
微博文本处理研究综述
2012-06-29 06:15张剑峰夏云庆姚建民
中文信息学报 2012年4期
张剑峰,夏云庆,姚建民
(1.清华大学,北京 100084;2.苏州大学,江苏 苏州 215006)
1 微博文本的定义
随着互联网和通讯产业的快速发展,微博成为了又一个跨时代的产品。微博存在着一个很显著的特点,就是能非常迅速及时地将信息传递到每一个用户。
微博文本与正式文本有很多不同的地方。第一,微博最大的特点就是文本长度短。不同微博系统对微博文本的字数限制不尽相同,以新浪微博为例,限定一个微博文本的字数不多于140个字符,更多的微博文本只是一个句子甚至一个短语。这一特点给微博文本处理造成了严重的数据稀疏问题。
第二,微博文本的文法通常是非正式的,语言是口语化的。为了提高交流速度,微博文本中缩写和拼写错误很常见,还经常掺杂着一些新近流行的网络语言和表情符号。
例1: “原来酱紫我^_^”
例1中的“酱紫”,是“这样子”对应的网络用语,“我”是“哦”的错别字,“^_^”代表了微笑表情。这些特点会给微博文本理解带来很大困难。
第三,半结构化。除了文本内容,微博文本还包含一些元数据,例如,作者、发布时间、转发数量、收藏数量、评论等信息。
第四,微博文本通常是某对话线索(conversation thread)中的一个发言或回复。通常定义线索为满足对话特征的微博文本序列,线索的第一个发言称为首帖。首帖发布后,更多的发言以回复的方式产生,称为跟帖。微博系统保存了大量的微博文本线索(thread),每个线索又包含了多个微博文本。微博文本的这一特点实际上形成了充足的上下文,给微博文本理解带来重要依据。
第五,显著的意图性和主观性。微博上言论自由,因此个性化语言和表达方式成为个性张扬的体现。但多数人意图明显,对首帖所提到的内容进行评论或补充,且带有明显的主观性。
第六,大量的省略和指代。由于提供了丰富的上下文,微博文本经常省略前文提到的内容,或者采取指代方式。每个微博文本都在评论别人,同时也是别人评论的对象。这一特点是微博文本大量采用省略和指代的最主要原因。
由于微博文本具有以上特点,在处理微博文本时,采用与处理普通文本时相同的方法通常难以奏效。与微博短文本在形式上类似的,还有短信、聊天记录等网络短文本,他们同样具有“短”、“口语化”、“网络性”、“图标化”“对话性”等特点。这些方面的研究同样值得密切关注。
关于聊天记录的相关研究起步较早。Dyke等提出了一种可以与用户对话的实时聊天工具,并记录用户的兴趣爱好,提供给用户可能感兴趣的资源[1]。Zhou等对特定技术领域的聊天记录按照话题进行聚类,并使用机器学习的方法,选取一些词汇特征,实现对聚类完成后的聊天记录的摘要生成[2]。Adams和Martell对在线聊天室记录上进行了话题分析研究,在VSM模型的基础上提出了三个加强因素: 时间距离、上位词和昵称,取得了不错的效果[3]。与微博文本不同之处在于,聊天记录文本更注重实时性,而且在聊天过程中,用户讨论的话题演变速度更快,所以,对聊天记录进行话题分析的难度更大。
而关于短信文本方面的工作则较少。Shen等提出基于VSM模型的短信文本会话(thread)识别方法,在相似度计算中融合时间因素和位置信息,并取新的message和原先存在的thread中的message最大的cosine值作为相似度。实验证明,改进取得了较好的效果[4]。彭京等针对短信文本中数据稀疏的问题,基于《知网》(HowNet)概念模型,提出了一种语义内积空间模型,并在此基础上构造了两阶段聚类算法完成文本数据的聚类[5]。而吴薇则对短信文本的过滤和分类方法进行了总结[6]。龚才春则对短信文本的特点进行了总结,并概括了挖掘网络短信文本的方法[7]。与微博文本相比,短信文本的“对话性”更强,主要是两个用户之间的交互行为,而与微博文本类似的是,短信文本的话题相对一致,演变速度不快。
