
一种基于随机化视觉词典组和查询扩展的目标检索方法
2012-09-19 11:32赵永威李弼程彭天强高毫林
电子与信息学报 2012年5期
赵永威 李弼程 彭天强 高毫林
(信息工程大学信息工程学院 郑州 450002)
1 引言
图像数据的集中和规模的增大给目标检索带来机遇的同时也带来了挑战,相较于传统的基于全局的图像检索,目标检索难度更大,面临的问题也更多,如查询目标的亮度、光照变化,视角的改变甚至部分目标被遮挡等。近年来,随着计算机视觉,尤其是图像局部特征(如 SIFT[1])和视觉词典法[2,3](Bag of Visual Words,BoVW)的飞速发展及应用,使得目标检索技术日趋实用化,如文献[4]就是一种面向网络的近似重复图像检索系统,文献[5]则允许用户使用手机拍摄图片并检索出与图片中所包含目标的相关信息。
视觉词典法最早由文献[2]提出,由于性能突出,目前已经成为目标检索领域的主流方法,但是它也存在一些开放性的问题。一是算法时间效率低及内存消耗大。视觉词典法涉及到大量高维数据的近邻查找问题,由此导致在数据规模很大的情况下,用于大规模高维近邻查找的时间将急剧增加,使得算法效率很低。文献[6]表明K-Means聚类算法只适用于生成较小规模的词典,当词典的规模超过510时就比较难以解决,为此,又引入了分层K-Means聚类算法(Hierarchical K-Means,HKM)来提高量化和检索效率。在此基础上,文献[7,8]采用近似 K-means算法(Approximate K-Means,AKM)针对大规模数据库的目标检索实现了进一步优化,并引入倒排文档结构(inverted file)来进一步提高检索效率。尽管如此,内存消耗依然是其当前面临的主要问题之一,文献[7]表明传统的视觉词典法处理110万幅的图像仍要占用大约4.3 GB的内存。此外,K-Means及其改进算法(HKM,AKM等)不支持动态扩充[9]。二是视觉单词的同义性和歧义性。由于没有考虑特征点之间的空间关系,基于K-Means及其改进的聚类算法都会导致以下两个问题:(1)聚类中心分布的不均匀特性[10],进而产生由多个视觉单词描绘同一图像特征区域的现象,即造成视觉单词的同义性;(2)偏离聚类中心的数据点会导致聚类中心产生偏移而造成视觉单词的歧义性,即同一个视觉单词描述的特征点之间存在很大差异的现象。对此,研究人员进行了诸多尝试,如文献[11]提出了一种软分配方法(Soft-Assignment,SA)来构建视觉词汇分布直方图,文献[12]则进一步验证了软分配方法对克服视觉单词同义性和歧义性问题的有效性,文献[13]在构建直方图时引入了一种 QP 分配(Quadratic Programming)的策略提高了特征点与视觉单词间的匹配精度。