
SSD数据结构与算法综述
2012-02-05 06:37史高峰李小勇
微型电脑应用 2012年4期
史高峰,李小勇
0 引言
SSD是一种基于闪存的电可擦除可编程的新型存储器件,本文主要介绍SSD闪存的数据结构和算法以及SSD闪存在分层存储中的应用。
闪存的读、写或擦除操作与易失的 RAM 和磁盘有很大的不同。闪存的每个单元只能擦写有限次(10,000到1,000,000次),超过这个最大次数后,闪存就变得不可靠了。
闪存种类主要有两种,NOR和NAND,这两种有很大的区别。写操作都是把“1”置为“0”,而擦除操作需要把一整个擦除单元的所有位都置为“1”。一个固定设备的擦除大小是固定的,从几KB到上百KB。NOR闪存的每个位(bit)都能被处理机直接访问并擦除,但是NOR的擦除时间比较长,而NAND闪存,擦除时间比较短,但是处理机不能访问到每个位(bit),访问的最小单位是页(page),一个擦除单元由很多页构成,典型的页大小为 512字节(byte)。一个擦除周期中的一个页只能被修改几次,因为修改几次后,页中的数据就不再可靠了。
因为这些特殊性,基于磁盘的一些存储技术就不太适合闪存了。随着闪存的广泛应用,在20世纪90年代后,基于闪存的存储技术不断发展。这些技术中,有一小部分是针对闪存的发明设计,而大部分发明是源自其他的存储技术。本文就是分析比较了闪存的各种数据结构和算法。
1 块映射技术
将闪存块当做磁盘块使用,会产生两个问题:
第一,一些块的修改次数远远大于其他块,对于磁盘块不会有任何问题,但是闪存中的这种块就会由于擦除太多而达到擦除上限,这种问题可以通过损耗均衡技术解决。
第二,不合理的映射会将一个很小的块映射到闪存的一个擦除单元,例如,文件系统将一个4KB的数据块映射到闪存中一个128KB的擦除单元中,那么修改这个数据块就需要将这128KB复制到内存,在内存中修改这4KB数据,擦除闪存中相应的128KB的擦出单元,然后,将这4KB数据写回闪存,如果中间掉电,可能会损失128KB数据,而磁盘中只会损失4KB数据。这个问题也可以通过损耗平衡技术解决。
1.1 块映射的思想
所有损耗平衡思想都是基于一个映射关系,即一个虚拟块号映射到闪存中的一个物理块号。闪存中,当一个虚拟块需要被重写,新数据不会写到之前映射到的那个物理块,而是写入一个新的物理块中,并修改逻辑块号和物理块号的映射表。
闪存中的一个物理块一般是一个擦除单元中的固定大小的一部分,在NAND闪存中,一般是一个页,而在NOR闪存中,有可能还会是变长大小。
这种映射有几个目标:
首先,频繁修改的块会保存到不同的物理块中,便于损耗平衡。
再次,这种映射允许写擦除单元中的一个页,而不是立即擦除掉整个擦除单元再进行写。
第三,写操作保持原子性,如果写的过程中断电,可以回滚到之前的状态。
写操作的原子性主要通过以下技术实现,每个物理块有一个小的头部,这个头部可以在物理块中,也可以保存在其他擦除单元中。当写一个块时,首先找到一个可用的物理块,这种块和它的头部中的所有位都为“1”,然后头部中的“空闲/占用”位被置为“0”,表明这个块已经被占用,逻辑块号写入这个物理块的头部的相应位置,并且数据写入相应的物理块中,然后,头部中的“无效/有效”位被置“0”,表明这个块可以读,最后,之前旧的版本的物理块的头部中的“有效/过时”位被置“0”,表明这个块不再是虚拟块的最新版本。