研究者还将三种网络短文本(短信、聊天记录、微博)混合在一起进行了一些尝试。Wang对三类网络短文本(即时通讯、在线聊天室记录和手机短信)进行话题的抽取。该研究注意到网络短文本语句较短且不完整的特点[8]。Phan等借助外部资源,建立了一个框架体系,利用LDA工具进行话题分析,从大规模语料集中抽取主题,进而对混合短文本进行分类[9]。方法的优势在于降低了数据稀疏的影响,并扩展了分类器的覆盖面。黄永光等将短信、聊天记录这类表述不规范的文本称为变异短文本,并针对其特性提出了一种基于特征串匹配的聚类算法[10]。实验表明,该算法对于变异短文本聚类这一特殊领域有着很高的执行效率和准确率。
虽然研究者对短信、聊天记录、微博等短文本进行了一些研究工作,但是总体来说,对于短文本中的数据稀疏问题解决方法的效果并不好,所以,还有待研究者们根据短文本的结构特征,对于短文本中存在的问题,提出更好的解决方法。
2 微博文本研究的意义
由于微博极大促进了信息的传播和共享,其巨大的商业价值开始显现,并在危机公关、舆论炒作和网络推广等方面凸显商业优势。中国首届微博开发者大会于2010年11月16日在北京举行,将互联网行业对微博的关注推向高潮。根据新浪的统计数据,截止2010年11月,新浪微博用户数已达5 000万,每天微博发布量超过2 500万,微博总数超过20亿条[11]。据第三方调研机构DCCI预计,2011年中国互联网微博累计活跃账户数将突破1.5亿[11]。
在商界热捧微博的同时,互联网信息监管部门也意识到他们所面临的严峻挑战。微博允许任何人用电脑、手机等方式在任何时间发布任何言论,且这些言论能顷刻之间传播给互联网所能触及的任何人。微博正式启动了一个“人人都是记者”的新时代。微博的美好初衷不可否认,但如果缺少必要且及时的监管,各类影响社会稳定的负面信息必会有机可乘,终将酿成严重的社会后果。试想,一个恶意或虚假的消息可能被微博无限放大,将触发政府或商业机构的信任危机,乃至群体性恶性事件的出现。2011年1月18日,2010中国互联网产业年会发布了“影响2010年中国互联网发展的十件大事”,认为“规范管理和合理利用微博是经营者和相关主管部门面临新挑战”[12]。
近两年微博的迅速发展,给监管部门带来了以下挑战: 第一,数量惊人,产生速度惊人,传播速度惊人。仅新浪微博网站,目前已经积累了20亿条微博,每秒钟能产生785条微博,这些微博可瞬间遍布于与新浪微博网站建立内容分享关系的1万家全球网站。微博数量之大、影响规模之广,令人震惊;第二,微博内容极其独特,除了具有“短”、“口语化”、“网络性”、“图标化”等网络文本所具有的共同特点外,还具有显著的“对话性”特点。这些特点给传统文本分析处理带来了数据稀疏性问题,不规范的文法也给语言分析带来巨大困难。
于是,针对微博文本的研究工作应运而生。在语言分析层面上,研究涉及词汇层(如分词和词性标注),句法层(如命名实体识别和语法分析),语义层(如语义分析)。而微博文本的研究还和一些语言技术有关,例如,文本分类,信息抽取,话题检测,自动摘要,对话系统,情感分析等。对于微博文本的研究还可以应用于现实生活中的许多方面,例如,电子商务,信息监控,民意调查,电子学习,商业智能,企业管理等。例如,挖掘一个企业的官方微博评论或回复,可以了解用户对该企业推出的新产品有什么意见和建议,促使企业进一步改进产品的质量,其他用户也可以根据评论来决定是否购买该产品。
