
基于Web挖掘的图书馆个性化服务系统研究
2012-06-05 03:21唐秋鸿曹红兵唐小新李高虎
合肥工业大学学报(自然科学版) 2012年2期
唐秋鸿, 曹红兵, 唐小新, 李高虎, 高 嵩
(1.暨南大学 管理学院,广东 广州 510632;2.广西大学 图书馆,广西 南宁 530004;3.北京邮电大学 资产经营公司,北京 100876)
0 引言
个性化服务的实质是一种以用户需求为中心的服务[1],它不仅可以有效地解决用户“信息过载”与“信息迷航”问题,而且可以极大地提高图书馆的服务质量和资源的有效利用,因此成为当前图书馆新型服务模式的主流,而个性化服务系统则成为图书馆数字化、网络化服务的必然选择。
目前,国内外图书馆个性化服务系统正在起步,较具代表性的图书馆个性化服务系统有美国康奈尔大学图书馆的 Mylibrary@Cornell、北卡罗莱那州立大学图书馆的Mylibrary@Ncstate、洛杉矶国际研究实验室图书馆的Mylibray@LANL、浙江大学图书馆的MyLibrary、深圳图书馆的ILAS“我的图书馆”、中国国家图书馆的“我的图书馆”、中国人民大学图书馆的Kingbase DL和华中科技大学图书馆的Mylibrary@HUST等。这些系统的功能主要包括对资源的链接、定制、检索、最新资源通告以及文献传递等[2-4]。而基于Web日志挖掘技术的个性化服务系统的研究也开始出现。文献[5]提出应用Web日志挖掘技术可以帮助提高个性化推荐系统的可伸缩性、精确性和灵活性。文献[6]提出了一个两步Apriori改进算法,可对用户的 Web访问进行贴身指导。文献[7]提出了一个智能算法,能从Web访问日志中自动挖掘用户的访问轨迹。文献[8]提出了一个基于用户访问时间和访问密度的用户偏好算法,可以更精确地发现用户偏好。文献[9]采用OLAP技术和数据挖掘技术对用户的访问模式和趋势进行了挖掘,从而提高了Web系统的性能。文献[10]给出了一种基于项目与客户聚类的协同过滤推荐方法,增强了推荐算法的实时性,提高了推荐服务的质量。
但是,现有的图书馆个性化服务系统功能明显不能满足用户需求,而当前大多数 Web日志挖掘方面的研究缺乏对图书馆个性化系统的支持,或者只关注于算法、性能等技术层面,对图书馆用户个性化模型的深度挖掘不足,从而导致图书馆个性化系统的个性化服务水平低,个性化应用效果不够明显。
本文通过运用Web日志挖掘技术对用户在图书馆OPAC环境下的信息使用行为、习惯进行深度挖掘,构建一种动态的读者信誉度评估机制,用以科学地划分图书馆用户群体,设计能提供满足其个性特征和需求的个性化服务功能及其组合,以便为进一步开发与应用图书馆个性化服务系统提供技术基础。
1 系统结构与评估模型
1.1 图书馆个性化服务系统结构
在分析总结当前常见的图书馆个性化服务方式与类型的基础上,本文提出了一个兼顾虚拟与物理世界信息服务的图书馆个性化服务系统结构模型,如图1所示,以期为图书馆用户提供一个全方位、多角度、立体化、智能化及人性化的个性化信息服务。

图1 图书馆个性化服务系统结构
所构建的图书馆个性化服务系统由虚拟个性化服务和物理个性化服务2大部分组成。前者主要指以图书馆和网络虚拟资源为基础,利用网络为不同的用户提供基于图书馆虚拟环境的个性化服务,它又包括个性化定制服务、个性化推送服务、个性化检索服务、个性化收藏服务、个性化信息聚合服务、个性化知识管理服务、个人历史信息管理服务和个人账户管理服务。后者主要指以图书馆实体资源为基础,为用户提供基于图书馆物理环境的个性化服务,它又包括6个组成部分,即一卡通管理服务、智能识别服务、智能定位服务、智能导读服务、自助服务和电话服务。虚拟个性化服务和物理个性化服务两者相互结合,互为补充,并通过RFID电子标签进行信息交流,共同为用户打造一个全面、立体、融合物理与虚拟世界的个性化服务空间[11]。
1.2 图书馆读者信誉度评估模型
图书馆读者信誉度是指读者在使用图书馆资源与服务的过程中,对图书馆资源与服务的利用情况及其对图书馆各项规章制度的遵守程度并因此影响其第2次使用的各种因素的总和。因此,读者入馆情况、读者对图书馆文献资料的借阅、查询、浏览、下载及对所借文献资料按时归还的情况、对图书馆文献资料完整性的保护程度,以及对图书馆公共服务设施的使用情况等,都应当纳入图书馆读者信誉度评估体系之中,如图2所示,以形成系统的读者信誉监督机制,并用以更好地划分图书馆用户群体,从而支持图书馆的个性化服务,提升图书馆的服务效率和水平,进而提高读者的满意度。