如果在写操作中电源丢失,可能会出现两种状况,如果断电发生在新写的物理块被标记为有效之前,则新写的块被置为无效,并且“有效/过时”位被置“0”,标记新块可以被回收;如果断电发生在新写的物理块被标记为有效之后但是旧的物理块标记为过时之前,这两个物理块都是合法的,系统将随意选择一个标记为过时,如果最近更新的版本更重要,通过一个两位的版本号标示出哪个是最新的,具体是1比0新,2比1新,3比2新,0比3新【Aleph One 2002】。
1.2 块映射的数据结构
系统如何通过逻辑块找到相应的物理块呢?一般情况下,通过两种数据结构,一种是正向映射,另一种是反向映射。正向映射是将逻辑块号和物理块号填入一张表中,系统可以通过逻辑块号查询到相应的物理块号,反向映射是将每个物理块的块头中保存逻辑块号,如果系统需要通过逻辑块找到相应的物理块,就需要遍历物理块直到找到相应的逻辑块为止。正向映射可能不是简单的队列实现而是一些更复杂的数据结构,以便于更高的查询效率。而反向映射必须是队列,队列中的物理位置上可以不是连续的。
反向映射保存在闪存中,当一个逻辑块写入物理块时,逻辑块号记录到相应的物理块的头部中,并且逻辑块号伴随物理块的擦除而擦除。反向映射的主要作用是在设备初始化时重构正向映射。
正向映射保存在闪存控制器的内存中,是易失的,正向映射的作用是支持快速查询逻辑块的相应物理块,当逻辑块和相应的物理块的映射关系更新时,正向映射也应该相应的更新,但是闪存不支持这种就地更新正向映射,其过程,如图1所示:

正向映射并不是必须的,系统可以通过线性查询反向映射找到逻辑块号对应的物理块,这样的查询速度慢,但是节省闪存控制器中的内存空间。如果把一个逻辑块仅仅映射到一个集合的物理块中,这样可以提高查询速度【Assar et al.1995a; 1995b】。这种技术类似于缓存中的组相联映射,减少了内存占用,提高了查询速度,但是减少了映射的灵活度,可能会导致损耗平衡问题。
闪存转换层是一种将正向映射保存在闪存内存中,减少闪存中的映射更新。这个技术是Ban发明的【Ban 1995】,并且在后来被PCMCIA标准采用。
Ban后来发明了基于NAND闪存的闪存转换层NFTL【Ban 1999】,主要思想是,将一个逻辑块号映射成一个逻辑擦除单元和擦除单元中的块号,每个逻辑擦除单元对应一个物理擦除单元链,比如,查找逻辑擦除单元7的第5块,系统就顺着这个链,找到相应的物理块,将其返回,这个有效块的之前的擦除单元中的第五块都无效,之后的擦除单元中的块仍旧可用(所有位全是“1”)。如果修改这个第5块,则找出链中的下一个擦除单元的第5块,将数据更新到新块中,如果链中没有可用的第5块,则寻找新的物理擦除单元加入链中。当回收空间时,系统会将所有有效数据块写入链的最后一个擦除单元中,最后一个擦除单元作为新的链头,所有旧链中的其它擦除单元都被擦除,链的长度一般是 1或更长。
逻辑擦除单元与物理擦除单元链的映射关系,保存在一个物理擦除单元头部,在闪存设备初始化时,在闪存控制器的内存中构造相应的正向映射,因为是擦除单元之间的映射,而不是块之间的映射,所以这个映射占用的空间很少。
也可以将变长的逻辑块映射到闪存中,Wells at al.发明了这项技术【Wells at al.】,并且微软闪存文件系统【Torelli 1995】也采用了相似的技术,主要思想是,在一个擦除单元内,将变长的数据块从低地址存放,定长的头部信息从高地址存放。每个头指向相应的变长的块,微软闪存文件系统就是这样的系统。
Smith和Garvin发明了一个类似的系统,但是粒度更粗,他们将每个擦除单元分为3部分:头部、分配映射表和多个固定大小的块。系统将一个逻辑块分配到多个连续的物理块中,这些连续分配的物理块称作extent,并在分配映射表中有一个表项,这个表项中的信息包括 extent的地址信息、长度和逻辑块号等。当extent中的块需要修改时,一个extent就被分裂成两个或3个extent,将原来的映射表中的extent表项标记无效,并添加新的extent表项。
