
面向单机相依任务调度的GPU并行蚁群算法
2012-03-24 13:04邓向阳张立民黄晓冬
海军航空大学学报 2012年4期
邓向阳,张立民,刘 凯,黄晓冬
(海军航空工程学院 a.电子信息工程系;b.科研部,山东 烟台 264001)
当前许多系统面临的都是多机多任务的复杂环境,在一个系统内会不断出现需要服务的任务,并且在系统中往往存在多个可以进行服务的机器设备,对这类系统执行效率的研究受到了高度重视。此类系统的优化目的一般都是以执行时间最小为目的,是一个调度排序问题。虽然现实中的多机系统很复杂,但是大量多机系统具有松散耦合的特性,不同机器之间任务的联系不是非常紧密,不同机器之间的资源关联很小,在这种多机系统的任务调度过程中,可采用单机系统模型的线性叠加实现。另外,单机系统本身也以实体形式存在于许多应用领域。因此,有许多学者对单机调度问题进行了研究,如杨善林[1]等提出了一种启发式算法,研究了部分可续型单机的最大完工时间调度问题;卢冰原[2]等采用粒子群算法研究了时间参数模糊化的多目标差异作业单机批调度问题模型;王栓狮[3]等采用蚁群算法对一种差异工件单机批调度问题进行了研究。
本文以单机相依任务调度问题(Dependent Task Scheduling on Single Machine,DTSSM)研究为重点,建立单机调度问题的优化模型,基于通用计算架构(Compute Unified Device Architecture,CUDA)在流多处理器(Stream Multi-Processors,SM)中实现基于局部信息素更新的实时种群进化机制,并通过多SM 上基于全局信息素更新机制的多种群协同规约,建立一种基于GPU 的并行蚁群算法,并将该算法结合单机调度问题模型,实现了一种低传输量、鲁棒性好、并行化计算的单机相依任务调度算法。
1 单机相依任务调度问题模型
单机调度模型是应用领域的一个基本问题,对其进行深入研究是研究复杂多机系统的基础。单机调度模型主要讨论多个任务在单个机器上的执行过程,以达到效益最大化。
每个需要在机器上执行的任务叫做一个单任务,其具有如下性质:
1)由某个机器一次性单独完成;
2)单任务需求之间可能相互依赖,单任务在不同执行序下所需的时间不同。
据此,DTSSM 问题是一个相依多任务的排序问题,通过建立任务的作业顺序,使得任务之间的相依性最大,完成时间最短。DTSSM 问题的数学模型可定义为P=<ID,T,C>,其中,P为单任务集合,ID为该任务的编码集合,T为相依时间关系,C为任务执行的顺序号。
设有n个任务{ei},相依时间关系矩阵为T={tij},tij表示ej在ei之后执行时需要的时间,要求ej和ei之间具有紧前紧后执行关系,执行序变量为vi,x,其表示ei在第x序号执行,得到的DTSSM问题模型为:
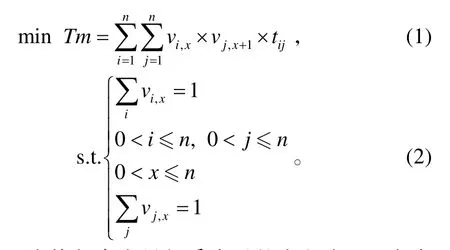
式(1)中2 个执行序变量相乘表示的含义为:只有当ei和ej具有紧前紧后执行关系时,ej的执行时间才计入总时间消耗。
相依时间矩阵T表示了不同任务相依关系下执行时间的经验,则T为一个非对称的非负矩阵,通过该矩阵定义了一个非对称加权的有向图G=(V,E),其中顶点为任务ei的集合,弧为相依任务执行时间的集合。如果两节点代表的任务之间可以相继执行,则建立弧,权值大小代表了相依执行序下的完成时间,如果2 个任务间不能够相继执行,则节点之间不存在弧,而节点的自连接,为任务无紧前任务时的执行时间。
通过上述转换,相依任务单机调度问题转为在每个G中搜索一条路径,该路径遍历G的所有节点,使加权和最小。该问题可等效为一个 ATSP (Asymmetric traveling salesman problem)。
2 单机相依任务调度蚁群算法
蚁群算法(Ant Colony Optimization,ACO)是一种群智能算法,通过蚂蚁个体之间的简单行为涌现出复杂的计算能力,具有并行化、正反馈、自组织、容易实现等优点,在不同领域得到了广泛的应用,ATSP 模型求解是蚁群算法的经典应用领域。本文研究的面向DTSSM 问题的蚁群算法模型以蚁群系统(Ant Colony System,ACS)[4]为基础,针对单机相依任务调度问题进行设计,定义为单机相依任务调度蚁群算法(DTSSM based on ACO,DTSSM-ACO)。
DTSSM-ACO 算法通过伪随机比例规则选择相继执行任务,根据各条执行路径上的信息量和启发函数值来计算状态转移概率。设表示蚂蚁k在执行完ei后继续执行ej的概率,可以通过下式计算:

