
基于加权算法的汉语语音同步三维口型动画研究
2012-07-07 03:37:26毕永新韩慧健周世文
图学学报 2012年2期
毕永新, 韩慧健, 周世文
(1. 山东经济学院山东省数字媒体技术重点实验室,山东 济南 250014;2. 山东经济学院科研处,山东省数字媒体技术重点实验室,山东 济南 250014;3. 山东省科技馆,山东 济南 250011)
具有真实感的语音同步口型动画是当今计算机图形学领域研究的一个热点。1998年,Jörn Ostermannp[1]提出英文中口型与字母音位的对应关系,并在 MPEG-4动画标准的基础上建立脸部、口型动画合成。此后,基于英文的真实感脸部动画和口型动画的合成得到了快速的发展,并在影视3D动画中得到了广泛的应用。
在汉语口型动画方面,哈尔滨工业大学的尹宝才[2]等研究的以汉语文本驱动的基本表情和口型合成系统,根据Ekman[3]定义的6种基本表情和汉语文本情绪维量的分析,成功合成了不同的人脸面部表情和口型。另外,汉语语音发音的唇形可视化研究[4-6],对汉语发音口型进行了较为系统的归类,清华大学等在口型的实时模拟合成方面[7-8]取得了较好的成果。虽然合成了比较逼真的动画模型,但都是基于单帧动画不能连续驱动,也没有跟语音同步。本论文针对汉语语音口型同步的连续驱动的动画的合成进行了研究,论文中重定义了口型拼音库,并提出了声韵加权控制和标号权重向量分析方法、口型动画过渡插值算法等,依据这些算法构建了一个汉语语音同步的三维口型动画合成原型系统。
1 汉语拼音发音口型特征的分析
本研究中只考虑一般情况下的汉语拼音发音规律,根据《汉语拼音方案》中提到的因素发音时的特征,结合唇度口型序列的聚类分类[5]和标准汉语拼音中声母和韵母的划分,本研究将基本口型划分为三级。
一级口型:张嘴型是发音的核心,a口型为嘴型张开;g、k、h、e 嘴型为下巴张开到最大角度的四分之一,嘴唇放松;f上齿触下唇形成窄逢;b、p、m双唇紧闭,阻塞气流。
二级口型:变化型 嘴型主要是前后左右的变化,i、y、j、q、x、z、c、s嘴唇向两侧拉伸,zh、ch、shi、r 嘴唇前伸,绷紧,o、u、w、ü 嘴型前伸,嘴型拢圆。
三级口型:嘴唇放松,音节之间的区别主要是舌头和喉咙的位置不同,嘴型变化细微,d、t、n、l嘴唇放松。
2 汉语语音同步的三维口型动画合成系统
根据上述对汉语拼音库的重定义和发音口型的分类,本论文提出了基于综合加权的语音同步口型动画合成算法,并基于该算法设计实现一个汉语语音同步的三维口型动画合成系统。对于输入的汉语文本,系统首先实现文本到语音的转换,同时能够将语音同步到唇形变化,实现语音口型同步的动画合成。动画合成算法的关键是合成口型的运行时间,运行时间的长短直接决定能否让脸部模型同步展示在系统前端。口型动画合成系统的基本框架入图1所示。
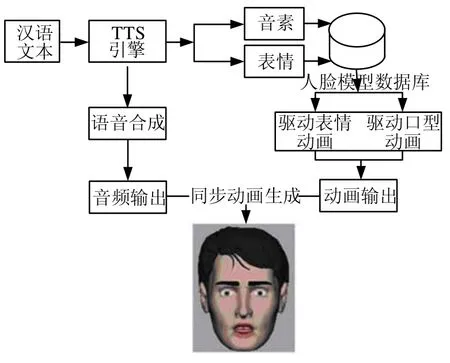
图1 汉语语音同步口型系统流程图
具体步骤如下:
Step 1 输入汉语文本;
Step 2 将文本转换为汉语语音学的拼音;
Step 3 从文本产生合成语音的样本;