2 擦除单元回收
随着时间的推移,闪存设备上的过时块越来越多而空闲块越来越少,为了空间利用,过时块必须被回收,回收块的唯一方式就是擦除整个擦除单元。回收总是针对整个擦除单元来说的。
回收发生在系统空闲时或当空闲块数量低于一个预先设定的阈值时。
系统回收空间有几个阶段:
首先,一个或多个擦除单元被选为将要回收的单元。
然后,将这些擦除单元中的有效数据块复制到设备中别的空闲块中。
再次,修改迁移数据的逻辑块和物理块的映射关系。
最后,回收的擦除单元被擦除,并将这些回收的块加入到空闲块池中。
回收时需要将回收单元中的有效数据块复制出来,所以系统中一般都会预留一部分空闲擦除单元来满足擦除时的这种要求。
回收机制有两个主要策略:选择哪些单元回收?将这些单元中的有效数据块迁移到哪里?这两个策略又依赖于一个策略,就是在块更新时,如何分配物理块给新的数据块?这3个相关的策略以3种方式影响系统。它们影响回收进程的效率(以过时块占回收单元的比例为衡量),它们影响损耗平衡,它们影响映射关系的数据结构的相应更新。
损耗平衡的目标和回收效率往往是相悖的,例如一个擦除单元中仅仅包含静态数据(很长时间不被更新的数据),从回收效率的角度来说,不会选择回收这样的单元,因为这样的单元不能释放更多有效的多余空间,但是,这样的回收有利于整个设备的损耗平衡。假设我们知道一些数据属于静态数据,即一段时间内不会修改的数据,则我们将这些数据迁移到已经擦除次数较多的块上,这样我们就可以减少这些单元的劳损。
很显然,回收时机往往发生在设备中没有足够空闲空间的时候,这种策略称作及时回收,但是,有些系统的回收时机发生在系统空闲时,这种策略称作后台回收。后台自动回收需要整个系统的支持,有的系统可以识别空闲时期,有的系统则不能。闪存的特性也很重要,当擦除速度很慢时,就应该避免及时回收否则影响数据块更新的时间,当擦除速度很快时,这种影响就不是那么明显。同样,当擦除允许被中断并能从中断中恢复,那么后台回收就不太影响数据块的更新,而当擦除不允许中断时,后台回收就会很影响数据块的更新。但是,所有这些问题都与算法和数据结构有互相交错的影响。
2.1 损耗平衡为中心的回收和测量损耗的技术
这里描述的回收技术的主要设计是以减少损耗为中心的,这些技术在系统中用独立的有效回收机制和损耗平衡策略。系统中在大部分时间使用效率为中心的回收策略,但在一些时候转换为损耗平衡为中心的回收策略。有些时候不均衡的损耗引发转换,有些时候周期性的发生转换。很多技术用于测量损耗情况,接下来,介绍损耗测量技术。
Lofgren et al.发明了一种由回收擦除单元触发的损耗平衡技术【Lofgren et al.2000; 2003】。在这个技术中,每个擦除单元头部保存一个擦除计数。首先,系统中预留一个备用的擦除单元,当最劳损的擦除单元被回收时,计算最劳损的擦除单元与最不劳损的擦除单元的擦出计数的差,如果这个差超过一个阈值,比如15,000,则负载平衡回收策略被采用,将最不劳损的单元中的有效块数据迁移到备用擦除单元中,擦除这个最不劳损单元,然后将最劳损单元中的有效数据块迁移的刚刚擦除的那个最不劳损单元中,再擦除那个最劳损单元,并将其置为备用单元。这个技术试图去识别最劳损单元和静态数据块,将静态数据块迁移到最劳损单元。而在下一个周期的损耗平衡中,最劳损块将保存最不劳损块中的数据。据推测,最不劳损单元中的数据相对静态,将这些数据块保存到最劳损单元中来平衡劳损单元的损耗,同时,将静态数据从最不劳损单元中迁移,提高了整个设备中的每个单元的损耗更加均匀。
