
基于闪存的混合存储系统缓冲区管理算法
2012-05-04 08:10:10王光忠王翰虎
计算机工程与设计 2012年6期
王光忠,王翰虎,2,陈 梅,马 丹
(1.贵州大学 计算机科学与信息学院,贵州 贵阳550025;2.贵州星辰科技开发有限公司,贵州贵阳550025)
0 引 言
基于闪存和传统磁盘的混合存储系统已经成为DBMS存储层的高效存储模式。它充分利用闪存和磁盘各自的特点,即闪存高速的随机读和磁盘快速的顺序写,有效提高了DBMS存储层的I/O效率[2,6]。针对混合存储的研究,国内外研究主要集中在混合存储系统的页迁移算法和缓存区管理算法两方面[1-8]。对于混合存储的缓冲区管理,文献[3]提出了一种动态的T/C LRU缓冲区管理算法。该算法根据闪存和磁盘数据页访问代价的不对称性,优先置换代价低的数据页,从而提高I/O的存取效率。但算法仅从简单的页代价比较进行置换,却忽视低代价数据页频繁置换产生的I/O代价。文献 [4]提出以闪存作为NVC(nonvolatile cache)金字塔式的多级缓冲区管理,通过闪存提高I/O的存取效率。但由于对I/O存取过多的集中在闪存上,缩短了闪存的使用寿命,无法均衡闪存和磁盘的I/O流量。
本文提出了一种自适应缓冲区管理算法DLSB(divded layer self-adaptive buffer management policy)。它根据数据页读写操作的逻辑代价和物理代价对数据页进行自适应的域间选择和域内置换,较好的适应了数据页序列存取模式变化,有效的提高混合存储系统的I/O存取效率。
1 闪存缓冲区置换算法
闪存主要有NOR和NAND两种。NOR型闪存以字节作为存取单位,容量小、价格高,适宜存储程序。NAND闪存以页作为存取单位,具有更大的容量和更高的写入速度,因此更适合用于大容量存储[9,15]。目前的混合存储系统多针对NAND闪存。
基于NAND类型的闪存由若干闪存块组成,每块由固定的闪存页组成。以页为单位进行读写操作。读写速度不对称,读的速度比写的速度快。写入闪存的数据页不支持原位更新,数据页的删除操作将导致所在块的删除,块的删除次数有限。和磁盘相比,具有许多不同于磁盘的特性,即读写代价不对称、不支持及时更新、以块为单位擦除(block-erasing)、块擦除次数有限。
以闪存作为DBMS的存储系统中,针对闪存的特点,提出了许多高效的缓冲区管理算法。比较经典的有ACR[10]、BPLRU[11]、CFLRU[12]、CFDC[13]、LRU-WSR[14]等 算 法,其中ACR算法针对闪存读写代价的不对称性,从逻辑和物理两个层面进行代价的评估,最终确定缓冲区的置换页,较好的适应不同数据页读写序列的存取模式。
在闪存和磁盘的混合存储系统中,文献 [2]提出一种动态的缓冲区管理算法T/C LRU。该算法把缓冲区从逻辑上划分为时间区和代价区,时间区里有一个LRU缓冲队列,最近访问的数据页或者频繁访问的数据页,根据时间戳在时间区的LRU中排列;代价区里有4个LRU缓冲队列,并按照数据页置换代价升序排列。时间区和代价区的大小根据磁盘的命中率和闪存的缺页率代价之比进行划分,即根据磁盘命中页的代价大于闪存缺页产生的代价进行动态调整。代价区中数据页置换按照Lcf<Lcd<Ldd<Ldf顺序,对代价区中的数据页进行置换。
当数据页命中,如果在时间区LRU中,把数据页插入到MRU位置,重新加上时间戳。如果在代价区中,从相应的LRU中取出数据页重新插入到时间区MRU位置,并重新加上时间戳,把时间区LRU的数据页置换插入到代价区相应的LRU队列中。
当数据页未命中,置换时间区中的数据页到代价区中相应的LRU中,把数据页插入到时间区的MUR位置。而代价区中数据页的置换,按照 Cfread<Cmread<Cmwrite<Cfwirte的顺序进行数据页的置换。
