
基于时变Copula理论的金融危机传染效应存在性研究——以2008年全球金融危机为例
2012-07-25 00:48李堪
世界经济与政治论坛 2012年2期
李 堪
“金融危机传染效应”(Financial Contagion Effect)是指当一个国家的金融市场出现过度动荡时,通过一定传导渠道波及其他国家的金融市场,这种波动的“传染效应”在相关性密切的金融市场之间较大。纵观历次金融危机,尤其是最近30年以来的金融危机,都表现出较强的“危机传染效应”,“金融危机传染效应”逐渐成为金融领域研究人员的焦点。理论界对金融危机“传染效应”的存在已经取得一致共识:金融危机具有国际性的传播影响;然而对金融危机传染的内涵却无定论。
世界银行对金融危机传染做出定义:通过计算两个金融市场之间在非危机时期和危机时期的影响概率来判断,如果危机时期两市场的条件相关影响概率大,那么表明两个市场之间存在着一定程度的金融危机传染。本文研究采用世行的定义,即金融危机传染是金融危机在国家间通过任何路径的扩散、蔓延现象。
在金融危机传染的研究文献中,应用传统检测方法的研究较多。直到最近采用Copula函数的方法来研究金融危机传染的文献才逐渐增多。Arakelian和Dellaportas①Arakelian V,Dellaportas P.Contagion tests via Copula threshold models.Working Paper,University of Athens,2006建立了门限Copula函数模型,通过检测市场间的相关结构或相关模式的变化来检测是否发生金融危机传染。Rodriguez①Rodriguez J C.Measuring financial contagion:A Copula approach.Journal of Empirical Finance 2007(14):401-423采用变参数Copula模型,Samitas②Samitas A.Kenourgios D.Paltalidis N.Financial crises and stock market dependence.Working Paper,University of the Aegean,2007等采用多变量的基于马尔科夫转换机制的Copula模型,研究了金融危机传染效应。从Copula模型检验方法的文献来看,Copula模型多为变结构Copula模型或者状态转移Copula模型,由于不同学者研究对象的不同以及对象的时间不同,得出的结论不尽一致。
国内学术界对金融危机传染的研究相对是较晚的,直到进入21世纪后才逐渐有学者对该问题展开了理论研究和实证研究。在研究初期,国内学者研究方法也从传统的检验方法入手,随着国内计量经济学的发展,一些国际上较前沿的方法也逐渐被应用于实证研究。韦艳华、齐树天③韦艳华,齐树天.亚洲新兴市场金融危机传染问题研究:基于Copula理论的检验方法.国际金融研究,2008(9):22-29采用Copula理论研究了亚洲金融危机时期的金融危机传染问题。王磊④王磊.基于条件Copula模型的股票市场间的危机传染效应研究(硕士学位论文).厦门大学,2009采用样本分段的形式建立了Copula函数模型,实证分析了亚洲金融危机时期和美国次贷危机时期美国、英国、台湾的股票市场的相关结构。
