
基于并行计算的木马免疫算法研究
2012-03-17 07:20王应战魏衍君
电子设计工程 2012年16期
王应战,魏衍君
(商丘职业技术学院 计算机系,河南 商丘 476000)
免疫算法是借鉴生物免疫系统中抗体识别抗原的原理发展起来的,是人工智能的一个新的研究领域,也是目前国内外研究的一大热点,许多研究学者都针对这一领域开展了深入、富有成效的研究工作。免疫算法主要模拟生物免疫系统中抗原处理的核心原理,运用免疫算法求解问题,本质上是抗体识别抗原的过程,而抗体(检测器)的产生是非常关键的一个步骤,关系到整个免疫检测系统的运行效率[1-2]。
常见免疫算法主要有阴性选择算法和克隆选择算法等。阴性选择算法由Forrest等人在1994年提出[3-4],该算法步骤简单,但却实用有效,阴性选择算法以r连续位匹配规则为基础,实现局部匹配,算法效率较高。但其也存在着致命缺陷,因为当检测字符长度增加或者匹配位数r增加时,检测效率大大降低,系统开销大大增加[5]。
文中提出一种改进的阴性选择算法,把总长度为L的字符串分成n个特征区域时,每一段特征区域产生一系列相应的检测器子集合,然后采用并行计算的匹配方式,对于整体则采用r连续位匹配规则进行匹配。设定匹配阈值,如果匹配度高于该阈值则两个字符串匹配,否则不匹配。
1 阴性选择算法
在免疫系统中,按照机体内外可以把整个机体分为“自我”和“非我”。将所要维护的正常模式行为或者系统的静态行为定义成“自我”,将异常行为模式定义为“非我”。阴性选择算法是个否定选择过程,目的在于区分“自我”和“非我”。设免疫系统整个空间为 U,“自我”为 S,“非我”为N,它们满足关系式:U=S∪N,S∩N=Ø。阴性选择算法以r连续位匹配规则为基础,r代表一个阈值,是衡量单个检测器能匹配字符串子集大小的指标[6]。
图1给出了采用阴性选择算法产生检测器的流程。
Forrest阴性选择免疫算法简述如下:1)分析问题,根据实际问题确定参数 PM、NS、Pf、r, 其中 PM为匹配概率,NS为自体个数,Pf为期望的检测失败率,r为阈值;2)随机产生NS个长度为L的二进制字符串作为自体;3)计算所需检测器个数NR与候选检测器个数NH;4)产生检测器,即随机产生一个长度为L的字符串,并与自体进行比较,如果随机产生的字符串与自体中任何一个字符串匹配,则丢弃该字符串;如果随机产生的字符串与自体中所有字符串都不匹配,则保留该字符串作为检测器。重复该过程直到得到NR个检测器。其重复次数即为候选检测器个数NH;5)验证检测效果,即改变自体中的某个字符串,并用所有检测器与自体进行逐个比较,若出现匹配则表明检测成功,否则检测失败。
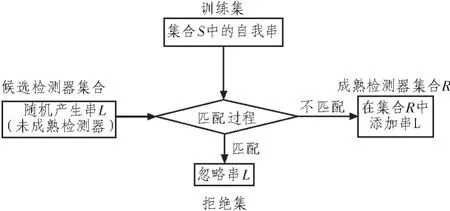
图1 检测器生成过程Fig.1 Detector generation process

表1 阴性选择算法中主要参数Tab.1 Negativeselection algorithm m ain param eters in the form ula