很显然,这种技术依赖于擦除单元头部的擦除计数,如果一个擦除操作正在进行,新的擦除计数没有写入擦除单元头部时掉电,这个单元的擦除计数就会丢失,这种危险相当严重,尤其是当擦除速度比较慢时。
一种解决这个问题的方法是将擦除单元的计数保存到别的擦除单元中,比如单元i的计数保存到单元j中( )。Marshall和Manning就发明了这样一种技术【Marshall and Manning 1998】。系统中每个擦除单元保存头部保存一个擦除计数,在回收单元i之前,将i的计数复制到一个任意块j的一个特殊区域中( ),那么在回收中丢失单元i的计数,就直接可以从单元j中恢复。
Assar et al.发明了一种更简单但是稍微低效的方法【Assar et al.1996】,将一个擦除单元的边界为8的8位二进制数,保存在别的擦除单元中,比如单元i的擦除计数保存在单元j中( ),当单元i被擦除时,就将单元j中的一位二进制位擦除(“1”置为“0”),这样,单元i可以被擦除多次,擦除计数会相应地更新。但是,因为计数的边界是8位,当擦除次数多于8次后,这个擦除计数就不准确了。这种系统中,需要周期性的损耗平衡机制来会回滚所有的擦除计数。
Jou和Jeppesen也发明了一种的擦除计数技术【Jou and Jeppesen 1996】。他们系统中使用了称为“写前擦除”策略:将回收的擦除单元的有效内容复制到别的单元中,但是这个单元不会被立即擦除,而是将其标记为候选擦除单元,并加入到闪存内存中的候选擦除单元的优先级队列中,以损耗计数来排序,损耗计数最小的单元先被擦除为可用单元。这种技术在一定程度上平衡了损耗,因为延迟了一些损耗严重的单元被擦除,损耗的均衡与否取决于优先级队列中候选擦除单元的多少:如果候选擦除队列比较短,损耗严重的块就可能不会被延迟很久被擦除。
Han发明了这个问题的另外一种解决方法【Han 2000】。依赖擦除延迟来预估损耗情况,一些闪存设备中,随着损耗的增加擦除延迟也相应增加,Han的技术通过擦除所用时间来判断损耗情况,并将这些损耗情况排序,这避免了保存擦除计数。损耗情况排序可用于分配策略等,但是系统仅仅预估一段时间的擦除单元的损耗状况,对于那些一段时间内仅有少数单元被擦除的情况,就没有办法很好地使整个设备的损耗平衡。
另一种损耗平衡的方法依赖于随机性而不是预估块的损耗情况。Woodhouse提出了一个简单的随机的损耗平衡技术【Woodhouse 2001】。每100次回收,系统会随机选择一个仅有有效数据的单元回收,这样就会将静态数据从所在的损耗小的单元迁移到损耗大的单元中,如果这个技术应用在一个倾向于回收效率而不是损耗平衡的系统中的话,极端的损耗不平衡仍旧存在,如果回收单元时仅仅根据其中的无效块的数量,那么一些仅有少量无效块的单元可能永远得不到回收。
大约在同一时间,Ban发明了一个更加健壮的技术【Ban 2004】。他的这个技术依赖于一个备用单元。每一个确定的回收次数中,一个擦除单元被随机选中,将选中的擦除单元中的有效数据块复制到备用单元中,选中的擦除单元擦除后就标记为新的备用单元,这种损耗平衡事件的触发可以是确定的,比如每1000次擦除引发一次,或者随机的。随机的触发损耗平衡可能会仅仅几次擦除就产生一次。这个技术的目的是使闪存中的生命周期中的每个擦除单元有公平的互换,大量的互换可以减少一个擦除单元长时间地存储静态数据。另外,这个技术中的损耗平衡开销是可预见的并均匀的。
这个技术的思想在更早的软件中已经使用,M-Sytems公司的TrueFFS,使用了结合擦除次数和随机性的损耗平衡技术,M-Sytems公司的描述中说,随机性的使用消除了保护每个擦除单元的确切擦除计数的必要。