对于2008年金融危机时期国外股票市场是否对我国股票市场产生危机传染,国内学者的研究结果不尽一致。赵丽琴⑤赵丽琴.基于Copula函数的金融风险度量研究(博士学位论文).厦门大学,2009采用Copula理论研究了2008年金融危机对“金砖四国”的金融危机传染效应,实证发现美国金融危机对巴西、印度、俄罗斯的金融市场具有明显的危机传染效应,而对于中国的股票市场并没有明显的危机传染效应。陈奕播⑥陈奕播.基于Copula方法的金融危机传染模型与应用研究(硕士学位论文).电子科技大学,2009通过建立Copula模型分析了上证指数和美国股指的相关结构也得出了类似的结论:金融危机对中国股票市场的传染效应并不显著。
然而,叶五一、缪柏其⑦叶五一,缪柏其.基于Copula变点检测的美国次级债金融危机传染分析.中国管理科学,2009,17(3):1-7采用了变点检测的Copula模型对2008年金融危机的传染效应作了研究,通过分段建立变结构的Copula模型结果发现在金融危机爆发时期,亚洲主要股票市场或多或少地受到了美国次贷危机的影响,存在金融危机的传染效应。孙彬①孙彬,杨朝军,于静.基于Copula函数的国际证券市场传染效应实证分析.上海交通大学学报,2009(4):544-549等采用Copula函数的方法考察了美国次贷危机时期与平稳期的亚洲证券市场的相关结构和相关模式的变化,结果发现无论从收益率水平还是波动方面的研究都证实了美国次贷危机对亚洲证券市场存在着金融危机传染效应。于建科、韩靓②于建科,韩靓.次贷危机中国传染效应实证研究——基于Copula的非参数检验.未来与发展,2009(5):19-22采用Copula函数也同样研究了金融危机时期中美股市的相关结构的变化,从而研究金融危机的传染问题,通过实证他们也认为在金融危机时期中美股市的相关性趋于增强。
纵观国内外诸多学者的成果发现金融危机传染问题仍然有研究空间。首先是研究对象上,国内外学者对发达国家之间金融危机传染研究相对多,而对发达国家和发展中国家的危机传染问题研究相对少,同时研究对象中包括中国金融市场的研究文献也很少;国内外学者对较早发生的金融危机研究较多,而对2008年由美国次贷危机引起的金融危机时期的传染问题研究还较少。其次是研究方法上,较早期的研究中学者多采用传统的检验方法,近期的学者才逐渐采用Copula模型的检验方法,从采用Copula模型方法的文献中,可以发现学者多采用的是分阶段的静态Copula模型、变结构Copula模型或者状态转移Copula模型,而没有采用时变动态Copula模型,我们认为采用动态的视角来研究金融危机传染问题更为合理。采用动态的视角来研究金融危机传染效应,也就是采用动态时变Copula模型来研究,这样也就避免了研究数据分段的不同对结果产生的影响。