图2 图书馆读者信誉度评估模型
随着图书馆文献信息服务手段的不断进步,日益暴露出图书馆读者信誉评价研究上的缺失,即决策手段不足、缺乏数据支持、服务方式单一、应用领域狭窄等。因此,基于图书馆流通业务系统中读者借阅、罚款等日志记录,即利用读者对图书馆文献资料的借、还、约和滞还、丢失、损坏、赔偿等日志记录,通过数据挖掘方式,构建形成一种动态的读者信誉度评估机制,并用以科学划分读者群,从而为图书馆个性化服务系统的功能设计和开发提供依据和决策支持。
2 图书馆读者信誉度的数据挖掘
2.1 数据挖掘处理逻辑
读者信誉度的数据挖掘主要是指运用Web日志挖掘技术,对图书馆流通业务系统中一定周期内读者的借阅、归还、罚款等日志记录进行挖掘,并通过使用聚类分析、异常检测分析等方法来分析处理挖掘结果,最终形成一种动态的读者信誉度评估机制的过程。读者信誉度的数据挖掘的主要思想和方法是:从大量的流通日志历史记录(D)中,汇总所有读者某一时间段(T)内借、还、约文献资料的总次数(F)和因滞还、丢失、损坏文献资料而被罚款的总金额(P),再利用数据挖掘聚类分析方法对这三者之间的关系进行分析,以形成一个动态的读者信誉度评估体系,用以科学地划分读者群,从而指导图书馆个性化服务系统的功能设计和开发。具体挖掘流程如图3所示。
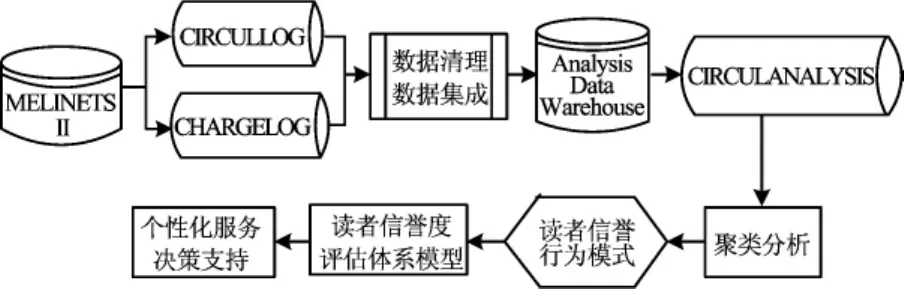
图3 读者信誉度的数据挖掘流程
读者信誉度的数据挖掘流程主要包括:
(1)对图书馆流通业务系统 MELINETSⅡ数据库中的2个日志表CIRCULLOG_A和CHARGE_LOG_A进行分析。其中,CIRCULLOG_A是记录读者借、还、约文献资料等借阅行为的流通日志表;CHARGE_LOG_A是记录读者因滞还、丢失、损坏文献资料而被罚款等信息的罚款日志表。通过对上述2个日志表中的数据进行分析,再根据数据字典中各字段表示的含义进行数据清理和数据选择,为下一步数据仓库的建立准备所需的数据。
(2)在Oracle Database 10g R2数据库环境中,建立数据仓库方案 Analysis Data Warehouse,并在该方案下创建数据挖掘表CIRCULANALYSIS。
(3)选择ODM(Oracle Data Mining)数据挖掘工具进行挖掘,再利用聚类分析(Cluster Analysis)和异常检测分析 (Anomaly Detection)方法分析处理挖掘结果,形成初步的读者信誉度评价体系。
(4)利用图书馆流通、采访等业务部门抽样调查与用户个人信息相结合的方式对以上所形成的读者信誉度评价体系进行评估,并将评估后的读者信誉度评价体系应用于图书馆用户群体的划分,从而为开发与利用图书馆个性化服务系统奠定技术基础。
2.2 挖掘算法的选择与应用
数据挖掘算法繁多,仅在聚类分析方面,就有Beefman聚类法、神经网络聚类法、模糊聚类法、加权聚 类 法 等[4,12-13]。因 此,在 建 立 用 户 个性化服务模型的过程中,必须根据不同的挖掘任务需求,研究选用适宜的数据挖掘算法,以便实现最佳的数据挖掘效果。本文主要通过使用聚类分析方法,对从图书馆流通业务系统中大量的Web流通日志记录挖掘得到的结果进行分析,来形成一种动态的读者信誉度评估机制。所谓聚类分析方法,是指根据数据对象间相似性条件的满足与否进行数据划分,并把物理或抽象对象的集合组成由类似对象组成的多个类或簇的一种数据分析方法。聚类分析所划分的类或簇的数量与类型均是事先未知的、非预定的。由聚类生成的簇是一组数据对象的集合。同一簇中的对象尽可能相似[14],使得组间的差别尽可能大,组内的差别尽可能小。簇与簇之间可以按照给定的聚类参数(如距离等)进行分解和合并。因此,可以将聚类分析方法应用于图书馆读者群体的聚集和划分,以及读者集群特性的分析等。
聚类分析的算法主要有k-中心点算法和k-平均算法(即k-means算法)2种。在k-中心点算法中,每个簇用接近聚类中心的一个对象来表示;而在k-means算法中,每个簇用该簇中对象的平均值来表示。本文采用k-means算法来对读者信誉度挖掘结果进行分析。