较于传统的硬分配(hard-assignment),它们都能在一定程度上克服视觉单词的同义性和歧义性问题,然而,这些方法都是建立在采用K-Means以及其改进的聚类算法生成的视觉词典基础上的,都不能有效地解决BoVW方法存在的效率问题。此外,当人工界定的目标区域所包含的信息不能正确或不足以表达用户检索意图时同样不能得到理想的检索结果,同时由于对特征点聚类生成视觉词典时存在量化误差,会导致原有特征信息的丢失。为此,文献[14]提出了一种汉明切入(Hamming Embedding,HE)技术,同时证明了几何验证(geometric verification)对提高检索查准率的有效性,但其计算复杂度较高,一般只用作对初始检索结果的重排序,因而导致在提高查准率的同时也降低了查全率,Hsiao等人[15]则利用相关信息反馈过滤目标区域的噪声。
精确欧氏位置敏感哈希[16]是位置敏感哈希LSH(Locality Sensitive Hashing)[17]在欧氏空间的一种实现方案,能够实现快速的大规模高维数据近似近邻查找,它能确保原始空间中距离较近的点,经过映射操作后,能够以较大的概率哈希到同一个桶中,而相距较远的点哈希到同一个桶的概率很小。因此,借鉴该思想,可以采用精确欧氏位置敏感哈希代替传统的K-Means及其改进算法对训练图像库的局部特征点进行聚类,生成一组随机化视觉词典,进而有效地避免多个单词描述同一图像区域和同一单词描述的特征点之间有很大差异的现象。而查询扩展[18]是应用在信息检索中的一种常见技术,其核心思想是指利用计算机语言学、信息学等技术把与原查询相关的概念添加到原查询,得到信息量更为丰富、更为准确的查询模型,它能有效地提高查全率。综上所述,本文提出一种基于随机化视觉词典组和查询扩展的目标检索方法。新方法有效地解决了传统聚类算法带来的高运算复杂度和视觉单词同义性及歧义性问题,并较好地增强了目标的区分性。
本文剩余部分组织如下。第 2节简要介绍了E2LSH的基本定义和哈希原理;第3节给出了基于随机化视觉词典组和查询扩展的目标检索方法涉及的关键技术,其中,着重介绍了基于E2LSH的随机化视觉词典组的生成及由 tf-idf算法分配权重的视觉直方图的构建;第4节对本文方法进行了实验验证和性能分析;最后,第5节为结束语。
2 相关知识
2.1 基本定义
LSH作为众多哈希算法中的一种,是目前解决高维向量近似最近邻问题的最优算法,在图像检索等领域有着广泛的应用。但初始的LSH只适用于汉明空间,而E2LSH是LSH在欧氏空间的一种随机化实现方法,增强了LSH的通用性,其位置敏感哈希函数是基于p-稳定分布的,它对高维稀疏数据具有很好的处理效果,特别是当高维向量中非零数据数目一定时,它的查询时间不变,这个性质是其它算法所没有的。故本文采用E2LSH对图像局部特征点进行哈希,位置敏感函数以及p-稳定分布的定义如下:
定义1 给定点集S中任意点q,v∈S,称函数族H={h:S→U}是位置敏感(locality sensitive)的,其中U为一实数集,如果函数
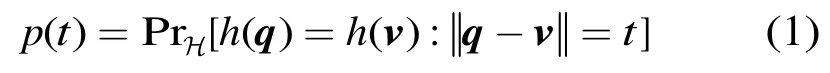
随t严格递减,即点q和v碰撞概率随它们的距离递减。
定义.2 对于一个实数集R上的分布D,如果存在p≥0,对任意n个实数v1,…,vn和n个服从D分布的随机变量X1,…,Xn,使得随机变量 ∑ivi Xi和同分布,则称D为一个p-稳定分布。且对任何p∈[0,2]都存在稳定分布。
2.2 E2LSH哈希原理
具体地,E2LSH中使用的位置敏感哈希函数具有如下形式:
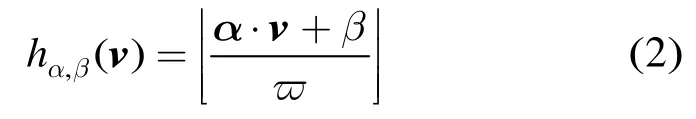

其中g(v)=(h1(v),…,hk(v)),那么,每个数据点v∈,经函数g(v)∈降维映射后,可以得到一个k维向量a=(a1,a2,…ak)。然后,再利用主哈希函数h1和次哈希函数h2对降维后向量进行哈希,建立哈希表并存储数据点,h1和h2定义如下:
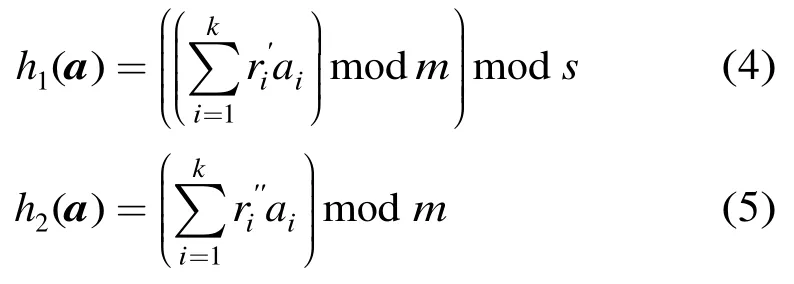
其中和是随机整数,s是哈希表的大小,其取值为数据点的总个数,m为一个大的素数,常取值232-5。E2LSH将主哈希值h1和次哈希值h2都相同的数据点存储在哈希表的同一个桶中,这样就实现了数据点的空间划分。
若将哈希表中每个桶的中心看成一个视觉单词,那么整个哈希表就可看为一个视觉词典,需要指出的是,由于函数g(v)的选取具有一定的随机性,因此通过其建立的视觉词典也带有随机性,本文为了降低这种随机性,从函数族g中选取L个独立的函数g1,…,gL,建立L个独立的视觉词典。
3 基于随机化视觉词典组和查询扩展的目标检索
针对传统聚类算法的效率低及视觉单词同义性和歧义性问题,本文采用E2LSH对训练图像库的局部特征点聚类,得到一个随机化的视觉词典组,并引入查询扩展策略构建信息量更为丰富、准确目标模型,具体流程如图1所示。首先,根据文献[1]的方法提取查询目标和图像数据库中所有图像的SIFT(Scale Invariant Feature Transform)特征,并对其进行E2LSH映射,实现特征点与视觉单词的匹配,得到词频向量;其次,采用tf-idf算法对词频向量重新分配权重,完成视觉词汇分布直方图的构建,并针对传统方法内存消耗大的问题,将图像库的直方图特征存为索引文件,而不再直接对数据进行内存操作;然后,将查询目标的词汇直方图特征与索引文件进行相似性匹配,得到初始结果;最后,综合利用查询目标和初始结果中正确匹配图像的特征信息,并由查询扩展策略构建信息量更为丰富的目标模型,进行二次或多次检索,得到最终结果。

图1 基于本文方法的目标检索流程图
3.1 基于E2LSH的随机化视觉词典组