由表1可知,匹配概率PM、检测失败率Pf对系统整体性能有很大影响。设定检测失败率Pf和自体规模NS在一定范围内的时候,决定候选检测器规模NH和检测器规模NR的只有匹配概率PM。当PM增大,NH和NR呈指数形式增加,这将导致检测时间大幅增加。而NH决定着系统的整体运行时间,NR决定着系统所占用的空间,因此PM的选择范围对整个系统性能起着决定性作用。传统阴性选择算法采用随机生成字符串的形式,匹配概率PM的值就由两个字符串间的匹配规则、匹配位数来决定[7]。
如果采用完全匹配规则(r=L),则当且仅当两个随机字符串相应位置的每一位字符均相同时,则两个字符串匹配,其匹配概率为PM=1/2L;如果采用部分匹配规则,即r<L时,则匹配概率 PM≈m-r[(l-r)(m-1)/m+1]。 当在试验中字符串采用二进制码,即 m=2 时,匹配概率公式则变为 PM≈2-r[(l-r)/2+1]。
候选检测器NH的数量将随着“自我”集合中二进制编码长度的增加成指数级增长,经阴性选择的检测器没有经过冗余检查就直接将其作为成熟检测器中的一个元素进入下一个环节,这可能导致成熟检测器集合R中的数据冗余。尽管在Forrest之后也提出了一些改进方法,如线性算法、贪婪算法、二进制模块算法,但都没有很好地解决上述问题。
2 阴性选择算法的改进
Forrest阴性选择算法中步骤4随机产生一个长度为L的字符串,并与自体进行比较,一般是采用局部匹配的方式进行比较,也就是采用r连续位匹配的方式;如果匹配位数r太小,在“自我”和“非我”相似度较大时,检测器会把“非我”当成“自我”而删除;但是随着r的增加和字符串L的增加,匹配次数呈指数形式增加,匹配效率明显不足,并且会产生大量的候选检测器,使得该算法时间复杂度太大,因此,在实际应用中就存在一个如何选择字串长度和匹配区域的问题[8]。
文中提出一种基于并行计算的多特征区域匹配方式,产生检测器和自体进行匹配,然后对于冗余的候选检测器进行筛选,最后产生成熟检测器。
该算法步骤如下:
1)把总长度为L的字符串分成n个特征区域,每个特征区域长度记为 Li(i=1,2,3…,n);
2)每一段特征区域产生一系列相应的检测器子集合Ni(i=1,2,3…,n),用这个检测器子集合对相应的特征区域进行特征匹配,各个特征区域的检测器集合是相互独立的,整个字符串的检测器集合 N={N1,N2,N3…,Nn};
3)对于每一个特征区域,采用并行计算的匹配方式,采用多指令流多数据流(MIMD)的体系结构。把自体串和特征区域放入两个数组中进行比较,通过n个处理器并行计算;
4)根据检测器子集合对每一个特征区域进行检测,得到它的匹配长度ri,设定每个特征区域的重要性权值Ii,有0≤ri≤li,0≤Ii≤1;
5)设定Mi表示特征区域的匹配情况,Mi=1表示该特征区域匹配,Mi=0表示不匹配,对于由各个特征区域组成的整体字符串,采用r连续位匹配规则进行匹配,得到它的匹配度R;
6)设定匹配阈值μ,如果公式(1)成立,则两个字符串匹配,否则不匹配。
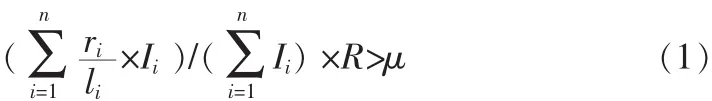
对于r连续位匹配算法,影响算法的主要因素是样本个数、字符串长度和连续位数。运用以往的r连续位算法,要至少遍历两个字符串的对应位置,但是如果采用并行算法,最佳效果是仅匹配一次即可成功,这将大大减少计算量,并增加运行效率。对于木马检测这种对实时反应时间要求较高的匹配模式来说,运用并行算法能较好地提高检测成功率和减少误报率;本算法采用了特征区域生成的办法产生检测器集合,以避免由于匹配区域r增大所带来的效率过低的问题,改进算法能较快速高效地产生满足精度要求的检测器集合。