在k-means聚类分析算法中,假定Ni为第iP聚类ci中的样本数目,mi是样本的均值。若分成k类,则各聚类的均值表示为:
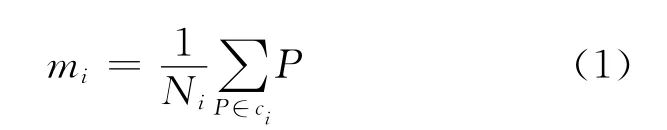
误差平方和为:

其中,E为观测数据中所有对象平方误差综合;P为空间中的点;mi为聚类ci中的平均值(P和mi是多维的)。对于不同的分类,k值不同,则E值就不相同,使E达到最小的分类数k被认为是当前的目标数[15-16]。
2.3 挖掘结果与分析
本文通过在Oracle Database 10g R2数据库环境中创建数据仓库,利用ODM数据挖掘工具,对广西某高校图书馆MELINETSⅡ系统中2010年的173.45×104条流通日志记录和20.5×104条罚款日志记录进行了挖掘,并采用聚类分析和异常检测分析算法,对读者行为进行了聚类分析,获得的聚类分析结果见表1所列。
依据表1中的挖掘结果,建立了一种基于MELINETSⅡ平台的动态的图书馆读者信誉度评估机制:全部读者按照其一定时间内(如以半年或一年为单位统计)借还总次数和罚款金额数的情况划分信誉等级,一共划分成5个等级,以信誉星级来标识。按信誉度从高到低,依次可分为五星级、四星级、三星级、二星级和一星级。
例如,可将1年内借还总次数少于20次,罚款金额低于5.73元(见表1聚类3)的读者划分为二星级读者;而将1年内借还总次数少于58次,罚款金额高达57.33元(见表1聚类9)的读者划分为一星级读者。星级越低,说明读者在该时间段内的信誉度越低,且使用图书馆资源与服务的频率越低。

表1 读者行为聚类分析结果
3 模型应用
将读者按照上述信誉星级划分为不同的用户群体后,通过深入分析不同群体的信息使用行为和特点,建立相应时间段内的动态的用户需求模型;根据用户需求模型,图书馆可以提供能满足不同信誉星级读者群体需求及特点的个性化服务功能或其组合,如图4所示。

图4 基于读者信誉度评估模型的图书馆个性化服务功能
通过分析发现,四星或五星级读者信誉度较高,熟悉并遵守图书馆的各项规章制度,熟悉并经常使用图书馆提供的各种资源与服务,是图书馆主要依靠和重点保障的VIP读者。对于这部分读者,图书馆要竭尽全力、充分利用各种现代化信息技术和手段,为他们提供所需要的资源与服务,以最大限度地满足其个性化服务需求。为此,图书馆可通过增加这部分读者的馆藏文献借阅册数和借阅期限,并为其提供更多、更灵活的个性化定制、推送、收藏、检索,以及个人知识管理和个人信息管理(如Email定制、手机短信定制、手机短信推送、手机短信查询、移动阅读、移动数据库检索、移动数字化多媒体馆藏借阅、移动音频导航服务、自助服务,以及SNS、博客、播客、评论、标签等Lib2.0功能等)服务功能,实现其个性化服务目标。
而一、二星级读者信誉度较差,不太熟悉图书馆的各项规章制度和所提供的各种资源与服务,且较少使用图书馆的资源与服务,是图书馆要努力争取和培养的惰性读者和潜在VIP读者。对于这部分读者,图书馆要想方设法促使其更多地利用图书馆的资源与服务,并自觉遵守图书馆的各项规章制度。为此,图书馆可采取在一定时间内减少其馆藏文献借阅册数和借阅期限,并加强图书超期提醒、个人借阅信息推送和新生培训、“怎样利用图书馆”和数据库专题讲座等各种培训信息的推送以及多种形式的多媒体培训课件、培训视频文件、在线实时培训等培训服务,以及FAQ、Email咨询、手机短信咨询、在线实时咨询等各种咨询服务和新书通报、好书推荐、专题导航、学科导航、课程导航等各种资源推荐和导航服务来实现其服务目标。
4 结束语
读者信誉度评估体系维系着读者对图书馆的信誉度和忠诚度,是图书馆服务和管理工作的重点,也是图书馆从被动、通用性服务向主动、智能化、个性化服务转型要解决的重要问题之一。本文提出了一个兼顾虚拟与物理世界信息服务的图书馆个性化服务系统结构模型及读者信誉度评估模型,采用 Web日志挖掘技术对图书馆MELINETS系统中大量的Web流通日志记录进行了挖掘,构建了一种能反映不同用户个体和群体信息使用行为、习惯及其变化特征的动态的读者信誉度评估机制,用以科学地划分读者群,根据不同信誉星级读者群体的不同特点和需求,设计了能提供满足其个性特征和需求的个性化服务功能及其组合。这些工作为进一步开发与应用图书馆个性化服务系统提供了技术基础。