基于此,本文认为在建立边缘分布函数模型时,采用非参数估计方法避免了因为选取分布函数的不同从而对研究结果产生的影响;在建立Copula模型时,采用时变Copula模型从而避免了对研究对象的分段处理对研究结果产生的影响。本文将按照该模型构建思想逐步展开,并实证研究2008年金融危机时期中国与其他国家的金融危机传染效应存在性问题。
时变Copula函数理论
在建立时变Copula模型时,必须根据Copula理论从相关的指标中选取一个具有明确经济意义,且能够与Copula函数中相关参数具有一一对应关系的指标作为桥梁,通过确定该指标的动态时变演化方程来反映Copula函数参数的动态时变过程,从而达到刻画动态相依结构的目的。
1.时变二元正态Copula模型相关系数
Patton(2001)将二元正态Copula函数的参数的演化方程用一个类似于ARMA(1,10)的过程来描述,即:
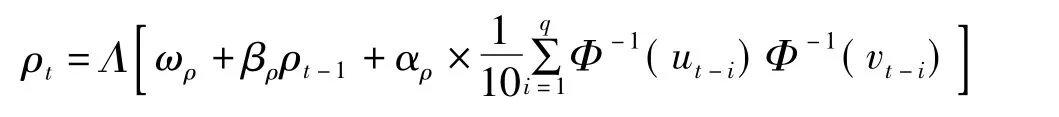
二元正态Copula函数作为一种椭圆族Copula函数,其分布具有对称性和尾部渐进独立性,因此无法捕捉到随机变量之间的非对称的相关关系和非对称的尾部相依结构。
2.时变二元t-Copula模型相关系数
一般而言,对于t-Copula函数,多假设自由度不随着时间的变化而推移,因为自由度的具体经济意义不是十分明确,并且影响自由度变化的因素也较难确定,因此,构建自由度的时变演化方程的意义不大。
时变t-Copula模型的相关系数的演化方程也可以根据Engle(2002)、Tse和Tsui(2002)的思想来构建。其方程形式与正态Copula模型的相关系数演化方程一样。如果按照Engle(2002)的思想构建参数的动态演化方程可以表示为DCC(1,1),即:

t-Copula函数也一种椭圆族Copula函数,其分布具有对称性和尾部渐进独立性,因此也无法捕捉到随机变量之间的非对称的动态相关关系和非对称的动态尾部相依结构。
(3)时变二元Clayton Copula模型和时变SJC-Copula模型相关系数
Clayton Copula函数在描述下尾相关特性的金融市场时优势明显,在分析熊市行情时,能够准确描述股票市场之间的相关结构以及股票价格之间的相关结构。如当一个股票市场或一支股票价格表现出暴跌时,另一个股票市场或其他股票价格也出现暴跌的可能性较大,这样的相关结构就可以用Clayton Copula函数的下尾部相关系数很好地刻画出来。因此我们在研究金融危机传染效应时,主要采用的阿基米德Copula函数是Clayton Copula函数和Symmetrized Joe-Clayton Copula函数(SJC Copula函数)。
