
不同调查方法森林资源调查结果的整合技术研究
2012-03-26 08:38朱磊
自然保护地 2012年2期
朱 磊
(国家林业局华东森林资源监测中心 浙江杭州 310019)
对某一区域内,森林资源总量是客观性的,也是唯一的。但在森林资源调查中,由于采用不同的调查方法,会得到不同的调查结果。目前各省(市、区)普遍存在一类清查和二类调查“两套数”、“两张皮”的现象[1],给森林资源管理带来很大不便。如何将一类清查成果和二类调查成果进行有效整合[2],成为森林资源管理部门期待解决的燃眉问题。学术界常见的整合思路主要分两类:一是以一类清查的统计结果为控制,对二类数据的统计结果进行强制平差;二是以字段的调查精度为主要依据,对统计结果进行取舍,从而整合为一套综合性的统计数据[3]。这两类方法均只是对字段的总体统计值进行整合或取舍,对分项或分区域的统计分析则很难实现,应用范围受限较大。本文从数据库元数据的层面对两套数据进行整合,不仅可生成相应的森林资源整合数据库,产出总体森林资源数据,也能分县区统计分析其森林资源状况,进一步拓展和丰富了一类清查成果,属于深层次的系统性整合,具体思路是通过地理信息系统技术将基于小班的二类成果面状数据转化为基于样地的点状数据,以一类数据为控制数据,根据二套数据的差值对加密的样地数据进行拉伸或压缩,从而实现两套数的技术性整合,为森林资源管理和学术专家提供决策参考和技术思路。
1 调查方法概述
目前森林资源调查的方法归纳起来可分为抽样调查和区划调查两大类。
抽样调查是在调查区域内随机或机械布设一定数量的样地,通过准确调查样地推算区域的森林资源总量。典型的方法是国家一类清查,以省(市、区)为单位织织实施,对设定的固定样地每五年复位调查一次,产出各省(市、区)的森林资源数据,汇总后得到国家森林资源数据,各调查因子可统计其抽样精度,面积越大精度越高,面积小的精度无法保证。调查的主要目的是为了快速掌握大尺度宏观区域的森林资源状况,为制定或调整林业方针政策、规划、计划提供依据,在短时间内能够产出符合精度要求的森林资源数据,成本费用低,但只能产出清查省的总体数据,各地级市和县(市、区)的森林资源状况无法反映,具体数据不能落实到山头地块。
区划调查是一般以小班为单位,将调查区域区划为若干小区域,逐块全面调查后汇总得到森林资源数据。最为典型的方法为二类调查,通常以县级行政区域(国有林场、自然保护区或森林公园)为单位组织实施,每十年调查一次,产出覆盖各乡镇单位的森林资源数据,逐县汇总得到全省的森林资源数据。调查主要是满足森林经营方案编制、总体设计、林业区划等需要,主要优势在于不仅产出总体数据,而且产出的森林资源数据具有准确的空间分布,能落实到山头地块[4],但调查工作量大,每个小班属性因子的调查精度不高,矢量化数据的储存和处理较为困难,对计算机配置要求也较高。
2 整合思路
根据一类样地的横纵坐标数据,将其加载到地理信息系统平台,建立样地点状图层,利用编程工具进行等间距样地加密,使其能满足产出县级森林资源数据统计的抽样精度要求。然后与二类小班面状数据层进行叠加,对中心点落入小班内的样地,将二类小班的属性利用计算机自动赋值给样地属性,确定其所代表的权重面积,从而将基于小班为二类成果面状数据转化为基于样地的点状数据,使两套数据具备相同的整合对接窗口。再以一类数据为控制数据,根据二套数据的差值对加密的样地数据拉伸或压缩,从而实现两套数的技术性整合。
