
一种适用于机器翻译的汉语分词方法
2012-06-29 05:53:22李博渊黄书剑陈家骏
中文信息学报 2012年3期
奚 宁,李博渊,黄书剑,陈家骏
(南京大学 软件新技术国家重点实验室, 江苏 南京 210093;南京大学 计算机科学与技术系, 江苏 南京 210093)
1 引言
获取双语词对齐信息是构建统计机器翻译系统的一项重要工作。在汉英机器翻译系统中,我们首先需要对中文句子进行分词,以适应词对齐的需求。目前学术界对中文分词的研究已经取得了很大进展,从单语角度提出的衡量分词质量的F-score已经达到一个较高的水平,并且存在许多成熟的中文分词模型和工具可供使用。然而,已有研究表明,衡量单语分词质量的F-score与机器翻译系统的质量之间并无明显关联[1-2],即从单语角度而言最优的分词结果对机器翻译而言未必是最合适的。因此,寻找更适合于统计机器翻译的中文分词方法,已经成为汉语相关的统计机器翻译研究工作中的一个新方向[1-2]。
传统的分词模型通常是在人工分好词的单语语料上训练得到的。该模型虽然有效利用了单语知识,但它却忽略了一个重要事实——异种语言间的词汇意义是非同构的。如果我们用它对双语训练语料进行分词,就有可能导致分词结果中的汉语词与英文单词不能形成一一对应,进而影响词对齐和翻译的质量。
Ma et al.[3]和Paul et al.[4]试图仅从训练语料的基于字的对齐信息中学习更适合统计机器翻译的“分词”。这种方法的性能受限于基于字的对齐的质量,并且在学出的分词结果中存在大量字符序列不能被识别成词(即召回率较低)的现象,进而会对词对齐和翻译过程带来新的副作用。Ma et al.和Paul et al.在训练词对齐时,从基于字的对齐出发,通过冗繁的迭代过程交替地学习新的中文分词和对齐,并在解码器端利用源句子的多种分词结果作为输入,企图通过增大解码器的搜索空间(牺牲效率)来弥补这一损失。
本文介绍了一种融合单语和双语知识的面向汉英机器翻译的中文分词方法。首先,在训练语料的双语字对齐的基础上,通过计算字对齐可信度,得到一种基于可信对齐的分词结果;然后,用传统的基于单语的分词工具对训练语料进行分词,根据该分词结果对上述基于可信对齐的分词结果进行修正,得到基于单语和双语知识的新的分词结果。最后,用此结果重新训练新的分词模型,并将这一模型运用到统计机器翻译系统中。本文使用了基于短语的汉英统计机器翻译系统[5]对该方法进行了测试。实验表明,即使在普通的解码器上,本文的分词方法也要优于传统的分词方法,应用该方法的统计机器翻译系统的性能得到了提升。
本文第二节详细阐述基于可信对齐的分词方法,以及基于单语和双语知识的分词方法;第三节介绍实验流程和实验结果;第四节对文章进行了总结和展望。
2 基于单语和双语知识的分词模型
本文将双语对齐作为统计机器翻译中分词模型的重要知识来源。首先,我们以双语训练语料中的汉语的字为单位与英语进行双语对齐,得到基于字的对齐结果;然后,根据可信对齐得分[3](2.1节),从基于字的对齐结果中挖掘出潜在连续字串,作为基于双语知识的词(2.2节);最后,将基于双语知识的分词结果与基于单语知识的分词结果相融合(2.3节),用于训练基于单语和双语知识的分词模型(2.4节),并将新分词模型运用到统计机器翻译系统的训练集、开发集和测试集语料的分词中。
2.1 可信对齐
对于某个对齐组合a=
我们对机器翻译训练语料中的所有对齐组合a=
2.2 基于可信对齐的汉语分词
若可信对齐组合a=
如图2所示,本文在汉英字对齐的基础上,利用可信度概念,将语料中可信对齐组合的汉语部分合并成“词”(图中浅色对齐标示部分),非可信对齐部分保持单字不变(图中黑色对齐标示部分)。我们将这种分词方法称为“基于可信对齐的分词”。
方法的全部流程如下:
