
基于规则的分布式集群运算系统研究
2011-12-27 01:05张智慧
河北省科学院学报 2011年4期
张智慧
(北京信息职业技术学院,北京 100015)
基于规则的分布式集群运算系统研究
张智慧
(北京信息职业技术学院,北京 100015)
在分析分布式集群运算需求的基础上,提出了按操作构件分解、基于规则调度构建分布式集群运算服务方法,实现业务运算的按需服务,并给出了试验系统总体设计和初步验证结果。
操作构件;规则;分布式;集群
随着信息技术的快速发展,信息系统已经成为企事业单位处理日常事务、拓展业务范围和提高工作效率的重要支撑平台。核心服务尤其是实时运算服务的可靠性需求日益提升,并进一步要求系统平台提供高性能、精细化、可伸缩的保障服务。服务器集群架构是目前普遍采用的系统核心服务架构模式,用于实现分布式数据处理、集群调度及负载平衡,根据数据处理负载的增长,方便地进行服务器集群扩展。在实时数据处理上,引入基于操作构件的数据流处理技术,操作构件执行对某一类型数据处理构成基本运算,通过组合建立复杂的处理模型,基于规则设定操作构件的迁移和数据流的重构,实现在分布式集群架构上的处理调度,满足信息系统的高效实时处理和动态重组需要。作者研究了基于规则的分布式集群运算系统的设计方案,并介绍了系统验证情况。
1 基于操作构件的数据流处理技术
1.1 运算分解
典型的分布式集群运算系统是以实时数据采集为驱动,以数据的实时收集、处理、分发为主线,其核心业务是数据的融合处理与组织运用。因此,系统体系必须是以数据的融合处理为核心,以满足大规模数据处理需求为重点,具备高扩展和高可用的集群化软件架构。为了实现这样的软件技术架构,需要基于业务模型化和软件构件化的思想,针对其处理的“数据对象”和“业务功能”做进一步的技术抽象,具备业务模型化定义、分布式处理的技术条件,以满足系统的扩展性要求。
业务分解。数据处理是围绕不断变化的应用业务实际需求进行的,而实际应用业务之间本身就存在着交集。通过分析业务流程中的业务处理交集,拆分成子业务,支持子业务重新组合提供新的业务支撑,同时在新业务处理中重用。
计算和数据分解。运算分解分为计算分解和数据分解。对子业务中的计算进项拆分,找出原子算子,对独有的业务计算进行定义,便于将业务计算交由集群中的多个计算节点进行协同处理,扩展系统的计算能力。对业务中需要处理的大规模数据按照业务、地域等领域进行拆分,分散到独立的业务计算,可由多个计算节点处理完成。各处理节点相互备份,有效减少业务中断风险,为系统提供高可靠能力。
按需服务。分解后的业务运算通过提供按需服务,满足各类业务处理个性化请求,对业务应用提供快速的支持,支持业务应用的快速拓展和实时响应。