对于Clayton Copula函数,函数中的参数并没有具体的经济意义,只是从数值上反映相关关系,因此我们主要构建Kendall的时变演化方程来反映随机变量的动态相依结构。根据Patton(2006)建立时变Copula模型相关系数演化方程的思想,我们可以建立时变二元Clayton Copula函数的Kendall的秩相关系数的动态演化方程:
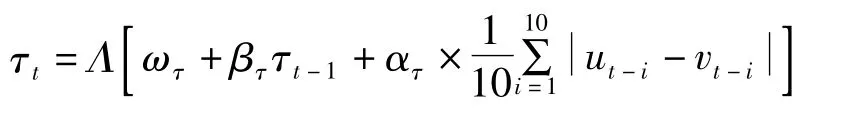
其中函数 Λ 为 Logistic转换函数:Λ(x)=(1+e-x)-1,该函数保证了Kendall的秩相关系数 τ∈(0,1)。
Joe(1997)提出了Joe-Clayton Copula函数,Joe-Clayton Copula函数的相关参数也不具有明确的经济意义,然而其相关参数与条件尾部相关系数存在一一对应的相互关系。两个变量之间的Copula函数为C(u,v),λU和λL分别为X和Y的上尾和下尾相关系数(假定极限存在),那么有:
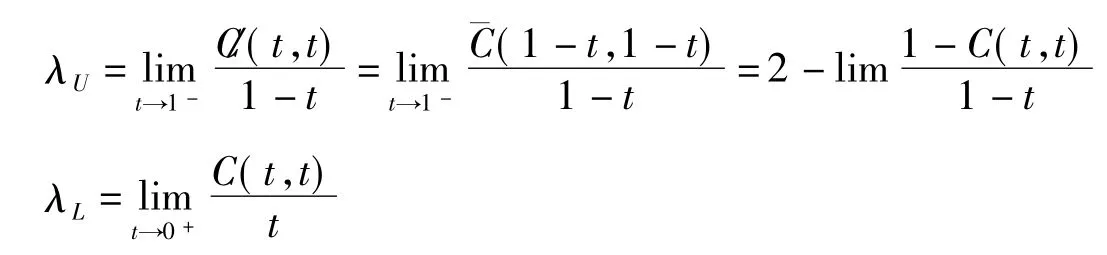
由上式可以发现,Joe-Clayton Copula函数的条件上尾相关系数完全由参数κ来决定,而其条件下尾相关系数完全由相关参数来决定。因此我们可以构建时变Joe-Clayton Copula函数的条件尾部相关系数的动态演化方程来刻画随机变量的动态相依结构。依据Patton(2006)的构建时变Copula模型演化方程的思想可以得到时变Joe-Clayton Copula函数的条件尾部相关系数的动态演化方程:
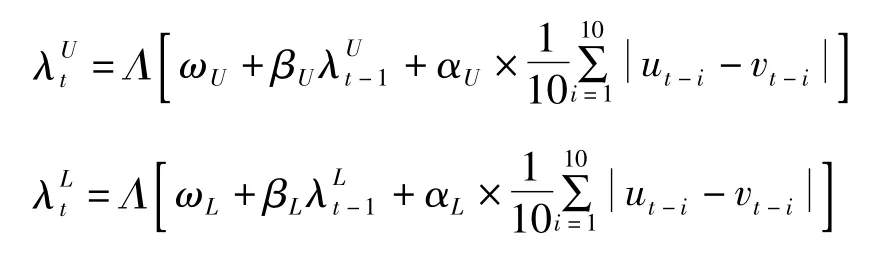
其中函数为Logistic转换函数:Λ(x)=(1+e-x)-1,该函数保证了条件尾部相关系数都处于之内。尾部相关系数演化方程的最后一项将滞后q期内概率积分变换后的变量的差的绝对值作为外生变量,作为度量数据与完全正相关之间距离的指标。
金融危机传染效应实证分析
本文应用上述动态Copula函数研究金融危机时期金融危机传染效应的存在,主要研究美国和英国股票市场对中国大陆股票市场的传染效应的存在,主要选取了中国大陆股市(沪深300指数)、欧洲股票市场(英国FTSE100指数)、美国股票市场(美国S&P500指数)。由于金融危机传染效应存在于危机发生前后一段时间内,因此本文主要考察2008年金融危机发生的前后两年内的主要金融市场间相关结构的变化,样本期从2006第一个交易日到2010年最后一个交易日,即2006年1月9日到2010年12月31日。由于国际资本市场节假日不一致,休市日期不一致,因此需要对样本数据做简单匹配处理,经过处理之后,原始样本数据有1 212个。去除数据异方差常用的方法是对原始数据取对数,做差分处理,这样就可以得到市场指数收益率数据,即:指数收益率序列为Rt=log(Pt)-log(Pt-1),经过收益率处理后,样本数据为1 211个。本文研究所有数据均来自Wind数据库,模型研究采用的主要软件有:Eviews5.1和Matlab R2010a。