3 整合技术方法
3.1 技术准备
一般情况下各地二类汇总成果皆包含行政界、林班界、大班界、小班界等的矢量化数据,否则应对二类成果图进行矢量化,创建规范的数据层,将其加载到地理信息软件平台。逐个字段规范其属性因子,使两套数据具有相同的属性结构和量度单位。确定需要整合的字段,并按优先顺序将其排序,整合字段一般为地类、林种和蓄积量等关键字段,选择的整合字段在一类统计成果中须达到相应的抽样精度要求,否则该字段整合结果难以让人信服。
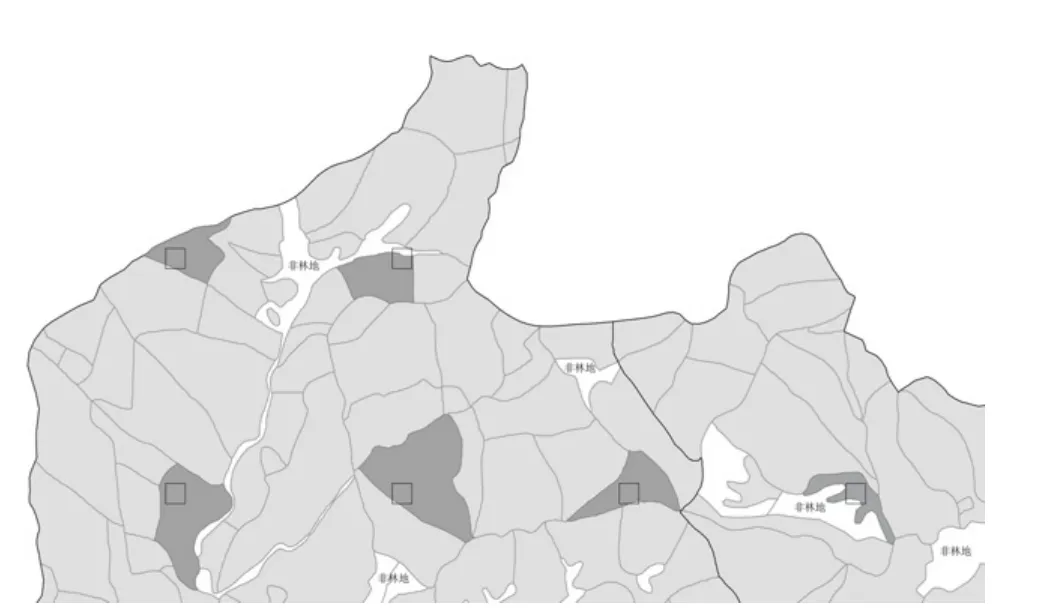
图1 一类清查数据和二类调查数据整合技术思路示意图
3.2 样地数据确定
先根据统计数表的特征和精度要求计算所需布设样地的数量,样本数量至少要能满足县级森林资源数据的统计需要,因为省级森林资源数据常常是分县区统计进行汇总。由于样地是计算机自动布设,赋值是计算机批量进行的,因此可通过增加样地数量的方式来提高抽样精度。如果要考虑产出县级分乡镇的统计数表,样地应进一步加密,可按县为单位进行布设后再汇总,但应注意布设样地的面积权重,产生的汇总误差也应累计到全省的总误差内。
3.3 样地布设与赋值
根据区域行政面积的大小和样地数据确定样地间距,计算方法是将区域行政面积除以样地数量,再开方取整。采用编程的方式自动产生加密样地横纵坐标,根据坐标值在地理信息系统软件平台上生成样地分布图。将样点图层和二类小班面图层进行叠加,对中心点落入二类小班内的样地,利用系统的空间属性关系将小班的属性数据赋值给样地属性,使样地与其中心点落入二类小班具有相同的属性数据。如果样地坐标数据与一类样地坐标相同,用一类样地的属性数据代替样地的属性数据,以便不影响一类数据的统计结果。例见图1,该图为某县二类调查成果矢量图的西北部角点,图中方形黑框为计算机自动布设的样地,深色图斑为样地中心点落入的二类面状小班,浅色图斑为样地中心点未落入的二类面状小班,白色部分为非林地,利用计算机将深色小班的属性读取给中心点落入其内部的样地,即可实现加密样的自动赋值。
3.4 数据的压缩与拉伸
统计加密后的森林资源数据,如果整合字段的统计数据大于一类数据,则应进行圧缩处理,反之则需拉伸处理。圧缩和拉伸仅针对不与一类样地重复的样地,以确保一类样地的原始性。对地类、林种等属性,压缩和拉伸的方法是整体调整样地代表的权重面积,由于土地总面积是定数,某一地类数偏高,则其它地类会偏低,因此压缩和拉伸时应保持土地总面积不变。以地类调整为例:如某地区共加密布设1万个样地,加密后的乔木林面积比一类面积多20万亩,竹林少15万亩,宜林地少5万亩。调整方法为:将所有乔木林样地的权重面积减去20万亩,竹林样地的权重面积加上15万亩,宜林样地的权重面积加上5万亩。对蓄积可直接调整样地蓄积量,但调查系数的确定应考虑到乔木林样地本身的蓄积量大小,如蓄积量本身为0立方米,不应再作加减,蓄积量越大,调整量应越大。
3.5 数据统计与分析