对于 2.2节函数族g中的每个函数gi(i=1,…,L),利用其分别对训练图像库的SIFT点进行哈希聚类,则每个函数gi都能生成一个视觉词典。那么,利用随机选取的L个哈希函数g1,…,gL就能够生成一个随机化视觉词典组,具体流程如图2所示。其中,单个视觉词典生成的详细过程可描述如下:
(1)训练图像库的SIFT特征提取。为保证实验结果的公正性,本文以目标检索常用的数据库Oxford5K[19]作为训练图像库,并提取包含K个SIFT特征点的图像特征库rK},其中每个点ri都是一个128维的SIFT特征向量;
(2)E2LSH降维映射。对特征库R中的每个SIFT点r,利用函数gi对其进行降维映射,得到k维的向量gi(r);
(3)E2LSH 哈希聚类。按式(4)和式(5)分别计算S I F T 点r的主哈希值h1(gi(r))和次哈希值h2(gi(r)),并将主、次哈希值都相同的点哈希到同一个桶中,生成哈希表,完成特征点的聚类,其中表示哈希表Ti的第k个桶,Ni为哈希表Ti中包含桶的个数。然后计算每个桶的中心即视觉单词,就能得到视觉词典其中
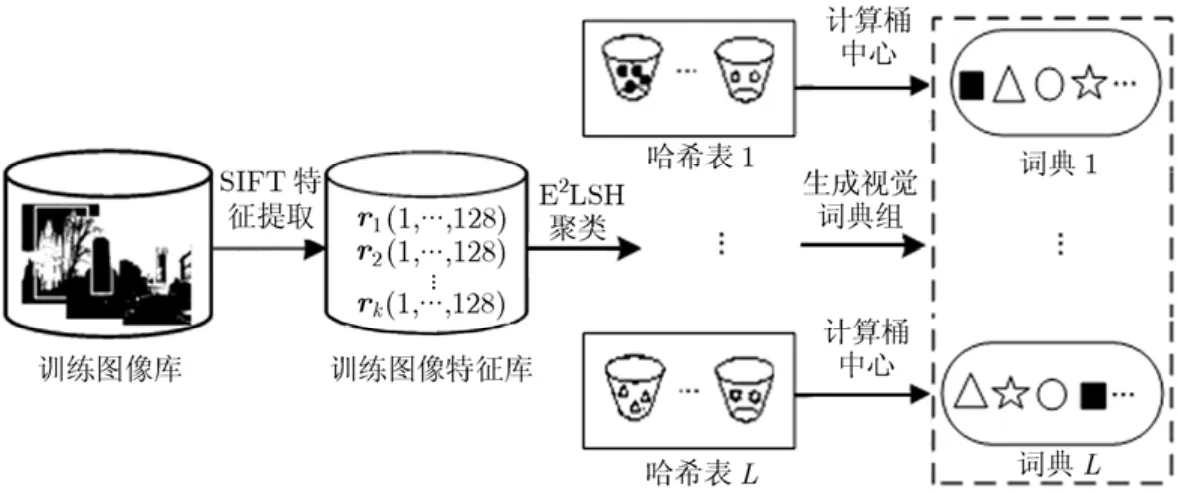
图2 随机化视觉词典组的生成示意图
(4)视觉单词过滤。对于每个视觉词典Wi,包含数据点太少或太多的视觉单词所携带信息的区分性往往不大,因此,在信息损失很小的前提下,可以将这些视觉单词滤除掉,本文为每个视觉词典都保留M个视觉单词,即
由上述过程不难看出,随机化视觉词典组的构造过程是与数据无关的,为了检验E2LSH对数据点的聚类效果,本文将它与 K-Means聚类算法在MATLAB环境下进行仿真对比,结果如图3(a)和图3(b)所示。其中,圆点代表初始数据点,星点代表各聚类中心,对比图3(a)和图3(b)可以看出,KMeans聚类算法在数据点密集的区域聚类中心很多而在稀疏区域的聚类中心很少,而由E2LSH聚类得到的各个桶的中心分布更为均匀。
3.2 视觉词汇分布直方图
对于每幅图像I,检测出其所有的 SIFT特征点,并对特征点进行E2LSH映射,完成特征点与视觉单词的匹配,然后统计其分布情况,则由每个视觉词典都可生成1个M维的视觉词汇分布直方图特征,那么,由文中构造的L个词典就能得到L个M维视觉词汇分布直方图H1,…,HL。其中,单个视觉词汇分布直方图构造方法可描述如下。
对于视觉词典Wi中的任意单词w,定义函数
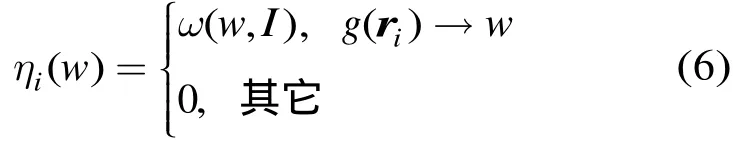
其中ri代表图像I的第i个SIFT点,g(ri)→w表示特征点ri能被哈希到单词w所在的桶,ω(w,I)表示视觉单词w在图像I中所占的权重,其值由 tf-idf算法计算:
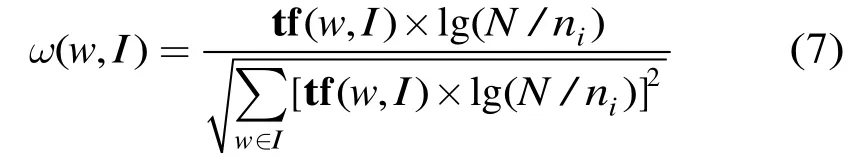