T/C LRU根据闪存的缺页率和磁盘的命中率比较,动态调整时间区和代价区的大小,降低了I/O访问开销。但忽视了闪存和磁盘干净数据页的频繁置换产生的I/O代价。并且随着存取模式的变化,需要重新调整时间区和代价区的大小,从而严重制约了算法的自适应性。
针对T/C LRU算法的缺点,本文提出了一种分层自适应 的 缓 冲 区 算 法 DLSB(divded layer self-adaptive buffer management policy)。
为了便于描述,对本文所涉及的若干符号给出了定义,见表1。

表1 本文所用符号及其意义说明
2 自适应存储方法
2.1 算法概述
我们提出的自适应缓冲区算法DLSB,根据缓冲区中数据页逻辑和物理操作代价,自适应地选择代价最小的数据域和数据页进行置换。算法把缓冲区逻辑划分为干净页域Lc和脏页域Ld。每个数据域中的数据页根据存储介质类型分为闪存队列和磁盘队列。假定缓冲区可以存放S个数据页,则Lc=|Lcf+Lcd|=B表示干净页域的数据页,Ld=|Ldf+Ldd|=S-B表示脏页域的数据页。当缓冲区未满或数据页命中时,计算域和域内队列的逻辑和物理操作代价,调整域中闪存队列和磁盘队列的理想数据页容量。当数据页不在缓冲区时,自适应地调整干净页域和脏页域的代价比,选择代价最优的置换域。在选择的置换域中,根据可容纳的理想数据页容量与队列中实际数据页容量进行比较。当闪存队列实际值大于理想的闪存队列值时,选择闪存队列中的数据页作为置换页。反之选择磁盘队列的数据页进行置换。
2.2 自适应的域间选择策略
干净页域的代价和脏页域的代价分别为式(1)、(2)
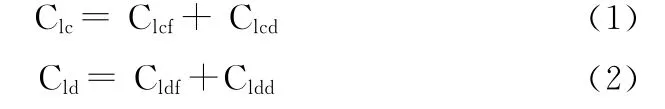
式中:Lcf的代价记——Clcf,代价计算如式(3)
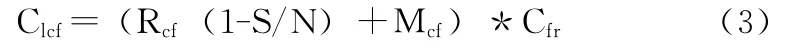
式中:S/N——一个有N页大小的文件,对该文件中某个数据页的逻辑操作在缓冲区中命中的概率。1-S/N——一个逻辑操作被转换为物理操作的概率。同理Lcd、Ldf、Ldd的代价——Clcd、Cldf、Cldd,其代价计算分别为
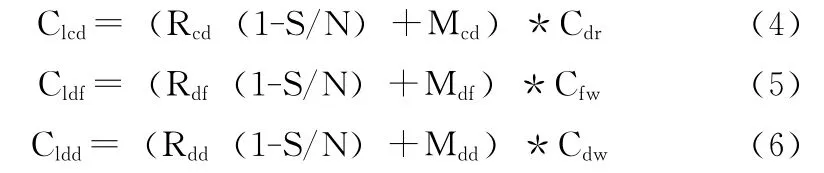
如果缓冲区满且当前请求的数据页P不在缓冲区中,根据Lc域和Ld域的大小和其过去一段时间内数据页置换所付出的代价比例(式(7))进行选择。若|Lc|=B<βS,则Ld过大,选择Ld作为置换域;反之Lc作为置换域
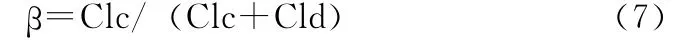
通过对数据页逻辑和物理操作代价的计算,使得对干净页域和脏页域的自适应选择能很好的适应数据页读写序列的模式变化。
2.3 自适应的域内数据页置换策略
对于数据域中闪存数据页和磁盘数据页的置换,采用了一种自适应的队列代价优化算法。对干净页域中的两个LRU队列,即Lcf和Lcd,队列大小为|Lcf|+|Lcd|=B,0≤|Lcf|≤B,0≤|Lcd|≤B。用参数δ(0≤δ≤B)表示Lcf可以包含的干净闪存页的理想值。当数据页P在Lcf队列中命中,根据公式δ=min(δ+Cfr*(|Lcd|÷|Lcf|),B)增加δ值。Cfr*(|Lcd|÷|Lcf|)表示命中Lcf队列中的闪存队列后与磁盘队列的代价比。反之数据页在Lcd命中,δ=max(δ-Cdr*(|Lcf|÷|Lcd|),0)减少δ值。当实际的|Lcf|>δ,则从Lcf中置换页,相反则从Lcd中置换页。同理,脏页域中的页置换也采用相同的算法。
2.4 DLSB算法描述
如表2所示,1-12行描述了数据页在缓冲区中命中的情况。1-7行中,数据页P在干净页域中命中,操作类型是读,则根据数据页类型移动到相应队列的MRU位置,增加相应的逻辑操作次数,

表2 DLSB算法