• 首先,将原始双语训练语料中的汉语部分按字进行切分,利用词对齐工具得到训练语料的基于字的对齐结果;
• 其次,取对齐结果中的所有可信对齐组合ai=
• 最后,将双语训练语料中所有候选词字符集分别合并成词,得到“分好词”的新语料。
图1展示了训练语料中的一个句对的基于可信对齐的分词结果。其中的中文句子含有汉字33个(不包括阿拉伯数字和标点符号),使用分词结果识别出10个词(不包括句号),共含汉字17个,占总字数的51.5%。可以看出,基于可信对齐分词方法的分词召回率较低,远不能满足统计机器翻译的需求。
2.3 基于可信对齐的分词与基于单语的分词相融合
从2.2节可以看出,可信对齐分词方法具有较低的分词召回率。为此,本文将可信对齐的分词结果和基于单语知识的分词结果进行融合,过程如图2所示。

图1 基于可信对齐的分词结果

图2 融合了单语知识的可信对齐分词法示例
对于一个待分词句子,分别利用可信对齐分词方法和单语分词方法对齐进行分词,然后将两种分词结果用投票的方式进行合并。合并时,从左到右遍历单语分词结果中的每一个词,如果遇到当前词和可信对齐分词结果中识别出的词(浅色部分)不一致,则用可信对齐分词的结果去修正单语分词的结果。例如,“公司”是可信对齐分词方法识别出的词,因此单语分词方法结果中的“集团公司”一词将修正为“集团 公司”两个词。
为表述简便,本文后续部分将可信对齐分词与单语知识分词融合的方法称为“基于单语和双语知识的分词”。
2.4 分词工具训练
在统计机器翻译系统中,训练语料、开发集语料和测试集语料的分词需要保持一致,才可能得到较好的性能。然而,开发集语料和测试集语料中的中文源句子,由于缺乏与其平行的英语句子,使其无法直接应用2.3节提出的基于可信对齐的分词方法。因此,需要寻找一种新的分词方法来对训练和测试语料进行分词,并且新方法应满足如下条件:(1)新方法中应包含双语知识信息; (2)新方法能对中文单语语料分词。
本文通过使用条件随机场分词模型[6-8]来解决开发集和测试集的分词问题。
• 通过本章2.3节描述的方法,从双语训练语料中得到“分好词”的中文语料;
• 将该语料作为训练语料,用条件随机场训练分词工具;
由于使用了可信对齐分词和单语知识分词相结合的结果作为训练语料,故在训练得到的模型中一定包含双语知识信息。而条件随机场分词模型本身可以对仅含中文的单语语料进行分词。因此,通过上述方法得到的分词工具满足本文所提的条件。本文的实验部分将以此分词工具得到的分词结果作为本文的最终分词结果。
本文使用CRF++*httphttp://crfpp.sourceforge.net/作为条件随机场模型的训练工具。采用四字位标注法[9](见表1所示)和基于子串的序列化标注方法进行分词[10],其中子串部分为基于规则识别出的英文单词和表示数字的词。分词模板如表2所示。
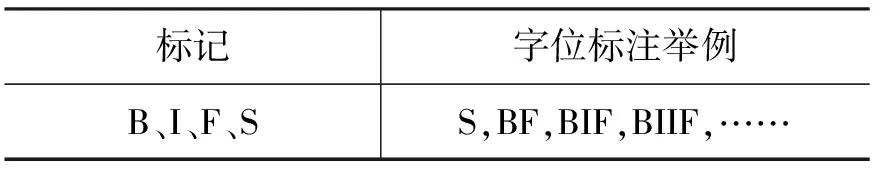
表1 四字位标注集的定义
在四字位标注法中,用B表示词首,I表示词中,F表示词尾,S表示单字词。

表2 CRF分词工具采用的模板
表2中表示单个字符作为特征,n=0表示当前字符,n=-1表示当前字符的前一个字符,n=1表示当前字符的后一个字符。CnCn+1表示相邻的两个字符组合作为特征。C-1C1表示当前字符的前后字符组合作为特征。F(Cn)的值表示该字符是否是汉字、标点或者子串。
3 实验步骤及结果3.1 数据和实验环境
本文利用人工切分过的1998年1至6月份的《人民日报》语料,作为基于单语知识的分词工具的训练语料,从LDC2003E14语料中选取了19万句中英平行句对作为统计机器翻译系统的训练语料。使用NIST’06测试集作为系统的开发语料,NIST’08测试集作为测试语料。使用SRILM对Gigaword中的Xinhua部进行分训练,得到了一个五元语法模型作为机器翻译系统的语言模型。
