
基于内容管理技术的档案网站信息资源整合
2011-12-27 09:20:42岳修志赵建建
中原工学院学报 2011年1期
岳修志,赵建建
(中原工学院,郑州 450007)
基于内容管理技术的档案网站信息资源整合
岳修志,赵建建
(中原工学院,郑州 450007)
基于内容管理技术,分析了档案网站信息资源整合的现状,总结出了元数据模型信息提取和存储的方法.
档案网站;内容管理;信息资源整合;元数据
随着信息技术的发展,目前大多数档案馆都实现了在B/S模式下的网上办公,通过网络环境将“有形”的纸制档案转化成网上无纸办公.档案网站提供的信息资源越来越多,种类也越来越丰富.纵观各个档案馆,电子档案往往只是纸质档案的数字化,各个档案馆只是一个信息孤岛,缺少资源共享.用户面对众多分散的网站档案信息往往无所是从,因此迫切需要整合各个网站的档案信息,以提高用户检索效率.内容管理是信息资源管理的核心部分,目前的数据库技术主要是解决结构化的信息资源的管理,而内容管理技术是解决非结构化信息资源管理的有效方法.对档案资源整合而言,内容管理技术是提高信息资源管理效率的关键环节[1].
1 内容管理技术
内容管理(Content M anagement,CM)是指对组织机构内部多种格式和媒体类型的信息资源的组织、分类、管理等有序化的过程[2].其基本思想是分离内容的管理和设计,页面美工的设计存储在模板里,而内容存储在数据库或者独立的文件中[3].内容管理能够使网站使用通用的设计元素和模板,以确保整个网站的协调.
一个内容管理系统至少要包含以下4个子系统[4]:
(1)内容收集系统:进行内容的收集、获取、分发、编辑、整合及转换等工作,并可加入元数据以支持对内容组件的定义及搜寻.
(2)管理系统:负责组件、内容及发布模板的存取管理,并可记录内容的版本、工作流程的状态、权限的设定及更新处理等.
(3)发布系统:负责将内容快速且自动地按照所建立的发布模板送至浏览器端.
(4)工作流系统:负责整个内容的收集、储存和发布.
档案网站内容管理系统属于资源型网站,其结构比较复杂,主要包含以文章发布为中心的文档资源类栏目以及图片资源、视频类、光盘类资源的发布等.
2 档案网站的信息资源整合
2.1 档案网站信息资源整合的涵义及现状分析
档案网站信息资源整合是指根据档案用户的利用需求,结合档案网站信息资源整合的特点,利用先进的技术,按照一定的原则、规范及标准,实现一定范围内的档案网站信息资源的抓取与优化,并组织成一个集关联性、动态性和实用性于一体的有机整体或者统一的利用平台[5].
目前,我国档案网站已经初具规模,但随着档案网站的增多,档案网站信息资源的充分整合是目前我们必须要解决的问题.档案网站在信息资源整合方面主要存在以下不足[6].
(1)整合层次较低.资源建设主要以馆藏为主,从而形成一个个“信息孤岛”,用户面对零落的、离散的资源,不知道如何寻找自己需要的信息.
(2)资源整合缺乏规范性.网站类目组织的一致性、检索平台的统一性需要加以规范.
(3)重资源建设,轻资源利用.在资源整合技术的选择上,只是针对资源的特点来进行堆积,片面重视资源数量,而不是从用户利用的角度来合理整合资源,缺乏导航服务和个性化服务等.
2.2 内容管理技术在信息资源整合中的优势
(1)统一了管理标准.网站内的内容格式和处理方式标准化,统一了页面的现实风格,增强了网站的扩展能力.
(2)统一了访问接口.利用XML技术能够描述各种不规则的数据,因此可以将文档等半结构化的数据纳入到同一个XML文件并传送到客户端[7].
(3)相对传统的Web网站,负载能力强.
(4)内容管理系统提供强大的二次开发平台,降低了开发难度.
(5)网页呈现和内核技术、日常发布和系统维护等完全分离,使得日常操作非常简单,降低了维护成本[8].
2.3 内容管理技术在档案网站信息资源整合中的应用
内容管理系统主要是支持异构平台上的各种类型信息的管理和访问,而信息包含结构化形式和非结构化形式的信息,如何管理这些信息成为档案网站信息资源整合的关键.结构化信息可以直接存储到关系数据库中;而对于非结构化信息如何处理,成为档案网站信息资源整合的关键.