图1说明了对于微博文本的研究所涉及的语言分析层面、相关语言技术和部分应用领域。
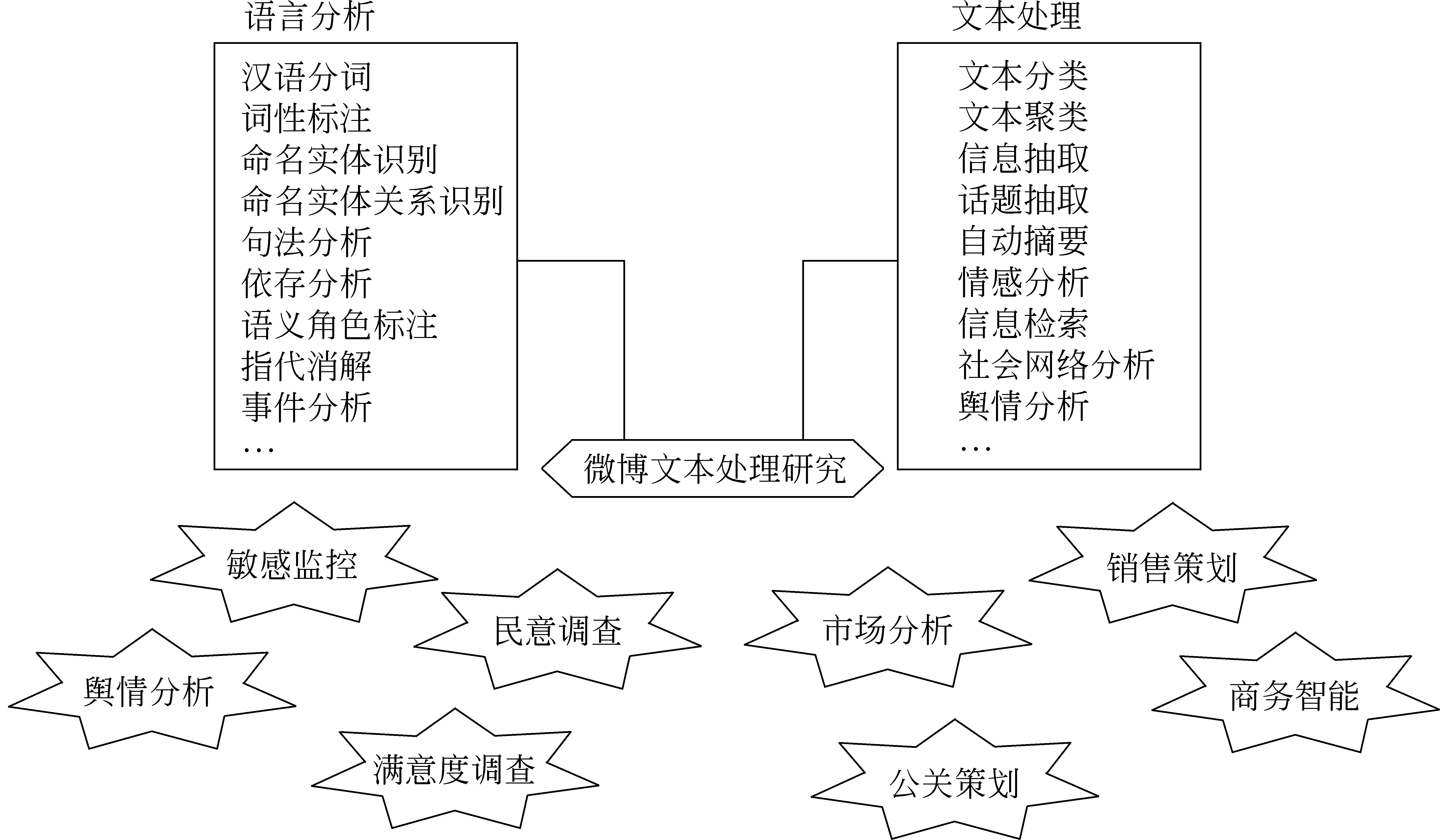
图1 微博文本处理研究所涉及的语言分析、文本处理和部分应用领域
综上所述,微博文本的研究是一项有前途的、新颖的工作,但是,它同样也面临着许多问题和挑战。因此,对于微博文本的研究工作不仅具有理论意义,而且具有实用价值。
3 微博文本研究现状
本节,我们从语言分析、文本处理和用户行为三个方面介绍国际国内针对微博文本的研究现状。在文本处理层面,我们又将研究工作划分四个典型的课题进行阐述。最后,介绍目前已经存在的微博文本数据集和两个微博文本应用系统。
3.1 语言分析
早期与微博文本相关的工作集中在语言分析方面。Java等对微博的概念和作用进行了总结和探讨,介绍了微博的即时性、共享性、快速传播等特点,并从各个角度统计了微博在近年来的使用增长情况[13]。文章根据用户之间的关系,阐述了哪一类用户会分享相同的微博信息。Kwak等讨论了微博的出现,作为一种社交网络或者是一种新闻媒介,对世界的影响[14]。并全面统计和剖析了从Twitter出现的三年来,Twitter的所有相关数据,包括Twitter的日发布量、发布总量、使用人数等。Ellen则对微文本(microtext)进行了特征分析,认为微文本具有“短”、“文法不规范”和“半结构化”等特点[15]。这些工作对研究者了解并把握微博文本的特征提供了重要依据。
在此基础上,Shen等从Twitter(www.twitter.com)、饭否网(http://fanfou.com/)和叽歪网(m.jiwai.de)下载了976 348 篇微博文本,采用TFIDF算法对中文微博文本语言进行了初步的分析和统计[16]。而Locke等则将命名实体识别引入到微博文本的研究中[17]。文章采用分类的方法,将命名实体分为三个不同的类别(人名,地名,机构名),Locke指出,微博文本由于具有与普通文本许多不同的特征,所以在进行特征选择时,应该选择微博文本所特有的特征,再进行分类。实验证明,该方法取得了一定程度的提高。
3.2 文本处理
在初步了解了微博文本的语言特点后,研究者们开始尝试对微博文本进行处理。与微博文本相关的文本处理技术有很多,在这里,我们主要介绍四个典型的课题,即文本分类和聚类、信息抽取、话题检测和情感分析。
3.2.1 文本分类和聚类
所谓微博文本的分类和聚类,就是根据微博主题的不同,将描述一类话题的微博文本聚集到一起,方便用户阅读和参考。但由于微博文本字数少,区别于普通文本的特点很多,所以在使用机器学习的方法对其进行分类或聚类时,常常会产生严重的数据稀疏问题,对性能产生影响。
于是,研究者们对解决数据稀疏问题进行了一些尝试。Sriram等考虑到微博文本区别于普通文本的特征,共选取了八类特征(即作者信息,发布时间,标志符号等)[18]。加入这些特征后,分类性能得到了显著提高,改善了数据稀疏的问题。而Liu等提出在特征选择的时候考虑词性,选择微博文本中词性丰富的词汇作为初始特征,再采取HowNet语义知识库,将这些词汇扩展到语义相关的词汇,从而达到特征扩展的目的,最终克服微博文本的数据稀疏问题[19]。实验证明,该方法获得了一定程度的提高。