本文用条件随机场模型在上述《人民日报》的语料上训练出一个分词工具,成为CRF-Based。随后在机器翻译系统的训练语料上,用GIZA++训练得到汉语单字与英文单词的对齐结果。然后用第二`节所述的方法训练基于双语知识的分词工具。本文尝试将可信对齐分词的结果与不同单语分词工具得到的结果相结合(CRF-Based、ICTCLAS*http://www.ictclas.org/、Stanford Chinese Segmenter*http://nlp.sttanford.edu/software/segmenter.shtml),训练不同的基于双语知识的分词工具,并将其用于统计机器翻译系统。
在机器翻译系统方面,本文采用了一个类似Moses的基于短语的统计机器翻译系统,并采用最小错误率训练方法(minimum error rate training,MERT)[11]进行参数训练。最后用系统翻译结果的BLEU得分[12]对系统性能做出评价。
3.2 单语知识分词
本文首先使用《人民日报》1998年1至5月份人工切分过的语料作为CRF的训练语料,训练得到分词模型CRF-Based,并使用《人民日报》6月份的语料对CRF-Based进行测试。表3给出了测试结果,其中F-score按照下列公式进行计算,β=1。

表3 CRF-Based 性能表
3.3 机器翻译实验
本文首先使用CRF-Based对统计机器翻译使用的训练集,开发集和测试集等语料进行分词,构建基于短语的统计机器翻译系统,将其作为基线系统。经测试,基线系统的BLEU得分为21.82(如表4第一行所示)。
接下来,本文用2.4节所描述的CRF模板,以双语语料的可信对齐分词结果作为分词训练集,训练得到基于可信对齐的CRF分词模型,称为AC-Based。我们用AC-Based对机器翻译的训练集,开发集和测试集进行重新分词,该系统的BLEU得分为21.05(如表4第二行所示)。可以看出,纯粹的基于双语知识的可信对齐分词会产生大量的未识别字符,这些单字词的存在,影响了词对齐的质量,进而损害了机器翻译的性能。
根据2.3节所述的方法,本文将上述基于双语知识的可信对齐的AC-Based分词结果与基于单语知识的CRF-Based分词结果相融合,并将其结果作为分词工具训练语料,利用2.4节所描述的模板训练得到基于单语和双语知识的分词模型AC+CRF。并使用AC+CRF对机器翻译使用的训练集,开发集和测试集等语料进行分词,系统的BLEU得分为22.46。可见,使用本文所提的分词方法,可以使统计机器翻译系统的性能得到提升。
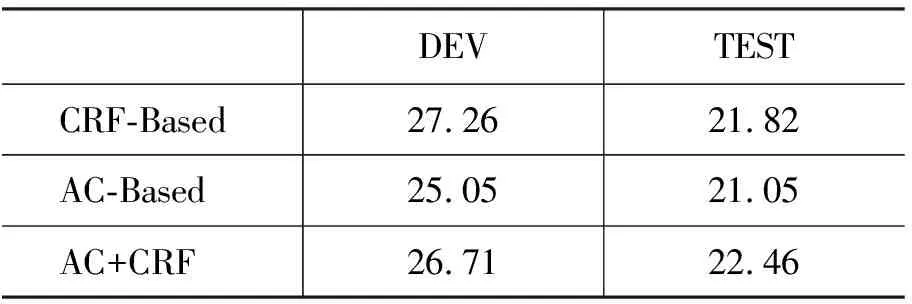
表4 各种分词方法在SMT中的表现
为探讨AC+CRF使机器翻译性能提高的原因,我们将CRF-Based与AC+CRF的分词结果进行了对比,如表5所示。
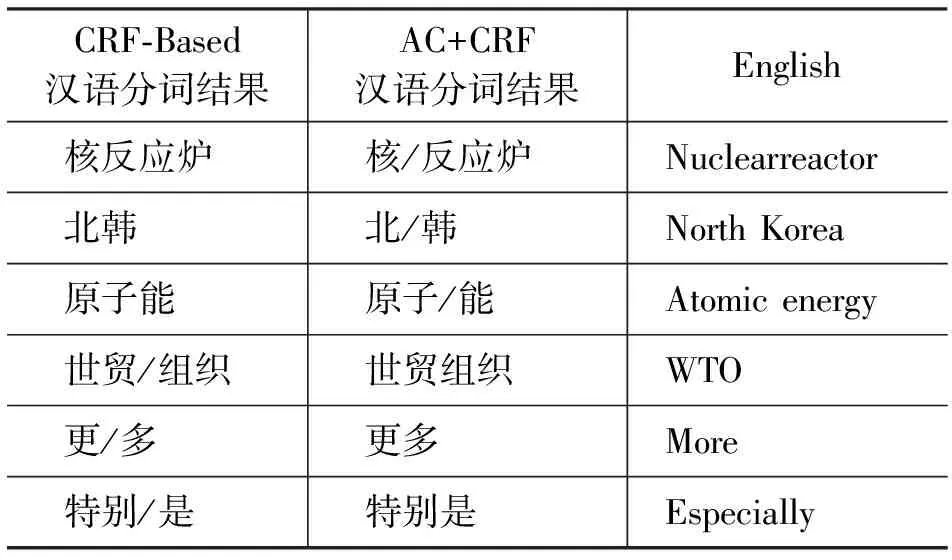
表5 CRF-Based与AC_CRF分词示例
由表5可见, AC+CRF方法得到的分词结果,能使汉语词和英文单词之间的对应关系更能形成一一对应的关系。因此能够得到比CRF-Based分词更高的翻译性能。
为了进一步验证本方法的可扩展性,本文将基于双语知识的可信对齐分词结果与不同的单语的分词工具分词结果(ICTCLAS、Stanford Chinese Segmenter)相融合,分别训练不同的分词模型,并将这些模型用于统计机器翻译系统训练集,开发集和测试集的切分。表6给出了融合不同单语分词模型的机器翻译系统的性能,可以看出,无论是和哪种单语分词工具相结合,基于单语和双语知识分词的系统总是优于基于单语分词工具的机器翻译系统。