[1]崔 林,宋瀚涛,龚永罡,等.基于 Web使用挖掘的个性化服务技术研究[J].计算机系统应用,2005(3):23-26.
[2]吕艳丽.基于Web使用挖掘的图书馆个性化系统研究[J].图书馆学刊,2006(4):135-137.
[3]钱 力.数字图书馆个性化信息服务系统的研究与设计[D].北京:首都师范大学,2008.
[4]李雪倩.Web使用记录挖掘在数字图书馆个性化服务中的应用研究[D].哈尔滨:黑龙江大学,2008.
[5]Mobasher B,Cooley R,Srivastava J.Automatic personalization based on Web usage mining[J].Communication of the ACM,2000,43(8):142-151.
[6]Lazcorreta E,Botella F,Fernández-Caballero A.Towards personalized recommendation by two-step modified Apriori data mining algorithm[J].Expert Systems with Applications,2008,35(3):1422-1429.
[7]Tug E,Skiroglu M,Arslan A.Automatic discovery of the sequential accesses from Web log data files via a genetic algorithm [J].Knowledge-Based Systems,2006,9(3):180-186.
[8]Wang Shuqing,She Li,Liu Zhen,et al.Algorithm research on user interests extracting via Web log data[C]//2009International Conference on Web Information Systems and Mining,WISM 2009,2009:93-97.
[9]Zaiane O R,Xin Man,Han Jiawei1.Discovering Web access patterns and trends by applying OLAP and data mining technology on Web logs[C]//Proceedings of the 1998IEEE Forum on Research and Technology Advances in Digital Libraries,ADL,1998:19-29.
[10]张 娜,何建民.基于项目与客户聚类的协同过滤推荐方法[J].合肥工业大学学报:自然科学版,2007,30(9):1159-1162.
[11]曹红兵,唐秋鸿,唐小新,等.物联网环境下的高校图书馆个性化服务体系构建[J].情报理论与实践,2011,34(3):70-76.
[12]李亚飞,刘业政.Web挖掘的体系研究[J].合肥工业大学学报:自然科学版,2004,27(3):305-309.
[13]李超锋.Web使用挖掘关键技术研究[D].武汉:华中科技大学,2007.
[14]罗 可,蔡碧野,吴一帆,等.数据挖掘中聚类的研究[J].计算机工程与应用,2003(20):182-184,218.
[15]高孝梅.基于聚类分析的图书馆读者阅读习惯调查[J].情报探索,2010(12):11-12.
[16]张建民,姚 亮,胡学钢.一种面向数据缺失问题的K-means改进算法[J].合肥工业大学学报:自然科学版,2008,31(9):1455-1457.
猜你喜欢
华人时刊(2021年13期)2021-11-27
大众投资指南(2021年35期)2021-02-16
心声歌刊(2020年4期)2020-09-07
物联网技术(2018年2期)2018-03-03
小学生(看图说画)(2017年6期)2017-11-06
电力与能源(2017年6期)2017-05-14
大观(2016年12期)2017-04-15
淮海医药(2015年2期)2016-01-12
信息通信技术(2015年6期)2015-12-26
中国经贸导刊(2014年11期)2014-05-27