其中tf(w,I)表示单词w在图像I中的词频向量,N为训练图像库的图像总数,ni为图像库中出现单词w的图像数目,分母为归一化因子,那么视觉单词w在图像I中的分布就可表示为
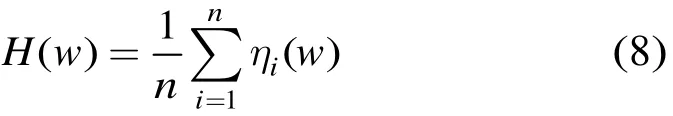
其中n为图像I中总的SIFT点数目,其它视觉单词的分布可同样由上述方法得出,则由视觉词典Wi就能生成M维的视觉词汇分布直方图特征H(H1,H2,…,HM)。

图3 不同算法的聚类效果对比图
3.3 相似性度量和平均查询扩展
由于每个视觉词汇分布直方图特征都可看作是M维的空间向量,因此,本文将采用向量的点乘积来度量两幅图像的相似性。定义相似性度量函数如下:

查询扩展作为相关反馈技术的一种,可以有效地丰富原有查询的信息,构建更为准确的查询模型。由文献[11,18]知,查询扩展有多种方法,综合考虑性能及效率,本文将采用一种平均查询扩展(average query expansion)的方法,对初始检索结果的前N幅相关图像的词频向量作平均,并将其作为查询目标的新词频向量。其定义如下:

其中dq表示初始查询的词频向量即 t f(wj,Q),j=1,…,M,di表示初始检索结果中第i幅图像的词频向量。
4 实验结果与性能分析
本文实验数据采用牛津大学为目标检索及分类提供的Oxford5K[19]数据库,共有5062幅图像。其中,包含55幅标准的查询图像,每个目标选取5幅图像,涵盖了牛津大学的11处标志性建筑。此外,为了验证本文方法在大规模数据下的实验性能,又引入了Flickr1[20]数据库作为干扰项。实验硬件配置为Core 2.6 GHz×2,内存2 G的服务器。性能评价指标为平均查准率均值(Mean Average Precision,MAP)和查全率-查准率曲线,相关的定义如下:

AP(Average Precision)为查准率-查全率曲线所包含的面积,而MAP为5幅查询图像的平均AP值。
由本文中第2节内容,不难得出,参数L取值越大,算法的随机性越小,但算法的效率会随之降低,而参数k则对哈希表中桶的数目具有较大影响。本文以Oxford5K为训练图像库,提取约16334970个特征点,然后采用不同的k,L值的E2LSH对其聚类分别生成不同规模的视觉词典组,并分析其对目标检索结果的影响,如图4所示。其中图4(a)反映了各查询目标的MAP值随哈希表数目的变化情况。图4(b)反映了哈希表中桶个数与k取值之间的关系。综合考虑到算法的精度和效率,本文取L=25,
