
基于SVM预测模型的汽车电子市场价值估计
2012-05-09 10:15添玉张琳娜
上海海事大学学报 2012年2期
添玉,张琳娜
(上海海事大学物流工程学院,上海 201306)
0 引言
随着统计学理论的发展和计算机的出现,商业预测在企业战略决策中的作用越来越明显.本文通过对德国大陆汽车信息收集和业务开拓(Business Development and Marketing,BD&M)的预测业务进行分析后,发现其对中国汽车市场的短期预测不够准确.究其原因,该部门采用的汽车产量数据来自GI(Global Insight)数据库,结果适用于长期预测,在短期预测方面具有滞后性,缺乏一定的适应性.
支持向量机(Support Vector Machine,SVM)是基于统计学习理论发展起来的新兴的机器学习方法.基于结构风险最小化原则,SVM将最大化分类间隔的思想与基于核的方法结合在一起,表现出很好的泛化能力.SVM具有坚实的数学基础,并且可以很好地克服“维数灾难”和“过拟合”等传统算法所不可规避的问题,已被广泛应用在数据挖掘[1]、需求预测[2]等领域.鉴于SVM的原理和特征特别适合小样本,本文提出一种中国汽车月产量的优化核函数参数的改进SVM预测模型,并应用在德国大陆汽车公司轻型汽车电子市场价值估计中.
1 统计学习理论与SVM
1.1 统计学习理论
统计学习理论就是研究小样本统计估计和预测的理论,主要包括4个方面[3]:(1)经验风险最小化准则下统计学习一致性的条件;(2)在这些条件下关于统计学习方法推广性的界的结论;(3)在这些界的基础上建立的小样本归纳推理准则;(4)实现新准则的实际算法.其中,最有指导性的理论结果是推广性的界,与此相关的一个核心概念是VC维.VC维是为了研究学习过程一致收敛的速度和推广性而定义的有关函数集学习性能的指标.VC维反映函数集的学习能力,VC维越大则学习机器越复杂.统计学习理论系统地研究各种类型的函数集、经验风险与实际风险之间的关系,即推广性的界.关于两类分类问题,结论是:对指示函数集中的所有函数(包括使经验风险最小的函数),经验风险Remp(ω)和实际风险R(w)之间以至少1-η的概率满足
式中:h是函数集的VC维,l是训练样本数.这一结论从理论上说明学习机器的实际风险由经验风险和置信范围两部分组成,其中置信范围与学习机器的VC维及训练样本数有关.因此,在有限训练样本下,学习机器的VC维越高则置信范围越大,从而真实风险与经验风险之间可能的差别就越大.这就是出现过学习现象的原因.机器学习过程不但要使经验风险最小,还要控制学习机器的VC维以缩小置信范围,才能把实际风险控制在一个较低的水平,使学习模型对未知样本具有较好的推广性.
1.2 SVM回归
假定训练样本集为{(xi,yi),i=1,2,…,l},其中输入值xi∈Rn,yi∈R为对应的目标值,l为样本数.定义ε不敏感损失函数为
学习的目的是构造f(x),使其与目标值之间的距离小于ε,同时函数的VC维最小.这样对于未知样本x,可最优地估计出对应的目标值.因此,回归的最优化问题[3]为
式中:C为惩罚因子,C越大表示对超出ε的惩罚越大.根据最优化的充要条件可知,拉格朗日乘子与约束的乘积在最优点为零,由此最优化计算得到的αi和,取值必然是以下5种情形之一:(1)αi=0,=0;(2)0 < αi<C=0;(3)αi=0,0 <<C;(4)αi=C=0;(5)αi=0,=C.以上5种情形中,称(2)~(5)对应的xi为支持向量.非支持向量对ω没有贡献,只有支持向量对ω有贡献,即对估计函数f(x)有贡献,由此称对应的学习方法为SVM.在支持向量中,称(4)和(5)对应的xi为边界支持向量,是超出ε之外的数据点,称(2)和(3)对应的xi为标准支持向量,是落在ε上的数据点.因此,ε越大,支持向量数越少,但函数估计精度越低.