1.2 技术抽象
操作构件是按照构件化的方式实现系统功能的,具有通用的输入、输出接口和参数设置接口。以分解后的业务运算构建操作构件,数据作为操作构件的输入流进入操作构件,经过操作构件计算处理后,将结果输出至操作构件的输出流,实现面向数据流的基本运算。数据流系统中的基本运算包括选择、投影和连接等常见运算以及用户自定义的业务运算,通过数据流元祖的属性描述数据项,基于这些基本运算组合建立复杂的处理模型。基本的操作构件包括对数据进行过滤操作构件(Filter)、投影操作构件(Map)、联合操作构件(Union)和连接操作构件(Join)等,以及用户根据实际的业务需要自定义的操作构件。
以Filter操作构件为例来说明操作构件的定义和使用。Filter操作构件基于选择运算,由一系列条件表达式组成从而将输入流分成若干个分流。可以形式化描述为:
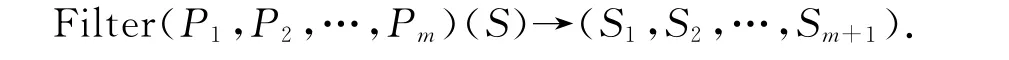
其中S表示输入流;P1、P2…Pm表示在输入流上的m个条件表达式;S1、S2…Sm+1表示输出流,Si(i=1、2…m)由所有满足条件表达式Pi(i=1、2…m)的元组组成,Sm+1输出流则由不满足所有条件表达式Pi(i=1、2…m)的元组组成,其所有的输入流和输出流数据格式都是相同的。
例如,有一条输入流和三条输出流的Filter操作构件。输入流的数据格式为位置和温度(location,temp),输出流具有同样的数据格式。定义处理过程为:当温度(temp)大于105时输出数据到输出流1;当温度大于100时,输出数据到输出流2;其他情况则输出数据到输出流3。其流程和结果如图1所示。

图1 Filter操作构件处理流程
对于自定义的操作构件,必须按照面向数据流的方式来规范输入、输出和参数设置接口,内部数据处理流程按照业务运算的规则设定。
操作构件之间通过数据流来连接,实现对数据流的复杂计算业务。如图2所示,操作构件Box1有三个输入队列、两个输出队列;操作构件Box2有一个输入队列、一个输出队列;操作构件Box3有两个输入队列、一个输出队列,三个操作构件分别通过数据流来连接。
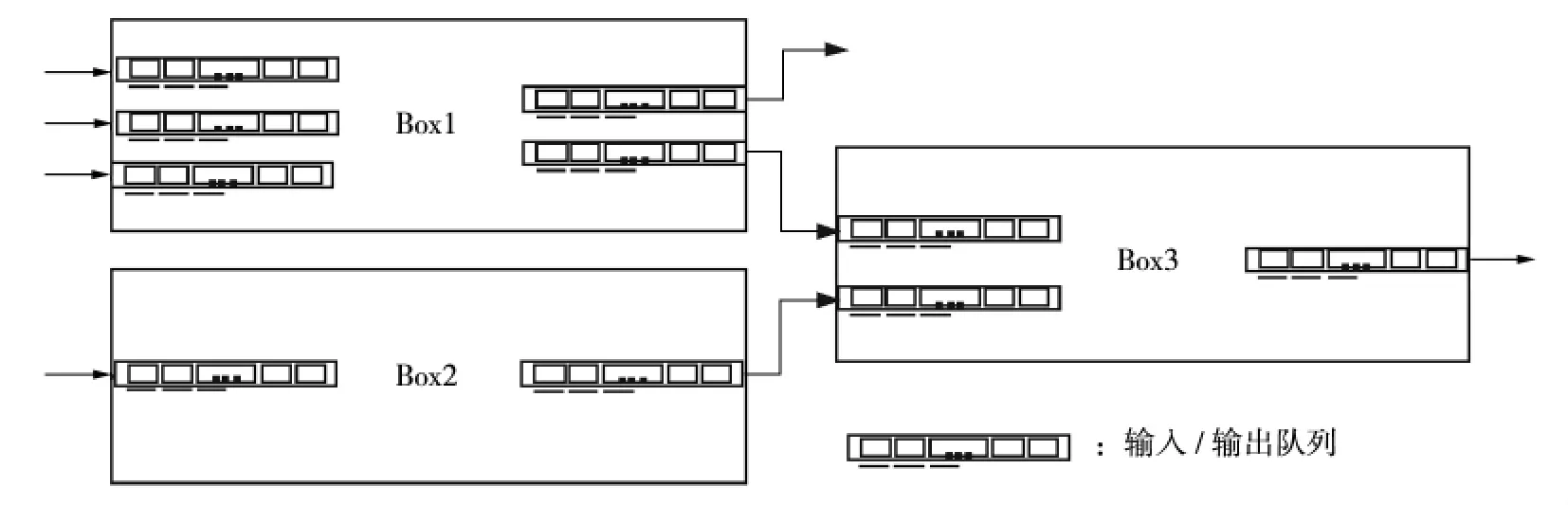
图2 操作构件连接示意图
2 基于规则的运算调度技术