首先,本文对视觉单词同义性和歧义性问题作简单说明,如图5所示,其中w1-w5表示图像局部特征点的各聚类中心(即视觉单词),数字 1-5表示图像中的局部特征点。由图5可知,特征点3,4,5在空间上距离很近,故可以认为它们表征图像的同一区域内容,而特征点1,3在空间上距离很远,用以表征图像的不同区域。若采用硬分配方法[7],则表示同一区域内容的特征点3,4,5将分别被分配到视觉单词,即产生由多个视觉单词描述同一特征区域的现象,造成视觉单词的同义性,而表示不同区域的1,3将同时被分配到单词w1造成视觉单词的歧义性,而软分配方法[11,12]由于同时将一个特征点分配到与之相近的几个视觉单词,因此可以在一定程度上克服视觉单词的同义性和歧义性问题。本文采用的E2LSH算法在聚类时能将空间中相邻较近点以较大的概率哈希到同一个桶,相距较远的点则几乎不被哈希到同一个桶,因此,特征点3,4,5将以较大的概率分配至同一个视觉单词,而特征点1,3分配至同一单词的概率极小。此外,本文采用多个哈希表构建视觉词典组,在降低E2LSH算法随机性的同时,也能够实现同一特征点与多个距离相近的视觉单词之间的匹配,故采用E2LSH构建随机化视觉词典组能够克服视觉单词的同义性和歧义性问题。
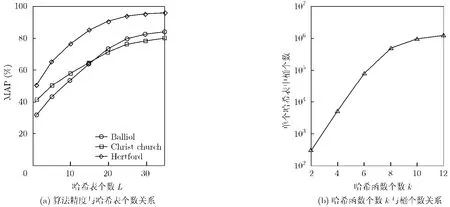
图4 E2LSH参数的影响
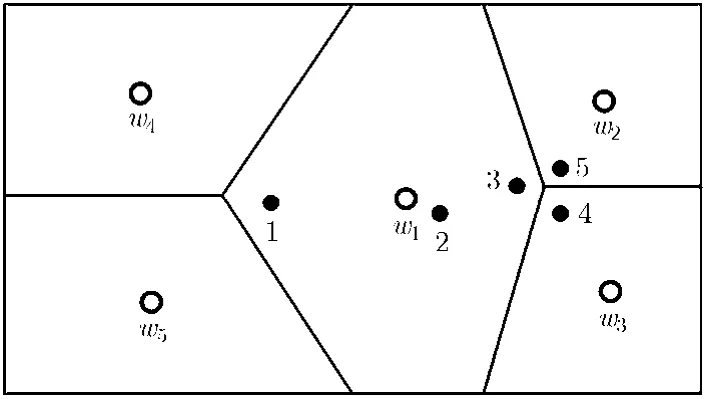
图5 视觉单词同义性和歧义性问题示意图
为了验证采用E2LSH聚类生成一组随机化视觉词典组(Randomized Visual Dictionaries,RVD)并由E2LSH映射完成特征点与视觉单词间匹配的方法对克服视觉单词同义性和歧义性问题的有效性,本文将其与传统的硬分配[7]方法(AKM+HA)和常用的软分配[11,12]方法(AKM+SA)方法作比较,得查全率-查准率曲线如图6所示。其中,硬分配和软分配方法的视觉词典均由AKM算法[7,8]生成,词典规模为106。由图6可知,基于随机化视觉词典组的方法相较于硬分配方法和软分配方法具有更高的检索精度,并且对于初始查全率低而导致查询扩展使用受限的情况效果尤为明显,说明利用E2LSH对特征点聚类能够比较有效地克服视觉单词的同义性和歧义性问题。
然后,将本文方法(Randomized Visual Dictionaries+Query Expansion,RVD+QE)与经典的基于AKM和软分配的方法[11,12](AKM+SA),软分配与查询扩展相结合的的方法(AKM+SA+QE)以及未引入查询扩展的基于随机化视觉词典组(RVD)的方法在 Oxford5K数据库上对部分目标的检索精度作比较,总结了平均查询扩展策略对检索结果的影响,得MAP值如表1所示。从表1结果可以看出,对不同的查询目标而言,AKM+SA方法的平均查准率均值(MAP)均低于其他3种方法。由于随机化视觉词典组较之AKM+SA更能有效地克服视觉单词同义性和歧义性问题,因此,RVD方法的MAP值有所提高,但因RVD方法没有构建信息量更为准确的目标模型,所以与 AKM+SA+QE方法相比略有逊色。而本文方法在随机化视觉词典组的基础上又引入查询扩展策略构建信息量更为准确、丰富的目标模型,其 MAP值均高于其它几种方法。因此,采用查询扩展策略构建目标模型能有效地提高目标检索精度。
