
Chord路由算法的分析与改进
2012-08-15 02:03张亚松
网络安全与数据管理 2012年8期
张亚松
(武汉理工大学 计算机科学与技术学院,湖北 武汉430063)
高效的查找资源决定了P2P网络的性能,是P2P网络研究的重点。Chord[1]是MIT提出的基于分布式哈希表DHT(Distributed Hash Table)的资源搜索算法,在可扩展性和查找确定性方面都有比较好的表现,其他的系统还有 Pastry[2]、CAN[3]和 Tapestry[4]。 Chord 可 以 保 证 在 log2N跳数之内找到所需要的资源,但其存在路由表信息冗余以及逻辑网络与物理网络不匹配的问题,导致查找效率不高。
为了解决上述两个问题,在Chord的基础上,本文提出了一种改进的Chord路由算法。该算法将路由表中重复的路由信息删除,加入原始路由表中覆盖不到的半环的路由信息;为每个节点增加邻居表,邻居表中记录了本节点附近节点的物理位置信息。通过邻居表路由过程不再是由指针表单独决定,而是由指针表和邻居表共同决定。这样既消除了原路由表中的冗余信息,又增大了路由表的覆盖度,也解决了逻辑网络和物理网络不匹配的问题,从而提高了查找效率,降低了平均路由延迟。
1 Chord路由算法
Chord是MIT提出的基于DHT的资源搜索算法,平均路由跳数一般在log2N/2之内。在Chord系统中,节点和关键字都有一个m位的标识符,每个节点的ID可以通过对IP进行哈希运算得到。所有节点按照ID从小到大沿顺时针方向排列成一个逻辑的标识圆环(Chord环)。节点的资源关键字标识符K通过对关键字本身进行哈希运算得到。关键字标识符K存放在节点ID=K或者ID=min{ID-K;ID-K>0}这样的节点上。Chord中每个节点都有一个路由表,路由表有m条记录,其中第i条记录记录了在Chord中和该节点的距离大于等于2i-1(i∈[1,m])的最近节点。显然,路由表只能覆盖从本节点开始的半个环的区域。
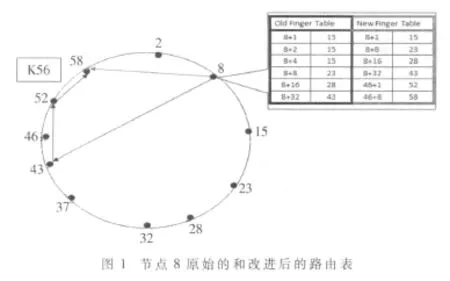
如图1所示,当节点8要查找 K56时,首先判断自身ID等于8而非56;然后检查K56没有落在本节点和它的后继节点之间,即 56 不在[9,15]、[16,23]、[24,28]和[40,43]区间内;然后查找路由表,找到表中最大且小于K56的节点43,把请求转发到节点43。重复此过程,请求转发到52,找到存放K56的后继节点58,把请求转发到节点58,查找结束。查找过程为8→43→52→58。
2 改进的Chord路由算法
从图1以及路由表的构造可知,路由表中存在冗余路由信息,并且由Chord环构造的逻辑网络和物理网络没有任何关联,所以导致了平均查找跳数和平均路由延时的增加。因此,应该从这两个方面对路由算法进行改进,即对指针表(Finger Table)进行修改以及增加邻居表(Neighbour Table)。
2.1 修改指针表
如图1所示,从以节点8为初始节点的路由表可以看出,有两条冗余的路由信息。假设Chord环的大小为M=2m,节点数 N=2n(n<m),所有节点平均分布,节点平均冗余路由信息数量为log2(2m/2n)=m-n[5]。因为相对于大小为M的标志符空间,N个节点相对比较稀少,导致节点和它的后继节点之间的间隔大于1,所以出现冗余路由信息无可避免。
从路由表的构造可以看出,路由表可以覆盖从本节点开始的一半Chord环,当要查找的K存储在另一半Chord环时,就需要更多的跳数来完成。由于路由表中每个节点平均有m-n条冗余路由信息,所以可以把冗余的路由信息删除。如果可以用有效的路由信息替代冗余的路由信息,使路由表可以覆盖更大的范围,那么必然会降低查找的平均跳数,从而提高查找效率。
假设本节点为N,新的指针表的构造方法如下:
(1)用原指针表的构造方法,构造m条路由信息,从中删除重复的路由信息,假设重复的记录数量为P。
(2)找到指针表中最大的后继节点(图1中的43),然后找到此后继节点的直接后继节点 D(图1中的46)。
(3)以节点D为起点,构造D的指针表,从上到下选择P条不重复的路由信息,将其增加到(1)中构造的节点N的指针表后面。
(4)删除D的指针表。
由以上构造方法及图1中的New Finger Table可知,新的指针表可以覆盖原指针表覆盖不到的另一半Chord环的绝大部分空间,从而指针表查找的范围增大,平均查找跳数自然降低了。在新的指针表中,当节点8要查找K56时,只需要一条就可以找到存储K56的节点58,即 8→58。
2.2 增加邻居表
节点的邻居表主要用来存放在物理网络中相距比较近的节点信息。邻居表的表项是<ID,IP>这样的键值对。邻居表的表项信息可以利用界标簇算法[6]和往返延迟RTT(Round Trip Time)测量技术收集。利用这种测量方法可以把在物理上距离本节点比较近的节点信息加入自己的邻居表。为了保证有效性,系统中的每个节点定时地测量距邻居节点的距离。因为Chord环中的节点不断地加入和离开,所以当邻居表表项达到最大时,应该删除表中距本节点物理距离最远的点。
