
一种面向网店商品搜索的中文分词系统设计
2012-09-03 08:23:08叶宽余
合肥工业大学学报(自然科学版) 2012年6期
王 敏, 叶宽余, 薛 峰
(1.安徽工商职业学院 工商管理系,安徽 合肥 230041;2.合肥工业大学 计算机与信息学院,安徽 合肥 230009)
0 引 言
在电子商务领域,随着在线商品数量、种类的急剧增加,商品搜索显得越来越重要,而要实现快速、精确的搜索,“分词”是其中最为关键的一步。英文行文以词为单位,词与词之间以空格作为自然分节符,而中文行文则是通过标点、段落等明显的分界符来简单划界,没有一个形式上的分界符对词进行有效、准确的分割,因此对于中文字符串,需要经过特殊的中文分词处理才能进行有效的检索,这就需要研究一套真正适合电子商务网店商品搜索的中文分词系统[1]。
中文分词(Chinese Word Segmentation)指的是将一个汉字序列(如句子)切分成一个一个单独的词,是文本挖掘的基础。近10余年来,中文自动分词研究取得了很大成就,如清华大学的SEGTAG系统、北京航空航天大学的CDWS系统等。主要的分词算法有:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法[2]。基于字符串匹配的分词方法又叫机械分词法,它是按照一定的策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。机械分词从切分程度或切分策略上看,可以分为部分切分和全切分2种,部分切分只取得输入序列的一种或几种可接受的切分形式,全切分则要求获得所有可接受的切分形式[3]。建立在全切分基础上的分词方法从根本上避免切分形式的遗漏,保证分词结果的准确性,但最终的分词结果是否正确和完全,还要依赖于歧义处理方法的选择与设计[4-5]。
“网店商品搜索”是网店为潜在买家开放所有在线商品信息,展示网店数据价值的重要平台。用户可以根据输入的关键词,查询到网店流行趋势以及消费趋势。为了将用户输入的关键词处理成真正体现用户实际意图的最佳商品CPV(类目-属性-属性值)组合,本文结合全切分算法,研究一种面向网店商品搜索的中文分词系统。
首先,设计一种数据结构对网店商品原有的CPV树信息进行加工处理,构成一个相对简洁的词条字典供系统的分词匹配使用。然后,结合全切分算法,实现对用户输入关键词的完全切分,并通过和词条字典匹配得到所有候选的词条组合。同时,为了消除分词过程中的歧义和不合理的词条组合,保证搜索结果的准确性和可靠性,系统结合商品类目树的存储结构,设计了3个过滤算法,并通过引入权值计算的方法对过滤后的词条组合进行排序,得到最佳搜索结果。实验表明利用该方法,比较好地处理了全切分算法中的歧义问题,商品搜索中分词匹配的准确性和速度也明显提高[6-7]。
1 系统主流程设计
分词算法分为4个功能模块,如图1所示。
(1)词表初始化模块。为提高全切分算法的匹配效率,设计词条数据结构对原CPV树进行简化处理,形成词条字典;设计类目节点和属性/属性值节点数据结构保存原CPV树的节点信息,为系统的过滤算法和权值计算提供有效数据。
(2)全切分模块。应用全切分算法对用户输入的字符串进行完全切分,再和词条字典进行匹配,留下匹配成功的词条组合。
(3)Filter模块。根据CPV树中类目、属性和属性值的逻辑关系,设计3个过滤方法去掉商品类目树中歧义和不合理的词条组合。
(4)权值计算模块。根据分词匹配的准确度以及词条中类目和属性的权重计算出词条组合的权值,选出最佳词条组合,分词成功。
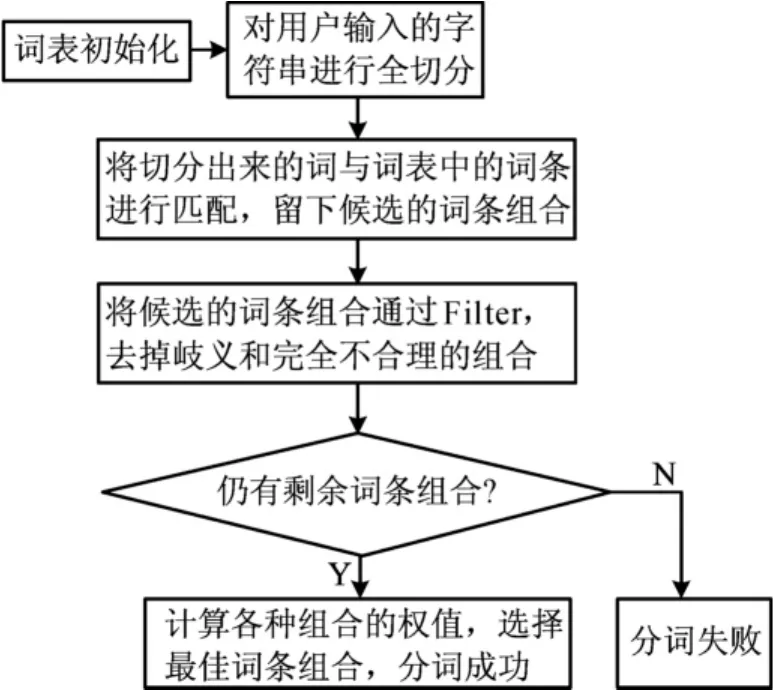