但是对于各个特征区域,该算法都要产生一系列对应的检测器子集合,各个特征区域的检测器集合是独立的,因此区域与区域之间的检测器有可能会重复,从而产生检测器冗余。针对这个问题,文中加入了冗余检测器筛选步骤,对经过改进的阴性选择算法后产生的候选检测器进行筛选,把它们和已经存在的成熟检测器进行比对,判断该候选检测器是否重复,如果是重复的则删除该检测器,否则把它加入到成熟检测器集合中。
实验1:设定其他的参数不变,在不同的自体规模(即Ns)下进行实验,仿真结果如表2所示。
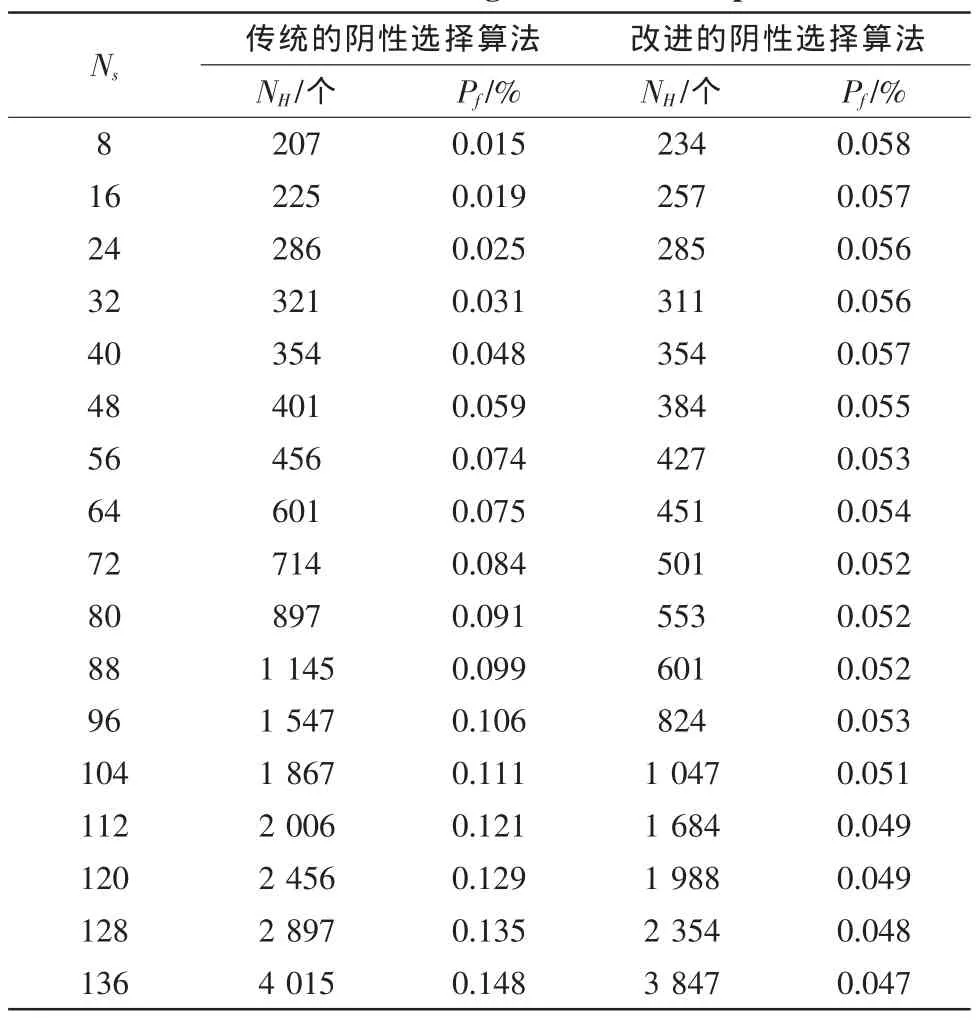
表2 两种不同算法的比较Tab.2 Two different algorithm s for comparison
由表2可以看出,当自体规模从8增加到136的时候,传统算法产生的候选检测器数量大大增加,从207个增加到了4 015个,增加了18倍。而检测失败率也从0.015%增加到了0.148%,增加了将近9倍;而用本文改进的算法所产生的候选检测器数量只从234个增加到3 847个,增加了15倍,而失败率反而从0.058%降低到了0.047%,检测失败率下降了17%;虽然在自体规模只有8个的时候,改进算法产生了234个候选检测器,多于传统算法,这是因为改进算法较复杂,可能会增加冗余的检测器,但是随着自体规模的增加,候选检测器的数量能保持较少的增长率,说明改进算法的收敛性较小,收敛效果较好,而且也提高了检测成功率。
实验2:设定随机字符串长度L和自体规模Ns不变,改变匹配位数r的长度,对比两种算法产生的候选检测器数目NH和检测时间t,结果如表3所示。

表3 两种算法的检测时间对比Tab.3 Two algorithm testing tim e contrast
由表3可以看出,在字符串L位数和自体规模NS不变的情况下,当匹配位数r增加,传统算法所产生的候选检测器数目大大增加,增加了将近18倍,检测时间增加了18倍,效率明显降低;采用文中的多属性特征区域匹配方式,候选检测器集合数目增加了只有11倍,并且改进算法引入了并行计算的方式,检测时间增加了14倍,而且低于传统算法的检测时间。从这里可以看出,新算法在匹配位数r增加的情况下,系统效率影响较小,能有效改善系统性能。
3 结束语
阴性选择算法随着匹配位数r的增加和字符串L的增加,匹配次数呈指数形式增加,匹配效率明显不足,并且会产生大量的候选检测器,使得该算法时间复杂度太大,论文提出一种改进的阴性选择算法,把字符串分为多个特征区域,每个特征区域之间采用r连续位匹配方式再次匹配,同时采用并行计算,实验结果表明改进的阴性选择算法在匹配位数和随机字符串位数增加时,候选检测器增加速度较平缓,系统负担增加较缓慢,因此具有较好的检测效率。
[1]刘念,刘孙俊,刘勇,等.一种基于免疫的网络安全态势感知方法[J].计算机科学,2010(1):126-129.
LIU Nian,LIU Sun-jun,LIU Yong,et al.A network security situation awarenessmethod based on immune[J].Computer Science,2010(1):126-129.