并且调整干净页域中闪存和磁盘的LRU可容纳的理想数据页大小δ。8-12行描述脏页域命中,同干净页域一样调整相应逻辑操作次数和可容纳的理想数据页大小η。13-16行描述了数据页未命中的情况,如果缓冲区已满,调用过程EvitctPage置换相应数据页,并根据数据页来自闪存或者是磁盘调整逻辑操作次数和物理操作次数,将相应数据页插入到相应的LRU队列的MRU位置。

表3 EvitctPage过程
表3中EvitctPage过程描述了对缓冲区中数据页的置换过程。1-2行根据干净页域和脏页域逻辑代价和物理代价的计算,自适应调整参数β,最终确定置换域。根据域中的LRU队列的实际大小和理想参数δ、η比较,确定相应数据页的置换。
3-6行描述脏页域中的数据页的置换以及相应的物理操作次数,7-11行描述干净页域中数据页的置换。
3 实验与结果分析
3.1 实验环境
本实验使用的硬件配置为:Intel Core 2P4Duo CPU 2.83GHz,2GB内存,Intel X25-V 40G的SSD硬盘和2个Maxtor Diamond Max 6L300 300G的磁盘 。实验环境采用文献 [2]混合存储系统,对LRU、T/C LRU、DLSB算法进行比较。
3.2 实验结果分析
实验结果如图1,图2所示。图1中显示了缓冲区大小对3种算法在混合存储系统中I/O访问开销的影响(这3种算法均执行一个15万次的页请求序列来进行测试,读写请求数目之比为8:2,闪存和磁盘存储的读写数据页各占50%),其中图1(a)和图1(b)分别比较了3种算法的写操作次数和访问开销。如图1所示,传统的LRU算法对混合存储磁盘的写操作和访问开销很大。图1(a)中,T/C LRU算法写操作次数明显低于DLAB,同时图1(b)中的访问开销却高于DLSB,接近于LRU的访问开销。这是因为T/C LRU算法只注重于简单的数据页代价比较,没有考虑到数据页频繁访问的代价。
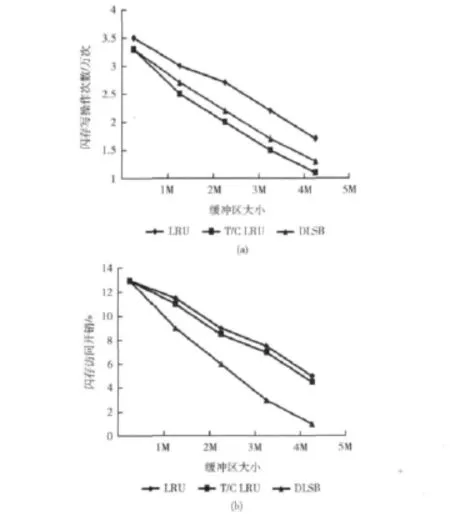
图1 缓冲区大小对I/O性能的影响
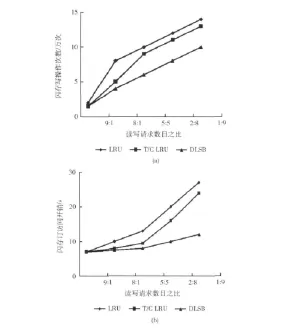
图2 存取模式对I/O性能的影响
图2显示了在不同的数据流中,不同的存取模式对3种算法在混合存储系统中I/O访问开销的影响(缓冲区为10M,页请问请求为15万次)。如图3所示,DLAB算法在数据页的写操作次数和访问开销方面显著优于LRU和T/C LRU算法。随着读写请求比例的减少,T/C LRU算法可置换的干净的磁盘页和闪存页所占比例逐渐降低,缓冲区中可用于优先置换的干净页越来越少,T/C LRU算法性能逐渐下降。同时DLAB算法在读写比例减少的情况下,由于基于代价的自适应性,对数据页的置换没有优先级别的划分,因此写操作次数和访问开销显著优于另外两种算法。
4 结束语
本文提出一种针对混合存储系统的自适应缓冲区管理算法DLSB。通过对数据页逻辑操作和物理操作的代价考虑,选择代价最优的数据域,较好的适应不同数据流的访问负载。同时,通过域中队列实际容量和队列理想容量的比较,最终确定置换的数据页,降低了对干净数据页的频繁置换。实验结果表明,与LRU和T/C LRU相比,DLSB显著降低了混合存储系统的I/O访问开销。今后的研究工作,将进一步完善DLSB算法中闪存脏页的置换效率,提高闪存的使用寿命和混合存储系统的I/O访问效率。
[1]CHEN Zhiguang.Research and implementation on introducing flash into multi-level storage archtecture [D].Changsha:National University of Defend Technology,2009:20-30(in Chinese).[陈志广.引入flash的多层次存储结构研究与实现[D].长沙:国防科技大学,2009:22-30.]