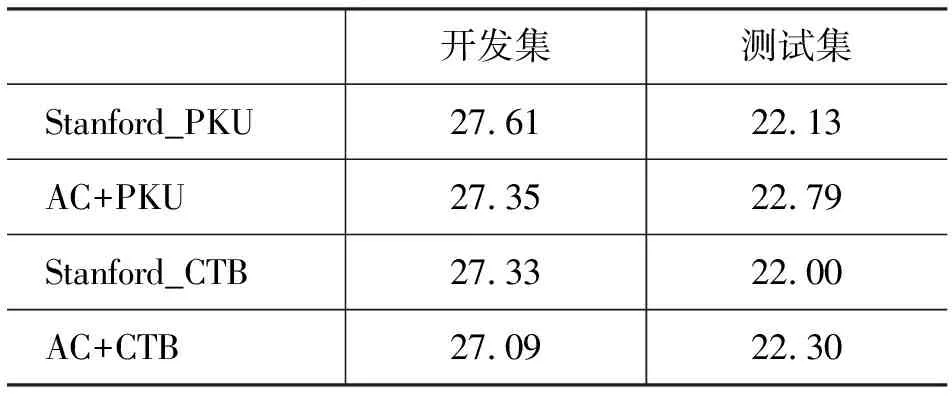
续表
AC+ICT为可信对齐结合ICTCLAS的结果,AC+PKU和AC+CTB分别为可信对齐结合Stanford Chinese Segmenter 中PKU模型和CTB模型的结果。
4 总结
本文从汉英机器翻译中的中文分词工作入手,旨在寻找一种更适应于机器翻译系统的分词方法。本文通过对基于单语知识的分词和基于双语可信对齐的分词的进行了分析,提出了一种新的结合了单语和双语知识的分词方法。与传统分词方法相比,本文提出的分词方法可以使汉语词与英文单词间的对应关系更加明确,具有更好的机器翻译性能。
由于训练模板的限制,我们提出的分词模型并不能达到100%的准确率。其中包含的分词错误仍然会影响机器翻译的性能。另一方面,基于Lattice[13]的解码已经得到广泛讨论,基于Lattice的解码方法可以摆脱机器翻译解码时对某一种分词结果的依赖。因此,在未来的工作中,我们将尝试将本文的分词方法和基于Lattice的解码相结合,以克服分词错误对系统性能带来的影响。
[1] Pi-Chuan Chang, Michel Galley, Christopher D. Manning. Optimizing Chinese word segmentationfor machine translation performance[C]// Proceedings of the Third Workshop on Statistical Machine Translation, 2008: 224-232.
[2] Ruiqiang Zhang, Keiji Yasuda, Eiichiro Sumita. Improved statistical machine translation by multiple Chinese word segmentation[C]// Proceedings of the Third Workshop on Statistical Machine Translation, 2008: 216-223.
[3] Yanjun Ma, Andy Way. Bilingually Motivated Domain-Adapted Word Segmentation for Statistical Machine Translation[C]// Proceedings of the 12th EACL, 2009: 549-557.
[4] Michael Paul, Andrew Finch, Eiichiro Sumita. Integration of Multiple Bilingually-Learned Segmentation Schemes into Statistical Machine Translation[C]// Proceedings of the Joint 5th Workshop on Statistical Machine Translation and MetricsMATR, 2010: 400-408.
[5] Philipp Koehn, Franz Josef Och, Daniel Marcu. Statistical Phrase-based translation[C]// Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology, 2003: 923-940.