1.模型构建
采用非参数-MLE估计方法研究金融危机传染效应的存在性分为三个步骤:
(1)非参数核密度估计。Pazen(1962)在论文中证明了采用非参数的核密度方法估计的核密度函数具有渐进相容性和渐进正态性。本文先对每个研究对象进行非参数估计得出每个时间序列的核密度函数。
(2)Copula模型估计。通过第一步核密度估计后得到了每个时间序列的核密度函数,然后通过概率积分变换就可以得到对应每个时间序列的新时间序列,如果这些新的时间序列服从(0,1)均匀分布,那么就说明通过非参数估计得到的核密度函数能够充分描述每个收益率序列的边缘分布,因此可以用来估计Copula模型的参数和时变相关系数的参数。
(3)相关系数时变过程与变点检测。通过第二步得到相关系数的相关参数估计,选择合适的动态相关系数,得到动态相关系数图和序列,通过动态图和变点检测分析在样本期内相关系数是否发生了显著变化来确定是否存在金融危机传染效应。
2.模型估计
实证研究的第一步是非参数核估计,得到每个资本市场指数收益率的核密度函数,先确定核函数,然后再寻求最优窗宽。如果研究对象样本足够大,核函数可以选取正态核函数,正态核函数具有良好的光滑性。然后再选取合适的窗宽,一般采用Bowman(1997)提出的最优窗宽选择原理来选取最优窗宽。表1给出了各个资本市场指数的最优窗宽结果。

表1 各资本市场指数收益率最优窗宽
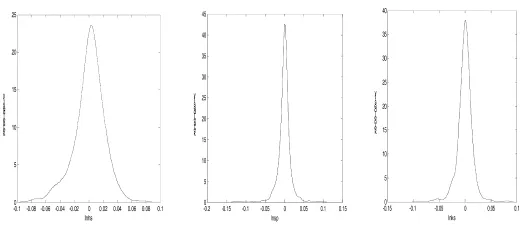
图1 沪深300、标普500、富时100核密度函数估计图
图1给出了三个资本市场指数收益率的核密度函数估计图,通过观察上述核密度函数估计图可以发现,资本市场指数收益率序列都具有尖峰厚尾的特征,峰度很大,且都有不同程度的左偏或者右偏。股指收益率右偏,也就是描述统计量中偏度系数为正值,说明股指上涨的可能性大于下跌的可能性,反之则反是。这些特征都符合高频金融时间序列的基本特征,如果仅从收益率二阶矩出发研究风险度量、资产定价等主题是不合适的。因此如果基于收益率序列做总体分布假定,如正态分布、学生t分布等,在此假定下做概率积分变换并估计Copula模型,得到的实证结果必然是不准确的,非参数核估计的优势正在于此。
对资本市场指数收益率序列进行概率积分变换①本文对数据做概率积分变换时没有调用Matlab 2010a中自带的经验累积分布函数(ecdf.m),而,也就是在每个指数收益率序列拟合的核密度函数下,计算每个指数收益率的经验分布函数。三个市场指数收益率序列顺序分别为:①沪深300指数;②美国标准普尔500指数;③英国富时100指数。经过概率积分变换后的序列理论上服从(0,1)均匀分布,即每个值出现的概率都一致。
