
基于语音结构化模型的数字语音识别
2012-11-30 03:18俞一彪
计算机工程与设计 2012年4期
姜 莹,俞一彪
(苏州大学 电子信息学院,江苏 苏州215006)
0 引 言
目前非特定人语音识别已经取得了很大进展,但与特定人的语音识别系统相比还有很大的差距。影响系统性能的一个重要因素是说话人语音之间的声学差异,包括不同说话人的性别、年龄、不同的声道长度和形状以及说话的风格口音等对语音特征参数的影响。传统的消除说话人之间的声学差异通过对模型以及参数处理,如模型自适应、说话人聚类方法等,以减少说话人之间的声学差异。或者采集数量很大的说话人语音用于训练,让训练语音覆盖更为广泛的语音空间,因此对语音训练量要求较高。
事实上传统的语音识别方法都是采用声学特征来描述模型,无论采用模型补偿方法还是归一化方法,都无法解决说话人差异对识别系统性能的影响。最近,日本东京大学N.Minematsu教授从挖掘语音信号中具有相似语义特征的基本单元以及它们之间特征分布的内在关系着手,通过运用Bhattacharyya测度,提出了一种全局声学结构AUS,理论上可以证明这一结构化描述对于说话人差异具有不变性[1],即可以从语音中提取对说话人差异具有鲁棒性的结构化特征AUS,它可以忽略说话人个性特征,只包含语义特征信息。该理论已被成功用于基于方言的说话人分类[2]、音素的切分[3]、语音评测系统[4]、语音转换[5]、语音合成[6]、计算机辅助语言学习[7](computer aided language learning,CALL)系统以及日语元音串和词的识别研究[8-9]。汉语数字发音也有其本身特点,时长较短,且含有丰富的声学音素,因此将AUS用于数字语音识别具有一定的实际意义。
首先介绍语音结构化模型的相关理论,并将其应用于中文数字语音识别。实验测试了少量语料训练下,AUS方法和HMM方法在以下说话人差异情形下的识别情况:①采用声道弯折方法模拟不同说话人之间的差异性;②20个实际说话人之间的差异性。实验结果表明,在少量语料训练下,该方法可以取得优于HMM的性能,语音结构化模型可以有效消除说话人之间的差异。
1 语音结构化模型及数字识别
1.1 全局声学结构AUS
全局声学结构AUS描述的是语音内在的声学特征结构关系[10],如图1所示。其中,结构点表示语音中最小语义单元的声学特征分布,构成语义的基本单元,其大小并不是固定的,从汉语来讲语义单元可以是单词、音节、声韵母或者是更为精细的音素等;而节点之间的连线表示语义单元声学特征分布之间的关系,所有连线形成的网络被定义为全局声学结构。
