
基于数学模型的关联规则实用性测度指标在养猪过程中的应用
2012-06-02 09:31王越,邢茜
重庆理工大学学报(自然科学) 2012年1期
王 越,邢 茜
(重庆理工大学计算机科学与工程学院,重庆 400054)
随着计算机技术、网络技术、人工智能与模式识别技术的发展,各领域的信息化建设也不断向前推进。而信息化建设以及信息技术的应用,使各领域积累了海量的数据。在数据仓库技术的支持下,这些海量数据可以通过联机(在线)分析处理(online analaytic processing,OLAP),为决策者提供可行的决策依据。但对于潜在的、不明显的数据关系,就不能直接应用OLAP算法,例如经典的购物篮问题。关联规则(association rule)挖掘是数据挖掘的一项重要任务,其目的就是从事物数据库、关系数据库中发现项目集或属性之间的相关性、关联关系和因果关系。
生长肥育阶段的猪所消耗的饲料占全期耗料的70%~75%,如果在该阶段采用有效的饲料配方和饲料调制,必将大幅度提高生产效益。在强调猪胴体总重的同时,还必须满足消费者要求,即提供高品质、低脂肪、高瘦肉率的胴体。由于动物生产性能、健康状况、体重、采食量、环境及其他因素的差异,不同品种猪的差别极大。只有相应调整饲料的调制方法,不同品种的猪才可能表现出其生长的潜在优势,因此,在猪场易于收集的数据中提取相关样本数据,并与计算机技术进行结合,从而可以对猪群的整体新城代谢情况和生长状况进行诊断,为及时调整饲喂方式提供依据。本研究利用数据挖掘中的关联规则分析以及有效性和实用性分析,对大量数据进行挖掘,揭示出数据间隐藏的依赖关系。
1 关联规则
1.1 关联规则基本概念及形式
关联规则最早由 Agrawal、Imielinski和Swami提出,既可用于挖掘寻找给定数据集中项之间的关联关系,也可用于挖掘直观的表达数据中项集间的关系。关联规则的一般形式是:
X→Y(规则支持度,规则置信度)
其中:X称为规则前项,可以是一个项目或项集,也可以是一个包含逻辑与(∪)、逻辑非(~)的逻辑表达式;Y称为规则后巷,一般为一个项目,表示某种结论或事实。例如,面包→牛奶,前项和后项均为一个项目。这种规则表示方式适合于事务数据组织成事实表的情况,表示购买面包和牛奶,即购买面包则会购买牛奶。
1.2 Apriori算法
Apriori算法是基本的关联规则挖掘算法。为了减少候选数据项集的数目,Apriori算法使用逐层搜索的方法,通过对数据库D的所有事务数据项扫描来发现所有的频繁项目集,大致可分为2步:
1)连接(类矩阵运算):通过将2个符合特定条件的k项频繁集作连接运算,从而寻找k+1项频繁项集,而这些频繁项集是发现关联规则的基础。
2)剪枝:去掉那些没必要的中间结果,即通过引入一些经验性或经数学证明的判定条件,来减少一部分不必要的计算步骤,提高算法效率。
1.3 关联规则的有效性
依据样本数据可以得到很多关联规则,但是并不是所有的关联规则都是有效的。换句话说,有的规则并不足以让人们信服。那么,判断一条关联规则是否有效,应依据各种测度指标,其中最常用的指标是关联规则的置信度和支持度。
1)规则支持度(support)。规则支持度是指在事物数据库D中包含项目集X的事物占整个事物的比例,记为sup(X),看作是项目集X在总事务中出现的频率,其数学表示为

其中:|T|表示总事务数;|T(X∩Y)|表示同时包含项目X和项目Y的事务数。支持度应用于发现频率出现较大的项目集,体现“项目集相对总事物所占的比重”。支持度太低,说明规则不具有一般性。
2)规则置信度(confidence)。规则置信度是指在事物数据库D中,同时包含项目集X和Y的事物与含项目集X的事物的比,看作是项目集X出现,使项目集Y也出现这一事件在总事物中出现的频率,其数学表示为

其中T(X)表示包含项目X的事务数。可信度应用于在出现频率较大的项目集中发现频率较大的关联规则,体现“项目集在另一项目集影响下相对总事物所占的比重”。例如,如果面包→牛奶(S=85%,C=90%),则表示购买面包则同时购买牛奶的可能性为90%。
关联规则挖掘就是在D中找出满足指定的最小支持度min_sup和最小可信度min_conf的所有关联规则,它们之间具有内在联系,即