2.2 结合有效回收和损耗平衡技术
Kawaguchi,Nishioka和Motoda发明了一个这样的技术【Kawaguchi et al.1995】。他们实现了一个闪存设备的块设备驱动程序,这个驱动程序被用于日志结构文件系统。这个文件系统操作更像一个块映射机制:它负责分配块并回收擦除单元。Kawaguchi et al.描述了两种回收策略。第一个策略是选择下一个回收单元的原则是计算回收好处与回收代价的比率,一个单元的回收好处是这个单元中无效块的个数,回收代价是将这个单元中有效块复制到别的单元中的代价。一个单元距上次修改的时间也是其中的参数,即时间越长单元中的有效数据就越像静态数据,这个时间越长就越容易被回收。而这个技术避免了回收好处与回收代价比率增长时回收,因为这时擦除单元距上次修改的时间比较短。这个技术没有专门为损耗平衡设计,但是也达到了损耗平衡的结果,因为即使少量无效块的擦除单元,随着时间的推移,终将被回收。
Kawaguchi et al.发现这个策略在某些情况下仍旧低效率,于是提出了另外一个策略,他们提出将数据分成两种单元,一种单元中存放“冷”数据,即在回收擦除单元中的不经常修改的数据,另一种单元存放“热”数据,通常不在回收过程中动态写入的数据。这种方式可以提高回收效率,因为动态的数据存放在一起,回收的时候可以将这个单元回收,而只迁移少量有效数据。存放静态数据的单元不需要回收,因为它上面没有无效数据块。显然,这样的静态数据单元很长时间不会得到回收,这会导致损耗平衡问题,除非采用别的损耗平衡策略。
Wu和Zwaenepoel描述了一个更缜密的策略【Wu and Zwaenepoel】。系统将擦除单元分为固定大小的区域,假设小号的区域存储“热”逻辑块,大号的区域存储“冷”逻辑块,每个区域都有一个活跃的擦除单元存放最近更新的数据块,当一个虚拟块被更新,新的数据就写入当前区域的活跃单元的一个相应的物理块中,当一个区域中的那个活跃单元被写满,系统选择这个区域中有效块最少的单元回收,假如擦除单元分为前部和后部,在回收时,这个单元中的有效数据被复制到一个空单元的前部,这样,不经常更新的块就被保存到擦除单元的前部,即“冷”块,而新更新的块就保存到擦除单元的后部,也就是相对“热”块,Wu和Zwaenepoel就是这样区分冷热块的,其冷热区如图2所示:
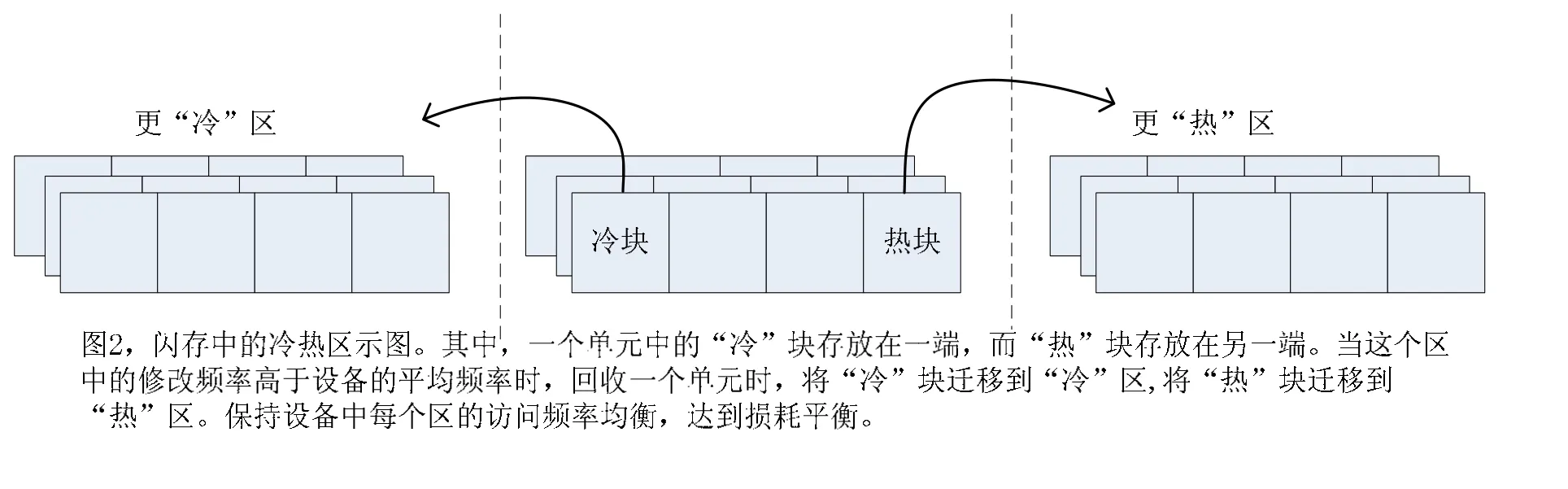
对于每个区域,系统试图去获得均衡的回收频率,然而,热区域应该比冷区域有更少的块,因为热数据无效的速度更快。在每次回收时,系统会将当前区域的回收频率与区域的平均频率作比较。如果,当前区域的回收频率比平均频率高,就将区域中的一些块迁移到临近的区域中,擦除单元中的前部,即冷块迁移到冷区域中,擦除单元的后部,即热块被迁移到热区域中。
Wu和Zwaenepoel实现了简单形式的损耗平衡,当最劳损的单元比最不劳损的单元擦除计数高100时,交换这两个单元的数据。当最不劳损的擦除单元保存的是静态数据时,这是很有效的,这种交换会使劳损的单元休息下来。
Wells发明了一种依赖于有效回收和损耗平衡的回收策略【Well 1994】。系统选择下一个回收单元是基于一个分数,单元j的分数的定义如下:

其中,无效块(j)是指擦除单元 j中的无效数据块的总数,擦除数(j)是指擦除单元j的擦除次数,最大分数的块将是下一个回收的块,无效块(j)和擦除数(j)可以从每个擦除单元中获得,0.8和0.2是发明中的数据,可以根据具体情况调整。总的原则是,回收有效性权重,而损耗平衡权轻。在足够多的单元回收后,系统会检查是否需要更激进的损耗平衡策略。如果最劳损和最不劳损的擦除次数相差超过 500或更多,系统将用另外一个分数公式来计算回收策略。
