
英语实词动态增长与重复分析
2013-01-31 05:01赵小东胡赛儿
大连海事大学学报(社会科学版) 2013年4期
赵小东,胡赛儿
(大连海事大学 外国语学院,辽宁 大连 116026)
国内外许多学者,如Baayen[1]、Brunet[2]、Fan[3-5]、Tuldava[6]等都研究过词汇量与篇章长度的关系。他们或设计不同的量化模型来描述词汇量与语篇长度的关系,或运用不同的语言数据去验证这些模型。也有学者对实词进行了研究,如Francis等[7]、Johansson 等[8]通过计算LLC、Brown 和LOB语料库中的实词比率对实词进行了静态的分析。对词汇重复率的研究主要为国内学者,如Fan[4-5]、罗卫华等[9-10]。但目前却没有对各类实词的动态的词汇量与篇章长度关系的研究。因此本文拟利用计量的方法,对普通英语和科技英语中的实词按4000词切分,对其进行词汇增长的动态分析,对比研究两个语料库中实词的词汇增长、词汇重复情况。
一、基本定义
本文中实词包括名词、动词、形容词和副词。对介词、连词、冠词、代词等虚词不作研究,这是因为英语中虚词总量非常有限,增长模式不明显。实词词汇增长是通过各实词词类的累积类符数除以该词类的累积形符数计算的。
许多语言学家都注意到类符/形符比(Type/Token Ratio,简称TTR)跟形符总数的关系。而且类符/形符比还通常用来测算词汇多样性(lexical variation 或lexical diversity)[11-12]。但计算TTR 的方法不尽相同。本文采用公式“TTR =各词类累积类符数/各词类累积形符数”来计算随着英语篇章长度,即累积形符数(4000)的增加,普通英语和科技英语的各类实词TTR 的变化规律;各类实词标准类符/形符比采用每4000 词(形符数)的TTR:每4000 词时各类实词的类符数除以4000。
本研究中,英语单词的形符包括以空格断开的英文单词、字母、缩略等,但不包括标点符号。形符数也称词次。总词数即总词次。类符指单词的词元(lemma)形式,即把词类相同、意义相同,但词尾变化不同的词归纳为同一词元。如think、thinks、thought 和thinking 统一归并为一个词元think。本文中的词汇即为词元或类符,词汇数或词汇量即为词元数或类符数。归并词元时,剔除标点符号、阿拉伯数字以及其他各种非字母字符。
二、研究设计
本文中科技英语语料采用JDEST 语料库,JDEST 为上海交通大学建立的国内权威科技英语语料库,总容量为1 079 649;普通英语语料采用BNC(英国国家语料库)的笔语部分抽样。在对BNC 进行抽样时,先运用FoxPro 程序将BNC 笔语语料库的所有赋码文本(tagged texts)中的标注码去掉。然后运用另一FoxPro 程序从BNC 笔语库中随机抽取28个文本,总词次为1 136 347。以下将此抽样文本称为SBNC。接着运用CLAWS4 对JDEST 和SBNC 两个语料库进行词类(POS)标注。然后运用另一FoxPro程序对两个语料库进行分词处理,并根据POS 赋码,即以N(名词)、V(动词)、J(形容词)和R(副词)开头的标注码,提取各类实词。接着将各类实词中的词类标注、标点符号、特殊符号以及其他非字母字符去除。
然后再运用两个FoxPro 程序分别处理经过分词处理的SBNC 和JDEST 语料库。这两个程序分别将SBNC 随机分为284个4000 词(形符)的文本块(chunks),共113 600 词次;JDEST 分为247个4000词的文本块,共988 000 词次。由于Biber[13]认为2000 至5000 词的抽样文本(text samples)足以代表文本范畴(text categories),因此本文按4000 词对SBNC 和JDEST 进行切分。接着,程序会分别计算出各语料库的每4000 词文本块的各类实词类符数以及随着两个语料库按4000 词(形符)增长时累积形符总数、累积各类实词类符数、累积各类实词形符数、各类实词的TTR 及各类实词的累积重复数、累积重复率等。
其中,累积各类实词类符数即各类实词的累积词汇量。下面以名词为例说明累积实词重复数及重复率的计算。累积名词重复数的计算公式为:累积名词重复数=累积名词数-累积名词量。公式中累积名词数为各4000 词的文本块的名词类符数,即名词词汇数之和。比如科技英语JDEST 语料中前两个4000 词文本块各自名词词汇数为760 和767,则累积名词数为1527。但如果将这两个文本块相加,变为8000 词,这两个文本块的名词词汇数760 和767中就会有重复的名词,将重复的名词合并,这样就可计算出累积名词量,为1221。因此,JDEST 中前两个文本块的累积名词重复数为1527-1221 =306,名词累积重复率为0.1268。而第一个文本块的名词重复数和重复率都为0。表1为JDEST 语料库中名词部分数据。