另外,还有一些研究方法并不局限于对微博文本的特征选择,而是利用数据中的某些现象来提高分类或聚类效果。例如,彭泽映等通过实验分析,发现了微博数据类别中所具有的“长尾现象”,并由此提出了不完全聚类信息,可以有效地提高这类信息的聚类性能[20]。Churchill等则根据微博用户的社会关系,先对用户进行聚类,然后结合贝叶斯分类算法,利用用户聚类的结果提高分类性能[21]。类似的,M. Yoshida等首先对检索微博的查询词分类,然后再根据查询结果对检索到的微博进行分类[22],同样取得了一些提升。
上述这些研究工作只是发现和利用了微博文本中的一部分特点和现象。如果能利用尽可能多的微博文本特点,则会在特征选择的过程中尽可能多地提取特征,从而提高微博文本分类或聚类的效果。
3.2.2 信息抽取
对微博文本的信息抽取工作,其目标类似于对普通文本的信息抽取。特殊的是,由于微博文本长度较短,在对其进行处理时,通常是先将同一话题的一批微博文本聚类到一起,再抽取用户所需的信息。
B. Sharifi等首先提出了从与某一话题相关的众多微博中自动的抽取出具有概括性总结的方法[23]。文章中使用了PR(Phrase Reinforcement)算法,找到包含某一话题出现次数最多的短语作为总结句。然后B.Shrarifi等将上述文章的方法应用到了从Twitter.com网站上挖掘到的特定领域的微博资源[24]。实验结果显示,系统的效果和人工的效果很相近。
针对微博文本的信息抽取还涉及到其他相关的自然语言处理技术。例如,Petrovi′c等将事件检测技术融入到微博文本中,文章提出的方法的处理速度好于目前大多数的事件检测系统[25]。而Sakaki等借助用户行为特征,对网络微博文本进行实时监控,从而在第一时间使用户了解近期内发生的热点事件[26]。实验结果表明,该实时事件检测系统的效果较好。Zhao等对Twitter文本进行与话题相关的关键词抽取[27]。他们提出了一种基于上下文的PageRank算法,根据相关度,对与话题相关的关键词排序,最终抽取关键词。当然,微博本身还有很多有趣的信息可以提取,还有待研究者们进一步探索和思考。
3.2.3 话题检测
区别于微博的信息抽取工作,针对微博文本的话题检测则是将每个微博文本看作一个个体,然后将其与给定话题进行比较,由此得出微博的主题。
微博话题检测工作具有很重要的意义,它主要具有两方面的功能: 第一,可以使用户了解近期国内外所发生的重要事件。Sharifi等提出了自动总结微博文本主题的方法[28]。文章提出了一种基于最大公共子串的方法将含有该子串的微博聚集到一起,并最终采用该最大公共子串作为这一类微博的主题。而O’Connor等则采用文档聚类和文本摘要的技术,采用四个步骤对与检索词相关的话题进行归纳[29]。他们的成果形成了一个微博应用系统(见3.3节)。这些研究工作的贡献主要在于,为用户提供了一个平台,根据话题的不同,去了解用户感兴趣的事件。
第二,可以帮助用户在浏览微博时滤去很多无关文本,节省用户的操作时间。Ramage等采取Labeled LDA模型,将Twitter微博文本映射到substance、style、 status和social characteristics 四个潜在维,并基于上述分析结果实现了微博排序和微博推荐两个功能[30]。Weng等则采用了一种扩展自PageRank的TwitterRank算法,对在检索模型中检索到的相关微博文本,根据与话题的相似度进行排序[31]。类似的,Duan等提出用Learning to rank算法选取特征的方法,结合微博本身的内容,对微博文本和话题的相关度进行排序[32]。
但是以上工作均假定微博文本之间彼此独立,针对一个个的微博文本进行处理,并不能有效利用微博的“对话性”特点,所以有些工作还是存在着严重的数据稀疏问题。