Step 4 询问音频处理器,且从语音播放处理器中决定当前的音素;
Step 5 从当前音节的轨迹中计算出目前的口型;
Step 6 合成语音同步的口型并且同步图形展示,返回Step4直至没有可读因素为止。
其中,Step1至Step3是预处理阶段,是算法所必要的部分,因为语音转换和音频样本可以被预产生并存储在磁盘里。而Step4至Step6是实现语音口型动画同步性的关键。本文结合前人的研究,综合汉语拼音发音时口型变化的规律和汉语标号的时间控制,提出了声韵加权控制算法,并对整句、整段话中的标号加以权重向量的分析,能够合成与语音同步的连续变化的口型动画模型。在处理过程中,需要数/模转换(DAC)来产生相关说话声波的模拟信号,并联合使用音频播放设备,这些必须是在系统程序的一个请求响应维持时间内完成,否则就会出现口型动画迟缓于语音的现象。因此,需要把全局时钟设置为基于音频服务请求响应的时间作为一个响应时钟。音频服务设备的时钟,在初始化过程中被采样并存储。
声音与图形的同步实现如下:音频服务器被初始化,并返回开始时间序列。一个样本小序列被播放,并返回持续时间(毫秒级别)和当前服务器时间,并从当前服务器时间计算出相关的动画驱动时间,以此计算当前口型的形变。一旦口型形变被计算出,另外的操作控制,例如眨眼等,被控制发生在这个时间内。之后,面部图形被更新,渲染,并被表现在系统前端。
3 基于加权算法的汉语语音同步算法
3.1 口型动画拼音重定义方案
根据上述口型的特征分类,可以发现很多音素的发音口型是相同或者是类似的,因此为了达到快速、易操作的目的,本研究对标准汉语拼音进行重新定义,将汉语拼音划分为声部和韵部。对标准声母表的分类简化为基本的6类如表1,韵部可分为4类口型如表2。
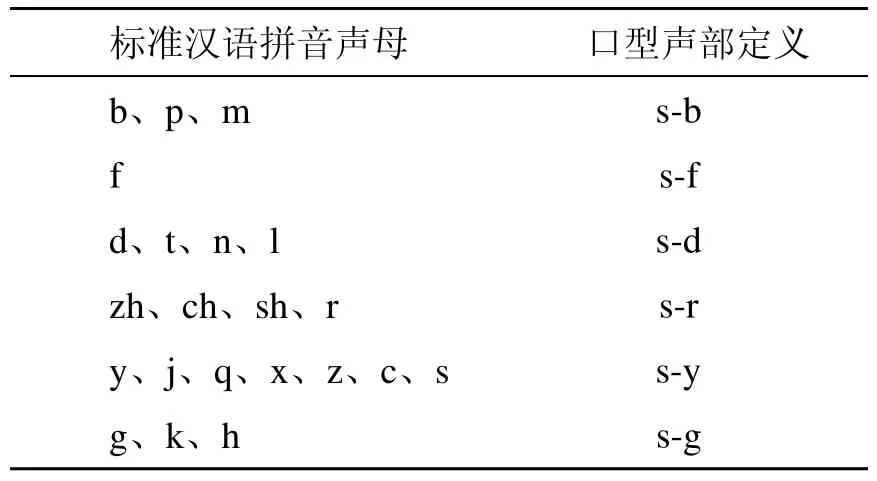
表1 标准汉语拼音声母转换表

表2 标准汉语拼音韵母转换表
声部的定义主要是将发音口型特点相同或者类似的声母归类:s-b双唇紧闭,阻塞气流;s-f上齿触下唇形成窄逢;s-d嘴型微开,嘴唇放松,嘴型变化细微;s-g嘴型为下巴张开到最大角度的四分之一,嘴唇放松;s-r嘴唇前伸,绷紧;s-y 嘴唇向两侧拉伸。同样根据口型特征,韵部可分为:y-a口型,主要是用于发音时嘴唇开度较大的不圆唇的韵母发音,例如 a、an等;y-o口型,主要是用于发音时嘴唇略圆,嘴向前撮的韵母,例如o、ou等;y-e口型,主要是用于发音时嘴唇半张、口型不圆的韵母例如e、i等;y-o主要是用于发音时嘴唇向前突出成圆形只留较小缝的韵母,例如u等。根据表1和表2,本研究将所有的汉字拼音转换成口型声部和口型韵部两个部分,例如“动画”两字就可以分别表示成 s-d→y-o和s-d→y-a。如果把s-b、s-d、s-f、 s-r 、s-y、y-a、y-o、s-g和 y-e、y-i做成 9个口型模型,那么每两个模型关键帧之间的变化过程将构成一个汉字的发音口型动画。