也就是说,包含项目X的事物中可能同时包含项目Y,也可能不包含。规则置信度反映的是其包含项目Y的概率,是规则支持度与前项支持度的比。
1.4 关联规则的实用性
通常情况下,如果规则置信度和支持度大于用户指定的最小置信度和支持度,那么这个规则就是一条有效规则。事实上,有效规则在实际应用中并不一定实用,也就是说,有效规则未必具有正确的指导意义。
例如,在猪场数据中,通过关联规则分析发现,断奶日龄在20~25 d之间的仔猪,出栏体重40%未达到一级标准,即:断奶日龄(20~25 d)→体重(未到一级标准)(S=40%,C=40%)。如果用户指定的最小置信度和支持度为20%,表面上看该规则是一条理想规则,但是进一步计算发现,此时出栏中体重未达到一级标准的猪也为40%,即后项支持度为40%,也就是说,体重未达到一级标准的仔猪(断奶日龄20~25 d)比例与所有未达到一级标准的猪的比例一致,此时所反映的只是一种前后项无关联下的随机性关联,并没有提供更有意义的科学指导,因此不具有实用性。
因此,规则置信度和支持度只能分析出一条规则的有效性,但是并不能衡量是否具有实用性和实际意义。在上述例子中,猪场养殖户更希望通过关联规则分析出具有实际意义的规则,以提高其养殖效益。
1.5 基于数学模型的实用性测度指标
1)信誉度(prestige)。信誉度是置信度和后项支持度的比,其数学表达式为
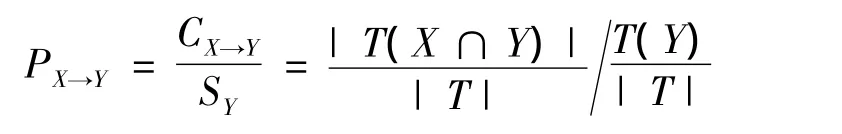
信誉度反映了项目X的出现对项目Y(研究项)出现的影响程度,一般大于1才有意义,意味着X的出现对Y的出现有促进作用,因此,信誉度越高越好。对于上述提出的问题,信誉度为40%/40%=1,虽然该规则是有效的,但并没有意义。
2)置信差(confidence different)。置信差与信誉度类似,也利用了后项支持度,是置信度与后项支持度的绝对差,数学表示为

例如,后项支持度是80%,即80%的猪出栏体重达到一级标准,如果置信度是82%,即通过学习知道仔猪断奶日龄在20~25 d的个体猪,出栏体重达到一级标准的概率是82%,那么置信差为2%,应该说此关联规则提供的信息量并不高。置信差应高于某个最小值,所得到的关联规则才有意义。
3)置信率(confidence ratio)。置信率的数学定义为

其中括号中的第1项为信誉度,第2项为信誉度的倒数。由于信誉度越大越好,所以R也是越大越好。
4)正态卡方(normalized chi-square)。正态卡方从分析前项与后项的统计相关性角度评价规则的有效性,其数学定义为

不难得出:当项目X和项目Y独立时,SXSY=SX→Y,N为0;当项目X和项目Y完全相关时,N为1。因此N越接近于1说明前项和后项的关联性越强。
5)信息差(information difference)。信息差是在交互熵的基础上计算出来的。交互熵(cross entropy)也称为相对熵,是Shannon的信息论中非常重要的理论,主要用于度量2个概率分布间的差异性。
设 P=(p1,p2,…,pn)和 Q=(q1,q2,…,qn)是2个离散型随机变量的概率分布向量,则H(P|Q)称为P对Q的交互熵,其数学定义为

其中:第1项可替换为X条件下Y的分布;第2项可替换为X独立于Y情况的期望分布。
仍以猪场猪仔断奶日龄和出栏体重为例来说明信息差的含义,具体数据见表1。
表1中:每个单元格的第1个数据为X和Y独立条件下的期望概率分布,第2个数据为实际概率分布;r为关联规则的置信度;a为前项支持度;c为后项支持度。现计算这2个概率分布的差异。信息差定义的数学公式为
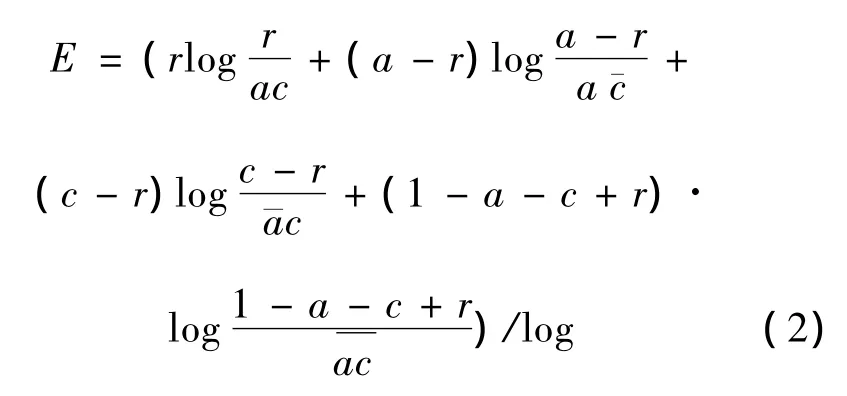
可见,信息差越大说明实际前后项的关联性越强。同样,信息差应高于某个最小值,所得到的关联规则才有意义。下面,就以个体猪养殖问题出发,通过上述各指标的分析,得出有实际应用价值的关联规则,以提高养殖效益。

