
基于本体的多专业领域知识语义检索系统研究
2011-12-26 07:47刘紫玉杨国霞李学会
河北科技大学学报 2011年5期
刘紫玉,杨国霞,李学会
(1.河北科技大学经济管理学院,河北石家庄 050018;2.河北科技大学信息科学与工程学院,河北石家庄 050018)
基于本体的多专业领域知识语义检索系统研究
刘紫玉1,杨国霞2,李学会2
(1.河北科技大学经济管理学院,河北石家庄 050018;2.河北科技大学信息科学与工程学院,河北石家庄 050018)
多专业领域是指由多个专业构成的学科领域,如高速铁路领域由工务工程、牵引供电、动车组、运营管理等专业领域构成。对于多专业领域本体的构建,可以先构建各个专业领域本体,然后根据专业领域之间的关系进行本体集成。面向多专业领域,在本体模型的基础上提出了多专业领域本体模型,并给出了多专业领域本体概念语义相似度计算模型,此模型可作为语义扩展的基础。在此基础上,设计了一个基于本体的多专业领域知识语义检索系统,并以高速铁路领域为背景对提出的语义检索系统进行实验验证,从测试结果来看,开发的语义检索系统可以获取较高的准确率和召回率。
本体;多专业领域;语义检索;高速铁路领域
本体在知识管理、人工智能、信息检索、Web服务发现等领域中扮演着越来越重要的角色。根据领域依赖程度,可以将本体分为通用本体、领域本体、任务本体和应用本体[1]。领域本体可以有效地组织领域中的知识,使知识更好地共享、重用。
对于多专业领域本体的构建,可以先构建各个专业领域本体,然后根据专业领域之间的关系进行本体集成。在本文中作以下定义:由多个专业领域构成的领域定义为“多专业领域”,如高速铁路领域;基于每个专业领域构建的本体称为“专业领域本体”,如动车组专业领域本体;由多个专业领域本体集成的统一本体称为“多专业领域本体”,如将高速铁路的动车组专业领域本体、牵引供电专业领域本体等集成后的本体称为“高速铁路多专业领域本体”。多专业领域本体构建方法本文不进行详细说明,可以参见相关作者的文章[2]。
笔者面向多专业领域,在本体模型的基础上提出了多专业领域本体模型,并给出了多专业领域本体概念语义相似度计算模型,此模型可作为语义扩展的基础。在此基础上,设计了一个基于本体的多专业领域知识语义检索系统。最后以高速铁路领域文献资料知识作为实验对象,对本文提出的语义检索系统进行实验分析,从测试结果来看,开发的语义检索原型系统可以获取较高的准确率和召回率。
1 概念语义相似度计算模型
1.1 本体模型
关于本体(Ontology)的定义有许多,目前获得较多认同的是STUDER等的解释[3]:“Ontology是对概念体系的明确的、形式化的、可共享的规范说明”。
定义1 一个完整的本体应由概念、关系、函数、公理和实例等5类基本元素构成。本体可以表示为