通过SPSS Statistica 17.0软件中基于Kolmogorov-smirnov检验和Eviews 5.1软件中的Q-Q图检验(图2)发现,经过概率积分变换后,每个序列中每一个值出现的频次都为1,每个序列都不能拒绝服从(0,1)均匀分布的原假设,因此可以认为概率积分变换序列服从U(0,1)分布。检验概率积分变换序列的自相关性,如表2结果显示在5%的显著水平下,所有的序列都不能拒绝序列为随机序列的原假设,概率积分变换序列具有独立性。是编程采用经验累积分布函数这里的 1 是示性函数,即二者的不同之处在于本文采用的经验累积分布函数的分母为(T+1),而Matlab中的分母为T。之所以不用软件自带的程序代码是因为,该程序在计算过程中会出现无穷大的值,这将使得程序自动报错而停止,因此本文采用A.J.Patton提出的经验累积分布函数程序,程序来自:http://econ.duke.edu/~ap172/
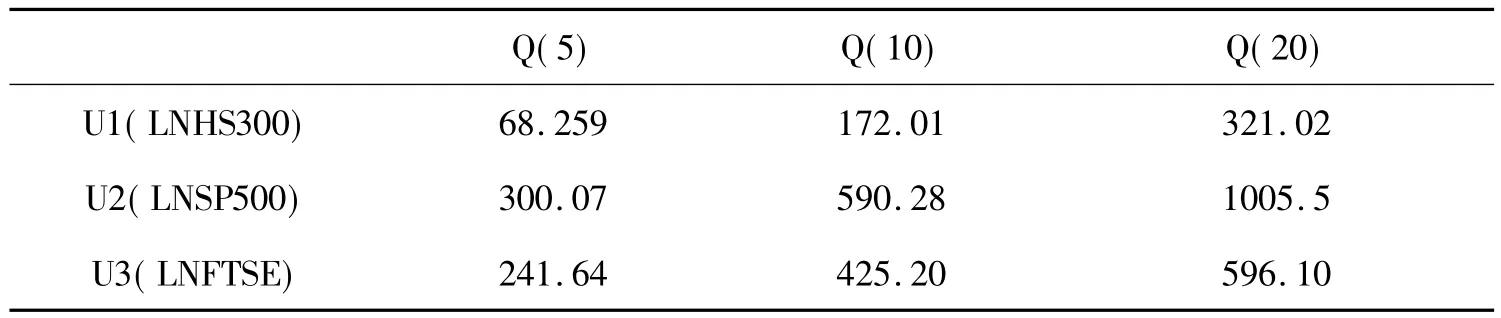
表2 各概率积分变换序列Ljung-Box Q检验
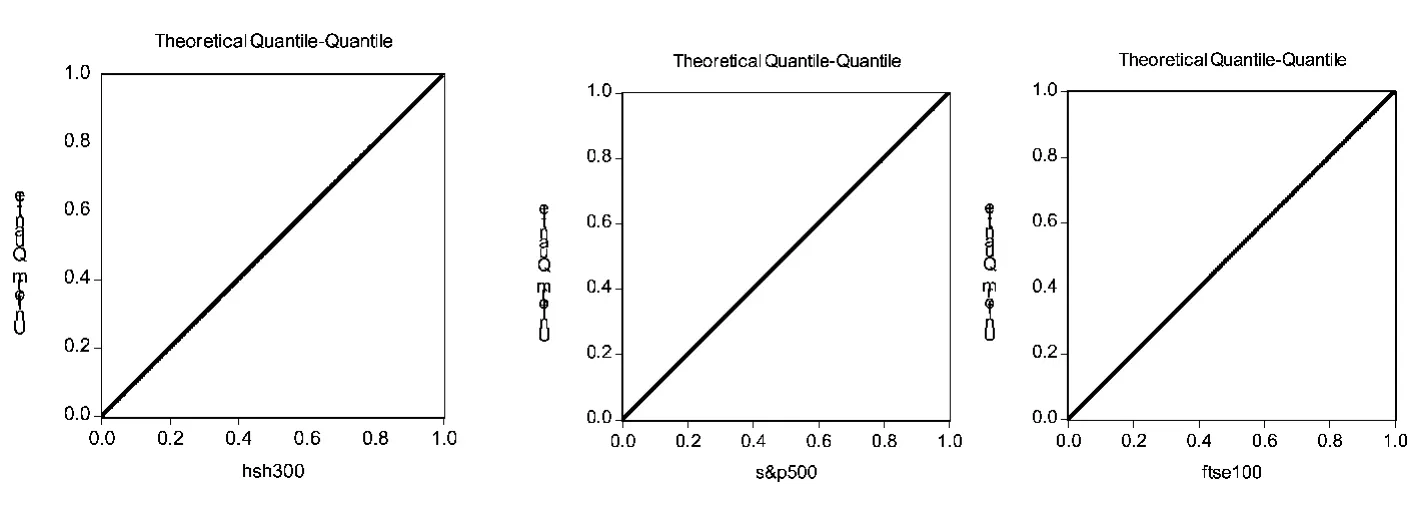
图2 概率积分变换序列Q-Q图检验
对概率积分变换后的序列进行经验分布检验和独立性检验,表明序列服从U(0,1)分布,并且具有独立性,可以认为序列是随机序列,因此可以用来构建Copula模型。本文将分别对中国大陆股票市场和各个主要国际股票市场建立四个估计模型,包括两个椭圆Copula函数模型和两个Archimedean Copula函数模型,即:t-DCC(tDCC)模型,Gaussian-DCC(GDCC)模型,time-varying Clayton(tvC)模型和time-varying SJC(tvSJC)模型。
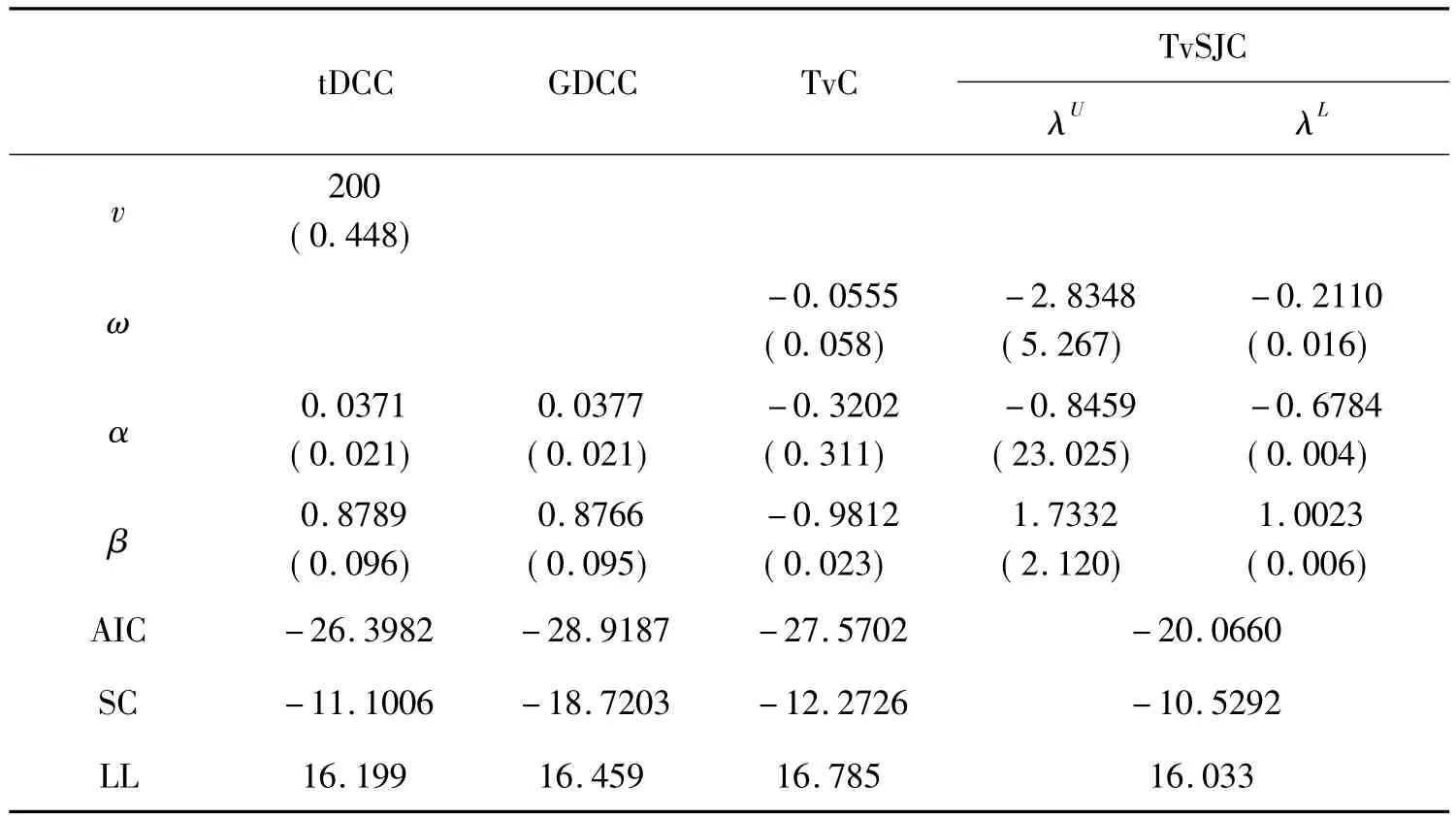
表3 沪深300指数与标普500指数模型估计结果
根据回归结果(见表3、表4),沪深300指数与标普500指数回归结果部分参数显著性不高,虽然TvSJC模型中信息准则和极大似然值稍微差点,但其下尾相关系数估计值具有显著性,因此我们采用TvSJC模型研究中美股票市场;沪深300指数和富时100指数的回归结果相对较好,GDCC和TvSJC模型回归结果都较好,鉴于TvSJC模型能够反映非对称相关结构,因此也采用TvSJC模型来研究中英股票市场。结果如表5所示。
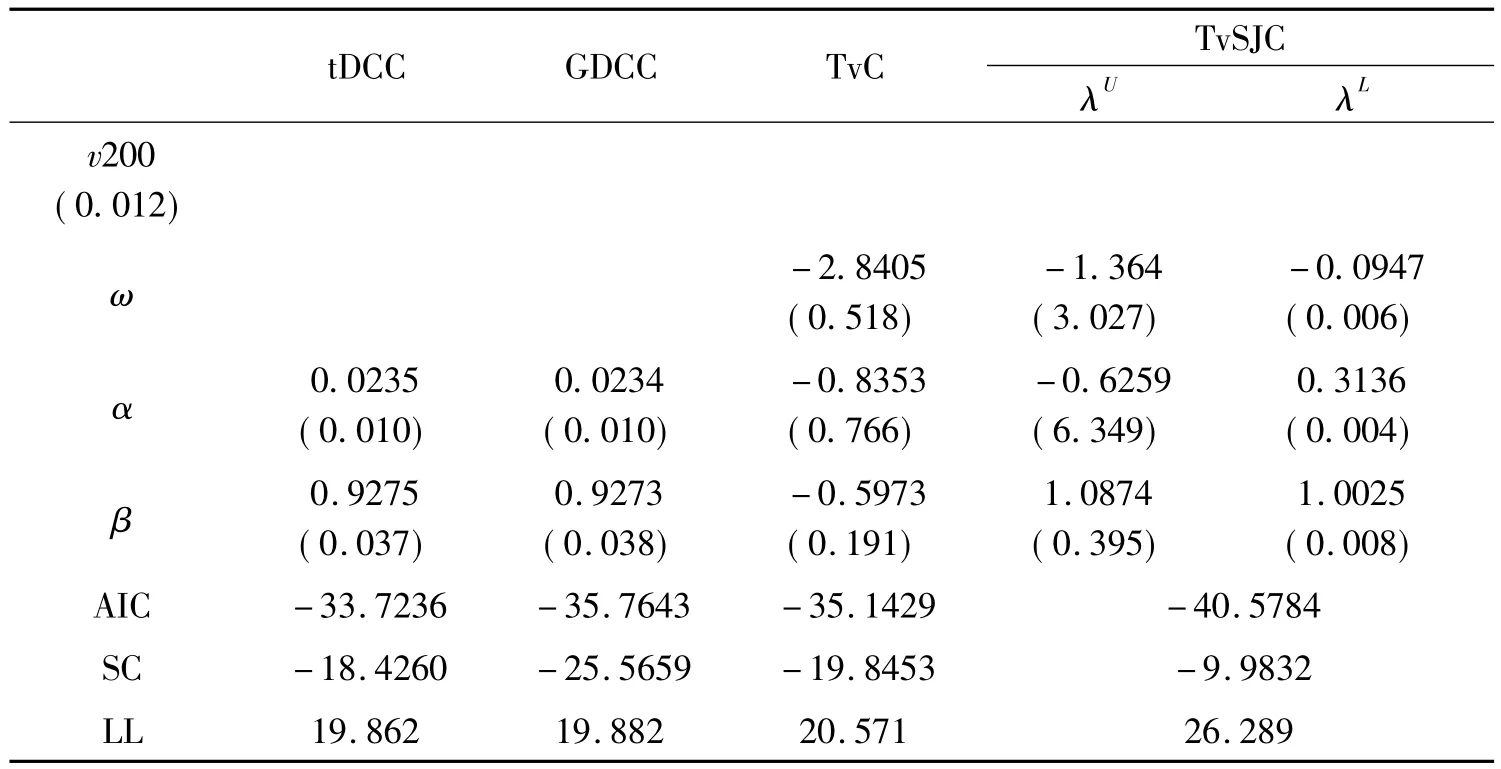
表4 沪深300指数与富时100指数模型估计结果

表5 最优模型选择
3.时变相关系数和变点检测
模型估计得到了时变相关系数的估计参数,将其带入Copula函数的相关系数动态演化方程,得到时变相关系数的估计序列,对时变相关系数的动态过程进行分析,检验两个金融市场之间是否存在金融危机传染效应。对时变相关系数的分析还可以通过变点检测,以检测时变相关系数是否存在变点来检验相关系数是否发生显著变化。
(1)时变相关系数图