3.2.4 情感分析
关于微博文本的情感分析工作具有十分重要的商业价值。越来越多的商家都推出了官方微博,用户可以通过其他消费者在微博上的评论信息来决定是否购买该商家的产品,同时,商家也可以根据用户的评论反馈,监督产品的市场效应。
在微博文本中,时常有表情符号出现,这种现象也给微博的情感分析工作带来了困难。Read等阐述了在情感分类问题中处理表情符号的问题[33]。文章指出,利用Twitter API可以获得大量的表情符号,而表情符号所表示的含义一般都是很明显的。如代表积极,而代表消极。
除了对表情符号的处理外,微博文本的情感分析工作主要是由机器学习方法来处理。Go等首次提出了对微博文本进行情感分析的思想[34]。文章采用无监督指导的三种机器学习方法(朴素贝叶斯,最大熵和支持向量机),将表情符号也加入到选取的特征中,取得了超过80%的分类准确率。接着Go等在他们前期工作的基础上,加入在文本中识别出的讽刺或反语句作为新特征,提升了情感分类的效果[35]。最后,Go等对微博文本的情感分析研究工作进行了总结[36],包括使用的机器学习方法,选取特征的方法,以及错误的分析方法示例。
类似使用机器学习方法来进行微博文本情感分析的研究工作还有很多。Pak 和Paroubek组织标注了一个Twitter微博文本情感极性数据集,实现了基于朴素贝叶斯、SVM和CRF的情感分类器[37]。Barbosa和Feng提出了一个两阶段Twitter文本情感极性分类方法,第一步区分主观与客观,第二步再区分积极与消极[38]。由于评测数据来自三个不同的Tweet网站: Twendz、Twitter Sentiment和TweetFeel,而三个网站对情感分类的标注不一,导致数据噪音。为解决这个问题,Barbosa和Feng对三个网站进行了分析,并设计了不同的融合策略,以最终实现较好的分类性能。而Li等则采用在线协同学习的方法,对Twitter的微博文本进行情感分类[39]。他们在不同特征的微博训练文本的基础上,训练出多个单一的情感分类器,然后,这些单一的分类器组成一个全局模型,进行情感分类。
3.3 用户行为
用户是微博系统的根本,除了对微博进行语言分析和文本处理方面的研究外,对微博系统用户的行为分析也是十分必要的。在很多情况下,一个微博系统的用户体验,是决定该微博系统成功与否的重要因素。
Ritter等提出了一种无指导建模方法,分别采取Conversation模型、Conversation+Topic模型及贝叶斯模型三种模型,从Twitter微博文本中识别八类用户的对话行为[40]。而Davidov等则提出了一种半监督的指导学习方法,识别微博文本和产品评论中的讽刺和反语句子[41]。文章采用了模板匹配和机器学习相结合的方法,抽取目标语句。但文章在分类时采用了基于标点符号的特征,特征的覆盖面较小,对分类效果产生了影响。
除了对用户行为语句的挖掘外,还有一些研究工作针对用户本身来展开。例如,判断用户自身的兴趣以及用户发布微博所在地等。Weng等通过分析网页中的Hashtags,建立基于全局的用户兴趣判定模型,从而判断用户的真正感兴趣的事物[42]。而Cheng等的研究工作十分新颖: 根据用户发布的Twitter内容,对用户目前的所在地进行判断[43]。不需要获得用户的IP地址,分析用户的发布内容,从中提取特征训练分类器,从而达到判断用户所在地的目的。但由于微博文本的自身特点,使用机器学习方法对微博文本进行处理,总会带来严重的数据稀疏问题,上述文章对数据稀疏的解决效果并不突出。
3.4 微博文本数据集