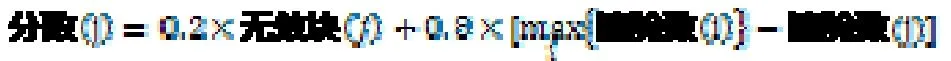
这种策略,先是考虑到回收效率,如果导致损耗不均衡,则进入损耗平衡阶段,在这个阶段回收效率不是那么重要。再者,没有必要过早进入损耗平衡阶段,因为那样反而会增加系统整体的损耗。
Chiang,Lee和Chang提出了一个称作CAT的块集群技术【Chiang et al.1999】,Chiang和Chang后来改进这个技术为DAC【Chiang and Chang 1999】。这些思想的中心概念是“温度”,一个块的温度表明这个块是否将要被更新。系统基于两个简单规则来为每个块维护温度:一个是当一个块被更新时,温度升高,另一个是,随着时间的增长块的温度降低。CAT将块分为三类:只读、冷和热。这种分类没必要必须与温度一致,因为在CAT中,块仅仅在回收的时候重新分类,每个擦除单元存储一类块,当擦除单元要回收时,擦除单元上的有效块被重新分类,CAT选择一下公式计算分数最高的回收单元。

其中,有效块(j)是擦除单元j中的有效数据块的个数,年龄(j)是从上次更新为止的时间,从这个分数公式可以看出,系统会优先选择无效块多而有效数据块少的单元、不是最近更新的单元和擦除次数少的单元。这一定程度上结合了有效性和损耗平衡。CAT策略还包括额外的损耗平衡机制:当一个擦除单元将要达到它的擦除上限时,会将其与擦除次数最少的擦除单元交换数据。
DAC策略则更加复杂。首先,块被分为3个以上的分类,更重要的是,块在每次更新时重新分类,所以冷块升温后将被重新分配到一个更热的擦除单元中,即使这个冷块所在的单元没有回收时。
TrueFFS选择回收单元是基于无效数据个数、擦除次数和静态数据的识别【Dan and Williams 1997】。TrueFFS还试图将相关的块放在一起,这样一个擦除单元中的块就可能同时无效,做法是将连续编号的逻辑块存放在一个擦除单元中,这种做法基于的假设是,上层软件将相关的块是有连续的逻辑编号。
Kim和Lee提出一个自适应的结合损耗平衡和回收有效性的技术【Kim and Lee 2002】。他们的方法是设计一个文件系统,而不是一个块映射机制,但是因为它也适应于块映射机制。这个方法称作CICL,选择一个擦除单元(事实上是一个称为段的一组擦除单元)回收,回收依据为一下公式的最小分数。

在这个表达式中,λ不是一个常量,而是依赖于更加最劳损和最不劳损擦除单元的差值。
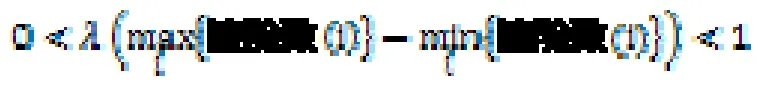
当λ小的时候,单元回收主要考虑擦除效率,而λ大的时候则以损耗平衡为主。当λ增加时,损耗平衡问题越来越严重,这时候这个公式就会将重点转向损耗平衡,而损耗均衡时则以擦除效率为主。
3 SSD在分层存储中的应用
SSD闪存具有较高的IO性能并且耗电量小等优点,但是SSD盘的单位价格仍旧太高,纯的SSD盘性价比比较低,而利用SSD的高性能和SATA盘的低价格组合的分层存储已经成为业内的更好的选择,很多大型数据中心已经开始研究如何使用SSD与SATA结合来提供更高的性价比,比如IBM数据中心等,SSD做为分层存储有两种方案,一种是将SSD与磁盘并行,另一种是将SSD作为磁盘的缓存,如图3所示:

图3 SSD分层存储结构图
3.1 FlashCache