非结构化信息一般采用元数据模型进行描述.元数据是描述一个具体的资源对象,能对这个对象进行定位、管理,并有助于资源的发现与数据的获取,是关于数据的数据[9].下面介绍内容管理的2个主要方面:元数据的提取和元数据模型的存储.
2.3.1 元数据的提取
根据元数据标准和国内图书情报领域的相关成果,依据都柏林核心元素规范,总结出档案网站元数据,如表1所示.

表1 档案网站内容管理元数据表
Web页面以 Html形式存在,我们为了收集内容,必须将Htm l源文件的 Html标记和文本区分开来,从而将文本形成2个Stream:Htm l标记Stream和文本Stream.这样Web网页内容就转换成容易处理的形式.
目前,从Web页面中提取所需要的元数据信息的方法主要有[10]:利用包装器 W rapper技术,基于层次结构的信息抽取及基于概念模型的多记录信息提取;以W 3C的文档对象模型DOM为基础,把提取的信息以DOM层次结构中的路径表达式来表示,通过归纳学习来获得所需信息的路径表达式,达到提取信息的目的.利用包装器W raaper技术工作量大,而且不便于推广.本文主要介绍以DOM为基础的元数据提取.其过程描述如下:
(1)利用DOM 提供的API分析文本信息,生成每个页面对应的DOM树型结构;
(2)提供档案网站内容管理元数据表;
(3)以元数据表和DOM树为输入,学习生成提取规则;
(4)使用提取规则提取数据,完成信息的提取.
2.3.2 元数据模型的存储
XML(Extensible Markup Language,可扩展标记语言)是由W 3C组织于1998年2月发布的一种标准.XML是自描述的、半结构化的和可扩展的标记语言.由于XML非常适合描述非结构化数据,一般元数据模型的存储都采用XML技术.
目前,XML数据管理的方式主要有文件系统方式、Native XML存储方式、关系数据库存储方式和面向对象XML数据存储方式.在内容管理系统应用上,上述4种方式各有特点,对XML的存储一般采用关系数据库存储方式.
要想将XML文档存储到关系数据库中,需要建立从XML到关系数据库的映射关系.目前,映射方法主要有3种:
(1)直接将整个XML文档数据作为关系数据库表的一个属性进行存储;
(2)基于XML结构树,将结构树中具有相同语义的父子节点用严格的二元联系模式来表示,这样能充分利用语义的直观性,确保查询的效率;
(3)假设每个XML文档都有相应的DTD与之对应,然后对D TD进行简化、分解等预处理,将D TD中的元素、属性映射成关系模式.这样,XML可以最大限度地利用底层RDBM S提供的查询处理和优化技术[11].
建立映射机制后,下一步就要完成XML到关系数据库的存储.XML标准提供了标准接口DOM、DSO来存取数据.DOM可以为不同的开发平台和开发语言提供一致的API.XML文档是按照层次结构组织起来的树形结构,所以DOM可以把XM L文件看成树形结构,文件中的每一部分数据信息相当于树节点.采用树形结构,方便了 XML文档的增加、删除、修改、查询等操作.DSO技术可以完成H tm l标记同XM L节点数据的绑定,以方便从XML文档中读取或者写入数据.XML数据存取机制如图1所示.
