
基于联合索引的下一代图书馆学术资源搜索研究
2012-12-06 02:32:22朱本军
大学图书馆学报 2012年2期
□朱本军
早期图书馆的数字资源建设思路,一般是根据拟建资源的类型开发出一套完整的资源管理和发布系统:后台著录与管理界面+数据库+前端读者检索界面。随着数字资源类型和用途的越来越多,图书馆资源系统也越来越多,除了本地书目系统和本地数字馆藏(如学位论文、古籍等),还有大量期刊数据库。据不完全统计,高校图书馆目前拥有的资源发布系统包括:
●图书馆网站:1个或多个,如门户、图书馆博客等;
●本地书目系统:1个,如自动化集成系统;
●本地数字馆藏系统:1个或多个,如学位论文、古籍(多个);
●本地或远程电子书系统:1个或多个,如方正电子书、NetLibrary等;
●商业数据库:几十个至几百个不等,如Pro-Quest、EBSCO、JSTOR、中国期刊网、维普数据库等。
各类资源呈分布式异构发展,系统之间差别较大:大多数系统基本上都是独立的系统,数据不能被其他系统调用;各系统用不同程序语言(如JAVA、PHP、C等)开发;各系统在内容、结构、服务方式和管理策略上各不相同;各个系统的元数据著录格式也各不相同,有自定义的(多见于本地自建资源系统)、有遵循区域规范的(如CALIS元数据标准规范、CNMARC、USMARC等)、有遵循行业规范的(如用于图书在线交换的ONIX标准)等。由于各系统分布式异构,很难将所有的资源整合在一起揭示,给图书馆用户带来了诸多额外负担[1]:增加用户选择和熟悉各资源分布的时间;各资源系统内容交叉重复,增加了读者信息鉴别和去重的时间;各资源系统之间数据的关联度低,增加用户知识衔接的负担。如何快速有效查找和利用图书馆的数字资源是图书馆一直面临的重要课题。
本文在对图书馆学术资源检索模式进行回顾的基础上,评介一种基于索引的学术资源搜索引擎及其工作模式。基于整合索引的学术搜索引擎较好地解决了资源查找效率和显示的问题,是下一代图书馆学术资源检索的趋势。为使读者深刻理解这种基于索引的学术搜索引擎,本文对常见的三个典型代表SUMMON、Google Scholar和SCIRUS进行案例分析和研究。
1 图书馆资源检索的模式:历史回顾
1.1 本地资源检索模式:实时检索和本地索引
本地独立资源管理与发布系统可能在功能上有的复杂有的简单,有的也有API数据接口,它们有大致相同的系统架构:元数据著录与后台管理+数据库+用户检索界面。这样的系统目前在图书馆分布非常普遍,典型的例子如图书馆自动化集成系统、方正学位论文系统、图书馆门户等。
本地独立资源管理与发布系统的检索模式有两种:一是实时检索数据库(如图1)。这种检索模式一般在数据量比较小的情况下使用。这种实时检索数据库模式的缺点非常明显:在数据量非常大的情况下,查询响应的效率非常低。以图书馆的自动化集成系统为例,一般拥有几十万甚至上百万条书目记录,如果采用实时检索数据库的方式,每一次显示结果,需要几秒、十几秒的等待时间。
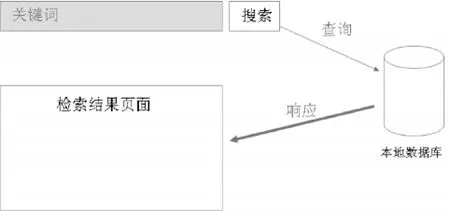
图1 实时检索数据库模式