表1 断奶日龄和出栏体重达标的列联表
2 实例
2.1 数据源
本研究所用数据来自猪场自动喂食系统所采集到的数据(如图1)。由于数据较多,图1中只列出部分数据,包括:个体猪生理数据,如个体猪类型、成熟体体重、当前体重、饲喂次数、生理阶段等;个体猪饲养效果分析;生理营养指标分析诊断结果,如采食量;饲料类型与料肉比分析结果;瘦肉生长率等。

图1 猪场自动喂食系统测定性能报告
2.2 数据处理
1)数据预处理。如果仅分析个体猪瘦肉率或高或低的关联关系,可删去个体猪个体信息数据库中的一些数据,如个体猪编号、耳号、总采食次数、总采食时间等噪声数据,结果如表2所示。
2)数据离散化处理。表2中的数据包括分类属性数据和连续属性数据,其中:分类属性数据有品种类型、生理阶段、能量摄入水平;连续属性数据有当前体重、日增重量、日采食量、瘦肉增长率。在挖掘数据的关联规则之前,首先将分类属性和连续属性的数据转换成“项”,即对每个数据进行识别编号。如对某列分类属性的一个数据,如果其同列前面有相同的数据,则取该数据的编号;如与其同列前面的数据都不同,则取同列中与其最邻近数据的编号加1为其编号。对连续属性数据的变换可以使用基于离散化的方法,由用户填入对连续属性数据进行分类的跨度,系统将每个连续数据按分类的跨度转换成一个整数,对其进行编号的方法同分类属性数据。按照以上对分类属性数据和连续属性数据的处理方法将数据编号为i,即将每个数据转换成一个数据项Ii,并存入数据库中。