对微博文本的研究没有公认的数据集,大部分的研究工作都采用从微博网站上挖掘到的网络资源。大多数的研究工作都从Twitter网站上挖掘到大量的微博文本,然后再根据研究者的需要进行预处理。例如,上文提到的Sharifi等、O’Connor等、Ritter等都从Twitter上获得微博文本。也存在一些研究工作使用从不同的微博网站上抽取到的资源。例如,Barbosa和Feng就使用了Twendz、Twitter、Sentiment和TweetFeel网站上抽取到的微博文本,因为这三个网站对微博文本进行了一定程度的情感标注,所以对微博文本的情感分析工作有很大的帮助。
而由于中文微博文本的研究工作起步较晚,针对中文微博文本的数据集也相对较少。目前使用较广泛的中文微博网站有新浪微博、腾讯微博、搜狐微博等。
3.5 微博应用系统
关于微博文本的研究已经出现了一些成熟的演示系统。上文中所提到的O’Connor等开发了一个微博检索和话题检测聚类平台*http://tweetmotif.com/,对用户给定的查询词,系统首先生成与该查询词所相关的40个话题词或短语(短语长度不超过三个词),然后对每个话题进行检索,生成包含该话题词或短语的微博文本。
另外,Mathioudakis和Koudas也开发出了一个对微博文本进行分类,以检测其描述话题的应用系统[44]。文章首先收集相同时间段内突现的高频热门词,认为这些高频词都是在谈论同一个话题,例如,“NBA”、“湖人”、“魔术”、“比赛”这些词语在同一时间段内反复出现,则文章认为是有很多网友通过微博对一场NBA比赛进行评论。然后再通过对热门词的归类,完成对微博的分类。
4 小结
本文介绍了国内外在对微博文本研究的方法、技术和应用系统中所取得的成果。在这些研究中,主要是围绕着两大方面、四个子任务展开的。虽然在国内外所进行的微博文本研究已取得了相当的进展,但还存在着一些不足之处,主要有以下四点。
1) 尚未提出有效的数据稀疏问题解决方法。尽管有研究者采取语义词典对微博文本进行扩展,但这种拓展并不能实质扩大文本的规模。前文分析中多次提到微博文本的“对话性”。我们认为,可充分利用这一特性,有效利用微博线索中的文本,根本解决数据稀疏问题。
2) 针对微博文本不正式文法的研究并不多,尤其在汉语微博文本方面并不多见。Xia等曾对出现在聊天文本的网络语言进行了系统研究,但针对微博文本的研究尚待继续[45]。
3) 评论的数量在微博文本中占多数,为提高发帖效率,人们经常通过指代或者省略手段利用上下文,这导致大量话题省略、指代现象的出现,给话题分析和意见对象分析带来重大挑战。
4) 意见陈述极具个性化,表达非常灵活,网络语言经常出现,语法也很不规范,有时从字面难以获知主观性,这给主观性分析和意见陈述识别带来了困难。
上述问题的普遍存在,使微博文本研究与实际应用还相距较远。深入系统的研究将弥补上述研究中的不足,包括鲁棒话题分析模型、大规模微博文本处理系统等方面。同时,迫切需要一个大规模的微博文本语料库,并基于该语料库展开公开的算法评测,以推动大规模研究的开展。这对有效应对微博迅速发展、微博文本急剧膨胀的现实需求,无疑是十分重要和必要的。
[1] N. Dyke, H. Lieberman, P. Maes. Butterfly: A Conversation-Finding Agent for Internet Relay Chat[C]//Proceedings of the 4th International Conference on Intelligent User Interfaces, 1999.