[2]关潮辉,薛琴.木马的攻击与防范技术研究[J].信息网络安全,2010(12):20-21.
GUAN Chao-hui,XUEQin.Trojan attacks and guard against technology research[J].Information Network Security,2010(12):20-21.
[3]陈雷霆,张亮.人工免疫机制在木马检测系统中的应用研究[J].电子科技大学学报,2005(2):221-224.
CHEN Lei-ting,ZHANG Liang.Research of trojan detection system based on artificial immune[J].Journal of University of Electronic Science and Technology of China,2005 (2):221-224.
[4]张红梅,范明钰.人工免疫在未知木马检测中的应用研究[J].计算机应用研究,2009,26(10):3894-3897.
ZHANG Hong-mei,FAN Ming-yu.Research of unknown trojan detection based on artificial immune[J].Application Research of Computer,2009,26(10):3894-3897.
[5]Aickelin U,Green S J,Twycross J.Immune system approaches to intrusion detection-a review[C]//Catania, Italy:Proceedings International Conference on Artificial Immune System,2004.316-329.
[6]HE Shen,LUOWen-jian,WANG Xu-fa.A negative selection algorithm with the variable length detector[J].Journal of Software,2007,18(6):1361-1368.
[7]ZHANG Heng,WU Li-fa.An algorithm of radjustable negative selection algorithm and its simulation analysis[J].Chinese Journal of Computers,2005,28(10):1614-1618.
猜你喜欢
数学年刊A辑(中文版)(2021年4期)2021-02-12
喀什大学学报(2020年6期)2021-01-28
无线互联科技(2020年11期)2020-12-01
火力与指挥控制(2018年10期)2018-11-13
中国交通信息化(2017年9期)2017-06-06
电子制作(2017年10期)2017-04-18
工业设计(2016年11期)2016-04-16
航天返回与遥感(2014年4期)2014-07-31
燕山大学学报(2014年1期)2014-03-11
通信学报(2014年12期)2014-01-01