FlashCache是一个为innoDB设计的块cache应用,也可以用于一般的应用。FlashCache是基于 linux设备映射(Device Mapper)框架,将SSD和SATA盘虚拟成一个独立的块设备的软件,利用SSD的高性能和SATA盘的高容量来提升整体的性价比。
FlashCache是将cache部分(SSD)分成逻辑的集合,然后将数据块通过 hash运算到相应的集合中,其中,块大小、集合大小以及cache大小是在创建时配置的参数,默认的集合大小为512块,这样,集合个数就时cache大小除以集合大小。其中,dbn(disk block number)即磁盘块号,也就是磁盘的逻辑块号,FlashCache使用以下的hash公式,将相应的磁盘块映射到相应的集合中。
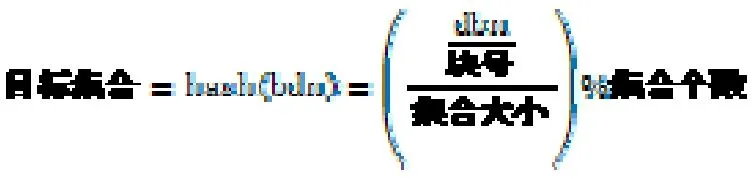
所以,每个块一定会映射到相应的集合上,根据块号就能从相应的目标集合中就能线性探相应的块。设备映射层会将 IO组合成固定块大小,然后将块存放在 cache上,FlashCache缓存所有的块级别的 IO,在每个集合中替换算法选择是FIFO或者LRU,可以通过sysctl进行算法切换。
对于每个逻辑块来说,都有一个逻辑块头,逻辑块头中包括逻辑块号(dbn)、闪存状态(Dirty/Valid/Invalid)、用于LRU算法的静态指针和校验和信息。校验和信息主要保证块信息的正确性,也可以不设置校验和。
所有的逻辑头,即逻辑块的元数据,可以拼接成物理块,存放在SSD中。
逻辑头所占用的空间开销,例如300GB 的SSD cache用16KB固定块大小,大约2千万个cache块,元数据占用480MB,如果是300GB SSD用4KB的块大小,元数据就占用1.8GB空间,如图4所示:

图4 SSD写回架构
读过程,首先,通过hash计算找出dbn所在的SSD中的目标集合,然后从相应的目标集合中线性找到dbn,如果命中则返回数据,否则从磁盘中读数据返回,然后将数据块替换到相应的集合中。
写过程,FlashCache的写过程使用写回策略,即所有的写操作都将数据写入flash中,并将写入的数据标记成脏块。(如果写入的数据已经是脏块,则不需要重新标记。)每个集合中的脏块百分比有个阈值,当脏块的比例超过这个阈值时,就被设置成将要写回磁盘,对于脏块的选择,使用一个类似时钟算法选择空闲的脏块写回。
读写过程中,尽量少写回元数据,避免不必要的损耗,比如读数据时,就不需要写回。
替换策略选择FIFO先进先出算法或LRU最近最久未使用算法,具体LRU算法的实现是使用静态双向链表,链表表头表示最近被访问的块,而链表表尾则表示最久未访问块,当一个块被访问时,被访问块就被更新为新表头。
4 结束语
SSD已经广泛应用于计算机、手机、摄像机以及工作站等,SSD为这些设备提供了高速可靠的存储,随着 SSD技术的不断提高、大规模的生产,SSD的价格也越来越低,性价比逐年攀升。
这篇文章的目的就是总结已发明的SSD闪存技术,希望能对新的SSD闪存技术的研究和开发提供更好的参考。
[1]Assar,M.,Nemazie,S.,and Estakhri,P.1995a.Flash memory mass storage architecture.US patent 5,388,083.Filed March 26,1993; Issued February 7,1995; Assigned to Cirrus Logic.