表2 个体猪个体信息数据的预处理
3)数据分析。①利用Apriori算法将表中的数据进行运算,取最小支持度为20%,扫描所有事物数据,找出频繁项集。② 由频繁k-项集的非空子集产生规则,若满足最小可信度,则称此规则为关联规则。对结果数据进行关联分析,输入置信度和支持度参数,设支持度参数为0.2,置信度参数为0.7。该组参数可以灵活变动,但取值过大,会丢掉有意义的关联规则,取值太小,则会将一些无意义的关联规则包含进来。设定一组参数,可得出该组数据中的关联规则。
3 结果分析
使用Apriori算法对经过预处理的猪场数据进行关联分析,得出以下关联规则。
由频繁3-项集产生的关联规则:
①{饲料类型:湿粉料}∧{采食方式:限量采食}⇒{瘦肉率:高},confidence=80%。说明该猪场采用限量饲喂以及湿粉料的个体猪的瘦肉率高的可信度为80%。
② {饲料类型:湿粉料}∧{瘦肉率:高}⇒{采食方式:限量采食},confidence=80%。说明该猪场采用湿粉料且瘦肉率高的个体猪是采用限量饲喂方式,可信度为80%。
③{品种类型:中猪}∧{当前体重:35~75 kg}⇒{饲养阶段:生长期},congfidence=85%。说明当前体重为35~75 kg的中猪,其饲养阶段为生长期的可信度为85%。
④ {品种类型:大猪}∧{当前体重:75~100 kg}⇒{饲养阶段:育肥期},congfidence=85%。说明当前体重为75~100 kg的大猪,其饲养阶段为育肥期的可信度为85%。
⑤ {日增重:600~785 g}∧{饲养阶段:生长期}⇒{品种类型:中猪},congfidence=82%。说明日增重在600~785 g并处于生长期的猪类型为中猪,其可信度为82%。
由频繁2-项集产生的关联规则:
① {当前体重:35~75 kg}⇒{品种类型:中猪},congfidence=83%。说明当前体重为35~75 kg的个体猪类型为中猪,其可信度为83%。
② {日增重:600~785 g}⇒{饲养阶段:生长期},confidence=85%。说明日增重为600~785 g的个体猪处于生长期的饲养阶段,其可信度为85%。
③{采食方式:自由采食}⇒{瘦肉率:低},confidence=70%。说明采食方式为自由采食的个体猪瘦肉率比较低,其可信度为70%。
④{采食方式:限量采食}⇒{瘦肉率:高},confidence=70%。说明采食方式为限量采食的个体猪瘦肉率比较高,其可信度为70%。
⑤ {饲料类型:湿粉料}⇒{瘦肉率:高},confidence=72%。说明饲料类型为湿粉料的个体猪瘦肉率高,其可信度为72%。
⑥ {瘦肉率:高}⇒{饲料类型:湿粉料},confidence=76%。说明瘦肉率高的个体猪采用的饲料类型为湿粉料,其可信度为76%。
通过Apriori算法得出上述关联规则,但是,并不是所有得出的规则都是有意义并且令人信服的,因此,运用基于数学模型的实用性测度指标对上述规则进行验证,找出其中对于猪场有效、并对养猪业有实际应用意义的规则。
例如:根据频繁2-项集得出的关联规则①,利用实用性测度指标中的信誉度来研究其前项的出现对后项的出现是否有促进作用。计算发现,该猪场有80%的个体猪类型为中猪,即后项支持度为80%,根据其数学定义,计算其信誉度为:70%/80% <1。由信誉度的概念可知,一般计算结果大于1才有意义。此时,该结果意味着虽然此规则是有效的,但是并没有意义。
同理,依次对推导出的每一个关联规则进行数学模型的判定,得出以下结论:
频繁3-项集:
①{饲料类型:湿粉料}∧{采食方式:限量采食}⇒{瘦肉率:高},confidence=80%。
② {饲料类型:湿粉料}∧{瘦肉率:高}⇒{采食方式:限量采食},confidence=80%。
频繁2-项集:
①{采食方式:自由采食}⇒{瘦肉率:低},confidence=70%。
②{采食方式:限量采食}⇒{瘦肉率:高},confidence=70%。
③ {饲料类型:湿粉料}⇒{瘦肉率:高},confidence=72%。
④ {瘦肉率:高}⇒{饲料类型:湿粉料},confidence=76%。
4 讨论
猪的采食和饲喂方式对猪的生产性能有着明显影响,选用合适的饲喂料类型和饲喂方式将明显增加个体猪瘦肉增长率,提高养猪业的经济效益。
该猪场饲喂湿粉料的限量采食的个体猪瘦肉率较高的可信度为80%;瘦肉率高的饲喂湿粉料的个体猪,采食方式为限量采食,其可信度也为80%。该分析结果提示,饲喂湿粉料的个体猪,其瘦肉率较高的可能性较大,表明该猪群由于采食方式的不同,导致个体猪可能由于自由采食过多,降低其生产性能,故应注意调整饲喂方式或改饲喂湿粉料。
使用关联规则挖掘算法对猪场记录数据进行相关性分析是一种有效应用。挖掘所得的规则模式通过数学模型进行有效性和实用性的测定,对猪场养殖业具有指导意思。本文只对一个简单的个体猪采食数据库进行实验性测试,但该方法同样适合于其他猪场的相关数据分析。
[1]韩家炜.数据挖掘:概念与技术[M].北京:机械工业出版社,2001:132-161.
[2]Jie Dong,Min Han.BitTableFI:An efficient mining frequent itemsets algorithm[J].Knowledge-Based Systems,2007,20:329 -335.
[3]薛薇,陈欢歌.Clementine数据挖掘方法及应用[M].北京:电子工业出版社,2010:242-251.
[4]廖芹,郝志峰.数据挖掘与数学建模[M].北京:国防工业出版社,2010:188-221.
[5]张云洋,袁源.关联规则挖掘研究[J].计算机时代,2009(7):6-8.
[6]文拯,梁建武,陈英.关联规则算法的研究[J].计算机技术与发展,2009,19(5):57 -58.
[7]蒋雨,刘宗慧.饲料加工方式对猪饲料营养价值和生产性能的影响[J].饲料与营养,2010(5):7-9.
[8]李云峰,陈建文,程代杰.关联规则挖掘的研究及对Apriori算法的改进[J].计算机工程与科学,2002,24(6):65-68.
猜你喜欢
中国塑料(2023年1期)2023-02-07
浙江畜牧兽医(2022年5期)2022-12-31
现代畜牧科技(2021年11期)2021-12-21
现代畜牧科技(2021年5期)2021-07-20
现代畜牧科技(2021年2期)2021-03-19
四川建筑(2019年6期)2019-07-20
物联网技术(2018年2期)2018-03-03
佛山陶瓷(2017年7期)2017-09-06
大观(2016年12期)2017-04-15
淮海医药(2015年2期)2016-01-12
