
基于层叠模型的话题检测方法研究
2012-05-15 09:05:16谢林燕张素香戚银城
郑州大学学报(理学版) 2012年2期
谢林燕, 张素香, 戚银城
(1.华北电力大学 电子与通信工程系 河北 保定 071003; 2.国网信息通信有限公司 北京 100053)
0 引言
随着互联网的迅猛发展,人类已经进入了信息爆炸和信息过载的时代,海量的网络媒体信息使得人们在获取信息时产生了一种咨询焦虑,因此,建立以话题为主线的信息组织模式,快速有效地检测出用户感兴趣的信息成为新的研究热点.话题检测与跟踪[1](topic detection and tracking, TDT)技术就是在这种背景下产生并发展起来的.话题检测是TDT测评任务中的一项任务,它是将新闻数据流中的报道归入不同的话题,并在必要的时候建立新话题的技术.
目前,已有很多学者针对话题检测展开研究,文献[2]通过分析大量英文报道的特征,提出基于内容分析的话题检测算法,通过内容分析将话题表示成标识中心向量和内容中心向量.文献[3]提出利用计算时间相似度和地点相似度进行话题检测,但是没有将两者结合起来.文献[4]提出了一种时间相似度和地点相似度计算方法,并结合两者进行话题检测.目前,多数话题检测算法是以语法信息为基础计算话题和报道的相似度,最终完成话题检测任务.然而,影响话题检测系统性能的一个重要因素是相似话题[1]的区分,如两次不同的海啸事故,因为描述这些事件的报道所使用的词汇大部分是相同的.针对这一问题作者提出了基于层叠模型的话题检测方法,首先识别话题和报道中的实体信息,同时改进时间相似度和地点相似度的计算方法,在底层通过计算文本内容相似度进行话题检测,在高层结合时间相似度和地点相似度,融合三类相似度的计算结果作为最后的判别标准,以此来克服相似话题难以区分的问题.实验结果表明,该方法很好地提高了检测精度.
1 构建话题检测系统
提出的话题检测系统如图1所示,主要包括建立新闻报道模型与话题模型、基于层叠模型的话题检测方法和话题检测算法3部分.
1.1 建立新闻报道模型与话题模型
1.1.1预处理与报道模型 文本预处理包括分词和去停用词两部分.分词是自然语言处理研究的出发点,本系统首先对输入的文本进行分词,然后为了降低后续处理流程的复杂度,提高检测精度,要去除停用词.

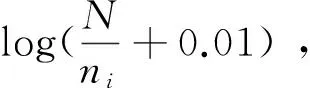
(1)
(2)
其中,tfi是termi在报道S中的词频,N是所有已输入报道的总数,ni是N篇报道中含有termi的报道的数量.

图1 话题检测系统框图Fig.1 Topic detection system chart
1.1.2话题模型 话题模型通常以质心表示,而质心也是通过向量空间模型描述的,因此,通过提取特征和计算特征权值将特定话题表示为质心.从已收集的话题语料中随机抽取若干篇作为训练语料形成相应话题,采用基于文档频率的方法选取文本特征.文档频率主要是统计所有不同词在话题中的文档的频次,并将这些词按照其频次的高低顺序排列,在该排列中抽取特定数目的词作为话题特征项.话题特征项的权重计算方法如下:
(3)
其中,weight(term,T)表示特征项term在话题T中的权重;Si是话题T中包含的新闻报道;N为话题T包含新闻报道的总数量;ω(term,Si)是特征项term在Si中的权重值.
1.2 基于层叠模型的话题检测方法
一个事件涉及到的时间、地点信息在解决相似话题难以区分的问题中起着不可忽视的作用.作者提出了基于层叠模型的话题检测方法,多层次、多角度地分析话题和报道中的相似性,将基于baseline模型[2]的计算结果作为底层检测,在高层结合时间、地点信息的相似度,三类相似度融合的结果用于完成话题检测任务.
1.2.1话题和报道的内容相似度计算 采用夹角余弦函数作为内容相似度的计算方法.假设报道S与话题T的向量空间模型分别为S=(ws1,ws2,…,wsn)和T=(wt1,wt2,…,wtn),那么报道S与话题T的相似度计算公式为
(4)
1.2.2话题和报道的地点相似度计算 对文献[4]提出的地点相似度的计算方法进行了改进,首先建立与话题相关的地点词典,将话题中涉及的重要地点信息收集到该词典中,形成话题地点向量,然后提取报道的地点信息形成报道地点向量,进行地点相似度计算,计算公式为
(5)
其中,mi为该话题的地点向量,mj为新闻报道Si的地点向量.
1.2.3话题和报道的时间相似度计算 时间信息在自然语言处理相关领域中起着重要的作用[6].在话题检测中,可以利用时间信息判断报道是否与某话题的后续报道相关,当报道时间与话题事件发生的时间差距增大时,认为两者之间的相关性减弱,因此将这一特点融入了话题检测中.作者改进了文献[4]中提出的时间相似度计算方法,利用新闻报道的发布时间与话题事件的发生时间差来表示话题和后续报道之间的相关性.算法改进后,缓解了相似话题难以区分的问题.为完成该任务,必须将报道和话题中的时间信息规范化,精确到天,时间信息的格式为:2010-11-23,计算公式为
sim(ti,tj)=-|ti-tj|,
(6)
其中,ti为新闻报道Si发布的时间,tj为话题事件T发生的时间.
1.2.4基于层叠模型的话题与报道相似度计算 将基于文本内容、时间、地点计算出的相似度加以融合,通过线性组合的方式得到最终的相似度,计算公式为
sim(Si,T)=cos(Si,T)+αsim(mi,mj)-βsim(ti,tj),
(7)
其中,α与β为设定的参数.本实验中,α=0.4,β=0.000 1.
1.3 话题检测算法
以Single-Pass聚类策略为基础实现话题检测算法,该算法按新闻报道输入的先后顺序依次处理信息流中的报道,直到所有的报道处理完毕,具体过程如下:
1)对新闻报道进行预处理,然后利用1.1.1节和1.1.2节中的特征权重计算方法计算报道和话题中各个词的权重值,分别建立报道模型和话题模型.
2)计算新闻报道与话题的相似度,与预设的阈值进行比较,报道与话题的相似度高于阈值,则判定该报道与话题相关,否则判定该报道与话题不相关.
3)重复上述过程直到信息流中的所有报道都处理完毕.
2 实验结果与分析
2.1 评价指标
实验采用的性能指标为正确率(P)、召回率(R)和F1测试值,计算公式如下:

2.2 实验设计与结果分析
采用从互联网收集到的新闻报道作为评测语料,该语料包含725篇中文报道,定义了包括韩朝开战、韩国前总统金大中去世、法国总统萨科齐访华、云南盈江地震、索马里海盗、韩国罗老号火箭坠毁等10个话题.随机选取4篇与韩朝开战相关的新闻报道作为训练语料,构建话题模型,剩余721篇新闻报道作为测试语料,其中选取韩朝开战事件作为本次实验的相关话题,其余话题作为与该话题不相关的反例话题,共计220篇报道.
设计了如下3个实验:
实验一 采用基于传统TF-IDF权重计算的baseline模型完成话题检测任务;
实验二 采用基于归一化TF-IDF权重计算的baseline模型完成话题检测任务;
实验三 采用基于层叠模型完成话题检测任务.
实验对比结果见表1.

表1 实验结果Tab.1 Experimental results
由上述实验结果可以得出以下结论:
1)通过设定不同的相似度阈值发现,随着该值的增大,正确率提高,召回率下降.
2)通过比较实验一和实验二的实验结果,实验二中构建的系统模型的召回率在同等实验条件下均高于实验一,同时F1测试值与实验一相比,也有所改进,这说明基于归一化TF-IDF权重计算的baseline系统模型的检测性能优于基于传统TF-IDF权重计算的baseline模型.
3)通过比较实验二和实验三的实验结果,基于归一化TF-IDF权重计算的baseline模型的话题检测方法的性能指标,在同等条件下低于结合新闻特征的检测结果,这说明将时间和地点信息应用到话题检测中是一种行之有效的方法.
对实验结果进行分析可知,未能正确检测识别新闻报道的原因主要有以下3种:
1)实验设定的反例中,存在与目标话题类似的话题语料,如“韩国前总统金大中去世”和“韩国罗老号火箭坠毁”两个事件中,均涉及到韩国的一些地名(如“首尔”、“青瓦台”等),它们在两个不同的话题中均出现,造成结果误判.
2)实验中存在部分与目标话题相关的新闻报道,语料篇幅偏短,涉及到的特征不够明显,因此在相似度计算中,计算结果偏低,随着相似度阈值的提高,对这部分相关语料就会误判.
3)实验语料中涉及一些关键人名,如“韩朝开战”事件中出现的官员名称“崔泰福”、“金星焕”等,对于区分相似话题可以起到作用,作者未对关键人名进行考虑.
3 结论
提出了基于层叠模型的话题检测方法.该方法通过分析新闻报道语料的特点,充分考虑了报道中地点、时间等信息,并结合基于baseline模型的相似度计算结果,将三类相似度的计算结果进行线性组合,以此结果为依据,进行报道和话题的相似度检测,从而完成话题检测任务.实验结果表明,基于层叠模型的话题检测方法能够提高检测性能指标.
参考文献:
[1] 洪宇,张宇,刘挺,等.话题检测与跟踪的评测及研究综述[J].中文信息学报,2007,21(6):71-87.
[2] 赵华,赵铁军,张姝,等.基于内容分析的话题检测研究[J].哈尔滨工业大学学报,2006,38(10):1740-1743.
[3] Jin Y,Myaeng S H,Jung Y. Use of place information for improved event tracking[J].Information Processing and Management,2007,43(2):365-378.
[4] 薛晓飞,张永奎,任晓东.基于新闻要素的新事件检测方法研究[J].计算机应用,2008,28(11):2975-2977.
[5] 刘海峰,王元元,刘守生.一种组合型中文文本分类特征选择方法[J].广西师范大学学报:自然科学版, 2007, 25(4):208-211.
[6] Li Baoli, Li Wenjie, Lu Qin.Topic tracking with time granularity reasoning[J]. ACM Transactions on Asian Language Information Processing,2006,5(4):388-412.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
活力(2019年15期)2019-09-25 07:22:10
海外华文教育(2016年1期)2017-01-20 08:21:58
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
新闻传播(2015年21期)2015-07-18 11:14:22
新闻传播(2015年9期)2015-07-18 11:04:11
新闻传播(2015年13期)2015-07-18 11:00:41