表1 JDEST 语料库中累计词次32 000 词前名词部分数据
表1中,t_cu 表示累积形符总数(累计词次),n_type 为每4000 词中名词类符数,n_cu 为累积名词类符数(累积名词量),n_cutok 为累积名词形符数,n_ttr 为名词类符/形符比,n_curep 为累积名词重复数,n_cureprate 为名词累积重复率。
三、结果分析
1.实词增长分析
结果显示:284个SBNC 文本块的名词、动词、形容词和副词累积词汇量分别为24 440、4601、9050和1632;247个JDEST 文本块的各类实词累积词汇量依次为14 754、3481、8961 和1152。SBNC 的284个文本块各实词的平均词汇量依次为851、284、245、118,JDEST 的247个文本块各实词平均词汇量依次为756、250、292、110。表明普通英语各文本块的名词、动词和副词词汇量大于科技英语。普通英语的累积形容词词汇量在第247个文本块时为8441,形容词总词量小于科技英语,而且普通英语各文本块的平均形容词词汇量245 也远小于科技英语各文本块的平均形容词词汇量292。观察科技英语语料库发现,除少量常用形容词外,如other、high、large、small 等,其中有大量的科技方面的形容词,用于正式或客观的学术表达,描写事物的特征,如magnetic(475)、hermal(406)、nuclear(375)、chemical(356)、conventional(331)、mechanical(314)、electric(297)、vertical(216)等。图1为SBNC 和JDEST实词增长曲线。
图1显示,在SBNC 和JDEST 中,四种实词的累积词汇量呈类似增长态势:开始都急剧增长,随后变缓。只是名词累积词汇量增长得最快、最急剧;形容词次之;动词的累积词汇量增长幅度位于第三;副词累积词汇量的增长最不明显,其增长曲线几乎与x轴平行。同时,图1表明两个语料库中,词汇量大多集中于名词,然后是形容词、动词和副词。
2.实词TTR 分析
程序运行结果显示SBNC 的名词、动词、形容词和副词的平均标准TTR 依次为0.2128、0.0709、0.0613和0.0296,JDEST 的各类实词平均标准TTR依次为0.1889、0.0626、0.0731 和0.0275。这说明普通英语各4000词(形符)文本块的名词和动词多样性大于科技英语,但其形容词多样性却低于科技英语,副词多样性大体相当。换言之,科技英语的某语篇内名词和动词重复较多,即形符数较多,类符数较少;但普通英语的篇内(每4000 词次)形容词重复性大,0.0613 <0.0731。下面分析两个语料库的累积TTR 曲线,如图2所示。

图1 SBNC 和JDEST 实词增长曲线

图2 SBNC 和JDEST 中各类实词TTR 下降曲线
图2中实线为SBNC 的TTR 曲线,虚线为JDEST 的TTR 曲线。图2显示SBNC 的名词、动词和形容词累积TTR 都高于JDEST。说明随着总词次以每4000 词增加,普通英语的名词、动词和形容词的词汇多样性一直高于科技英语。即普通英语的名词、动词和形容词(形符)篇际(累积语篇)重复性较小,科技英语的名词、动词和形容词的篇际重复性较大。两者的副词TTR 曲线大体相同。
因此可得出如下结论:普通英语中名词和动词的篇内和篇际重复性都小于科技英语;但其形容词的篇内重复性大,篇际重复性则小于科技英语。
3.实词重复分析
计算出两个语料库的累积实词重复数后发现,两个语料库中的累积实词重复数都呈类似线性的增长模式。SBNC 中名词、动词和副词的累积重复数一直高于JDEST。SBNC 中名词累积重复数在0 ~210 000 之间,动词累积重复数在0 ~76 000 之间,副词累积重复数在0 ~32 000 之间。而JDEST 中的名词、动词和副词累积重复数分别在0 ~170 000、0~58 000 和0 ~26 000 之间。不同之处在于SBNC的形容词累积重复数一直小于JDEST,两者的最终重复数相当。为进一步揭示各类实词累积重复数和其累积形符数的关系,算出了两个语料库中各类实词的累计重复率,如图3所示。
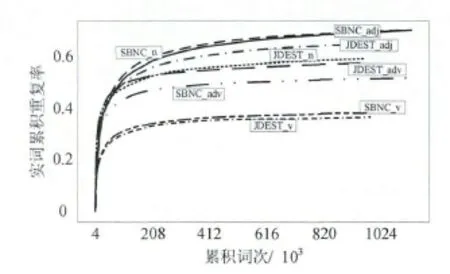
图3 SBNC 和JDEST 中各实词累积重复率
图3显示SBNC 语料库中的名词累积重复率最高,达到68.49%,其次是SBNC 中的形容词累积重复率。而且在曲线末端,形容词的累积重复率甚至超过了名词累积重复率,为68.72%。JDEST 中形容词累积重复率最高,达到64.69%,其次为名词,为58.58%。在SBNC 和JDEST 两个语料库中,副词累积重复率都位于第三位;最后是动词,其累积重复率最低,分别为38.49%和36.48%。进一步观察发现,SBNC 的名词、形容词、副词和动词累积重复率都高于JDEST。
