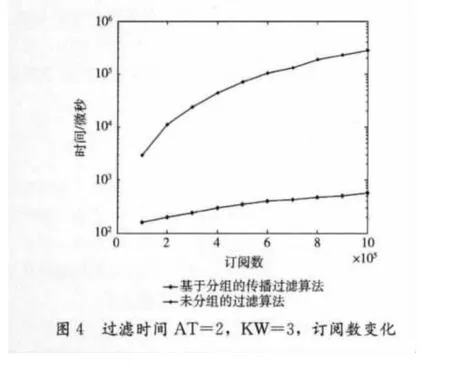
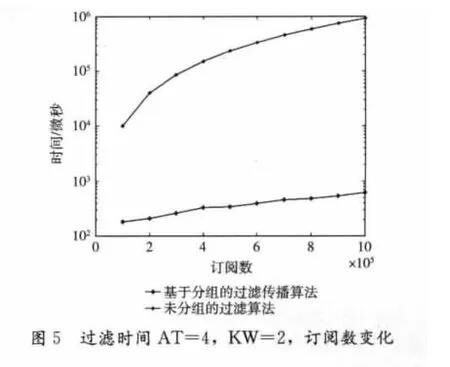
在这一节,我们通过实验验证算法的性能。我们的实验是在一个单CPU的PC上进行的,CPU是频率为3.2GHz的Xeon芯片,内存为4G,操作系统是Redhat Linux AS 4.0。未分组的过滤系统和基于分组的传播系统都是用c++语言在visual studio 2005环境下开发的。在以下我们对实验的主要参数做一些规定,我们用AT表示订阅中属性的平均个数,用KW表示属性中关键字的平均个数。实验中的事件是以Dublin Core元数据标准生成的,每个元数据有15个基本元素构成。在下面的图形中,过滤时间是指过滤1000个事件的总时间,时间单位是微秒。实验最大订阅数为100万。
图2到图5表明在参数AT和KW设置到不同时,工作负载从10万增加到100万时,过滤算法的时间开销。不难看出,两个算法都深受订阅数目的影响,同时AT和KW对算法的影响是很明显的。但是,未分组过滤算法对工作负载的敏感度大于基于分组的传播过滤算法。基于分组的传播过滤算法对于订阅数目的增加,过滤时间基本上能保持线性增长,而未分组过滤算法却几乎成指数增长,当订阅数达到50万时候,未分组过滤算法的性能开始急剧下降,而基于分组的传播过滤算法还能保持线性增长水平。当系统中有100万个订阅,AT=4且KW=2时,基于分组的传播过滤算法平均每秒钟处理1621个事件,而未分组过滤算法平均仅仅能够处理1.1个事件。图6和图7主要对比在引进词干提取和取消停用词和不引进之间的性能差。词干提取和取消停用词技术不但能够提高过滤算法的查全率和精度,而且从图6和图7看来,它们无论对未分组过滤算法还是基于分组的传播过滤算法的过滤器,性能的影响是很小的。

5 结束语
本文我们提出了基于内容的元数据过滤算法。基于分组的传播过滤算法可以有效处理订阅达百万的工作负载。实验表明,当订阅量超过10000,基于分组的传播过滤算法性能明显超过未分组过滤算法。词干提取和取消停用词对算法的性能是很小的。但是这些技术的引进对于提高系统的查全率和查准率却有很大的帮助。

在未来,我们计划把算法扩展到集群 (cluster of workstation)上,研究并行环境下系统性能的加速度。
[1]Yanlei Diao.Query processing for large—scale XML message brokering[D].Doctor Dissertation,2005.
[2]The Dublin Core.The dublin core metadata initiative [DB/OL].[2012—12—02].http://dublincore.org.
[3]Francoise Fabret,Arno Jacobsen H,Franqois Llirbat,et al.Filtering algorithms and implementation for very fast publish/subscribe systems[C]//Santa Barbara,California,USA:SIGMOD,2001.
[4]IBM,WebSphere MQ FAQ forum [DB/OL]. [2012—10—14].http://www.mqseries.net/.
[5]Markus Keidl.A publish and subscribe architecture for distributed metadata management [C]//San Jose,CA:IEEE Computer Society ECDE,2006:309.
[6]Microsoft Corporation.Biz Talk server [DB/OL]. [2012—11—04].http://www.microsoft.com/biztalk.
[7]Wei Tai,OSullivan D,Keeney J.Distributed fault correlation scheme using a semantic publish/subscribe system [C]//Salvador,Bahia,Brazil:Network Operations and Management Symposium,2008:835—838.
[8]Tova Milo,Tal Zur.Elad Verbin:Boosting topic—based publish—subscribe systems with dynamic clustering [C]//Beijing,China:SIGMOD Conference,2007:749—760.
[9]Google.Google reader [DB/OL] .[2012—12—02].http://www.google.com/reader/view/.
[10]Wang Jinling,Jin Beihong,Li Jing.An ontology—based publish/subscribe system [C]//Grenoble,France: Middleware,2005:232—253.
[11]W3C,Network news transfer protocol[DB/OL].[2012—11—10].http://www.w3.org/Protocols/rfc977/rfc977.
[12] MARC, MARC proposals [DB/OL] .[2012—12—03].http://www.loc.gov/marc/.
猜你喜欢
中华诗词(2022年2期)2022-12-31
新世纪智能(高一语文)(2021年11期)2021-03-08
——论胡好对逻辑谓词的误读
现代哲学(2020年5期)2020-11-30
西夏研究(2020年2期)2020-06-01
现代哲学(2019年4期)2019-12-14
小学生学习指导(低年级)(2019年3期)2019-04-22
小学生学习指导(低年级)(2018年9期)2018-09-26
小学生作文(低年级适用)(2017年3期)2017-07-06
小学生导刊(低年级)(2017年1期)2017-06-12
太原城市职业技术学院学报(2014年9期)2014-02-27

- 计算机工程与设计的其它文章
- 应用标签域的贝叶斯网络图像分割算法
- 基于概念漂移检测算法的数据流分类模型