现有集群调度策略,基本是工作在负载均衡或异地热备份模式,负载均衡包括负载的静态分配和动态调度;热备份模式是多台服务器并行运算,平时以其中一台为主,其他为备份运行,遇有主服务器故障自动切换到备份服务器,也可进行人工的主备份切换,进行系统维护,提供可靠、不间断运算服务。实际业务系统中集群的应用往往是在一定业务原则下的应用,既要求各类业务能够实现无缝的接替,又要求能够掌控集群运算的实时分布和迁移情况,在网络信道、安全防护策略、机房配套和维护保障要求上根据业务侧重不同采取不同措施,提高系统可用性,降低经费投入。例如,公司总部设在北京,和北京分公司、广州分公司服务器构成集群,对用户的服务以总部服务器节点为主,北京分公司节点为主备服务器,广州分公司节点备份服务器以异地数据备份为主,为广州片用户提供服务,同时作为大系统集群运算节点的次备份节点,公司核心运算和服务主要依赖总部节点和北京分公司节点,现有任务迁移策略不仅增加了集群管理的运算,而且还不能适应特殊业务集群调度需求。这就需要建立基于规则的集群运算调度策略来满足业务应用需求。
2.1 操作构件运行原理
操作构件是业务执行的核心模块。任何一个操作构件都遵循该结构和简单运行原则,即操作构件运行时从自己的输入缓冲队列中取数据,并执行计算,将输出数据通过调用输出流的相应方法放到输出流上。
在基于操作构件的数据流系统中,用户任务被描述为任务描述文件(即对任务的建模结果)。负责解析任务描述文件并执行操作构件的核心模块称为调度器。对于调度器而言,操作构件是什么类型,如Filter,Map是没有任何关系的,调度器识别的是封装了基本接口的抽象类Qbox。

2.2 任务调度机制
每台计算节点都包含一个调度器。该调度器单线程运行,并且具有系统锁。调度器包含两个队列,任务队列和需要运行的操作构件运行队列。调度器优先调度任务队列,其次是操作构件运行队列。在调度这两种队列时按照先入先出的调度原则(FIFO)。
任务队列排队查询业务拓扑图的改变控制命令。调度器将调用任务队列中的任务,如一个操作构件的增加,并执行该任务,将操作构件连接到本地业务图中。对于修改参数等相关的任务也是通过任务队列调度。
操作构件调度队列排队需要运行的操作构件。调度器不断从调度器中取需要运行的操作构件,执行操作构件相应功能。
若调度器完成所有任务,将等待事件的产生唤醒。事件包括新的拓扑修改任务和新需要运行的操作构件入队。
2.3 操作迁移步骤
操作符迁移的调度方法:全局负载管理器向源计算节点发送RPC请求,请求将指定操作移动到另一个目的计算节点。然后由源计算节点通过RPC与目的节点协商,完成具体的操作迁移过程。
(1)首先,源节点先停止指定操作符的运行,然后将这些操作符的状态序列化。创建一个包,将操作符元数据、流元数据以及操作符的状态包含其中,将整个包发送给目的计算节点。