[2]Koltsidas I,Viglas S D.Flashing up the storage layer[C].Proceeding of the 34th Conference on VLDB.New York:ACM,2008:514-524.
[3]Marsh B,Douglis F,Krishnan P.Flash memoryfile caching for mobile computers [C].Hawaii,USA:Proceeding of the 27th Hawaii International Conference on System Sciences,2005.
[4]Panabaker R,Hybrid Hard.Ready DriveTMTechnology:Improving performance and power for Windows vista mobile PCs[C].Porc of Microsoft WinHEC,2006.
[5]Bisson T,Brandt S,Long D.A hybrid disk-aware spin-down algorithm with I/O subsystem support [C].Proc of the 26th IEEE International Performance Computing and Communications Conference.New Orleans,Louisiana,USA,2007:11-13.
[6]Kim Young Jin,LEE Sung Jin,ZHANG Kangwon,et al.I/O performance optimization techniques for hybrid hard disk-based mobile consumer devices [J].IEEE Computer,2007,53(4):1469-1476.
[7]Wikipedia.Hybriddrive [EB/OL].http://en.wikipadia.org/wiki/Hybrid_drive,2011.
[8]Kim Young Jin,Kwon Kwon Teak,Jihong Kim.Energy-efficient file placement techniques for heterogeneous mobile storage systems [C].Proceedings of the 6th ACM IEEE International Conference on Embedded Software,2006.
[9]LEE Sang Won,Bongki Moon.Design of flash-based DBMS:An in-page logging approach[C].Proceedings of the ACM SIGMOD International Conference on Management of Data,2007.
[10]TANG Xian.ACR:An adaptive cost-aware buffer replacement algorithm for flash storage devices [C].Eleventh International Conference on Mobile Management,2010.
[11]Hyojun Kin.BPLRU:A buffer management scheme for improving random writes in flash storage [C].6th USENIX Conference on File and Storage Technologies USENIX Association,2008:239-252.
[12]Park Seon Yeong,Dawoon Jung.CFLRU:A replacement algorithm for flash memory [C].IEEE Transactions on Consumer Electronics,2006.
[13]YI Ou,Theo Harder,JIN Peiquan.CFDC-A flash-aware replacement policy for database buffer management [C].Proceedings of the Fisth International Workshop on Data Management on New Hardware.Rhode-Island,ACM,2009:15-20.
[14]Jung H,Shim H,Park S,et al.LRU-WSR:Integration of LRU and writes sequence reordering for flash memory [J].IEEE Trans on Consumer Electronics:2008:1215-1223.
[15]WU C H,KUO T W.An adaptive tow-level management for the flash translation layer in embedded systems [C].Proc of the IEEE/ACM International Conference on Computer-Aided Design,2006:601-606.
猜你喜欢
北京工业职业技术学院学报(2024年1期)2024-01-14 06:35:14
哈尔滨轴承(2020年2期)2020-11-06 09:22:36
电脑爱好者(2019年2期)2019-10-30 03:45:31
发明与创新·大科技(2019年12期)2019-03-17 09:23:31
网络安全和信息化(2018年2期)2018-11-09 01:16:18
网络安全和信息化(2017年3期)2017-03-10 07:45:51
网络安全和信息化(2016年8期)2016-11-26 06:42:50
中国教育信息化(2015年12期)2015-08-24 07:58:36
项目管理技术(2015年3期)2015-04-23 08:44:29
电测与仪表(2015年10期)2015-04-09 11:48:20