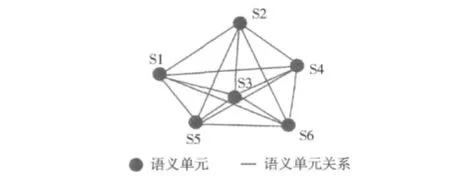
图1 语音的全局声学结构AUS
全局声学结构AUS的基本语义单元是用声学特征参数的统计分布描述的,而声学特征参数不可避免地会受到说话人差异性影响而引起一定的变化。说话人差异性包括不同说话人具有不同的声道形状 (主要指声道长度)和其个性特征[11]等。不同说话人声道长度差异通常在频域视为双线性变换
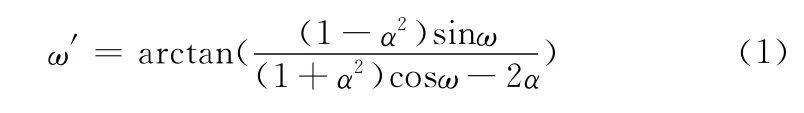
频率弯折曲线如图2所示。
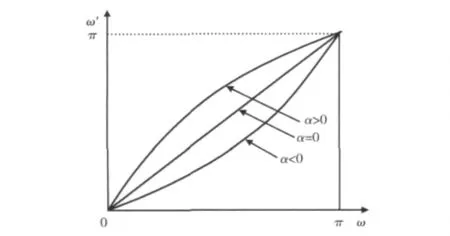
图2 对应不同声道弯折因子α的频率弯折曲线
这里,ω和ω′分别表示变换前、后的角频率,α为声道弯折因子,α=0时变换前后的角频率满足线性关系,对应声道长度不进行弯折处理。一般,有:-1<α<1,α的正负分别对应声道长度的缩短和增长[12],α绝对值的大小决定了声道弯折程度的大小。这种频域的非线性变换在倒谱域表现为一种线性映射。假设一说话人语音的倒谱域特征矢量为X,那么同一语音不同说话人的倒谱域特征矢量为AX。高斯混合模型 (Gaussian mixture model,GMM)用于说话人时,对不同说话人的语音的短时谱特征矢量所具有的概率密度函数进行建模[13],实现对说话人个性特征的建模。因此不同说话人之间个性特征差异可视作频域的乘性失真,在倒谱域空间可以表示为叠加性失真B,那么失真后的说话人的倒谱特征矢量变为X′=X+B。综合最终的特征矢量变为X′=AX+B。
AUS中特征分布之间的关系,用衡量统计分布之间的Bhattacharyya距离测度来描述,以保证在说话人差异的干扰下倒谱特征参数分布之间的关系保持不变。Bhattacharyya距离是衡量两个统计分布之间距离的一种测度。如下所示

如果统计分布是高斯分布,则上式可以推导为
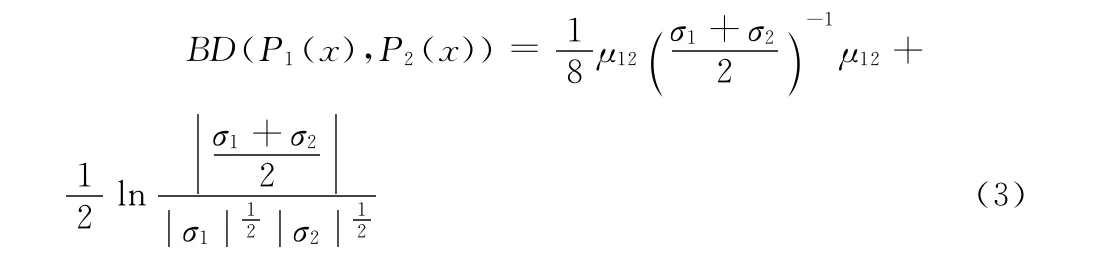
设原始倒谱域特征矢量x,服从分布P(μ,σ),相同语音不同说话人的倒谱特征矢量为x′=Ax+b,服从的特征分布为P(μ′,σ′)。
由于μ=E(x),σ=E(x-μ)(x-μ)T,μ′=E(x′)=E(Ax+b)=Aμ+b,σ′=E(x′)=E(x′-μ′) (x′-μ′)T=AσAT,那么有
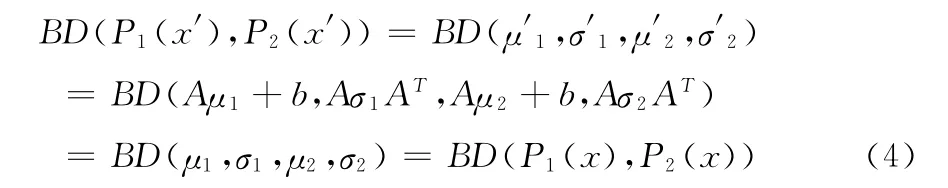
以上说明,我们可以从语音中提取对不同说话人和其个性特征具有鲁棒性的结构化特征,这种结构化特征采用了语音内部各个内在特征统计分布的相对Bhattacharyya距离来表示,它是语音的一种有效的结构性模型,这一模型不会受到不同说话人语音之间差异的影响。理论上不同说话人发相同语音尽管具有不同的声学特征分布,但其AUS是保持不变的[14]。