在数据量比较大的情况下,一般采用第二种方式:数据库本地索引模式(如图2)。这种模式的工作机制是:在检索之前对系统数据库关键词做索引,索引后每秒可以检索几百万条数据,大大提高查询和使用图书馆资源的效率。各高校使用的自动化集成系统,大部分都采用了这种模式。

图2 本地数据库索引模式
1.2 分布式异构资源检索模式:联邦检索
随着图书馆资源越来越多,图书馆的资源系统更多呈分布式发展:每个图书馆都有十几个甚至几十个资源系统的检索入口。分布式资源系统增加了用户选择和熟悉各资源分布情况的负担,并且各资源系统本身也存在内容交叉重复,各资源系统之间数据的关联度低的状况,不利于图书馆资源的综合利用。图书馆开始考虑以单一检索入口检索分布在图书馆的所有学术资源的方式,比较典型且在图书馆应用广泛的例子是利用联邦检索系统检索商业数据库。
联邦检索,有时称为整合检索、元搜索、同步检索、跨库检索、并行检索或广播检索,包含三个过程(如图3)[2]:(1)用户发出查询请求,联邦检索引擎对查询请求进行语法转换,然后广播到各数据库检索引擎;(2)各数据库检索引擎将查询到的结果反馈给联邦检索系统,联邦检索系统对反馈的结果进行合并、查重等实时处理;(3)将处理后的结果集以一种简洁、统一的格式展现在结果页面。
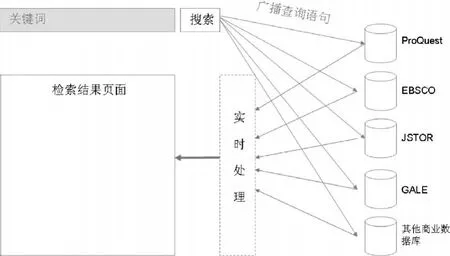
图3 分布式资源联邦检索模式
联邦检索的前提是每个资源系统都有一个本地搜索引擎,联邦检索将各个本地搜索引擎整合在一起而不管资源系统本身的架构,因此联邦检索可以将异构和同构的资源系统整合在一起。应用联邦检索系统,图书馆不仅可以整合检索电子期刊商业数据库(如JSTOR、EBSCO、ProQuest等商业数据库),还可以整合检索本地馆藏目录、本地数字馆藏(如学位论文、特藏库等)等。
虽然联邦检索解决了图书馆分布式异构系统通过同一入口揭示所有学术资源的问题,但是也有很多问题:
一是检索速度受网络、联邦检索服务器性能和数据源服务器性能影响较大。检索时间包含广播查询语句到各搜索引擎的时间、数据源服务器处理查询请求的时间、各资源系统返回查询结果的响应时间和在联邦检索服务器上对查询结果进行查重等处理的时间。这些时间又受到网络连接速度、联邦检索服务器和数据源服务器性能的影响。
二是检索结果集比较浅,且是偏态的。由于返回和检索时间比较长,为减少用户等待时间,联邦检索系统会先从各个资源系统返回少数结果。这种结果并不是对所有资源综合计算后的结果,而是按照返回的时间顺序给出的结果。
三是对结果集很难进行组织和相关度排序。主要是因为检索返回的结果都是动态的。
1.3 本地资源和分布式资源混合检索:混合模式
为了进一步提升资源检索效率,图书馆采用了另外一种方式:本地索引和联邦检索相结合的混合模式。混合检索比较典型的产品,如下一代图书馆目录Primo、Encore、AquaBrowser等。它们可以通过一个统一的、带不同标签可切换的检索入口(如图4)完成本地资源和远程资源的检索:当用户要检索图书馆本地资源时,只需要切换到搜索框上面的“本地馆藏”标签即可;当用户要检索远程的商业数据库时,则切换到“数据库”标签即可。

图4 混合检索用户界面