本节点和邻居节点一起称为一个单元,在单元中选取一个处理能力比较强的作为超级节点,单元中的节点一旦查询结束就把查询结果发送给超级节点进行缓存。对缓存信息的管理可以采用先入先出、最近最少使用的策略,这样在下次查询时,可以保证在两跳之内找到资源。
2.3 路由查找算法
假设本节点为ID=N,需要定位的资源为K,在修改了指针表,增加了邻居表以及超级节点时,改进的资源搜索过程如下:
(1)首先检查N是否等于K,如果相等直接返回本节点的IP地址,搜索结束;如果不相等继续步骤(2)。
(2)查找节点N的指针表,看是否存在节点标识符等于K的后继节点,如果存在,直接返回该后继节点的IP地址,搜索结束;否则,继续步骤(3)。
(3)如果节点N是超级节点,检查是否存在K的记录,如果存在,搜索结束;否则,继续步骤(4);如果 N不是超级节点,把请求转发至超级节点。
(4)查找节点N的指针表和邻居表,分别找到最接近K的节点 N1和 N2,比较 N1和 N2,选择物理距离与 K较近的一个作为下一跳的节点,将搜索请求转发到这个节点上。
通过上述过程搜索到所需要的资源后,主动上传资源的定位信息到超级节点,保存在缓存中,这样下次搜索时就可以迅速地定位了。
3 仿真实验与结果分析
在Linux系统下,采用P2PSim仿真平台对原Chord协议和改进后的Chord协议进行了实验。实验中主要对平均查找跳数和平均路由延迟这两方面进行了比较。实验对 10 组(256,512,1 024,2 048,4 096,6 000,8 192,10 000,13 000,16 384)数据都进行采样,设定 M=224,每个节点平均随机请求4次,对平均查找跳数和平均路由时延进行统计,得到的统计图如图2和图3所示。实验结果进一步说明了改进后的Chord协议因为增大了指针表的覆盖范围,并且考虑了物理网络与逻辑网络的差异,所以在平均查找跳数和平均路由延时方面都有一定程度的降低,提高了查询的效率。

本文针对原Chord协议指针表信息冗余,只能覆盖Chord环一半范围的缺点,删除了冗余路由信息,添加了有效的路由信息,扩大了指针表的覆盖范围。针对逻辑网络与物理网络不匹配的问题,在Chord协议中增加了邻居表,使节点在路由时可以选择物理距离相对比较近的节点进行转发请求。总体来说改进后的Chord协议的平均查找跳数和平均路由延时都有一定的降低,提高了查找效率。
[1]STOICA I,MORRIS R,KARGER D,et al.Chord:a scalable peer-to-peer lookup protocol for internet applications[C].Procedings of ACM SIGCOMM 2001,New York,USA:ACM Press,2001:149-160.
[2]ROWSTRON A,DRUSCHEL P.Pastry:scalable distributed object location and routing for large-scale peer-to-peer systems[C].18th IFIP/ACM Int Conference on Distributed System Platforms,2001:329-350.
[3]RATNASAMY S,FRANCIS P,HANDLEY M,et al.A scalable content-addressable network[C].Govindan R.Proc of the ACM SIGCOMM.New York:ACM Press,2001:161-172.
[4]Zhao B Y,Huang Ling,STRIBLING J,et al.Tapestry:a resilient global-scale overlay for service deployment[J].IEEE Journal on Selected Areas in Communications,2004,22(1):41-53.
[5]CASTRO M,DRUSCHEL P,HU Y C,et al.Exploiting network proximity in peer-to-peer overlay networks[R].Technical Report MSR-TR-2002-82,2002.
[6]Wang Biqing.Research and improvement of Chord routing algorithm[J].Computer Engineering and Applications,2010,46(14):112-114.
猜你喜欢
湖北第二师范学院学报(2020年2期)2020-06-05
魅力中国(2019年37期)2019-10-21
计算机技术与发展(2019年9期)2019-09-28
现代电子技术(2017年7期)2017-04-14
湖南教育(2017年3期)2017-02-14
贵州工程应用技术学院学报(2016年3期)2016-08-19
东北师大学报(自然科学版)(2016年2期)2016-06-30
电脑知识与技术(2016年7期)2016-05-19
科技资讯(2014年26期)2014-12-03
中国教育网络(2011年1期)2011-09-25