其中:C为概念,概念是指客观世界中任何事物的抽象描述,在本体中通常按照一定的关系形成一个层次结构;
R⊆2C×C,概念之间的关系,如“subclass-of”关系、“part-of”关系等;
F⊆Rn是一种特殊的关系,其中第n个元素cn相对于前面n-1个元素是唯一确定的,函数F可以表示为c1×c2×…×cn-1→cn;
A为概念或者概念之间的关系所满足的公理,是一些永真式;
I为领域内概念实例的集合。
1.2 领域本体模型
在实际的领域本体中,由于概念之间不仅仅存在着上下位关系,概念之间还通过其他各种关系可以连接,尤其在多专业构成的领域本体中还有许多自定义的关系,这使得概念的组织形式并不完全是一个树型结构,而是一个网状结构。因此,根据多专业领域本体的特点,在本体模型的基础上重新构建了领域本体模型。
定义2 领域本体模型是一个八元组:DO={C,P,Hc,Rs,Rud,I,F,A}。其中:DO 表示领域本体;C 表示概念(或称为类);P表示领域本体中Datatype类型属性;Hc表示类间的上下位(subclass-of)二元关系;Rs表示类间的同义(synonymy)关系;Rud表示类间的用户自定义(user-defined)关系(包括part-of关系也用自定义关系来描述),也就是类的ObjectProperty;I表示领域内概念实例的集合;F表示概念间一种特殊的关系,可以表示为c1×c2×…×cn-1→cn;A表示领域本体中概念或者概念之间的关系所满足的公理,是一些永真式。
定义3 概念C 的模型是一个九元组:C={P,Csc,Cuc,Cs,Cr,Hc,Rs,Rud,Ic}。其中:P 表示概念C 的Datatype类型属性;Csc表示概念C的子概念(subclass);Cuc表示概念C的父概念(upperclass);Cs表示概念C的同义概念(equivalentclass);Cr表示与概念C有关系的概念;这里主要指通过用户自定义关系联系起来的概念;Hc表示概念C的上下位关系;Rs表示概念C的同义(synonymy)关系;Rud表示概念C的用户自定义(user-defined)关系;Ic描述概念C 的实例。
概念之间的关系主要分为3类:1)上下位关系,用Csc,Cuc和Hc表示;2)同义关系,用Cs和Rs表示;3)用户自定义关系,用Rud表示。
1.3 概念语义相似度计算模型
1.3.1 模型组成描述
传统本体概念间相似度计算的不足在于其语义关系只考虑了层次语义关系,没有考虑语义关系中非层次关系的影响,同时对象实例对于概念的影响也没有考虑。笔者在定义3的基础上,提出了计算概念之间相似度的模型,该模型全面考虑了本体概念模型中各种元素对相似度的影响,考虑的元素主要包括属性(Datatype类型属性)、上下位语义关系、其他语义关系(自定义关系)和实例特征。
1.3.2 MD4模型概念语义相似度算法
在同一本体中,概念相似度计算首先需要检查2个概念是否同义。如果2个概念同义,那么2个概念是完全相似的,其相似度为1。
1)上下位关系语义相似度计算
在领域本体中,只考虑上下位关系时的本体模型为树型结构。计算上下位关系语义相似度时采用基于距离的概念相似度计算方法。笔者参考陈杰等人的算法,综合考虑概念距离和层次对概念相似度的影响[4],算法公式如下:
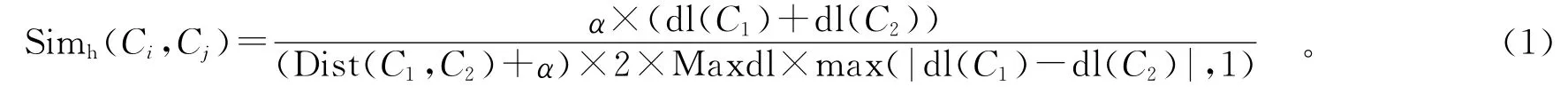
式中dl(C1)和dl(C2)分别是C1和C2所处的层次;Dist(C1,C2)是概念C1和C2之间的本体树中的最短路径;Max样dl是指本体树的最大深度,在这里除以该参数是便于计算结果的归一化处理;α是一个可调节参数,一般α≥0。
2)自定义关系语义相似度计算
假设有2个非同义概念Ci和Cj,根据定义3中的概念模型表示方法,可得到概念Ci对应的p个自定义关系集Rudi和p个自定义关系对应的m个概念集Cri,概念Cj对应的q个自定义关系集Rudj和q个自定义关系对应的n个概念集Crj。这里,每个集合中不存在相同的元素。
当2个自定义关系进行比较时,如果2个关系是相同的,那么相似度为1,否则相似度为0。
自定义关系相似度计算公式如下:

其中p和q分别是概念Ci和Cj对应的自定义关系的个数。
自定义关系对应的概念之间的相似度计算使用式(1),综合相似度计算公式为
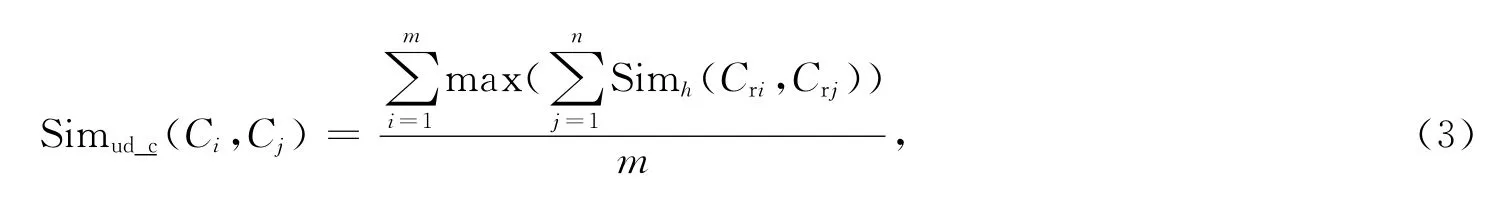
其中m是Ci的p个自定义关系对应的概念个数,n是Cj的q个自定义关系对应的概念个数。
在领域本体中,Ci和Cj通过自定义关系体现出的相似度Simud(Ci,Cj)为