把汉字按照声、韵母分成声部和韵部口型的方法基本适用全部汉字,只有个别汉字拼音例外,即单因素汉字如 a(啊)、0(哦)、e(饿)、ai(爱)、ei(诶)、ao(袄)、en(恩)、er(儿)等,它们只有汉语拼音划分中的韵母。如果按照上面的分类,都只有一个口型韵部,那么在动画合成中就只存在单个韵部口型,为了统一把它们都加上一个固定的声部口型符号称为自然状态模型,记为“&”。完成口型拼音声部与韵部定义后接下来就是转换工作,就是将汉字的标准拼音转换成由声部与韵部符号组成的口型拼音。为了程序实现方便,本研究中把声部与韵部的口型记号简化,去掉前面的“s-”和“y-”只写成一个字母简化后符号字母共有 10 个:a、o、e、i、b、d、f、r、y、g。表3给出了一些汉字拼音转换的例子。

表3 部分汉字转换举例表
3.2 口型动画合成
构造好基本口型模型并建立相应的口型动画拼音库后,还无法模拟自然人正常沟通时连续的汉语口型动画,还需要考虑上述单音节口型变化中声部和韵部对发音动画控制时间的不同,而且要综合考虑整句话甚至整段话中汉语标点符号对口型变化的影响。因此,本节考虑合成同步动画时声部和韵部控制时间的不同以及声、韵两部分动画过渡中的流畅性,在控制这两部分动画时,采用声韵加权的处理方法,以合理的控制两部的动画时间比例使动画更加逼真,并应用一种余弦函数处理两种口型动画的过渡,让动画更加的平滑流畅。
3.2.1 声韵加权算法
自然人在一个汉语音节中,声母和韵母在音节中所占的比例是不一样的,而且相对于韵母来说,声母所占的比例要小得多,也就是说口型的最终外观效果主要是体现在韵母上,所以在口型动画控制过程中韵部的动画时长要大于声部。针对此问题本研究中将对声部和韵部采用加时间权重来控制其在动画合成中所起的作用。在合成口型动画时,“人”每说一个汉字时,口型就由声部关键帧过渡变形为韵部关键帧。韵部的动画时长要大于声部,也就是说口型的最终外观效果主要是体现在韵部。
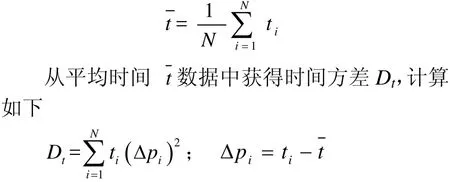
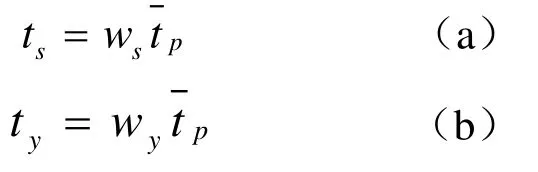
通过改变一定限度内的ws、wy权重值可以生成类似的训练集的基本口型,ws、wy称为声部权重和韵部权重,可以用到口型动画通道上。依此方法实现自动动画的程式控制,动态的获得 3D动态口型动画的合成。自然人发声音节时域波形与单音节的声韵加权控制动画合成过程对比效果如图2所示。
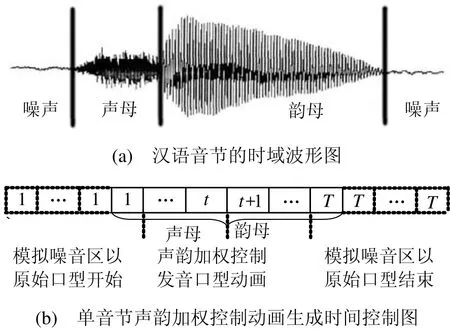
图2 发音实际时域波形和声韵加权控制的动画
3.2.2 标号权重向量分析
连续的口型动画不仅要考虑到这些单音节动画,更要考虑连续、完整句子或者段落中单个音节动画的过渡,句子或者段落中标点符号的停顿时长。句子前后都有停顿,并带有一定的句调,表示相对完整的意义。句子前后或中间的停顿,在口头语言中,表现为一定时间的间隔,在书面语言中,就用标点符号来表示。标点符号是书面语言的有机组成部分,是书面语言不可缺少的辅助工具,它帮助人们确切地表达思想感情和理解书面语言。同样,标点符号在自动合成连续动画的中所起的作用也是不可忽略的。标点符号中的标号,如引号,括号等在句子中出现时,停顿时间几乎可以忽略,在这个算法中将不予以考虑。本研究主要考虑在句内或句末出现的停顿时间较长的7种点号,如句号、叹号、问号、顿号、逗号、分号、冒号等,将其在句中的停顿时间加权表示如图3所示。