[2]Assar,M.,Nemazie,S.,and Estakhri,P.1995b.Flash memory mass storage architecture incorporation wear leveling technique.US patent 5,479,638.Filed March 26,1993; IssuedDecember 26,1995; Assigned to Cirrus Logic.
[3]Assar,M.,Nemazie,S.,and Estakhri,P.1996.Flash memory mass storage architecture incorporation wear leveling technique without using CAM cells.US patent 5,485,595.Filed October 4,1993; Issued January 16,1996; Assigned to Cirrus Logic.
[4]Ban,A.1995.Flash file system.US patent 5,404,485.Filed March 8,1993; Issued April 4,1995; Assigned to M-Systems.
[5]Ban,A.1999.Flash file system optimized for page-mode flash technologies.US patent 5,937,425.Filed October 16,1997; Issued August 10,1999; Assigned toM-Systems.
[6]Ban,A.2004.Wear leveling of static areas in flash memory.US patent 6,732,221.Filed June 1,2001; Issued May 4,2004; Assigned to M-Systems.
[7]Barrett,P.L.,Quinn,S.D.,and Lipe,R.A.1995.System for updating data stored on a flash-erasable,programmable,read-only memory (FEPROM)based upon predetermined bit value of indicating pointers.US patent 5,392,427.Filed May 18,1993; Issued February 21,1995;Assigned to Microsoft.
[8]Chang,L.-P.,Kuo,T.-W.,and Lo,S.-W.2004.Real-time garbage collection for flash-memory storage systems of real-time embedded systems.ACM Transactions on Embedded Computing Systems 3,4,837–863.
猜你喜欢
数学小灵通(1-2年级)(2021年11期)2021-12-02
中等数学(2020年8期)2020-11-26
小学生学习指导(低年级)(2020年4期)2020-06-02
课程教育研究·学法教法研究(2018年27期)2018-08-11
资源节约与环保(2018年1期)2018-02-08
数学小灵通·3-4年级(2017年11期)2017-11-29
铁路技术创新(2016年4期)2016-09-10
新闻传播(2016年11期)2016-07-10
云南电力技术(2015年2期)2015-08-23
中国老年学杂志(2015年1期)2015-01-25