其中β,γ分别表示2种相似度的权重(可简单设定β=γ=0.5),0≤β≤1,0≤γ≤1,β+γ=1。
3)概念Datatype类型属性相似度计算
当2个Datatype型的属性进行比较时,如果2个属性是相同的,那么相似度为1,否则相似度为0。首先确定Ci和Cj的属性集Pi和Pj,概念Ci和Cj分别对应m和n个Datatype类型的属性(DatatypeProperty),然后对属性集合Pi和Pj进行笛卡尔乘积Pi×Pj,得到配对集,再计算Ci和Cj的属性相似度Simp,得到Ci和Cj的属性相似度计算公式为

其中,m和n分别是概念Ci和Cj的Datatype类型属性的个数。
4)实例语义相似度计算
实例语义相似度的计算采用和概念Datatype类型属性相似度计算相同的算法。Ci和Cj的实例语义相似度计算公式为
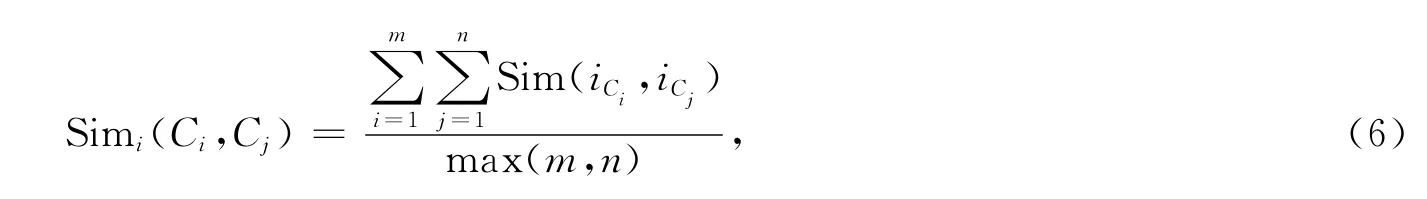
式中:m和n分别是概念Ci和Cj的实例的个数;iCi和iCj表示概念Ci和Cj的某个实例。
5)领域本体中非同义概念实际相似度计算
将上述4种相似度加权综合,得到非同义概念Ci和Cj的实际相似度计算公式为

其中ω,θ分别表示权重,0<ω<1,0<θ<1,ω+θ=1,一般ω较大。
2 语义检索系统结构
本文设计的语义检索系统[5]分为4个大的功能模块:本体查询、文献语义预处理与概念语义相似度预计算、语义扩展检索和推理检索,具体结构如图1所示。

图1 系统结构图Fig.1 Architecture of semantic retrieval system
用户界面主要和用户进行交互,系统提供4种功能:第1种是本体查询,可以查询所建本体的概念、概念属性、概念实例等;第2种是语义扩展检索,用户以关键字形式表达查询意图;第3种是推理检索,使用本体规则和公理进行推理检索;第4种是系统给用户提供对文献语义预处理与概念语义相似度预计算进行操作的界面。
本体知识库以OWL文件的形式存储领域本体知识,文献库存储进行语义标注过的领域文献知识。
2.1 本体查询
这一模块的主要功能是使用户可以方便查询本体知识库中所建本体的概念、概念属性、概念实例等。
2.2 文献语义预处理与概念语义相似度预计算
文献语义预处理与概念语义相似度预计算的主要结构如图2所示。该模块主要包括2个部分:文献语义预处理和概念语义相似度预计算。文献语义预处理主要是对文献事先进行语义标注,按照用本体库中定义好的概念对文献进行标引。语义相似度预计算事先对本体库中的概念进行语义相似度计算,根据本文的式(7)进行相似度值的计算,并在本体库中保留相似度值,方便语义扩展检索模块进行查询关键字的扩展。
文献语义标引的最终目的是获得文档的语义向量,对本体解析后可以遍历本体中的概念对一篇文档进行标引,关键是如何确定标引概念对应的权重,即这个概念相对于这篇文档的重要性。过去的研究表明,词频和位置在反映标引词和文献主题的关系上起着重要的作用,笔者采用山西大学郑家恒等人提出的非线性函数和“成对比较法”相结合的方法,综合考虑位置和词频2个因素[6],最终给出标引概念的权重。对于标引文档的概念和其对应权重,采用一维向量的形式来表示,文献的语义特征向量就由这2个一维向量来表现。
文档语义表示之后的概念向量和权重向量如下:


图2 文献语义预处理与概念语义相似度预计算结构图Fig.2 Process structure of semantic precomputation for document and the concept similarity
2.3 语义扩展检索
语义扩展检索模块的主要功能是把用户输入的查询词进行语义扩展,然后把语义扩展向量和从文献语义预处理模块中取出的标引向量进行相似度计算,计算后得到的相似度与用户设立的阈值进行比较,如果大于阈值则文献与查询相关,返回该文档查询结果,并按照相似度大小将排序后的文献列表返回给用户界面。
用户查询词经过概念语义相似度计算扩展以后,语义扩展向量可以用扩展后的概念向量(包括用户输入的查询概念词)和对应的权重向量来表现,这2个向量用一维向量的形式表示。

计算文档语义特征向量和用户查询语义扩展向量的语义相似度,本文借鉴的方法,首先计算两两概念之间的语义相似度,然后计算2个向量之间的语义相似度[7]。
对于文档语义特征向量Document(1)中的概念c1i,其对应的权重为w1i,用户查询语义扩展向量Document(2)中的概念c2j,其对应的权重为w2j。那么,对于这2个概念(c1i,c2j),其相似度计算公式如下:

其中distance(c1,c2)是c1和c2之间最短路径所包含的边的条数,用于计算c1和c2之间的距离。
最终计算2个一维向量的相似度,可以用以下的方法得到:
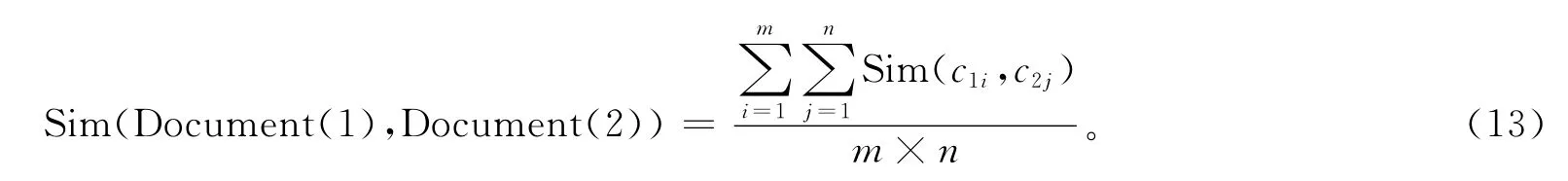
其中,m是文献语义特征向量的概念向量中概念的个数,n是用户查询语义扩展向量的概念向量中概念的个数。
2.4 推理检索
本体推理检索是在构建的本体的基础上,获得本体中隐含的知识或推理出需要的知识。推理检索的目的是回答用户问题,并检索出相关文献,按文献语义标注时的相似度排序后提交给用户[8]。推理检索模块直接使用本体中的规则和公理的语义关系进行推理检索,如利用本体中的子类公理(subClassOf)、同义(equivalentClass)等,实现了实例推理查询、实例所属类推理查询和三元组推理查询。
3 实验和结果
高速铁路领域由工务工程、牵引供电、动车组、运营管理等不同的专业领域构成,它是多专业领域的一个代表。在集成后的高速铁路多专业领域本体的基础上,以笔者提出的语义检索系统结构,开发了一个面向高速铁路文档知识的语义检索和推理系统,并对其进行了实验分析。
2个最常用的基于相关性的语义检索系统评价指标分别是准确率(precision)和召回率(recall),为了考察语义扩展检索方法的有效性,采用准确率和召回率作为评测标准。
实验目的:比较语义扩展检索方法(expand)和传统的关键字检索方法(non_expand)。
实验方法:分别用语义扩展检索方法和传统的关键字检索方法,进行10次检索,比较这2种方法的结果。结果如表1所示。