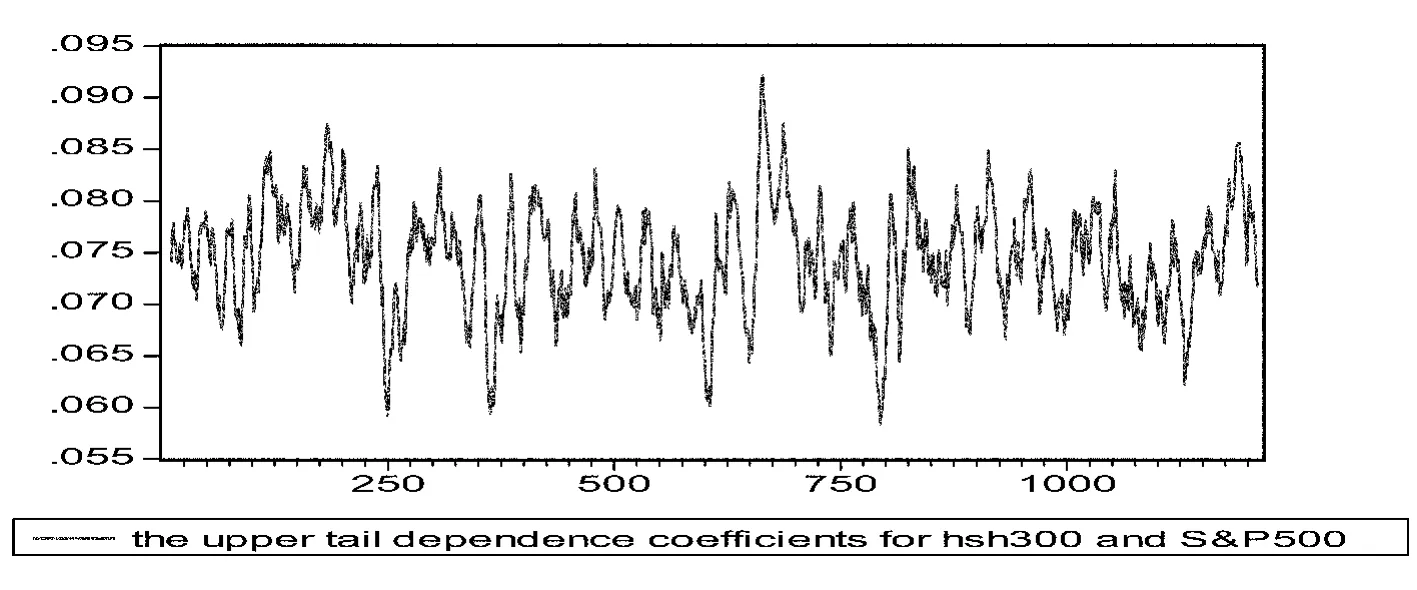
图3 沪深300与标普500指数上尾相关系数的时变图

图4 沪深300与标普500指数下尾相关系数的时变图
图3和图4分别给出了沪深300指数和标普500指数的上尾和下尾时变相关图。对比上面两图可以发现,下尾相关系数的均值明显的高于上尾相关系数的均值,并且下尾相关系数的参数估计值要明显显著于上尾相关系数的参数估计值,这表明沪深300指数和标普500指数之间的相关结构是非对称的。下尾相关系数较高,表明当其中一个市场出现大幅下跌的时候,另一个市场也出现大幅下跌的可能性较大,因为在下尾两个市场具有较高的相关性。
从相关系数的时变图可以看出,上尾相关系数虽有随着时间的推移而波动,但是其波动多在[0.065,0.085]之间,振幅有限,在样本观测期内只有5次出现过明显的超出范围,但随后也就回归均值波动;下尾相关系数波动范围在[0.62,0.68]之间,波动范围也有限,在样本观测期内,也只有5次明显超出波动范围,且在波动之后也回归到均值附近。从相关系数的时变图可以看出,相关系数没有明显的结构性变化,这说明在样本期内,中美两个市场相关结构是没有显著变化的,不能够说明两个市场之间存在金融危机传染。

图5 沪深300与FTSE 100指数上尾相关系数的时变图
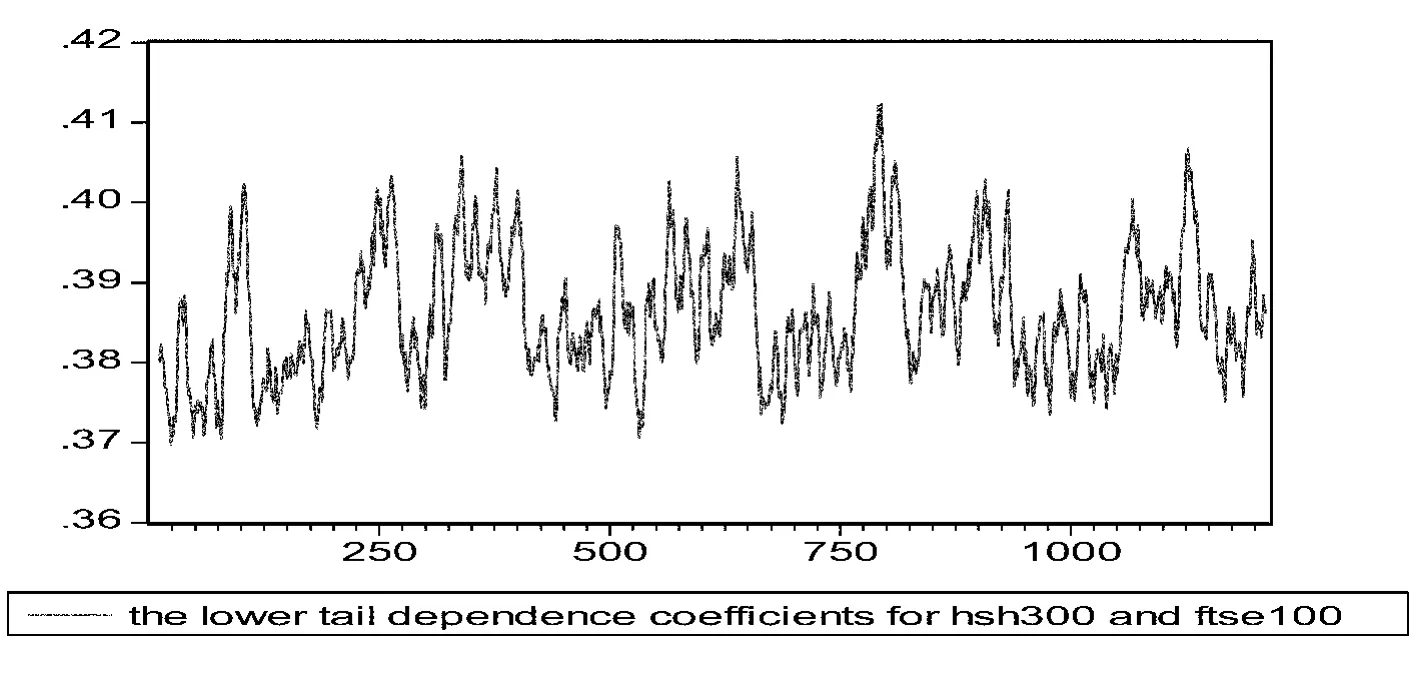
图6 沪深300与FTSE 100指数下尾相关系数的时变图
图5和图6分别给出了沪深300指数和FTSE 100指数的上尾和下尾时变相关图。对比上面两图可以发现类似的结果,即下尾相关系数的均值明显的高于上尾相关系数的均值,并且下尾相关系数的参数估计值要明显显著于上尾相关系数的参数估计值,这表明沪深300指数和标普500指数之间的相关结构是非对称的。
从相关系数的时变图可以看出,上尾相关系数虽有随着时间的推移而波动,但是其波动多在[0.19,0.23]之间,波动范围有限,在样本观测期内只有4次出现过明显的超出范围,但随后也迅速回归均值波动。下尾相关系数波动范围在[0.37,0.40]之间,波动范围也有限,在样本观测期内,也只有2次明显超出波动范围,且在波动之后也回归到均值附近。从相关系数的时变图可以看出,相关系数没有明显的结构性变化,这说明在样本期内,中英两个市场相关结构是没有显著变化的,没有充分证据说明两个市场之间存在金融危机传染。
(2)变点检测。检验时变相关系数是否存在变结构,可采用变点检测方法检测时变相关系数在样本期内是否出现变结构的情形。Dias(2004)给出了变点检测的方法。对于两个时间序列,其成对观测数据为:(x1,y1),(x2,y2),…,(xn,yn),假定其时变的相关系数为 ρi,i=1,2,…,n,且两个时间序列只存在一个变结构点,那么可以采用构建相关统计量对其进行检验:
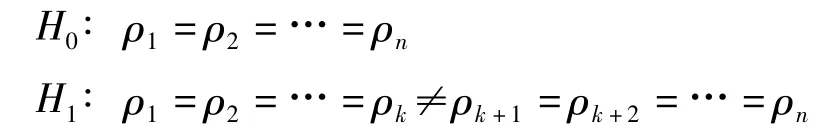