整合后的数据库在经过压缩和拉伸之后,可采用一类清查的方法进行统计,分析整合字段的统计值是否与控制数据相符,若不相符,则应继续调整,直到满足要求为止。数据调整时应在确保第一个字段权重面积不变的情况下调整第二个字段,避免前面的字段平衡后又转为不平衡。最后统计主要字段的调查精度和真值区间,看是否达到相关要求,否则应增加样地数量,重新布设样地和赋值,符合要求后正式生成整合成果数据库,即可进行各类数据统计分析。
4 几点说明与讨论
(1)若采用本方法,将二类数据整合到一类清查成果,须满足以下条件,否则产出的成果难以到得公认:一是二类成果数据应落在一类成果数据的真值区间内,符合精度要求,若二类数据落在一类成果数据的误差范围之外,那么二套数据的差值不是方法误差,属调查误差,应进行调查纠错后再进行整合,如果强制整合,数据扭曲性太大,实用价值不高;二是该地区已确认一类数据为公布数据,代表官方权威数据,如果该地区已认可当地的二类数据为官方数据,进行此项工作无实质意义;三是假定二类小班的外业调查数据准确,所区划的每个小班在空间上是均质的,落入小班的加密样地,其属性因子与小班完全一致。
(2)利用本方法能够将二类调查成果和一类清查成果有效整合起来,解决各省(市、区)两套数、两张皮的问题,拓展了一类清查成果,并能生成带有空间坐标和各种尺度的森林资源数据库,在样地数量达到相应要求的情况下,借助地理信息系统的空间属性和编程工具,可实现各应用区域的快速出数、应急监测和制定各类森林分布图。
(3)目前全国正在推进林地一张图的工作,主要是将二类调查成果的矢量图逐县逐省汇总起来,可能会面临两大难题:一是汇总工作量很大,由于各级行政界线争议较多,两个相邻区域重和漏区块的汇总协调难度大;二是由于是以图班为基础进行汇总的,会产生海量的各类点线面图层,目前的常规计算机处理能力、贮存能力均难以有效支持,特别在全国汇总阶段。利用本技术思路可大大缩短工作量,整合成果是一个不带图界的简单数表,占用内存小,处理快捷,可相对容易实现各地的汇总工作,生成全国的“一套数”的森林资源数据库。
[1] 曾伟生,周佑明.森林资源一类和二类调查存在的主要问题与对策[J].中南林业调查规划,2003, 22(4):8-11.
[2] 傅宾领,古育平等.新时期加强森林资源与生态状况监测的对策措施[J].林业资源管理,2007, (1):25-28.
[3]曾伟生.森林资源一类清查和二类调查数据的协调性问题探讨[J].中南林业调查规划,2008, 27(1):50-52.
[4] 熊泽彬,周光辉.关于森林资源监测体系总框架的构想[J].林业资源管理,2003,(4):28-30.
猜你喜欢
环球时报(2023-01-16)2023-01-16
医药与保健(2022年2期)2022-04-19
源流(2021年1期)2021-07-28
海洋信息技术与应用(2021年1期)2021-06-11
中学生数理化·高一版(2021年2期)2021-03-19
办公室业务(2019年13期)2019-08-01
中国粮食经济(2018年11期)2018-12-27
农村财务会计(2018年12期)2018-12-12
农村财务会计(2018年9期)2018-09-13
中国神经再生研究(英文版)(2017年10期)2017-11-08