表1 不同方法的召回率和准确率Tab.1 Recall and precision of different methods
通过实验,可以看出语义扩展检索方法在准确率和召回率上要明显优于传统的关键字检索方法。所以这在一定程度上证明了语义扩展检索方法的有效性。虽然人工选择的相关集有一定的不确定性,但这个不确定性也是人机交互系统所不可完全避免的一个问题。
4 结 语
以本体为基石的语义网的出现,克服了传统检索方法的不足,为实现信息检索提供了一种全新的方法,能够大大提高检索的效率和精确度。面向多专业领域,在本体模型的基础上提出了多专业领域本体模型,并给出了多专业领域本体概念语义相似度计算模型,此方法作为语义扩展的基础。在此基础上设计了一个基于本体的多专业领域知识语义检索系统,该系统包括4部分:本体查询、语义扩展检索、推理检索和用户界面。最后以高速铁路领域文献资料知识作为实验对象,对本文提出的语义检索系统进行实验分析,从测试结果来看,开发的语义检索原型系统可以获取较高的准确率和召回率。
[1] 金 芝.知识工程中的本体论研究[A].世纪之交的知识工程与知识科学[C].北京:清华大学出版社,2001.447-465.
[2] 刘紫玉,黄 磊.高速铁路领域本体构建方法研究[J].情报学报(Journal of the China Society for Scientific and Technical Information),2009,28(2):195-200.
[3] STUDER R,BENJAMINS V R,FENSEL D.Knowledge engineering:Principles and methods[J].Data and Knowledge Engineering,1998,25(1/2):161-197.
[4] 陈 杰,蒋祖华.领域本体的概念相似度计算[J].计算机工程与应用(Computer Engineering and Applications),2006,42(33):163-166.
[5] 孔田野,李万龙,张海鸥.基于药品本体的信息检索系统研究[J].河北科技大学学报(Journal of Hebei University of Science and Technology),2008,29(3):223-226.
[6] 郑家恒,卢娇丽.关键词抽取方法的研究[J].计算机工程(Computer Engineering),2005,31(18):194-196.
[7] WU Jiang-ning,YANG Guang-fei.An ontology-based method for project and domain expert matching[A].FSKD(2)[C].[S.l.]:[s.n.],2005.176-185.
[8] 董 慧,余传明,徐国虎,等.基于本体的数字图书馆检索模型研究——历史领域知识推理机制[J].情报学报(Journal of the China Society for Scientific and Technical Information),2006,25(6):666-678.
Research in semantic retrieval system for knowledge of multiple majors domain based on ontology
LIU Zi-yu1,YANG Guo-xia2,LI Xue-hui2
(1.College of Economics and Management,Hebei University of Science and Technology,Shijiazhuang Hebei 050018,China;2.College of Information Science and Engineering,Hebei University of Science and Technology,Shijiazhuang Hebei 050018,China)
In this paper a domain including different major fields is called multiple majors domain.For example,the high-speed railway domain consists of maintenance engineering,traction power supply,EMU and operation management,etc.Ontologies of the major fields are built based on thesaurus and thematic words,and these ontologies are integreted into a unified ontology for the multiple majors domain.Oriented to the domain that consisting of several major fields,this paper gives the ontology model for multiple majors domain,and also builds the model to compute semantic similarity between concepts for multiple major domain.Then,this paper puts out a semantic retrieval system for the knowledge of multiple major domain based on ontology and verifies it.The experimental results show that the developed semantic retrieval system can reach satisfying recall and precision.
ontology;multiple majors domain;semantic retrieval;high-speed railwaydomain
TP311
A
1008-1542(2011)05-0471-06
2011-03-05;
2011-09-12;责任编辑:李 穆
河北省科技支撑计划项目(11213504D);河北省教育厅科学技术研究项目(Z2011275);河北科技大学博士科研基金资助项目(QD201017)
刘紫玉(1975-),女,河北赵县人,讲师,博士,主要从事知识管理、本体等方面的研究。
猜你喜欢
信号处理(2018年1期)2018-09-03
信号处理(2018年5期)2018-06-28
信号处理(2018年4期)2018-06-27
信号处理(2018年3期)2018-06-27
制造业自动化(2017年2期)2017-03-20
专利代理(2016年1期)2016-05-17
文学教育(2016年27期)2016-02-28
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
质量与标准化(2010年5期)2010-05-03