式(3)中:α为信息启发式因子,表示轨迹的相对重要性;β为期望启发式因子,表示相依时间关系的相对重要性;τij为弧上的信息素密度;ηij为弧上的启发函数的值。ηij可以通过下式计算:

式中,tij表示pj在pi之后执行时的所需作业时间。
在每次迭代之后,全局信息素更新通过计算最优路径上的耗费时间得出,按照如下规则更新最优路径上的信息素:

式(5)中:Δτij为路径上的信息素增量;Tm*为本轮最优路径所耗费的总时间;ρ为信息素挥发系数。
3 基于GPU的DTSSM-ACO算法并行化设计
3.1 蚁群算法的并行化设计
蚁群算法是一种自然的并行化算法,只有运行在并行环境中才能体现其效能。目前,已有学者针对蚁群算法研究了4 种层次上的并行化:种群层次的并行化、蚂蚁层次的并行化、数据层次的并行化和函数层次的并行化[5]。对于种群层次的并行化和数据层次的并行化属于粗粒度并行化,而蚂蚁层次的并行化和函数层次的并行化属于细粒度并行化。整体来说,对蚁群算法进行并行化研究的文献较少,主要有M Dorigo[6]等实现了一种多种群的并行蚁群算法,得到了数据层次上的并行化设计;Marcus Randall[7]等设计了一种不需要通信的独立多处理器并行蚁群算法;于滨[8]等在多处理机上实现了一种粗粒度的并行蚁群算法。
因为一般的并行化需要多个处理器执行,多处理器的调度、并行编程等本身也是一个问题,广泛应用受到限制。因为GPU 的普及和结构简单等特点,近几年有学者将蚁群算法移植到GPU 上实现:李建明[9]等人首次采用GPU 实现了一种细粒度的并行蚁群算法;赵元[10]等人提出了基于多叉树并行蚁群算法的区位选址优化方法,并采用GPU 对其实现了并行加速设计;白洪涛[11]等人实现了一种基于共享信息素矩阵的并行蚁群算法,并证明了算法是值收敛和解收敛的。
GPU 就是我们通常所说的显卡的核心部分,它是一种浮点数处理器,是专为图形数据这种计算密集型、高度并行化的情况而设计的。因此,面向GPU的设计必须转化为标准的图形处理过程,这种移植过程需要专业的图形专业人员,实现难度大。
3.2 基于CUDA 的DTSSM-ACO 并行优化
为了解决GPU 应用专业受限的问题,NVIDIA公司于2007年推出了面向GPU 通用计算的CUDA架构。CUDA 是一种将CPU 和GPU 协同进行计算的架构,通过运行在CPU 上的程序进行任务的分支、选择等操作,而采用GPU 完成面向数据的处理操作,在CPU 上串行处理,称为Host 端的处理;在GPU 上并行处理,称为Device 端的处理。在Host端的主控函数中,依次调用Kernel 函数进行串行运算,而每一个Kernel 函数都是一段GPU 计算过程,调用时都会将计算转移到GPU 上执行,执行完之后返回。在Device 端的计算过程中,函数的处理过程被组织成大量的并行线程,进行同步处理。CUDA支持大量的线程并行,并在Device 中动态地创建、调度和执行这些线程。
针对前述的DTSSM-ACO 算法,下面实现一种基于CUDA 的多蚁群并行进化,且各蚁群内蚂蚁并行执行的两级并行策略。首先,将每个蚁群组织为一个Block,所有Block 共用一个路径矩阵存储空间,每个Block 中的蚂蚁进行某个任务阶段的路径搜索工作,每个Block 具有独立的信息素存储空间,通过共享存储器实现通信;每个Block 对应一个SM,在其中分配多个蚂蚁,每个蚂蚁对应一个线程,在一个流处理器上执行。
在上述的两级并行策略中,每个蚁群属于一个Block,该蚁群的所有蚂蚁的私有信息,包括已有解路径、禁忌表等信息,都存储在共享存储器中。独立蚁群在计算过程中,每次蚂蚁的移动都采用局部信息素更新策略更新信息素矩阵,信息素矩阵存储在共享存储器中,实现独立种群的即时信息素共享;在所有独立蚁群执行完毕之后,将各自的信息素矩阵读回CPU 内存进行规约,并进行所有种群的信息素更新,该过程采用全局信息素更新策略,使不同独立种群之间进行通信,达到所有蚂蚁协同进化的目的。DTSSM-ACO 算法流程如图1 所示。