(2)目的计算节点收到这个包之后,首先把操作符和流的元数据加入到它本地的目录中,然后根据传递过来的状态将操作符实例化,并建立与对应节点的数据连接。当这些操作符的执行得到恢复之后,目的节点向源节点发送一个请求,告诉对方可以安全删除操作符。
(3)源节点收到目的节点告知的删除消息后,将被暂停的操作符从本地删除,将更新它的本地目录。
为了避免节点间操作符迁移发生冲突,全局管理器会在调度完一对节点迁移后等待一段足够长的时间。
2.4 基于规则的负载均衡算法
管理节点的状态监控负责收集所有处理节点发送过来的负载信息,并将该信息整理映射为系统需要的数据,基于规则进行负载迁移,负载的迁移是以操作构件为单位进行的。
首先,建立操作构件状态集合Sc,考虑到用户需求在各计算节点上的侧重不同,分配权重形成带权重的状态集Scj,j=1,…,m。
设定各计算节点的优先级,Ci,i=1,…,n。
对于各项业务对应的备份或负载均衡计算节点,建立迁移规则。
迁移规则::=<规则ID,操作构件编号,状态编号,计算节点>
对同一操作构件可形成针对多个计算节点的迁移规则,按照权重进行状态迁移。
算法思路:
(1)遍历所有的操作构件,保存好当前操作构件与节点的映射关系,并按权重进行排序。
(2)依据节点的负载,找出系统中不平衡的节点对。将系统中的所有计算节点按平均负载进行排序,将第i个节点与第N-i+1个节点进行配对(即最大负载与最小负载节点配对),如果负载差值超过预定义的一个门限值,则表明这一节点对负载不平衡,将其加入到当前系统负载不平衡节点对列表中。
(3)对负载不平衡的节点中,取负载大的节点上权重最小的操作构件,并从负载不平衡节点列表中删除该节点对,如果按照规则目标计算节点中包含负载小的节点,则进行操作构件迁移,否则重复第(2)步。
在这个算法中,只允许从负载大的节点上往负载小的节点上迁移操作构件,同时需满足权重和规则约束,这样就确保重要的业务进程运行在指定的计算节点上,尽可能的将不重要的业务迁移到其它节点,实现对用户的按需定制服务。
3 系统总体设计
3.1 总体架构
以基于操作构件的数据流处理技术为基础,梳理数据处理的流程模式以及用户订阅数据的模式,将复杂的数据处理分解为基础操作单元,形成数据处理网络流图,然后由管理节点将操作单元按照规则分配到不同的服务器上组合计算,进行分布式并行处理,从而实现业务集群。集群的总体架构示意图如图3所示。
系统集群主要由集群管理、数据处理两大类节点组成。其中,数据流处理节点负责实现具体的数据处理,根据管理节点定义的任务,执行相应的处理操作,并将处理后的数据分发到下一节点;同时,还要监控自身的负载及处理时延情况。