[2] L. Zhou, E. Hovy. Digesting Virtual “Geek” Culture: The Summarization of Technical Internet Relay Chats[C]//Proceedings of ACL 2005: 298-305.
[3] P. Adams, C. Martell. Topic Detection and Extraction in Chat[C]//Proceedings of ICSC 2008: 581-588.
[4] D. Shen, Q. Yang,J. Sun, et al. Thread Detection in Dynamic Text Message Streams[C]//Proceedings of SIGIR’06: 35-42.
[5] 彭京,杨冬青,唐世渭,等. 一种基于语义内积空间模型的文本聚类算法[J]. 计算机学报,2007,8(30):1354-1363.
[6] 吴薇. 大规模短文本的分类过滤方法研究[D]. 北京邮电大学,2007硕士学位论文.
[7] 龚才春. 短文本语言计算的关键技术研究[D]. 中国科学院研究生院,2008博士学位论文.
[8] L. Wang. Conversation Extraction in Dynamic Text Message Stream[J]. Journal of Computers, 2008, 3(10): 86-93.
[9] X.-H. Phan, L.-M. Nguyen. Learning to Classify Short and Sparse Text & Web with Hidden Topics from Large-scale Data Collections[C]//Proceedings of WWW 2008.
[10] 黄永光,刘挺,车万翔,等. 面向变异短文本的快速聚类算法[J]. 中文信息学报,2007,21(3):63-68.
[11] 周文林. 中国微博市场催生巨大商业价值[N/OL]. 新华网. 2010年11月17日,http://news.xinhuanet.com/eworld/2010-11/17/c_12783668.htm.
[12] 网易科技. 影响2010中国互联网发展的十件大事[N/OL]. 网易科技报道. 2011年1月18日,http://tech.163.com/11/0118/15/6QMJJ4CG00094JC9.html.
[13] A. Java, X. Song. Why We Twitter: Understanding Microblogging Usage and Communities [C]//Proceedings of Joint 9th WEBKDD and 1st SNA-KDD Workshop ’07. San Jose, California, USA, 2007.
[14] Haewoon Kwak, Changhyun Lee, Hosung Park, et al. What is Twitter, a Social Network or a News Media?[C]//Proceedings of WWW2010, Raleigh, North Carolina, 2010.
[15] J. Ellen. All about microtext: A working definition and a survey of current microtext research within artificial intelligence and natural language processing[C]//Proceedings of ICAART-11. Rome, Italy: Springer.
[16] Y. Shen, C. Tian, S. Li, et al. The Grand Information Flows in Micro-blog[J]. Journal of Information & Computational Science 2009,6(2): 683-690.
[17] B. Locke. Named Entity Recognition: Adapting to Microblogging [D]. PhD Thesis, University of Colorado. 2009.
[18] B. Sriram, David Fuhry, Engin Demir, et al. Short Text Classification in Twitter to Improve Information Filtering[C]//Proceedings of SIGIR’10. Geneva, Switzerland, 2010.
[19] Z. Liu, W. Yu, W. Chen, et al. Short Text Feature Selection and Classification for Micro Blog Mining [C]//Proceedings of CiSE’2010:1-4, 2010.
[20] 彭泽映,俞晓明,许洪波,等. 大规模短文本的不完全聚类 [J]. 中文信息学报,2011, 25(1):54-59.
[21] A. L. Churchill, E. G. Liodakis, S. H. Ye. Twitter Relevance Filtering via Joint Bayes Classifiers from User Clustering [R]. University of Stanford, Dec. 12, 2010.
[22] M. Yoshida, S. Matsushima, S. Ono, et al. ITC-UT: Tweet Categorization by Query Categorization for On-line Reputation Management [R]. University of Tokyo, 2010.
[23] B. Sharifi, M.-A. Hutton, J. Kalita. Summarizing Microblogs Automatically[C]//Proceedings of NAACLHLT’2010:685-688.
[24] B. Sharifi, M.-A. Hutton, J. Kalita. Experiments in Microblog Summarization [C]//Proceedings of NAACL-HLT’2010.
[25] S. Petrovi′c, M. Osborne, V. Lavrenko. Streaming First Story Detection with application to Twitter [C]//Proceedings of HLT-NAACL’2010: 181-189.