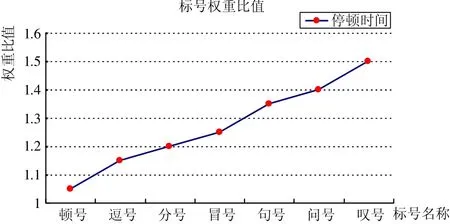
图3 标号权重
针对汉语中的标号同样赋以不同的权值,以便能生成更加逼真的、连续口型动画,计算公式如下

3.2.3 口型过渡处理
一旦t(现在的时间和 t0相关)被音频设备确定,唇部节点位移就可以被计算出来了。每一个唇部节点的视位可以用 xi( t) = [x ( t),y( t),z( t)]′来定义,在这里, i = 1 ,2,… ,n 是定义了嘴部几何和拓扑结构的控制节点的序列。为了做到完整口部形状的控制节点位置的内插值,拓扑结构必须保持固定,而且在每一个唇部形状雏形里的控制节点必须保持一致。中间的内插口型各个节点的位置X(s)可以通过初始和结束视位节点X0和X1的位置计算出来,公式如下
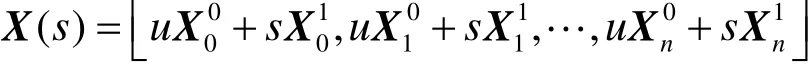
其中u=1-s,变量s通常被描述成t的线性或非线性变换,且0≤s≤1,然而,基于线性内插值的动作并没有展现出加速和减速的初始动作特征。一个加速和减速的相近的内插近似值使用了一个余弦函数来完善这个动作
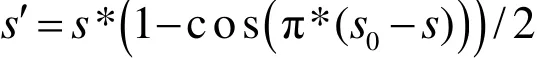
关于节点位移的动态计算,它以唇部的物理动作为依据,即如果指定了节点 Xi(t)的初始结构的位置、质量和速度,它就可以被计算出来一旦几何结构确定了,就可以应用牛顿物理学
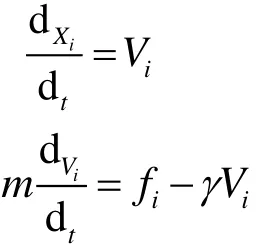
由于知道了X0和X1的位置,就可以计算它们沿向量X0X1的传递。为了计算出节点上的力,假设当时fi=0,这样力就可以适用于节点,γ是一个速度等价阻尼系数。唇部形状的变化使用了以节点分离为依据的Hookean弹性力,因此它可以提供一种面部组织比较灵活的动作的近似:节点分离向量
运动方程式是系统时间 t的函数,t是来自音频服务器的驱动时间,以此来计算新的速度和节点位置

4 试验结果分析
本文算法在 VC++平台上用 OGRE在Intel®i5,2.53GHz,2GB内存的PC机上实现。图4给出了我们的动画试验结果与真人发音口型的对比结果。图4(a)是合成“动”发音的动画口型序列,图 4(b)是真人说“动”时连续拍照所得到的口型序列。可以看出,采用该方法对口型动画进行合成,比较真实地反映人脸口型发音时的变化情况。
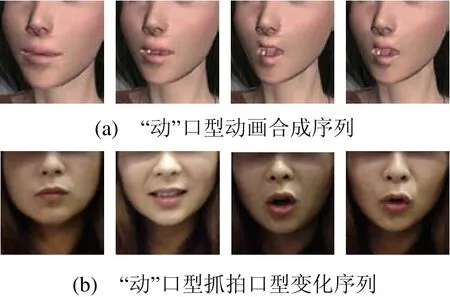
图4 动画合成 “动”口型与真人发音对比
5 结束语
本文提出了声韵加权算法和标号权重向量加权处理的语音同步的口型动画算法,并基于该算法设计实现了一个汉语语音同步的三维口型动画合成系统,系统不仅能够实现语音口型动画的同步,还能够连续的合成变化的口型,并搭配了简单的表情动画,使整个模拟过程更加逼真。该系统可以应用于简单的唇型识别,3D动画影视制作等。但是系统也存在不足,由于限制速度的原因,每个汉字只能应用一两个唇形合成,因此系统不能模拟比较细致的唇形变化。我们下一步考虑如何构建更加细致的个性化口型模型,并通过分析汉语文本中的情绪因素,使系统不仅能够模拟更加细致的唇型变化,更使系统在实现语音口型的同步的同时表现出更加丰富的表情。