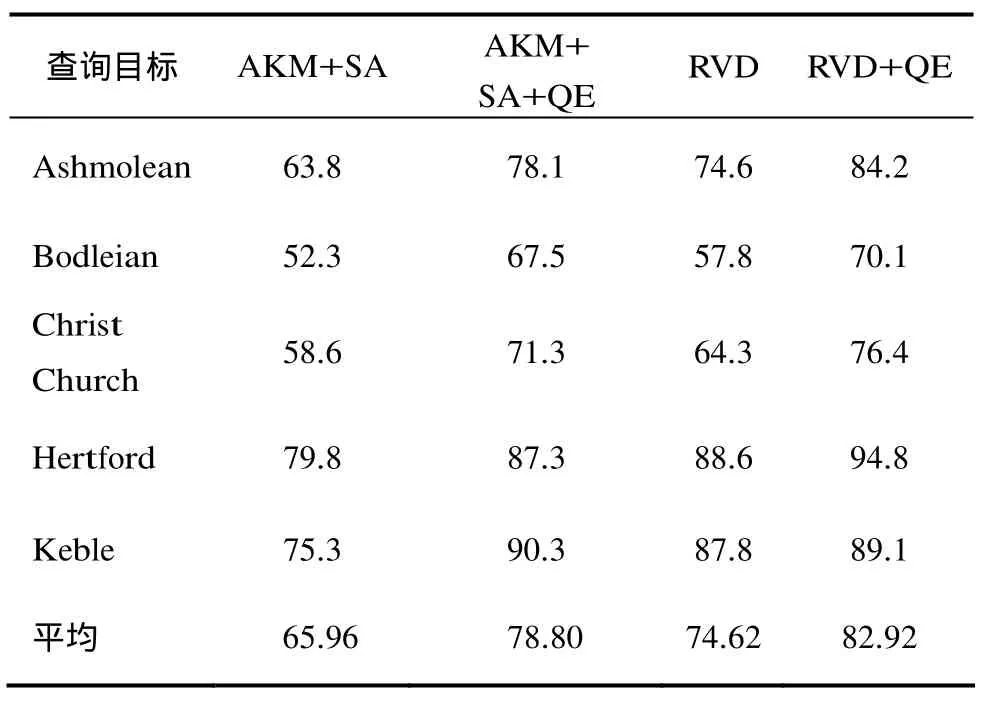
表1 平均查询扩展策略对MAP值的影响(%)

图6 不同方法的查准率-查全率曲线对比
此外,为了验证本文方法在大规模图像库下的有效性,图7给出了本文方法在Oxford5K+Flickr1数据库上的一些目标检索结果样例。其中,上面 5幅 Magdalen图像可由传统的 BoVW 方法检索得到,而下面5幅不易检索的图像可采用本文方法检索得到,可见,采用本文方法能够得到更多包含查询目标的图像。

图7 基于本文方法的Magdale_2目标检索结果
最后,将E2LSH和文献[7,8]的AKM算法在构建视觉词典及特征点与视觉单词匹配时的时间消耗作了对比。首先,从训练图像库中选取500幅图像,提取约 1320000个 SIFT特征点,然后分别采用E2LSH和AKM算法进行聚类生成视觉词典,并分别采用E2LSH映射与硬比对完成特征点与视觉单词的匹配,实验结果如图8所示。从图8 (a)可以看出,随着视觉词典规模增大,两种方法的时间消耗都以近乎对数的形式增加,但由文献[6,16]知,AKM 的时间效率与特征点数的多少成正比,而E2LSH算法则几乎不受特征点数量的影响。从图8(b)可以看出,硬比对方法的量化耗时随着视觉词典规模增大而线性增加,而 E2LSH方法随着视觉词典规模增大,其量化耗时基本保持不变。综合图8(a)和8(b)的对比可知,本文方法在图像规模增大的情况下,依然可以保持较高的时间效率,具有更强的实用性。
5 结束语
本文采用E2LSH算法代替传统的K-Means聚类及其改进算法对训练图像库的局部特征点聚类,生成了一组支持动态扩充的随机化视觉词典组,并在此基础上,利用E2LSH映射构建表征图像内容的视觉词汇直方图特征,并将图像库的特征存为索引文件。此外,为构建信息量更为准确、丰富的目标模型,在初始检索结果的基础上,引入一种平均查询扩展策略完成最终的目标检索。实验结果验证本文方法在一定程度上有效地克服了传统聚类算法带来时间效率低、内存消耗大及视觉单词的同义性和歧义性问题,并较好地增强了目标的区分性,能够取得更好的检索性能。需要指出的是,从硬盘中读取索引文件需要一定的响应时间,而引入的查询扩展策略有时需要多次迭代才能得到较好的效果,因此,也会带来额外的时间开销。所以,研究其它更为高效的目标检索方法仍十分必要。

图8 算法时间复杂度对比
[1]Lowe D G.Distinctive image features from scale-invariant keypoints[J].International Journal of Computer Vision,2004,60(2): 91-110.