[26] T. Sakaki, M. Okazaki, Y. Matsuo. Earthquake Shakes Twitter Users: Real-time Event Detection by Social Sensors[C]//WWW2010, Raleigh, North Carolina, 2010.
[27] W. Zhao, J. Jiang, J. He, et al. Topical Keyphrase Extraction from Twitter[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, Portland, Oregon, 2011: 379-388.
[28] B. Sharifi, M. Hutton, J. Kalita. Automatic Summarization of Twitter Topics [C]//Proceedings of National Workshop on Design and Analysis of Algorithm, Tezpur, India, 2010.
[29] B. O’Connor, M. Krieger, D. Ahn. TweetMotif: Exploratory Search and Topic Summarization for Twitter [C]//Proceedings of ICWSM 2010.
[30] D. Ramage, S. Dumais, D. Liebling. Characterizing Microblogs with Topic Models[C]//Proceedings of ICWSM’2010.
[31] J. Weng, E.-P. Lim, J. Jiang, et al. TwitterRank: Finding Topic-sensitive Influential Twitterers[C]//Proceedings of WSDM’10. New York, USA, 2010.
[32] Y. Duan, L. Jiang, T. Qin, et al. An Empirical Study on Learning to Rank of Tweets[C]//Proceedings of Coling 2010, Beijing, 2010:295-303.
[33] J. Read. Using emoticons to reduce dependency in machine learning techniques for sentiment classification [C]//Proceedings of the ACL Student Research Workshop. Association for Computational Linguistics, Morristown, NJ, 2005.
[34] A. Go, R. Bhayani, L. Huang. Twitter Sentiment Classification using Distant Supervision [R]. CS224N Project Report, Stanford, 2009.
[35] A. Go, R. Bhayani, L. Huang. Exploiting the Unique Characteristics of Tweets for Sentiment Analysis [R]. CS224N Project Report, Stanford, 2009.
[36] A. Go, R. Bhayani, L. Huang. Twitter Sentiment Analysis [R]. CS224N Final Project Report, Stanford, 2009.
[37] A. Pak, P. Paroubek. Twitter as a Corpus for Sentiment Analysis and Opinion Mining [C]//Proceedings of LREC 2010: 1320-1326.
[38] L. Barbosa, J. Feng. Robust Sentiment Detection on Twitter from Biased and Noisy Data [C]//Proceedings of COLING’2010: 36-44.
[39] G. Li, S. Hoi, K. Chang, et al. Micro-blogging Sentiment Detection by Collaborative Online Learning[C]//Proceedings of ICDM 2010, Sydney, Australia, 2010.
[40] A. Ritter, C. Cherry, B. Dolan. Unsupervised Modeling of Twitter Conversations [C]//Proceedings of HLT-NAACL’ 2010: 172-180.
[41] D. Davidov, O. Tsur, A. Rappoport. Semi-Supervised Recognition of Sarcastic Sentences in Twitter and Amazon [C]//Proceedings of CoNLL 2010.
[42] J. Weng, E. Lim, Q. He, C. Leung. What Do PeopleWant in Microblogs? Measuring Interestingness of Hashtags in Twitter[C]//Proceedings of ICDM 2010, Sydney, Australia, 2010.
[43] Z. Cheng, J. Caverlee, K. Lee. You Are Where You Tweet: A Content-Based Approach to Geo-locating Twitter Users[C]//Proceedings of CIKM 2010, Toronto, Ontario, Canada, 2010.
[44] M. Mathioudakis, N. Koudas. T. Monitor: Trend Detection over the Twitter Stream[C]//Proceedings of SIGMOD’10, New York, USA, 2010.
[45] Y. Xia, K.-F. Wong, W. Li. A Phonetic Based Approach to Chinese Chat Term Normalization[C]//Proceedings of COLING/ACL Joint Conference, Sydney, Australia, 2006, 2: 993-1000.
猜你喜欢
作文大王·低年级(2022年3期)2022-03-19
铁道通信信号(2019年6期)2019-10-08
时代英语·高二(2018年7期)2018-12-03
时代英语·高二(2018年3期)2018-06-06
小学生作文·小学低年级适用(2018年12期)2018-04-11
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
校园英语·下旬(2016年2期)2016-03-18
阅读与作文(英语高中版)(2013年12期)2013-12-11
阅读与作文(英语高中版)(2013年11期)2013-11-13