混合检索的实现机制(如图5)是:将图书馆本地的所有资源,包括本地馆藏目录、本地数字馆藏(如机构库、特藏库等)进行统一索引;而对分布在远程的商业数据库仍然实现联邦检索。混合检索模式解决了图书馆本地所有资源快速响应和结果集组织与显示的问题,但对于远程商业数据库仍然不得不采用联邦检索模式。
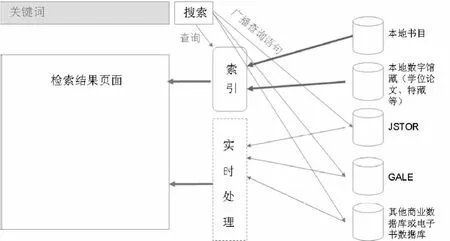
图5 混合检索模式
2 下一代图书馆资源整合检索模式:基于联合索引
混合检索模式虽然解决了用户单一资源检索入口的问题和本地资源集中快速访问的问题,但是仍然没有解决联邦检索中远程数据库检索和获取慢、相关度不高和结果集排列混乱的问题。
下一代图书馆的学术资源搜索引擎,采用本地数据和远程数据统一集中索引的方式达到对图书馆全部学术资源整合检索的目的(图6)。
在这种模式下,图书馆拥有和使用的所有学术资源(包括元数据、文章全文)在提供用户检索之前,全部被提前处理成规范的、结构化的XML数据。此外,还在XML数据的基础上进行查重、FRBR、内容增强(将其他网站的数据整合到单条记录中丰富记录信息,如封面、目录等)等处理,最后集中索引形成一个庞大的索引数据库。
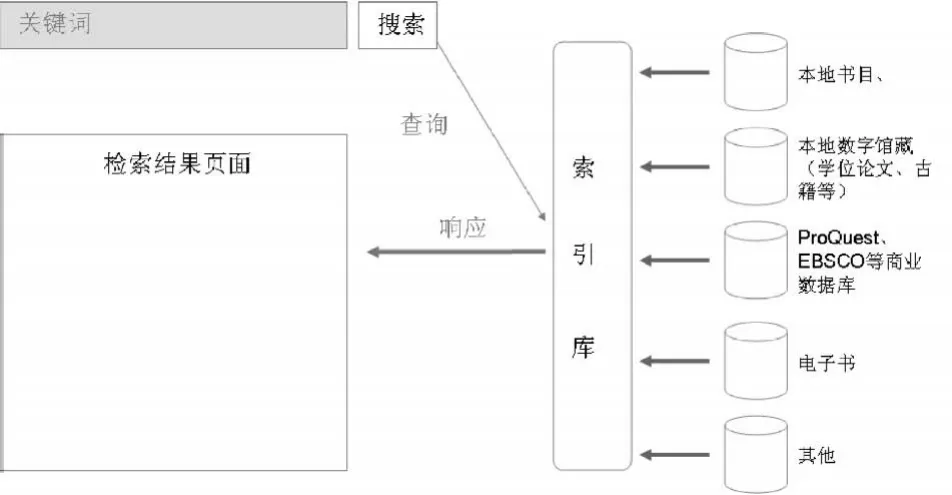
图6 下一代图书馆学术资源联合索引检索模式
经过查重、FRBR和内容增强等处理后的索引库,不仅解决了资源重复、不同版本多条显示、记录信息量少的问题,而且可以每秒几百万条记录的速度提供实时查询响应。除此以外,由于数据通过XML进行了非常好的结构化组织,资源和资源之间可以形成某种关联,结果集也可以通过web2.0技术得到非常好的组织和排列。
3 基于索引的学术搜索引擎案例研究
基于索引的图书馆学术资源整合检索模式,很早就在各大型商业数据库中使用,如美国的洛斯阿拉莫斯国家实验室(Los Alamos National Laboratory)、加拿大多伦多大学(the University of Toronto)、丹麦技术知识中心(the Technical Knowledge Center of Denmark)、德国的马克思普兰克学会(the Max Planck Society)等,它们都提供了存储在本地的大量电子期刊检索服务,用户只要在检索界面输入关键词,很快就能获得相关文章的全文链接[3]。
这种基于学术资源索引模式的产品趋于成熟,并于最近几年在图书馆相关行业被广泛使用。比较典型的例子,如专用于科学信息检索的SCIRUS[4]、Google Scholar学术搜索引擎[5],图书馆系统提供商360Serials Solution公司的SUMMON产品、Innovative公司的Encore Synergy[6]、EBSCO Host公司的EDS(EBSCO Discovery Service)产品,以及Ex Libris公司的Primo Central产品。下面对Google Scholar学术搜索、SUMMON和SCIRUS三个产品进行案例研究,以便对基于索引的搜索模式有更深入的了解。
3.1 Google Scholar学术搜索引擎
Google Scholar学术搜索于2004年10月面世。自其推出以来,即受到教育和学术科研机构的青睐。