1.2 基于语音结构化模型的数字识别
AUS结构化模型用于数字识别的整个过程如图3所示,包括两部分工作:①对训练数字语音建立全局声学结构AUS;②提取测试语音的AUS,与各数字的语音结构模型匹配,进行识别。
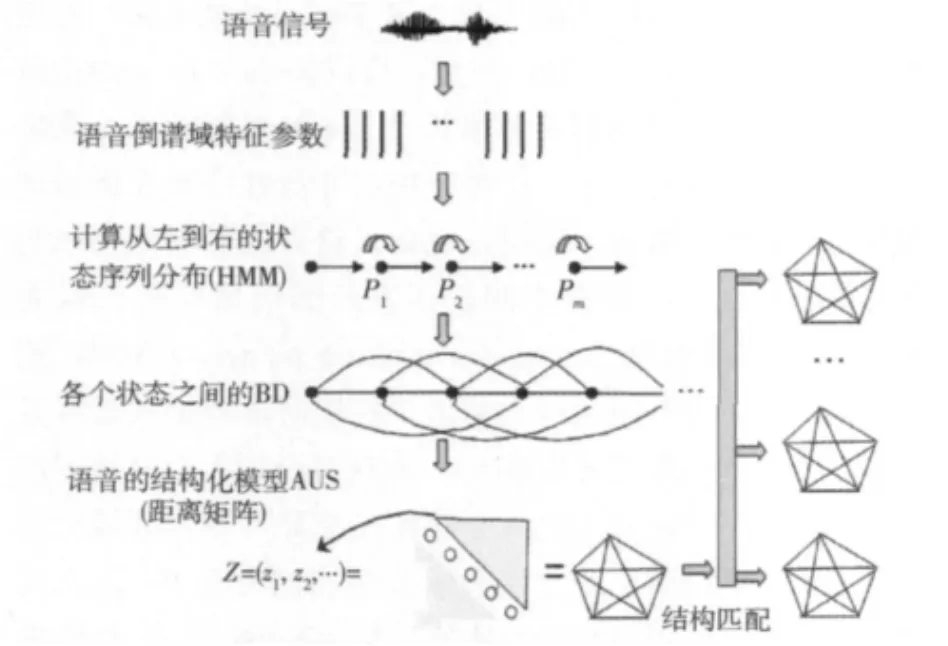
图3 基于AUS模型的数字识别流程
对训练和测试语音建立全局声学结构时,首先对数字语音提取倒谱特征参数 (如MFCC参数),然后通过HMM训练提取内在声学特征分布,构成一个自左向右的状态序列分布。最后计算各个分布之间的Bhattacharyya距离形成AUS。数字AUS模型的描述可以采用一个M×M对角线元素值为零的二维对称矩阵表达,其中M代表基本语义单元数,存放各语义单元特征分布之间的距离值。矩阵中各语义单元必须按序排列,第一个语义单元对应第一行,第二个语义单元对应第二行,并依次类推,表达各语义单元的相对时序关系。对训练语音建立AUS时,训练语音可以是一遍或者多遍样本数据,而对于测试语音,仅由一遍测试语音样本构建其AUS。
识别实际上是求两个AUS之间的距离,如果把各个二维矩阵元素看作是二维空间点的话,那么两个矩阵T和R之间的距离可以通过计算对应点之间的欧几里德距离进行计算并汇总得到[15],即
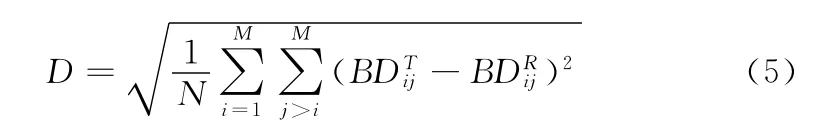
式中:N——计算的元素个数,M——基本语义单元数,BDij——语义单元i和j之间的Bhattacharyya距离值。
首先,对各个数字 (假设N个数字)语音建立AUS,得到N个参考AUS结构化模型,识别时提取测试语音的AUS,并与N个数字的AUS匹配,得到与各个数字的结构匹配差值d1,d2,…di,dN。第i*个数字串即为最终识别结果
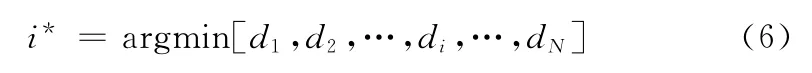
其中1≤i≤N。
2 实验分析
实验中训练语音数据库为SUDA-2008数据库,均在普通实验室环境下用普通声卡进行录音,采样率为16KHz,量化精度为16位。参加实验的人数共有20人,其中10位男性说话人,10位女性说话人。每人录制了3遍电话号码中的11 个 数 字 的 发 音:0 (ling)、1 (yi)、2 (er)、3(san)、4(si)、5 (wu)、6 (1iu)、7 (qi)、8 (ba)、9(jiu)、1 (yao)。语音信号分帧处理,帧长25ms,帧移10ms,加汉明窗,预加重系数取0.97,参数采用17阶MFCC参数。语音模型采用6个状态,每个状态下单高斯分布HMM。AUS方法中同样采用6个状态的HMM,形成6×6的数字AUS模型。