[1]Jörn O. Animation of synthetic faces in MPEG-4 [J].IEEE Computer Animation, 1998, 1087(4844): 49-55.
[2]尹宝才, 高 文. 利用 Bézier曲面的面部表情和口型几何造型[J]. 计算机学报, 1998, 21(S1): 347-350.
[3]Ekman P, Friesen W V. Manual for the facial action coding system [M]. Palo Alto CA: Consulting Psychologists Press, 1978: 1-45.
[4]王志明, 蔡莲红, 艾海舟. 基于数据驱动方法的汉语文本-可视语音合成[J]. 软件学报, 2006, 16(6):1054-1063.
[5]单 卫, 姚鸿勋, 高 文. 唇读中序列口型的分类[J].中文信息学报, 2002, (1): 30-36.
[6]吕 军, 曹效英. 基于语音识别的汉语发音自动评分系统的设计与实现[J]. 计算机工程与设计, 2007,28(2): 1232-1235.
[7]Du Yangzhou, Lin Xueyin. Realistic mouth synthesis based on shape appearance dependence mapping [J].Pattern Recognition Letters, 2002, 23: 1875-1885.
[8]Hong Pengyu, Wen Zhen, Thomas S H. Real-time speech-driven face animation with expressions using neural networks [J]. IEEE TRANSACTIONS ON NEURAL NETWORKS, 2002, 13(4): 916-926.
[9]粟学丽, 丁 慧, 徐柏龄. 基于熵函数的耳语音声韵分割法[J]. 声学学报, 2005, 30(1): 69-75.
猜你喜欢
今日农业(2022年16期)2022-11-09 23:18:44
橡胶科技(2021年11期)2021-07-20 03:23:54
科技经济导刊(2021年5期)2021-03-19 05:32:34
作文周刊·小学一年级版(2019年28期)2019-09-07 03:42:03
中华诗词(2019年9期)2019-05-21 03:05:12
文学教育(2017年6期)2017-06-08 20:21:17
小学生时代·大嘴英语(2017年4期)2017-05-18 17:17:16
草原歌声(2017年1期)2017-04-23 05:08:59
贵阳文史(2014年5期)2014-10-20 23:14:10
科学时代·上半月(2013年8期)2013-09-06 08:47:02