四、结 语
通过对SBNC 和JDEST 中的实词对比分析,得出如下结论:(1)普通英语和科技英语的名词、形容词和动词呈类似的增长态势:先是急剧增加,然后变缓。(2)普通英语的名词和动词多样性大于科技英语,但其形容词多样性却低于科技英语。(3)普通英语中名词和动词的篇内重复性以及名词、动词和形容词的篇际重复性都小于科技英语,但其形容词的篇内重复性较大。(4)普通英语和科技英语中累积实词重复数都呈类似线性的增长模式。普通英语中名词累积重复率最高,科技英语中形容词累积重复率最高。但科技英语的名词、形容词、副词和动词累积重复率都低于普通英语。本研究结果有利于对英语语篇、英语学习者的实词词汇量进行评估。由于英语中虚词数量十分有限,英语语篇的复杂度和多样性主要依赖于语篇中的实词词汇量。只要能估计某语篇的实词词汇量,就可预测其词汇多样性。这在教材编撰及选择不同层次水平的阅读材料时有重要意义。
[1]BAAYEN R H.Word frequency distribution[M].Dordrecht:Kluwer Academic Publishers,2001.
[2]BRUNET E.Le vocabulaire de Jean Giraudoux.Structure et évelution[M].Genève:Slatkine,1978.
[3]FAN Fengxiang.Models for dynamic inter-textual type-token relationship[J].Glottometrics,2006,12(1):1-10.
[4]FAN Fengxiang.A corpus-based study on random textual vocabulary coverage[J].Corpus Linguistics and Linguistic Theory,2008,4(1):1-17.
[5]FAN Fengxiang.An asymptotic model for the English hapax/vocabulary ratio[J].Computational Linguistics,2010,36(4):631-637.
[6]TULDAVA J.Methods in quantitative linguistics[M].Trier:WVT,1995.
[7]FRANCIS W N,KUCERA H.Frequency analysis of English usage:lexicon and grammar[M].Boston:Houghton Mifflin,1982.
[8]JOHANSSON S,HOFLAND K.Frequency analysis of English vocabulary and grammar 2 vols[M].Oxford:Clarendon Press,1989.
[9]罗卫华,邓耀臣.基于BNC 语料库的英语篇际词汇重复模式研究[J].外语教学与研究,2009(3):224-229.
[10]罗卫华,佟大明.篇际零重复词分布和增长模式实证研究[J].中国外语,2011(6):59-64.
[11]MALVERN D,BRIAN R,NGONI C,et al.Lexical diversity and language development:quantification and assessment[M].New York:Palgrave Macmillan,2004.
[12]READ J.Assessing vocabulary[M].Cambridge:Cambridge University Press,2000.
[13]BIBER D.Methodological issues regarding corpus-based analyses of linguistic variation[J].Literary and Linguistic Computing,1990,5(4):261.
猜你喜欢
三门峡职业技术学院学报(2021年4期)2021-04-19
韩国语教学与研究(2021年3期)2021-03-16
新世纪智能(英语备考)(2019年10期)2019-12-16
新世纪智能(语文备考)(2019年1期)2019-05-31
新世纪智能(语文备考)(2018年11期)2018-12-29
新世纪智能(语文备考)(2018年9期)2018-11-08
科学与财富(2016年21期)2017-03-02
外语教学理论与实践(2014年2期)2014-06-21
高中生学习·高三版(2014年3期)2014-04-29
语文知识(2014年2期)2014-02-28