集群管理节点负责整体的资源调度,保存用户的查询定义,可根据查询操作图对数据操作单元进行分配,并负责各个节点的负载平衡。为了解决集群中某个节点单点失效的问题,可以采用多点分发的策略,实现热备同步处理。
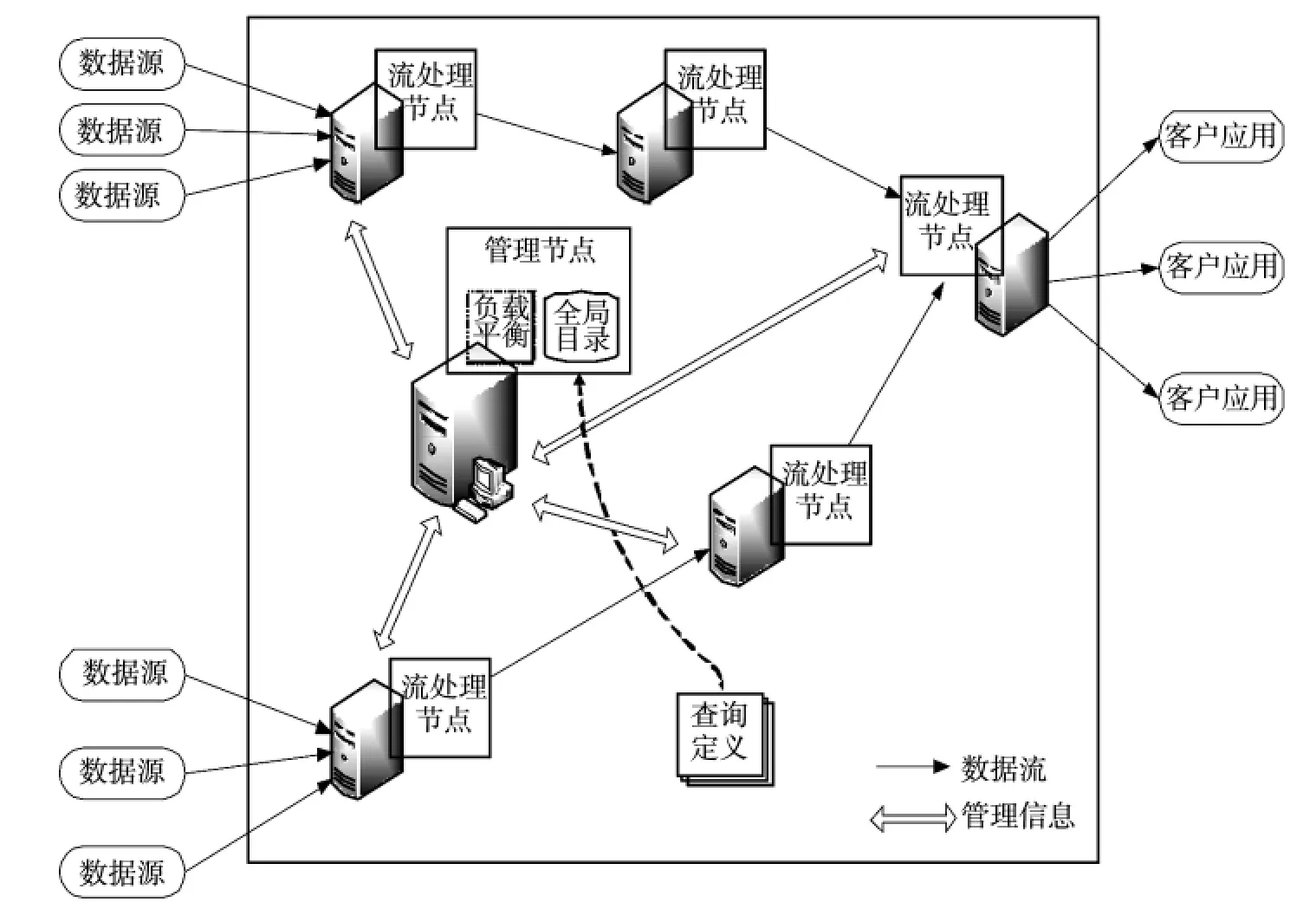
图3 集群总体架构
3.2 应用框架
现有的系统从业务需求出发,设计功能模块,最后加以实现,虽然也能完成当前业务系统的需求任务,但是给业务系统的升级带来了很大的麻烦,甚至需要重新设计软件系统的整体结构。显然,现有系统不利于业务的扩展,系统更新的周期长,成本很高。
针对现有系统的不足,结合业务能力需求,设计了高扩展性和高可用性的系统体系架构,各组件以一种松耦合的方式联系起来。系统以构件化设计思想为基础,具备良好的伸缩性和可扩展性。随着实际业务的不断变更,能够做到在保持系统整体体系架构不变的情况下,只对架构中的某些组件进行调整和扩展,来适应需求的变化。
以基于操作构件的数据流处理业务集群为基础,典型的系统应用框架如图4所示。
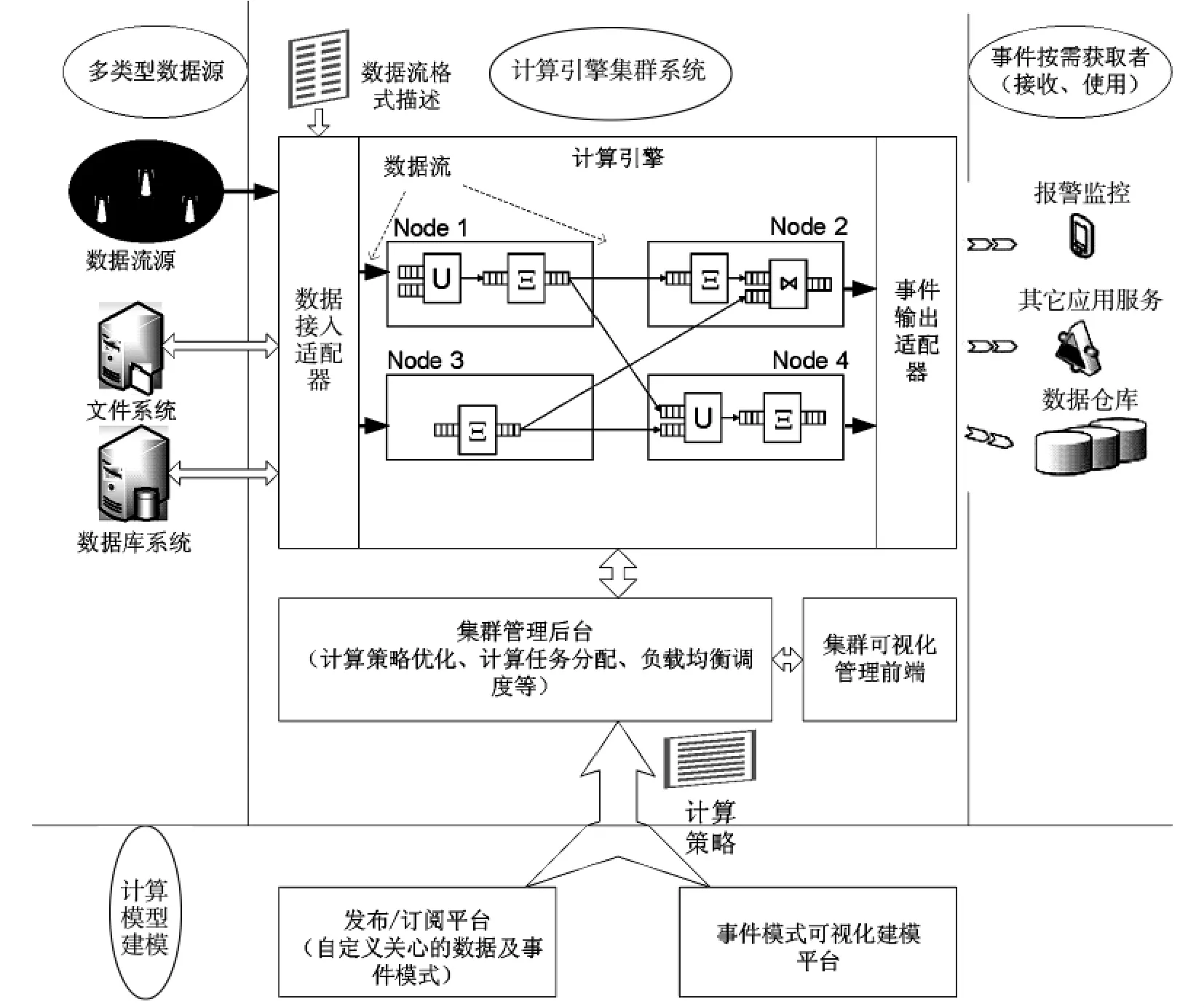
图4 系统应用框架
3.3 运行机制
系统的核心业务是数据处理,系统处理数据的获取是多源的,包括实时数据流 (如传感器)、文件系统、以及数据库系统。其中,实时数据流的处理是当前系统设计的核心和重点,其他类型的数据(如文件、数据库)可以通过开发扩展接口来实现接入并进行相应业务计算。系统的运行的基本流程和机制大致描述如下:
(1)首先基于发布/订阅平台,系统采用Web或C/S模式发布数据通告,并提供基于内容的订阅人机接口,用户根据自己想要关心的数据,定制生成查询事件。也可以直接通过事件模式的可视化平台构建查询事件,再向业务集群注册查询事件。
(2)业务集群管理后台收到查询事件请求,对业务查询进行解析拆分,形成以由流和操作构件连接而成的任务链,再将这些操作构件分配给业务集群处理节点。另一方面,任务链也可以直接通过可视化的集群管理前端构建。
(3)业务集群处理节点将收到的操作构件任务装入任务队列,根据任务调度机制执行操作任务,随着数据的到来,操作构件不断运转,数据从操作构件输入队列进入,处理完毕后从操作构件输出队列出来形成新的数据流。
(4)若操作构件输出的数据流去向为其它处理节点,这些数据便会重复(3)的操作,若去向为终端节点则直接推送给用户应用终端,此时用户便得到了所关心的数据。同时,动态的数据流也可以使用文件系统或数据库系统进行归档存储。
整个系统以数据为驱动,依据当前的业务进行数据的接收、处理和分发,业务可动态更新,具有高可扩展性和高可用性。
4 结论