2 改进SVM预测模型
本文采用的数据从国务院发展研究中心信息网和国家统计局网站收集整理而得.中国汽车月产量包括乘用车和商用车两部分,国内生产和CKD(全散装件)都包括在内.具体数据见图1.
世界银行的报告显示,汽车产量与GDP密切相关.根据“GDP=总消费+总投资+净出口”这个公式,本文初步选定固定资产投资完成额、社会消费品零售总额、进出口总值和净出口额等4个因素作为自变量,所选数据为2005—2010年的月数据.

图1 2005—2010年中国汽车产量
2.1 数据处理
在对中国汽车月产量进行预测的4个自变量中,社会固定资产投资完成额与社会消费品零售总额有较大的相关性,去除前者,对剩下的数据进行回归预测.因数据结构的特殊,首先使用Excel中的Format Data To Libsvm宏将数据转换成可识别的形式,将预处理的文件保存为data.txt,然后使用线性函数转换对数据进行归一化处理,将归一化的数据分为训练数据train.txt和预测数据forcast.txt.
2.2 回归方法和核函数的选择
将SVM应用于回归方面,主要有VAPNIK提出的 ε-SVR 和 SCHOLKOPF 等提出的 v-SVR.ε-SVR通过事先确定ε来控制算法希望达到的精度,具有良好的可控性,相对于v-SVR而言模型也较简单,在有较好的参数选择方法时适宜选择ε-SVR方法.根据本文的数据及计算的实际要求,选择ε-SVR回归方法较好.由于RBF核函数具有一定的代表性,这里选用RBF核函数作为SVM的核函数.
2.3 核参数最优化方法
训练SVM时首先需要考虑两种参数:核参数γ和惩罚参数C.参数的选择并没有通用的先验知识,需要在一定范围内进行搜索以找到好的参数组合.目前,选取SVM参数最常用的方法是网格搜索法结合交叉验证法[4].
SVM机器学习方法就是根据分类规则
对下列优化问题
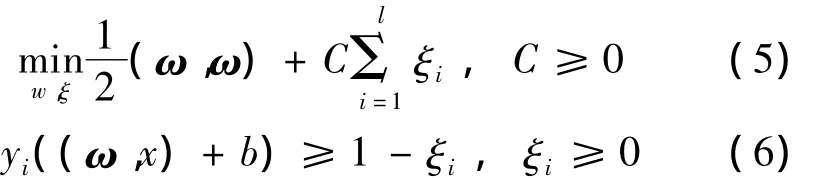
应用Lagrange乘子法得到的Wolfe对偶优化问题的最优解
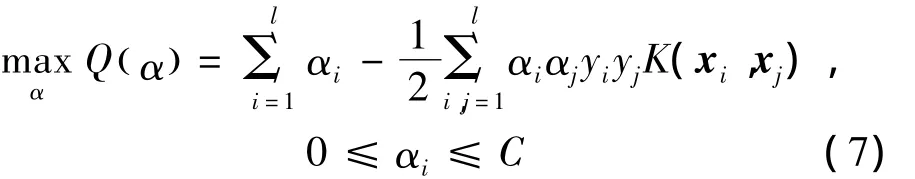
训练一个SVM,求解
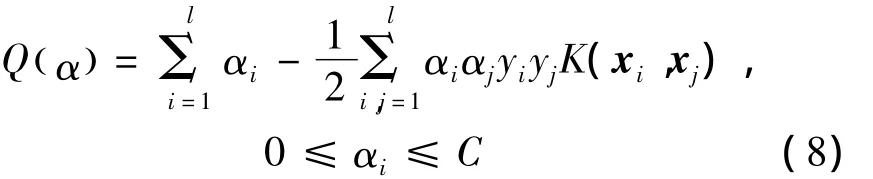
的最大化解α和b.通过最小化推广能力的估计值(通常采用测试错误率表示推广能力的估计),得到常数C和核函数固有参数.