图1 系统主流程图
1.1 词表初始化模块
1.1.1 网店商品的类目管理
一个大型电子商务网店的在线商品数有时会达到亿以上,类目管理相当巨大。这时,为了便于快速查询和合理利用存储空间,通常将其类目体系分为3个层次:类目(C),商品分类;属性(P),描述特征含义的名字;属性值(V),具体的一个特征值。所有类目采用具有树形关系的存储结构,简称CPV树,CPV树可通过某些自动化算法生成,也可基于人工方法生成,它们的关系如图2所示。根节点Root将所有一级类目关联到一起,前几层为类目,上下级类目是继承关系,类目和属性值都可以拥有属性,每个属性总属于某个类目,一个类目可具有多个属性,但规定只有叶子类目才可以拥有属性,一个属性可以有多个属性值,但属性P与属性值V总是成对出现。
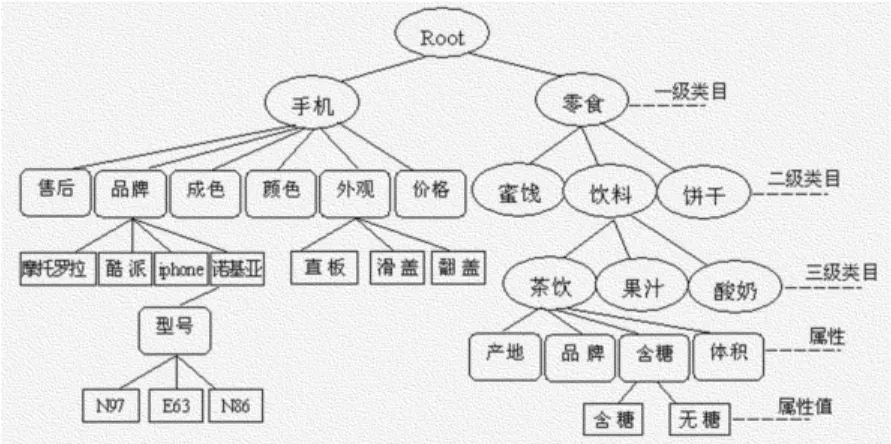
图2 CPV树示意图
1.1.2 词条数据结构
网店中的CPV树以文本形式存储,每一行的数据从左往右分别表示节点ID、节点类型、节点级别、父节点ID、子节点ID、类目ID、类目名称、属性ID、属性名称、属性值ID、属性值名称、类目属性级别、状态标记串。
CPV树存储了所有商品信息,是全切分词进行匹配的原始数据,但这种存储形式中含有很多冗余数据,加上该文件含有上百万条的数据,匹配效率会很低。因此,需要重新设计一个精简的表1所列的数据结构来存储各个词条信息,所有的词条信息构成一个新的数据词典。

表1 词条lexeme的成员变量
1.1.3 CPV树节点数据结构
系统在成功匹配后会存留一些有歧义的词条组合需要剔除,为了判断这点,需要设计一个数据结构来保存CPV树的所有节点信息。首先,利用一个HashMap〈long,List〉来存储所有类目节点的信息,long为类目ID(cid),List中存储了类目节点的具体信息。List的第1个元素为一个String,保存类目的名称cname;第2个元素为一个HashSet,记录了这个类目所有的上级类目;最后一个元素long则记录了该类目拥有多少个属性,用于计算节点的权重。
同理,再利用一个 HashMap〈long,List〉来存储所有属性/属性值节点的信息,long为属性ID(pid),List中存储了该属性节点的具体信息。List的第1个元素是一个String,保存了属性的名称pname;第3个元素记录了该节点可以挂在多少个类目下,同样是用于计算节点的权重;第2个元素又是一个 HashMap〈long,List〉,用来保存该属性节点所拥有的所有属性值节点的信息,long为该属性值的ID,List中保存了该属性值名称vname以及该属性/属性值组合所属的叶子类目的ID。
1.1.4 词表初始化
词表的构造是本文分词算法的前提,构造词表的过程为:
(1)读入含冗余信息的CPV树信息。
(2)对CPV树信息进行精简处理,将其转换成一个个词条(lexeme)。
(3)在创建词条的同时,更新并保存CPV树中所有节点的信息,采用1.1.3中类目节点和属性/属性值节点设置的数据结构。
(4)计算一个类目下最多挂有多少属性/属性值节点,同时计算一个属性/属性值节点最多能被多少个类目拥有,按一定的规则预先设定权值并更新词条(lexeme)的权重信息。
1.2 全切分模块
全切分模块的过程如图3所示,首先接收用户输入字符串,然后选择切分点切分字符串,再进行词典匹配,匹配成功,保留切分结果,匹配不成功,不保留切分结果,继续进行下一次切分,直至完成切分。全切分过程的关键是切分点的选择,该过程的核心算法如下:
(1)计算字符串长度,假设长度为n,则一个与该字符串长度相同的二进制串的取值范围为0~(2n-1)。
(2)记切分点个数为x(起始为0),计算0~(2n-1)之间所有数字长度为n的二进制串形式,判断每个二进制串中“1”的个数是否为x,是则保留该二进制串。
(3)判断所保留的二进制串中“1”所在的位置,以该位置作为切分点对字符串进行切分。
(4)若x<n,则令x=x+1,继续步骤(2)。

图3 全切分流程图
1.3 Filter模块的设计
对用户输入的字符串进行切分,并在词条词典中匹配会得到若干类目词条和属性词条,将这些词条相互组合后,会有一些歧义和不合理的组合,需要将其排除。为此,系统设计了3个Filter模块,用于过滤那些完全不合理的组合,以提高分词系统的准确率。
(1)Filter_MoreThanOneC():用于去除有多个cid的词条组合。在CPV的组合中,不能存在多个cid,否则该组合就是无效的。
(2)Filter-SameP-Different-V():CPV 中属性和属性值总是成对出现的,因此,对于某个属性,如果包含多个属性值,也是不合理的,这样的组合也要过滤掉。
(3)Filter-NotleafNotPutin():判断组合的词条在CPV树上是否存在父子关系,如果一个叶子类目和另一个叶子类目下的属性组合了,也需要过滤掉。
1.4 权重计算模块
词条组合经过过滤,大大提高了搜索结果的准确性,但过滤后的词条可能数目较多,排列混乱,不利于用户的直接应用。因此,为了进一步优化分词结果,选出最佳的词条组合,设计了权值计算的方法,权重信息分可为3个方面。
(1)分出词的匹配度。记Pn=当前组合分出词的个数/分出最多词的个数。
(2)分词中字的匹配度。记Pm=匹配出来词的字数/用户输入的字数。
(3)词条权重。在1.1初始化词表的时候,每个词条都赋予了一个权重,记该组合中每个词条的权重分别为:P1,P2,…,PN,词条权值是它们的平均值,即Pi= (P1+P2+…+PN)/N。
最后,设定总权重W =PnaPmbPic,其中引入3个参数a、b、c,是为了能灵活调整Pn、Pm、Pi3个值所占的比重。为了确定a、b、c这3个参数的最佳值,设计了一个评估函数,该函数利用一个设计好的评估测试集,动态地调整a、b、c三者的值,记录下分词效果最佳时各个参数的值。该评估函数在判断分词效果优劣的时候考虑了2点:一是分词结果和测试集中结果完全符合的个数;二是如果不符合,它们之间的相近程度有多少。
2 实验结果与分析
(1)用户输入字符串,算法提交后,返回分词后的结果。例如用户输入“红色手机”,返回的结果是:{“cate”:{“id”:1512,“name”:“手机”},“value”:{“1”:{“id”:28326,“name”;“红色”}},“property”:{“1”:{“id”:16270207,“name”:“颜色分类”}}}。cate中包含类目id和类目名称,只允许存在一个类目;value中为属性值id和属性值名称;property中是属性id和属性名称,属性/属性值可以存在多个,但必须成对出现。
(2)系统实验中可以查看分词过程中的处理数据。例如,当输入“红色手机”,由全切分算法将其切分成“红色/手机”和“红/手机”这2种情况,计算词匹配度、字匹配度和每个词条自身的权值,根据公式计算出总权值,并按总权值进行排序,处理结果见表2~表4所列。
全切分后的分词结果:① 红色/手机;② 红/手机。所有匹配情况和对应的总权值为:
情况1:词匹配度2/2=1.0,字匹配度4/4=1.0,总权值0.9;情况2:词匹配度2/2=1.0,字匹配度4/4=1.0,总权值0.55;情况3:词匹配度2/2=1.0,字匹配度4/4=1.0,总权值0.55。

表2 情况1处理结果

表3 情况2处理结果

表4 情况3处理结果
3 结束语
全切分算法是一种常用的分词算法,其核心问题是歧义的识别与处理,本文为了消除分词结果中的歧义和不合理词条组合,保证搜索结果的准确性和可靠性,在重新设计网店商品数据结构的基础上,进行词条字典匹配,并设计了3个过滤算法,有效地解决了全切分算法中的缺点和不足。此外,为了使得搜索结果更符合用户意图,系统引入了权值计算的方法对搜索结果进行排序,获取最佳结果。实验表明利用该方法,网店商品搜索中分词匹配的准确性和速度明显提高,实用性更强。虽然本系统中对分词算法的改进已经达到了一定效果,但还有很大的提升空间,比如可以对词表进行一定的处理,用一定的规则将一些无关紧要的词条排除掉,以提高分词的准确性和速度;此外,当前处理同义词和一些特殊情况的方法还不够丰富,有待进一步的研究[8]。
[1]王显芳,杜利民.一种能够检测所有交叉歧义的汉语分词算法[J].电子学报,2004,32(1):50-54.
[2]万建成,杨春花.书面汉语的全切分分词算法模型[J].小型微型计算机系统,2006,24(7):1247-1251.
[3]Zhang Maoyuan,Lu Zhengding.A Chinese word segmentation based on language situation in processing ambiguous words[J].Inf Sci,2004,162(3/4):275-285.
[4]曹勇刚,曹羽中.面向信息检索的自适应中文分词系统[J].软件工程,2006,17(3):356-363.
[5]许高建,胡学钢,路 遥,等.一种改进的中文分词歧义消除算法研究[J].合肥工业大学学报:自然科学版,2008,31(10):1622-1625.
[6]Manning C,Schütze H.统计自然语言处理基础[M].苑春法,李 伟,李庆中,译.北京:电子工业出版社,2005:45-50.
[7]Luo Zhengqing,Chen Zengwu,Hu Shangxw.A revised MMalgorithMof Chinese automatic words segmentation [J].Journal of Chinese Information Processing,1996,10(3):30-36.
[8]欧阳一鸣,周 强,胡学钢,等.数据挖掘中动态改变样本域提高预测精度 [J].合肥工业大学学报:自然科学版,2006,29(4):395-398.
猜你喜欢
中学生数理化·七年级数学人教版(2020年9期)2020-11-16 01:18:36
中国外汇(2019年12期)2019-10-10 07:26:58
疯狂英语·新悦读(2017年2期)2017-04-08 01:31:27
海南师范大学学报(社会科学版)(2015年7期)2015-12-28 08:17:40
图书馆学刊(2015年11期)2015-02-12 17:16:27
图书馆论坛(2015年2期)2015-01-03 01:43:00
燕山大学学报(2014年1期)2014-03-11 15:28:11
图书馆理论与实践(2013年3期)2013-04-27 05:39:56
测绘科学与工程(2013年6期)2013-03-11 15:07:57
网络安全与数据管理(2011年17期)2011-07-25 00:33:50