在试验验证系统中,给出各操作构件的XML描述,启动管理后端,动态计算结点和数据源,不断加大一个节点的负载,扩大两节点负载差距,最终使其操作构件发生迁移,对操作构件的工作情况进行跟踪,满足预先设定的迁移规则,可以实现对用户的按需定制。
[1]杨俊秀,等.基于状态改变的集群动态负载均衡调度策略[J].华中科技大学学报,2003,31(10):238-240.
[2]王映辉,冯德民.大规模软件架构技术[M].北京:科学出版社,2003.
[3]特尼博姆等著,辛春生等译,分布式系统原理与范型(第2版)[M].北京:清华大学出版社,2008
[4]夏榆滨,软件构件技术[M].北京:清华大学出版社,2011.
Researched on rule-based distributed cluster operation
ZHANG Zhi-hui
(BeijingInformationTechnologyCollege,Beijing100015,China)
Based on the analysis of distributed cluster computing requirement,a method of cluster computing services decomposed into operating components,for rule-based scheduling in distributed cluster computing services is put forward in this paper.The system design and preliminary experimental validation results are given also.
Operating component;Rule;Distributed;Cluster
TP309
:A
1001-9383(2011)04-0001-06
2011-08-30
张智慧(1972-),女,河北临漳人,硕士,讲师,主要从事电子学与通讯的研究.
猜你喜欢
汽车维修与保养(2020年10期)2021-01-22
汽车维修与保养(2020年11期)2020-06-09
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
军事运筹与系统工程(2019年4期)2019-09-11
军营文化天地(2018年2期)2018-12-15
电子制作(2018年11期)2018-08-04
产品可靠性报告(2017年7期)2017-09-05
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