图1 DTSSM-ACO算法流程
4 实验结果及分析
DTSSM-ACO 算法实验的环境为:CPU 为Intel Core i5 760@2.8GHz;内存为4GB RAM;操作系统为Windows 7,显卡为GeForce GTX 460,CUDA的计算能力为2.1。实验过程选取了50、100、200、400、800 个任务分5 次测试,任务之间的相依作业时间在[5, 15]之间随机产生,每个种群输出30 只蚂蚁进行搜索,其他参数设置为ρ=0.1、α=2、β=1.2、τ0=0.001,算法循环300 次,由算法得到的全局最优值曲线和加速比如图2 所示。

图2 最优解变化过程和加速比
通过图2 可分析知,算法在110 次迭代左右达到了收敛状态,在后期保持了算法的稳定性,表明DTSSM-ACO 算法具有可行性。同时,通过在GPU上的并行优化设计,使得算法在5 种不同规模任务环境中得到了从3 到39 不等的加速比。在任务数较小时,得到的加速比小,这是因为任务数较小时并行算法的大部分时间花在从CPU 内存上载数据到GPU 内存,以及相反的数据传输过程,得不到好的加速效果,但是随着问题规模的增大,大部分时间需要完成计算功能时,加速效果得到了明显的改善。
5 结论
本文探讨了一种单机相依任务调度问题,通过将该问题等效为非对称TSP 问题,采用蚁群算法对其进行了求解,为了获得更好的求解效率,对面向单机相依任务调度问题的蚁群算法基于GPU 进行了并行化设计,取得了较好的加速比。但是,本文没有探讨多机环境下的调度模型,也没有对基于GPU 的并行化算法进行了更加深层次的加速,这将是后续的重点研究内容。
[1] 杨善林, 马英, 鲁付俊. 带不可用时间段的单机调度问题的启发式算法[J]. 系统工程学报, 2011,26(4): 500-506.
[2] 卢冰原, 黄传峰, 贾兆红. 模糊环境下多目标差异作业单机批调度问题研究[J]. 控制与决策, 2011,26(11): 1675-1680.
[3] 王栓狮, 陈华平, 程八一, 等. 一种差异工件单机批调度问题的蚁群优化算法[J]. 管理科学学报, 2009, 12(6):71-81.
[4] DORIGO M, GAMBARDELLA L M. Ant colony system: a cooperative learning approach to the traveling salesman problem[J].IEEE Transactions on Evolutionary Computation, 1997,1(1):53-66.
[5] ANDRIES P ENGELBRECHT. 计算群体智能基础[M]. 谭营, 译. 北京: 清华大学出版社, 2009:303-306.
[6] M DORIGO, DI CARO G. The ant colony optimization meta-heuristic[R]. London: McGraw Hill, 1999.
[7] MARCUS RANDALL, JAMES MONTGOMERY. Candidate set strategies for ant colony optimization[R]. Queensland: School of Information Technology, Bond University, 2002.
[8] 于滨, 程春田, 杨忠振. 一种改进的粗粒度并行蚁群算法[J]. 系统工程与电子技术, 2006,28(4):626-629.
[9] 李建明, 胡祥培, 庞占龙, 等. 一种基于GPU 加速的细粒度并行蚁群算法[J]. 控制与决策, 2009,24(8): 1132-1136.
[10] 赵元, 张新长, 康停军. 并行蚁群算法及其在区位选址中的应用[J]. 测绘学报, 2010,39(3):322-327.
[11] 白洪涛, 欧阳丹彤, 李熙铭 等. 基于GPU 的共享信息素矩阵多蚁群算法[J]. 吉林大学学报: 工学版, 2011,41(6):1678-1683.
猜你喜欢
计算机测量与控制(2022年2期)2022-03-30
新疆钢铁(2021年1期)2021-10-14
军民两用技术与产品(2021年4期)2021-07-28
音乐天地(音乐创作版)(2020年2期)2020-04-18
数字通信世界(2020年3期)2020-04-06
歌海(2019年5期)2019-12-19
航天工业管理(2019年11期)2019-04-20
特别文摘(2016年18期)2016-09-26
特别文摘(2016年15期)2016-08-15
现代防御技术(2016年1期)2016-06-01