如果原假设别拒绝,那么就说明两个时间序列的相关结构存在变点k,在k点的前后相关系数是显著不同的。对于金融危机传染效应研究而言,如果变点之后相关系数显著增强也就验证了金融危机传染效应的存在。可以构建对数似然比统计量:
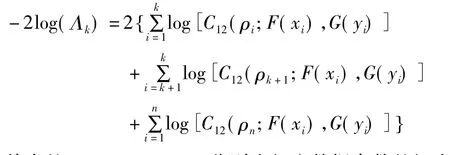
其中的ρi,i=1,2,…,n分别为相应数据参数的极大似然估计值。
当统计量-2log(Λk)在1,2,…,n中取的最大值,如果明显的很大的话,那么就可以拒绝原假设,接受备择假设。统计量渐进服从自由度为约束个数的卡方分布,即LR∶χ2(l)。根据统计量的临界值就可以判断是否拒绝原假设,从而接受备择假设。如果拒绝原假设,那么使得统计量-2log(Λk)最大的那个点即为相关系数的变结构点。
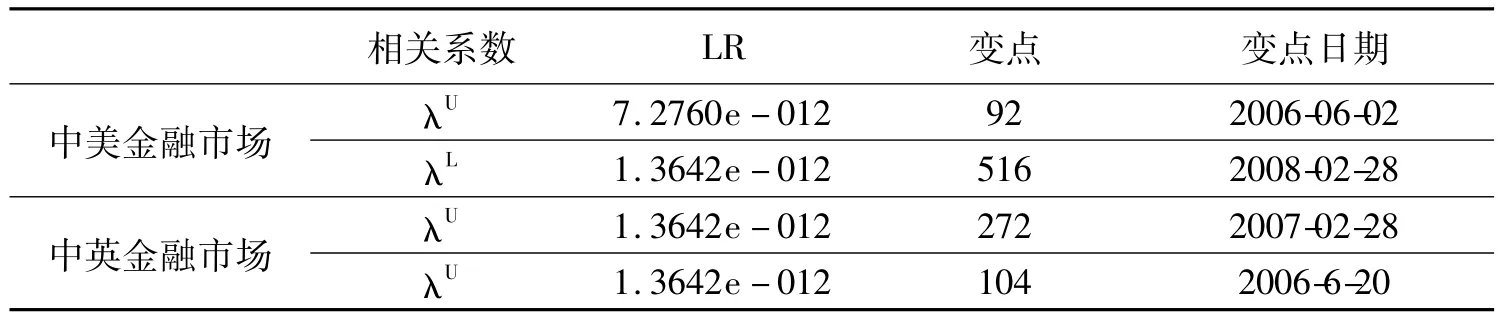
表6 变点检测结果
表7给出了时变相关系数中美、中英金融市场的上尾、下尾时变相关系数的变点检测结果,通过构建对数似然比统计量,发现统计量结果较小,几乎为零,不能拒绝原假设,也就是说在样本观测期内,中美、中英金融市场的上尾和下尾相关系数没有发生显著的结构性变化,没有变点。在每个相关系数时变过程中,统计量最大处也不是金融危机爆发的前后,因此通过变点检测也表明中美金融市场、中英金融市场没有发生金融危机传染效应。
结论与展望
本文通过建立时变Copula函数模型研究了在次贷危机时期中美、中英金融市场之间的金融危机传染效应问题。本文通过非参数-MLE方法估计了时变Copula模型,采用非参数-MLE估计方法,避免了分布假定给估计结果带来的影响。本文构建了四种模型(tDCC,GDCC,TvC,TvSJC),并估计了上尾、下尾时变相关参数,通过分析相关系数的时变图和变点检测方法得出结论:在次贷危机引起的金融海啸过程中,中美、中英金融市场之间没有发生显著的金融危机传染效应。
虽然研究结果表明美英金融市场没有对我国金融市场产生危机传染,但我国还是受到了一定的冲击。与1997年亚洲金融危机对比我们可以发现,发达国家一旦出现金融危机,会对发展中国家产生冲击;而当发展中国家的金融危机却对发达国家仅有很小的冲击力。也就是说,金融危机的传染效应在发达国家和发展中国家的影响过程是不对称的,这可以作为未来金融危机研究的一个方向。
猜你喜欢
初中生学习指导·中考版(2021年2期)2021-09-10
意林绘阅读(2019年12期)2019-12-30
阅读与作文(英语初中版)(2019年11期)2019-09-10
软件(2017年9期)2018-03-02
智富时代(2017年7期)2017-09-05
智富时代(2017年7期)2017-09-05
故事作文·低年级(2017年7期)2017-07-20
智富时代(2017年4期)2017-04-27
智富时代(2017年4期)2017-04-27
科学与财富(2016年28期)2016-10-14