Google Scholar学术搜索引擎本质上是在学术资源索引库的基础上架设一个Google搜索引擎(如图7)。其中Google搜索引擎采用了Google公司专有的PageRank相关度页面排序技术,返回的结果带有引文信息、版本信息等学术信息。其学术资源索引库集中了大量的各类学术资源,包括普通网页中的学术论文、同行评议文章、学位论文、图书、预印本、文摘、技术报告等学术文献,文献来源于学术出版物、专业学会、预印本库、大学机构,内容从医学、物理学到经济学、计算机科学等横跨多个学术领域[7]。
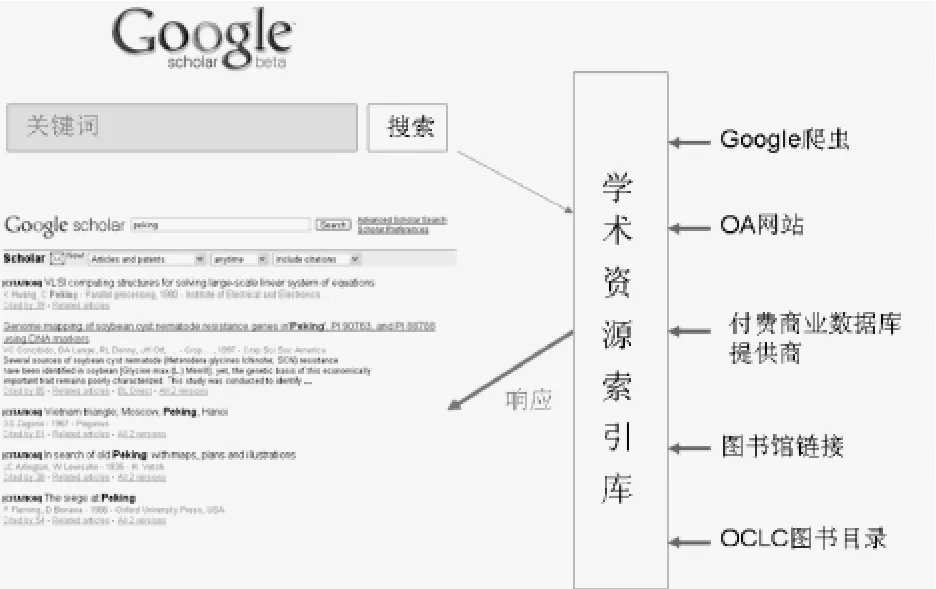
图7 Google Scholar学术搜索
Google Scholar学术资源索引库中的数据大致有如下几个方面的来源[8]:一是Google爬虫搜集到的网上免费的学术资源,包括已经发表的论文、论文的预印本、工作报告、会议论文、调研报告等有学术价值的文献。二是开放获取的期刊网站,如英国牛津大学出版社、斯坦福大学的High Wire出版社出版的学术期刊,大部分已被Google Scholar所涵盖。三是付费电子资源提供商,通过与Google Scholar合作向Google Scholar提供电子数据库的元数据和摘要。四是图书馆链接,Google Scholar通过向图书馆发出免费链接邀请,让图书馆提供本地学术资源数据,并提供面向这些图书馆资源的链接和查询。五是OCLC提供的书目数据[9]。
3.2 SCIRUS科学信息搜索引擎
SCIRUS是一个由Elsevier Science开发,比Google Scholar更早利用学术资源索引库的大型搜索引擎。SCIRUS与Google Scholar的不同之处在于SCIRUS专门提供科学信息的检索。
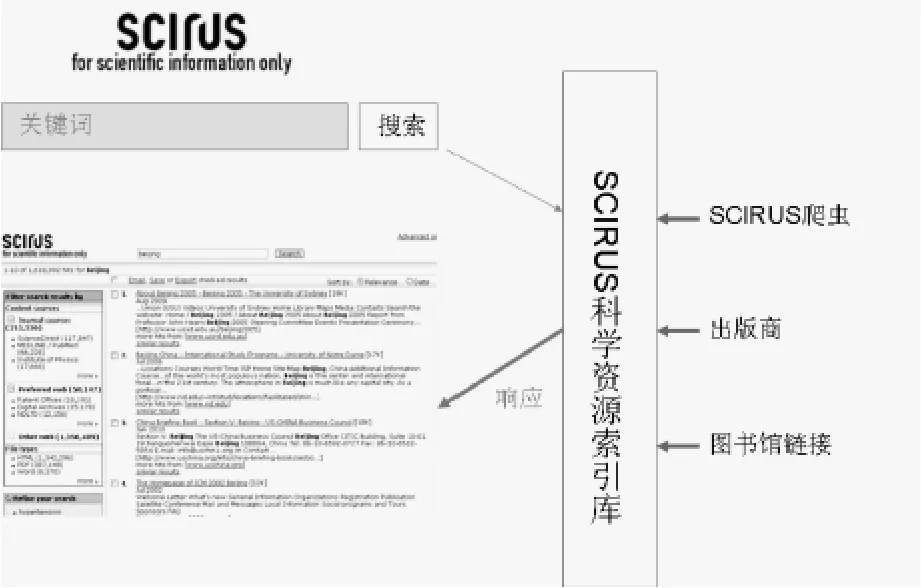
图8 SCIRUS科学信息搜索引擎
SCIRUS涵盖的资源的主要来源:一是SCIRUS爬虫,搜集各与科学相关的网站和文档,并对这些网站进行深度索引。从其官方资料中了解到其资源主要来自互联网,目前涵盖3.8亿个与科学相关的网站,包括:1.26亿.edu站点、0.4亿个.org站点、0.2亿个.ac.uk站点、0.38亿.com 站点、0.38亿个.gov站点和1.18亿其他相关科技与社会研究及大学网站[10]。二是出版商,如 NASA、BioMed、ScienceDirect、Royal Society Publishing 等[11]。三是图书馆链接,接受来自世界各地的图书馆链接[12]。所有这些科技信息网站的索引信息,包括文章、电子印本、同行评价文章、专利、文档、期刊文章等[13]。
SCIRUS的工作机制(如图8):首先将不同来源的资源进行索引,形成SCIRUS科学资源索引库;然后提供SCIRUS专有的搜索引擎界面。
3.3 SUMMON学术资源索引服务
SUMMON是360Serials Solution公司推出的一款数据服务类产品,于2009年1月面世,同年7月开始在全球范围销售。目前已有一些大学图书馆用户,如密歇根州州立大河谷大学图书馆[14]、悉尼大学图书馆[15]、西悉尼大学图书馆[16]等。