[6] John D. Lafferty, Andrew McCallum, Fernando C. N. Pereira. Conditional Random Field: Probabilistic models for segmenting and labeling sequence data[C]// Proceedings 18th International Conference on Machine Learning, 2001: 282-289.
[7] Fuchun Peng, Fangfang Feng, Andrew McCallum. Chinese segmentation and new word detection using Conditional Random Fields[C]// Proceedings of the 20th international conference on Computational Linguistics, 2004: 562-568.
[8] Jun-Sheng Zhou, Xin-Yu Dai, Rui-Yu Ni, et al.. A hybrid approach to Chinese word segmentation around CRFs[C]// Proceedings of the Fourth SIGHAN Workshop on Chinese Language Processing, 2005: 196-199.
[9] Franz Och. Minimum error rate training in statistical machine translation[C]// Proceedings of the 41st Annual Meeting of the Association for Computational, 2003.
[10] Kishore Papineni, Salim Roukos, ToddWard, et al.. BLEU: a Method for Automatic Evaluation of Machine Translation[C]// Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, 2002: 311-318.
[11] Nianwen Xue, Libin Shen. Chinese word segmentation as LMR tagging[C]// Proceedings of the Second SIGHAN Workshop on Chinese Language Processing, 2003: 176-179.
[12] 赵海, 揭春雨. 基于有效子串标注的中文分词[J].中文信息学报, 2007, 21(5):8-13.
[13] Christopher Dyers, Smaranda Muresan, Philip Resnik. Generalizing word lattice translation[C]// Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics, 2008: 1012-1020.
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
智富时代(2019年6期)2019-07-24 10:33:16
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
海外华文教育(2016年1期)2017-01-20 08:21:58
高中生·天天向上(2016年9期)2016-11-22 09:10:34
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