参数选择可以归结为最小最大化问题:最大化式(7)并在解的基础上最小化推广能力的估计值,由此可以得到选择SVM参数的最优化方法.[5]
最优化方法选择参数的步骤:(1)为常数C和核函数固有参数赋初值;(2)最大化式Q(α),得到α和b;(3)更新常数C和核函数,最小化推广能力的估计值;(4)如果估计值满足要求结束运算,否则重复步骤(2).其中,步骤(3)中的推广能力是指学习机测试未知数据的分类性能,主要有留一法(利用错分类率评估分类性能)和支持向量计算法(利用支持向量数与训练样本总数之比评估分类性能).
从式(5)可知,惩罚因子C控制的是训练错误率与模型复杂度间的折中;从式(6)可知,惩罚因子C并没有出现在式(5)的Wolfe对偶式中,而是改变Lagrange系数的取值范围.因此,对于一个SVM,如果无限增大惩罚因子C,当SVM中没有边界支持向量时,C的改变不再影响分类性能.[6]

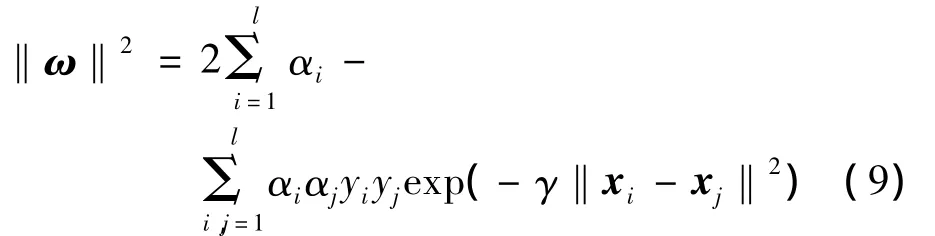
从式 K(xi,xj)=exp(-γ‖xi- xj‖2)可以看出,核参数γ相当于对样本间欧氏距离的归一化,判定特定空间中向量间的距离.另一方面,根据KKT互补条件的一个重要结果:对于j∈SV,
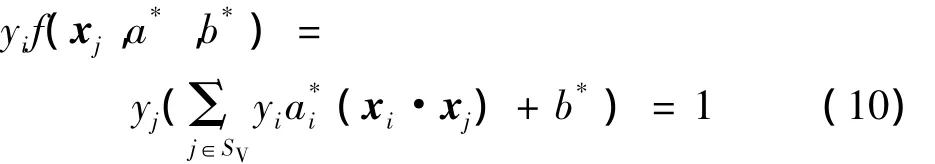
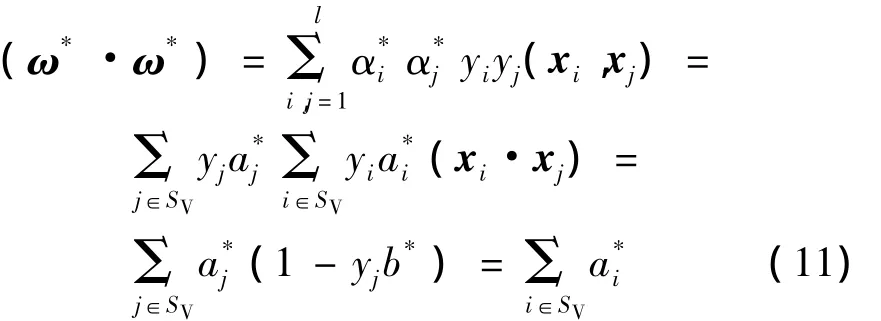
综上,选用支持向量与样本数的比例估计推广能力时,根据式(9)调整γ是合理的.并且该式对γ求导有
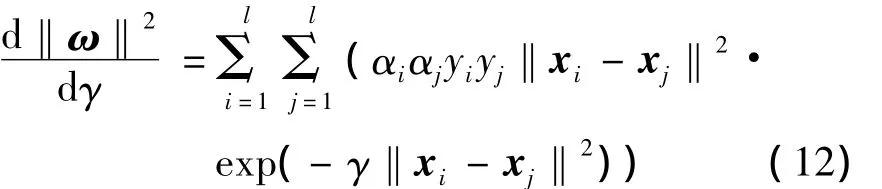
由此可得γ的调整规则为
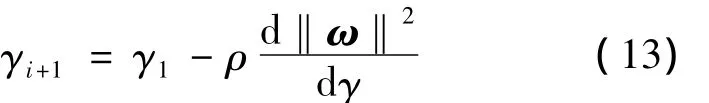

2.4 训练集训练
将第2.3节生成的3个参数用于训练SVM模型.在得到训练模型后,用预测样本预测汽车月产量.汽车月产量预测结果分别为1 524 150,135 204,173 435,预测值与实际值的拟合曲线见图2.