SUMMON的原理是提供一种数据服务(如图9),将不同来源的学术资源和摘要集中索引成一个索引数据库,并提供开放的API数据接口供其他系统调用。不过,为了更好地利用数据、推广SUMMON,360Serials Solution公司在推出SUMMON产品的时候在学术资源索引库上架设了一个用户界面。用户界面使用的是一款开源全文搜索引擎Lucene/SOLR,学术资源索引数据库是对360Serials Solution拥有或与其有合作关系的数据库提供商提供的所有资源的元数据、摘要甚至全文的索引。

图9 SUMMON数据服务
SUMMON的学术资源索引的涵盖范围可以包括图书馆本地书目记录、电子期刊文章、数据库、报纸文章、电子书、学位论文、机构库、会议文集、灰色文献、引文、报告和数字图书馆[17]。索引数据主要有两个来源:一是付费数据库提供商,通过与内容提供商签署合作协议来达成,主要是期刊和报纸出版商、电子书出版商和第三方整合者[18];二是购买SUMMON产品的图书馆提交的本地资源,包括本地书目记录、本地数字馆藏和图书馆其他愿意通过SUMMON揭示的资源。
4 结论
从对图书馆学术搜索的三种模式的历史回顾,以及对三个学术资源搜索引擎的案例研究中,可以看出下一代图书馆学术资源搜索引擎在搜索模式上并没有特别创新之处,主要是观念上的变化:从把搜索系统整合在一起的联邦检索,转向把数据整合在一起,将数据作为一种服务,提供面向服务的索引数据。
基于索引的服务模式,不仅解决了单一搜索框高效快速检索图书馆所有本地和远程分布式异构学术资源的问题,而且还通过提供标准化、结构化的XML数据解决了结果集的组织和排列问题。这种基于索引的搜索服务将会成为目前和未来图书馆学术资源搜索的主流模式。这也是本文采用“下一代”这个词的主要原因。
1 李书宁.数字图书馆跨库检索技术研究.数字图书馆论坛,2005(2):6-9
2 Péter Jacsó.Thoughts About Federated Searching.Information Today,2004,21(9):17
3 Tamar Sadeh.Google Scholar Versus Metasearch Systems.High Energy Physics Libraries Webzine,2006(12).[2010-06-04].http://library.web.cern.ch/library/Webzine/12/papers/1/
4 SCIRUS.[2010-06-04].http://www.scirus.com
5 Google Scholar.[2010-05-31].http://scholar.google.com
6 Innovative Launches Encore Synergy.[2010-10-04].http://encoreforlibraries.com/2010/04/16/innovative-launches-encore-synergy
7 关于Google学术搜索.[2010-06-04].http://scholar.google.com/intl/zh-CN/scholar/about.html