基于以上语音数据,进行两组实验,实验一:对训练集的语音进行不同程度的声道弯折以模拟更多 “不同说话人”的语音,并构成测试集。实验二:来自非训练集的实际说话人语音构成测试集。两组实验均采用少量语料训练,分析AUS方法消除说话人差异性的性能,并与传统的HMM方法比较。
实验一:测试集作如下处理,对20个说话人的3遍语音采用 (1)进行频率的非线性变换,实现不同程度的声道弯折,以模拟具有不同声道长度的说话人语音。实验中弯折因子α取-0.4,-0.35,…,0,…,0.35,0.4,共17个弯折系数,其中α=0表示声道不做弯折处理,并以该 “说话人”的各个数字的1遍语音分别作为训练集,进行Mel倒谱分析,训练HMM,建立AUS结构化模型。其余16个弯折因子下,即16个 “不同说话人”的语音构成测试集,同样训练HMM提取其AUS与各个数字的结构化模型进行匹配。实验统计20个说话人的语音数据的识别情况,其中每个弯折因子下660(=20×3×11)个识别数据。实验结果如图4所示。
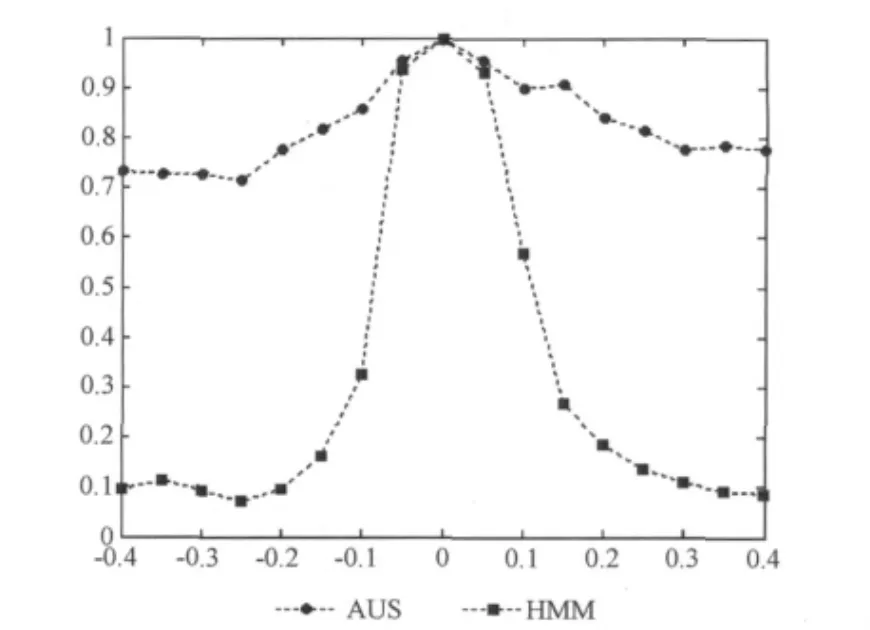
图4 不同弯折因子下的识别率
由图4可以看出:
(1)声道弯折因子α=0时,该情况下测试语音来自训练语料集,AUS方法和HMM方法具有一致的性能。识别率都为100%。
(2)在声道弯折程度较小α=-0.05和α=0.05时,由于说话人声道长度差异性较小,AUS方法的识别率略高于HMM方法,AUS方法的优越性并不明显。
(3)当声道弯折程度|α|>0.05时,随着声道弯折程度的增加,不同说话人之间声道长度差异增大,HMM方法下的识别率迅速下降,而AUS方法的识别率在不同弯折因子下仍能都保持在70%以上。在|α|>0.2的各个弯折因子下,AUS方法的识别率效果相当,并没有随着说话人差异的增加而导致识别率降低。可见,语音结构化模型可以有效消除说话人之间的差异,提高系统的识别率。
实验二:以来自非训练集的实际说话人语音构成测试集,对20个说话人依次标号,其中1-10为男性说话人,11-20为女性说话人。以说话人1的各个数字的2遍语音作为训练集,进行Mel倒谱分析,训练HMM,建立AUS结构化模型。除说话人1外其余19个说话人每人3遍的语音,共627(=19×3×11)个测试语音构成测试集做识别;同样以说话人2的各个数字的3遍语音做训练集,除说话人2外其余19个说话人的语音构成测试集,依次类推。实验分析以20个说话人语音依次作训练集时,AUS方法和HMM方法的识别性能,实验结果如图5所示。