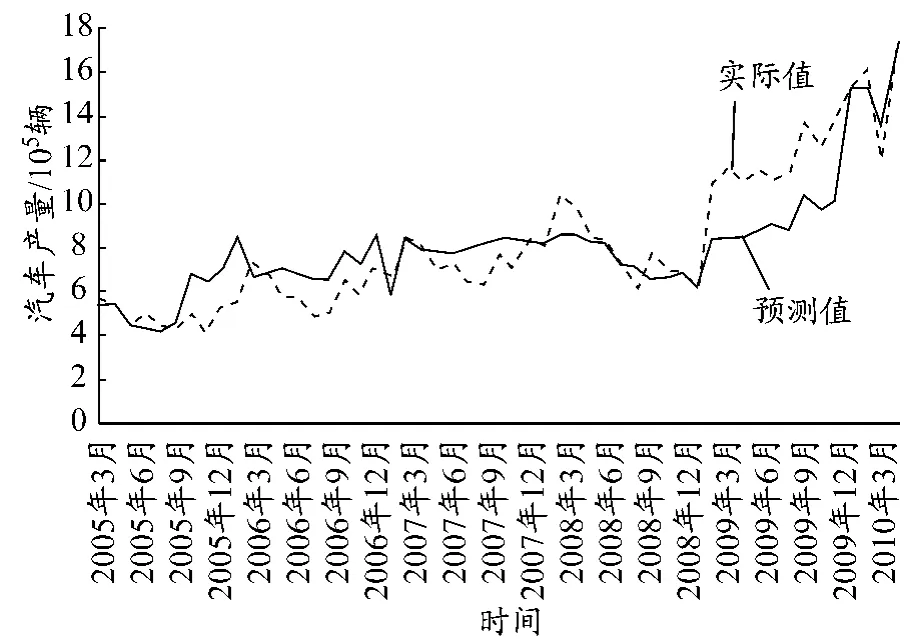
图2 改进SVM预测结果与实际值拟合曲线
3 预测模型的应用
根据上述预测模型估计2010年3个月的中国轻型汽车电子市场容量,见图3.