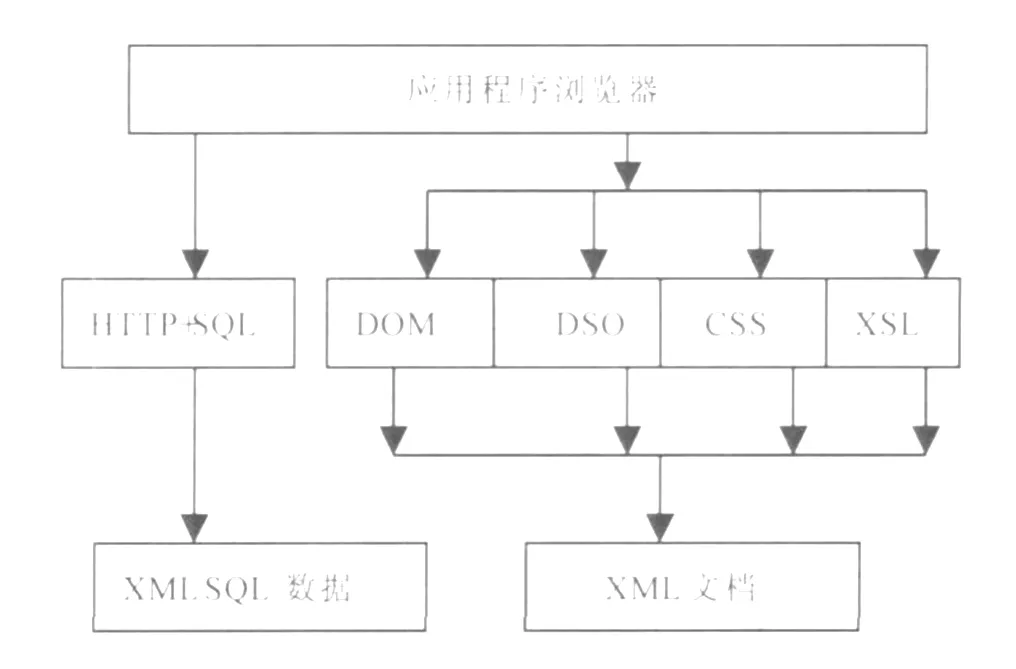
图1 XML数据存取机制
3 结 语
档案网站信息资源整合的难点是异构平台及非结构化数据的整合问题,整合的目的就是将各种不同类型的信息资源,利用内容管理技术,通过元数据模型或者提供中间件的方式整合成相联系的统一平台,便于用户检索,提高档案网站的交互性,更好地满足用户的需求.
[1]王芳,郭英.电子政务内容管理及其应用分析[J].理论与探索,2009(6):47-50.
[2]孔佳.内容管理系统的产生与发展[J].农业网络信息,2008(3):89-92.
[3]宫生文,穆江波.基于ASP.NET 2.0的内容管理系统的设计与实现[J].科技信息,2009(1):487-488.
[4]徐小静.基于XML的内容管理与内容发布技术系统的研究[D].武汉:武汉理工大学,2005:22-23.
[5]吴建华,方燕平.档案网站信息资源及其整合概念的界定——“档案网站信息资源普查与整合研究”系列论文之一[J].档案学通讯,2009(5):52-55.
[6]杭珊,吴建华.档案网站信息资源整合现状及分析[J].学术园地,2009(9):15-19.
[7]向培素,黄勤珍.内容管理系统中统一访问接口的实现[J].中国测试技术,2003,9(5):61-63.
[8]陈晓慧.基于内容管理的网站自动化生成系统的开发与实现[J].计算机科学,2005,2(32):106-108
[9]姜波.基于XML的企业内容管理系统的研究[D].武汉:武汉理工大学,2009:24-26.
[10]刘政怡.基于DOM和元数据的Web信息提取[J].计算机与现代化,2003(10):106-108.
[11]崔清华.XML文档在关系数据库中的存储研究[J].微计算机信息,2007,4(23):184-186.
Information Resources Integration of ArchivesWeb Site Based on Content Management Technology
YUE Xiu-zhi,ZHAO Jian-jian
(Zhongyuan University of Technology,Zhengzhou 450007,China)
Information resources integration is the core issue of archives Web site information.Based on content management technology,the statusof information resources integration are analyzed,and information extraction and storage methods of metadata model are summed up.
archives Web site;content management;integration of information resources;metadata
G270.7
A
10.3969/j.issn.1671-6906.2011.01.010
1671-6906(2011)01-0039-03
2011-01-08
河南省档案局科技项目(2010-X-43)
岳修志(1972-),男,河南获嘉人,副研究馆员.
猜你喜欢
山东冶金(2022年2期)2022-08-08 01:51:30
快乐学习报·教师周刊(2022年10期)2022-04-21 21:34:31
河北理科教学研究(2021年4期)2021-04-19 13:34:44
内蒙古教育(2021年14期)2021-02-12 02:40:32
计算机教育(2020年5期)2020-07-24 08:53:00
中国外汇(2019年19期)2019-11-26 00:57:32
中国交通信息化(2018年2期)2018-06-06 05:54:54
计算机工程(2015年8期)2015-07-03 12:20:35
河北大学学报(自然科学版)(2015年1期)2015-02-27 13:06:13
华东理工大学学报(自然科学版)(2014年5期)2014-02-27 13:49:32