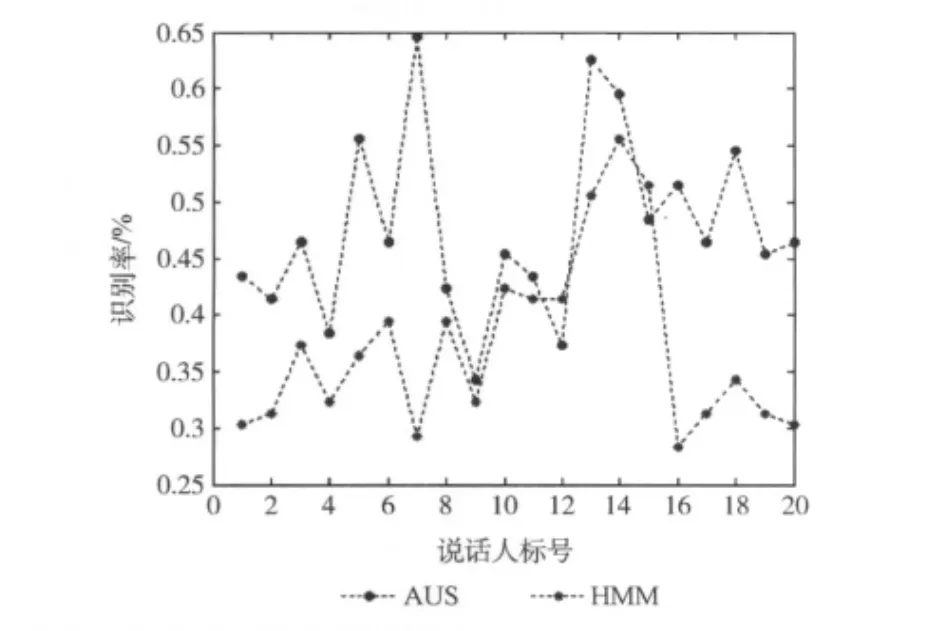
图5 20个说话人语音依次作训练集时AUS方法和HMM方法的识别率
由图5可以看出:
(1)AUS方法下的识别率大多高于HMM方法下的识别率,只有在说话人13和说话人15都为女性说话人时,HMM方法的识别率高于AUS方法。在以说话人7作为训练模板时,AUS方法达到最大的识别率65.12%。可见在较少训练量的情况下,AUS方法能够消除实际说话人之间的差异性,获得比HMM更高的识别率。
(2)实际上从实验一的结果可以看出,如果实际说话人差异不大,HMM方法和AUS方法的性能相当,所以在实验二中以个别说话人作为训练集时,HMM方法的识别率高于AUS方法。因此少量语料且说话人差异较大时,较HMM方法AUS方法能很好地体现其优势性。
(3)由于不同说话人声道长度的差异不一定能很好地符合频域的非线性变换,且实际中说话人之间的差异性还受很多其它因素影响,如声音的不稳定性等。因此与实验一结果相比AUS在消除实际说话人差异性方面的效果不那么明显。
以上两个实验表明,在少量语料训练下,AUS方法可以取得优于HMM方法的性能。HMM方法在说话人语音特征差异下,即训练和测试语音特征空间相差较大时,其识别性能迅速下降。而AUS方法能有效消除模拟说话人和实际说话人之间的差异,且较少的训练语料就可以达到较好的识别效果。
3 结束语
本文介绍了一种新颖、不同于传统声学特征来描述模型的语音识别方法—语音结构化模型的识别方法。引出语音结构化模型的相关理论,并运用语音结构化模型方法进行数字语音识别。实验中比较了AUS方法和HMM方法在两种情形下的识别率:①采用声道弯折方法模拟不同声道长度的说话人之间差异性;②实际说话人之间的差异性。实验结果表明,在少量语料训练下,AUS方法可以取得优于HMM的性能,语音结构化模型可以有效消除说话人之间的差异。但实际说话人之间的差异性除了声道长度和个性特征差异外,还有其它因素的影响,此时AUS方法在消除差异性方面效果相对不那么明显。
[1]Nobuaki Minematsu.Mathematical evidence of the acoustic universal structure in speech [C].Japan:Proceedings of IEEE International Conference on Acoustics Speech and Signal Processing,2005:889-892.