首先通过与制造商和经销商沟通,结合网上查到的资料选出各车型的模型车及其所用的汽车电子产品,然后根据产品经理以及各事业部的报告获得各类电子产品的装车率,接着通过中国汽车产量预测模型计算出当月的汽车月产量;然后分别乘以各车型的比例,再乘上前两步的数据,得出总共需要的电子产品总量;最后通过战略分析、与各个事业部交流后得出每个电子产品的价格,乘以各自的总量后得到各车型的电子市场价值,最后求和得到中国轻型汽车电子市场的总价值.[7-9]
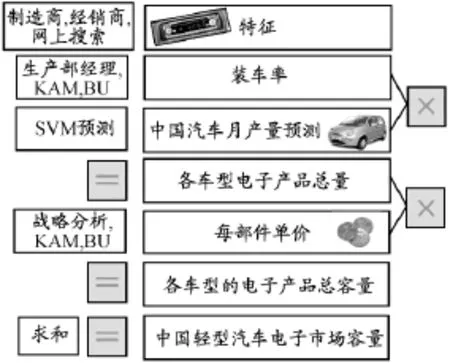
图3 中国轻型汽车电子市场容量计算
中国的轻型汽车主要包括乘用车和轻型商用车.乘用车根据汽车的轴距、排量、重量等参数可分为A,B,C和D型车,其中由于D型车属豪华型轿车,产量较少,这里不列入计算范围.首先,在确定好列入计算的车型后,对每种车型进行模型车的选择,A,B和C型车选取两种模型车,国内品牌和国外品牌的各一种,假设模型车的电子产品安装率和价格是其代表车型的平均水平,模型车的选择见图4.然后经过调查建立各模型车的电子产品类别和装车率表,同时根据市场分析和收集的数据得出各电子产品的价格,见表1.

图4 模型车的选择
再根据对2010年3个月汽车产量的预测,结合每类车型所占比例,参照每个电子产品的市场价格,计算出每个电子产品的容量,数据见表2.