8 段其宪.Google Scholar成功特性分析.现代情报,2007(7):221
9 Norman Oder.So,Can Google Use OCLC Records?Yes,But.[2010-06-03].http://www.libraryjournal.com/article/CA6695887.html
10 The Range of Scientific Content Scirus Covers.[2010-06-04].http://scirus.com/srsapp/aboutus/#range
11 More About Scirus Information Sources.[2010-06-04].http://scirus.com/srsapp/aboutus/#sources
12 About Scirus Library Partners.[2010-06-04].http://scirus.com/srsapp/librarypartners/
13 About Scirus.[2010-06-04].http://www.scirus.com/srsapp/aboutus/
14 Grand Valley State University Library.[2010-06-04].http://gvsu.edu/library
15 The University of Sydney Library.[2010-06-04].http://www.library.usyd.edu.au/
16 University of Western Sydney Library.[2010-06-04].http://library.uws.edu.au/
17 Summon Overview.[2010-06-04].http://www.serialssolutions.com/summon
18 Summon Content Participants.[2010-06-04].http://www.serialssolutions.com/summon-content-participants/
猜你喜欢
家庭影院技术(2020年10期)2020-12-14 07:54:16
家庭影院技术(2019年7期)2019-08-27 02:42:06
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
专利代理(2016年1期)2016-05-17 06:14:36
中国卫生(2015年12期)2015-11-10 05:13:38
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06 07:49:12
技术经济与管理研究(2014年11期)2014-03-11 17:02:44
俄罗斯问题研究(2013年1期)2013-03-11 15:43:59
中国宪法年刊(2012年0期)2012-03-25 13:11:43
质量与标准化(2010年5期)2010-05-03 04:15:40