[2]MA Xuebin,Nobuaki Minematsu.Dialect-based speaker classification of Chinese using structural representation of pronunciation [C].Proc of Speech and Computer,2008:350-355.
[3]YU Qiao,Shimomura N,Minematsu N.Unsupervised optimal phoneme segmentation:Objectives,algorithm and comparisons[C].IEEE International Conference on Acoustics Speech and Signal Processing,2008:3989-3992.
[4]Daisuke Saito,YU Qioa,Nobuaki Minematsu,et al.Improvement of structure to speech conversion using iterative optimization [C].Proc of Speech and Computer,2009:174-179.
[5]DAO Jianzeng,YU Yibiao.Voice conversion using structured Gaussian mixture model[C].Beijing:10th International Conference on Signal Processing,2010:541-544.
[6]Saito D,Asakawa S,Minematsu N,et al.Structure to speech conversion-speech generation based on infant-like vocal imitation[C].9th Annual Conference of the International Speech Communication Association,2008:1837-1840.
[7]Minematsu N,Asakawa S,Hirose K.Structural representation of the pronunciation and its use for CALL [C].Proc of IEEE Spoken Language Technology Workshop,2006:126-129.
[8]Takao Murakami,Kazutaka Maruyama,Nobuaki Minematsu,et al.Japanese vowel recognition using external structure of speech [C].Proceedings of Automatic Speech Recognition and Understanding,2005:203-208.
[9]YU Qiao,Nobuaki Minematsu,Keikichi Hirose.On invariant structural representation for speech recognition:theoretical validation and experimental improvement[C].10th Annual Conference of the International Speech Communication Association,2009:3055-3058.
[10]Minematsu N,Satoshi Asakawa.Implementation of robust speech recognition by simulating infants’speech perception based on the invariant sound shape embedded in utterances[C].Proc of Speech and Computer,2009:35-40.
[11]Nobuaki Minematsu.Yet another acoustic representation of speech sounds [C].Proceedings of International Conference on Acoustics Speech and Signal Processing,2004:585-588.
[12]Michael Pitz,Sirko Molau,Ralf Schluter,et al.Vocal tract normalization equals linear transformation in cepstral space [J].IEEE Trans on Speech and Audio Processing,2005,13(5):930-944.
[13]RUI Xianyi.Research on speaker identification in noisy environment[D].Suzhou:Soochow University,2005 (in Chinese).[芮贤义.噪声环境下说话人识别研究 [D].苏州:苏州大学,2005.]
[14]Nobuaki Minematsu,Tazuko Nishimura,Katsuhiro Nishinari,et al.Theorem of the invariant structure and its derivation of speech gestalt[C].Proceedings of Speech Recognition and Audio Processing,2005:930-944.
[15]Nobuaki Minematsu.Mathematical evidence of the acoustic universal structure in speech [C].Japan:Proceedings IEEE International Conference on Acoustics Speech and Signal Processing,2005:889-892.
猜你喜欢
家庭影院技术(2021年10期)2021-11-20
家庭影院技术(2020年7期)2020-08-24
家庭影院技术(2020年6期)2020-07-27
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
家庭影院技术(2019年1期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年10期)2018-11-02
家庭影院技术(2018年10期)2018-11-02
中国交通信息化(2018年3期)2018-06-13