最终估计结果见图5,其中每月编号1的数据为使用SVM预测的汽车月产量而得出的值,编号2的数据为使用GI数据库的汽车年产量除以12以后得到的值.对比结果可发现使用旧方法预测的值比新方法小,因为它的预测周期长(最新数据为2009年9月预测),没有充分考虑到中国汽车市场的迅速发展趋势,而且缺乏波动性.由此可见,在进行短期市场价值估计时,使用SVM回归方法获得汽车月产量数据的预测结果较好.
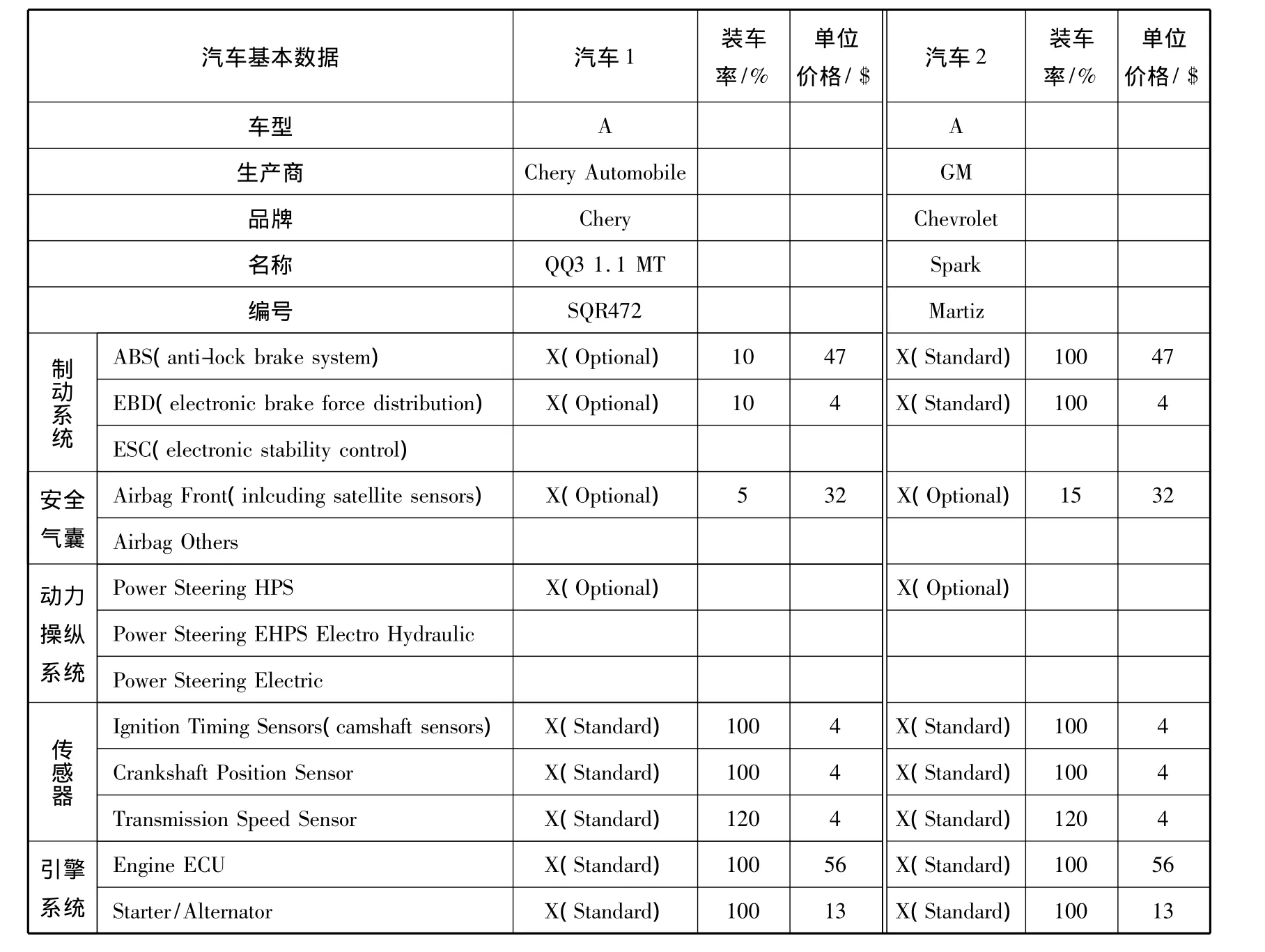
表1 各车型电子产品装车率及单位价格(部分)
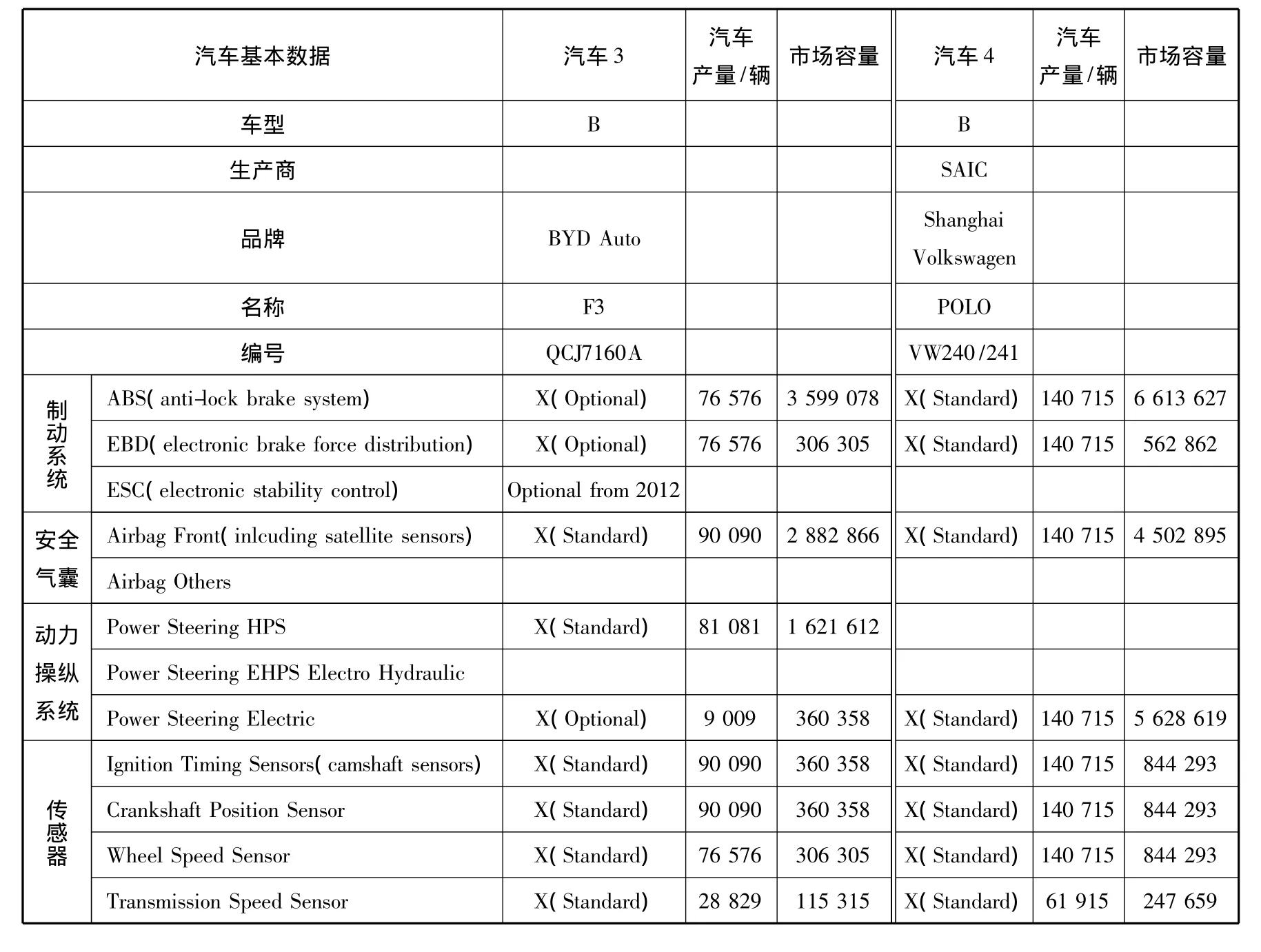
表2 单个电子产品市场价值(部分)

图5 电子市场价值估计结果比较
4 结束语
以中国汽车月产量的预测作为研究对象,针对德国大陆汽车BD&M部门的业务流程中预测方法存在的缺陷,提出一种改进的SVM预测方法,对中国汽车月产量进行短期预测并应用于汽车电子市场的潜在价值估计,取得满意效果.然而,商业预测是一项复杂的系统工程,除了在预测方法上进行改进外,信息系统的构建、关键数据的定时收集也必不可少,除此之外还必须在组织机构上进行优化,使得各部门之间一些关键信息得到共享,减少不必要的沟通和协调工作.
[1]毛建洋.支持向量机在数据挖掘中的应用研究[D].上海:华东理工大学,2006.
[2]王颖,邵春福.基于支持向量机的公路货运量预测方法研究[J].物流技术与方法,2010(21):142-150.
[3]CRISTIANINI N.支持向量机导论[M].北京:机械工业出版社,2005.
[4]段凤娟,朱吉胜,王华建.支持向量机快速算法的实现技术[J].现代计算机:专业版,2008(09):57-58.
[5]邓乃扬,田英杰.数据挖掘中的新方法:支持向量机[M].北京:科学出版社,2004.
[6]王睿.关于支持向量机参数选择方法分析[J].重庆师范大学学报:自然科学版,2007,24(2):1-4.
[7]程远.我国分地区乘用车市场分析及预测[D].上海:上海交通大学,2007.
[8]赵海龙.中国汽车保有量预测建模及其应用研究[D].长沙:湖南大学,2009.
[9]邓丽娜.中国汽车工业与国民经济发展的相关分析及需求预测[D].成都:西南交通大学,2005.
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
新高考·高一数学(2022年3期)2022-04-28
红蜻蜓·低年级(2021年11期)2022-01-19
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
甘肃教育(2020年8期)2020-06-11
中华家教(2018年8期)2018-09-25
中国资源综合利用(2017年3期)2018-01-22
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