[2]Sivic J and Zisserman A.Video Google: a text retrieval approach to object matching in videos[C].Proceedings of 9th IEEE International Conference on Computer Vision,Nice,2003: 1470-1477.
[3]Jurie F and Triggs B.Creating efficient codebooks for visual recognition[C].Proceedings of International Conference on Computer Vision,Beijing,2005: 604-610.
[4]Canada Idée Inc.Reverse image search system.http://www.tineye.com[2011-03].
[5]Google Company.Google goggles.http://www.google.com/mobile/goggles/[2011-03].
[6]Nister D and Stewenius H.Scalable recognition with a vocabulary tree[C].Proceedings of IEEE Conference on Computer Vision and Pattern Recognition,New York,2006:2161-2168.
[7]Philbin J,Chum O,Isard M,et al..Object retrieval with large vocabularies and fast spatial matching[C].IEEE Conference on Computer Vision and Pattern Recognition.Minneapolis,June 17-22,2007: 1-8.
[8]Cao Yang,Wang Chang-hu,Li Zhi-wei,et al..Spatialbag-of-features[C].IEEE Conference on Computer Vision and Pattern Recognition,San Francisco,USA,2010:3352-3359.
[9]Marée R,Denis P,Wehenkel L,et al..Incremental indexing and distributed image search using shared randomized vocabularies[C].Proceedings of MIR’10,Philadelphia,USA,2010: 91-100.
[10]Van Gemert J C,Snoek M,et al..Comparing compact codebooks for visual categorization[J].Computer Vision and Image Understanding,2010,114(4): 450-462.
[11]Philbin J,Chum O,Isard M,et al..Lost in quantization:improving particular object retrieval in large scale image databases[C].IEEE,Conference on Computer Vision and Pattern Recognition,Anchorage,Alaska,USA,June 2009:278-286.
[12]Van Gemert J C,Veenman C J,Smeulders A W M,et al..Visual word ambiguity[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2010,32(7): 1271-1283.
[13]Wang Jing-yan,Li Yong-ping,Zhang Ying,et al..Bag-offeatures based medical image retrieval via multiple assignment and visual words weighting[J].IEEE Transactions on Medical Imaging,2011,30(11): 1996-2011.
[14]Jegou H,Douze M,and Schmid C.Hamming embedding and weak geometric consistency for large scale image search[C].IEEE Conference on European Conference on Computer Vision,Heidelberg,2008: 1-29.
[15]Hsiao J H and Chang H.Topic-sensitive interactive image object retrieval with noise-proof relevance feedback[C].IEEE International Conference on Acoustics,Speech,and Signal Processing,Prague Congress Center,2011: 869-873.
[16]Datar M,Immorlica N,Indyk P,et al..Locality-sensitive hashing scheme based on p-stable distributions[C].Proceedings of the Twentieth Annual Symposium on Computational Geometry,Brooklyn,New York,2004:253-262.
[17]Gionis A,Indyk P,and Motwani R.Similarity search in high dimensions via hashing[C].Proceedings of the 25th International Conference on Very Large Data Bases (VLDB),Edinburgh,Scotland,1999: 518-529.
[18]Sajina R,Aghila G,and Saruladha K.A survey of semantic similarity methods for ontology based information retrieval[C].IEEE Second International Conference on Machine Learning and Computing,Bangalore,India,February,2010: 297-302.
[19]Robotics Research Group.Oxford5K dataset.http://www.robots.ox.ac.uk/_vgg/data/oxbuildings/.[2011-03].
[20]Yahoo Company.Flickr1 dataset.http://www.flickr.com/[2011-03].
猜你喜欢
电脑爱好者(2020年20期)2020-10-22
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
专利代理(2016年1期)2016-05-17
工业设计(2016年8期)2016-04-16
电脑爱好者(2015年13期)2015-09-10
中关村(2014年5期)2014-05-15
电子设计工程(2014年12期)2014-02-27
当代修辞学(2013年4期)2013-01-23
质量与标准化(2010年5期)2010-05-03
