
声调格局与元音格局的研究综述
2011-12-05 07:09:20梁磊
当代外语研究 2011年5期
梁 磊
(南开大学,天津,300071)
语音格局一般分为元音格局、辅音格局、语调格局等。汉语等声调语言还会有声调格局。汉语的语音格局研究以声调格局的分析为开端。以T值计算为代表的声调格局研究已经广泛被学界采用。最近几年,我们又相继提出了二维、三维元音格局的研究范式并有所应用,取得了一定的成果。
1. 声调格局
1.1 声调T值的计算及声调格局图
声调格局指由一种语言(或方言)中全部单字调所构成的格局,而广义的声调格局则应该包括两字组及多字组连读的声调表现,相对于单字调的静态研究,那就成为声调的动态分析。单字调的声调格局是静态的分析,是声调研究的基础形式,是考察各种声调变化的起始点。
利用语音实验取得某位操一种语言(或方言)的发音人的全部单字调的测量数据,例如每个声调取9个测量点。分别对各测量点上的数据分组计算,每个测量点得出一个平均值,然后采用T值公式进行数据的归一化和相对化分析(石锋1986)。公式如下:T=[(lg x-lg min)/(lg max-lg min)]×5。其中max为该发音人各点平均值中的最大值,即调域上限;min为最小值,既调域下限;x表示表示任一测量点的平均值。取常用对数的目的是使音高的赫兹单位接近人耳的听觉特性。乘以5是为了使实验数据跟传统的五度值记调法相对应。实际上T值公式把不同发音人各自不同的调域进行了归一处理,得出的是某个测量点在该发音人整个调域中的相对位置,这就实现了音高数据的相对化。计算中也可以采用简化的公式(石锋、廖荣蓉1994:114):T=[(x-min)/(max-min)]×5。
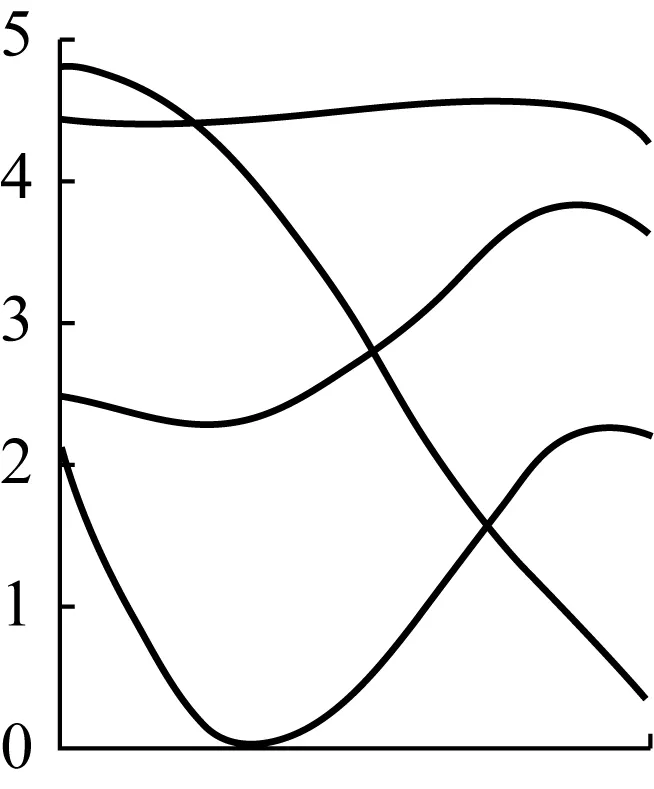
图1 北京话单字音声调格局
在一个平面坐标图中把各个声调的T值数据依次标示为坐标点,再用平滑曲线分别把同一声调的各点联接起来,就成为这种语言或方言的声调格局图。图1是北京话的声调格局图。采用T值的计算方法得出声调格局图形,可以直观地表现声调的系统特征和相对关系,增强不同地点和不同发音人相互之间的可比性。
1.2 声调格局数据的统计分析
在对于大样本声调实验数据进行统计分析中,需要在原有T值公式的基础上做适当调整。适合大样本声调统计的T值公式如下:T={[lg x-lg(min-SDmin)]/[lg(max+SDmax)-lg(min-SDmin)]}×5。跟原有T值公式相比,新的T值公式把最小值(min)改为(min-SDmin),即各测量点平均值中的最小值减去该点全部数据的标准差;最大值(max)改为(max+SDmax),即各测量点平均值中的最大值加上该点全部数据的标准差。经过调整的T值公式消除了大样本统计分析中最大值(max)和最小值(min)受到的抑制作用。原有的T值公式适合于单个发音人的小样本数据处理,调整的T值公式适合于多个发音人的大样本数据统计。
标准差根据一组数据中每个值跟平均值的差异量得出这组数据分布的离散程度,是数据统计特性的重要表现之一。在声调统计分析中,可以基于各测量点T值数据的标准差来考察每个声调的主体分布。图2为52位北京发音人的声调主体分布图。其中,位于中间的曲线由9个点的平均值确定,这就是带状包络的中线或主线;上方和下方的曲线分别由平均值加减标准差而得到。每个声调的不同部位的数据分布各不相同。数据集中的部位发音比较稳定。依据数据集中的程度可以区分出每一声调的稳态段和动态段,进而可以考察声调的共时变化和历时变化的特点和规律。如果把标准差作为声调稳态段的指标,则可以把标准差较小的部分看作稳态的分布,反之则是不稳定的分布。由此得出稳态段是:阴平的起点和终点;阳平的终点;上声的折点和去声的起点。动态段是:阳平的起点、上声的起点和终点、去声的终点(王萍、石锋2009)。

图2 北京话四个声调的主体分布总图
1.3 声调统计中的偏分布
人们通常假设一般样本的数据都是正态分布。因此通常是在平均值上下各加减一个标准差的距离作为数据分布的主体范围。理想正态分布的中位数跟平均数是重合的,如图3上;实际上二者却常常是分开的,这就是数据的实际分布跟理想的正态分布有不同程度的偏离现象,如图3下。如何描述和分析数据分布的偏离程度和偏离方向,在语言研究中十分重要。
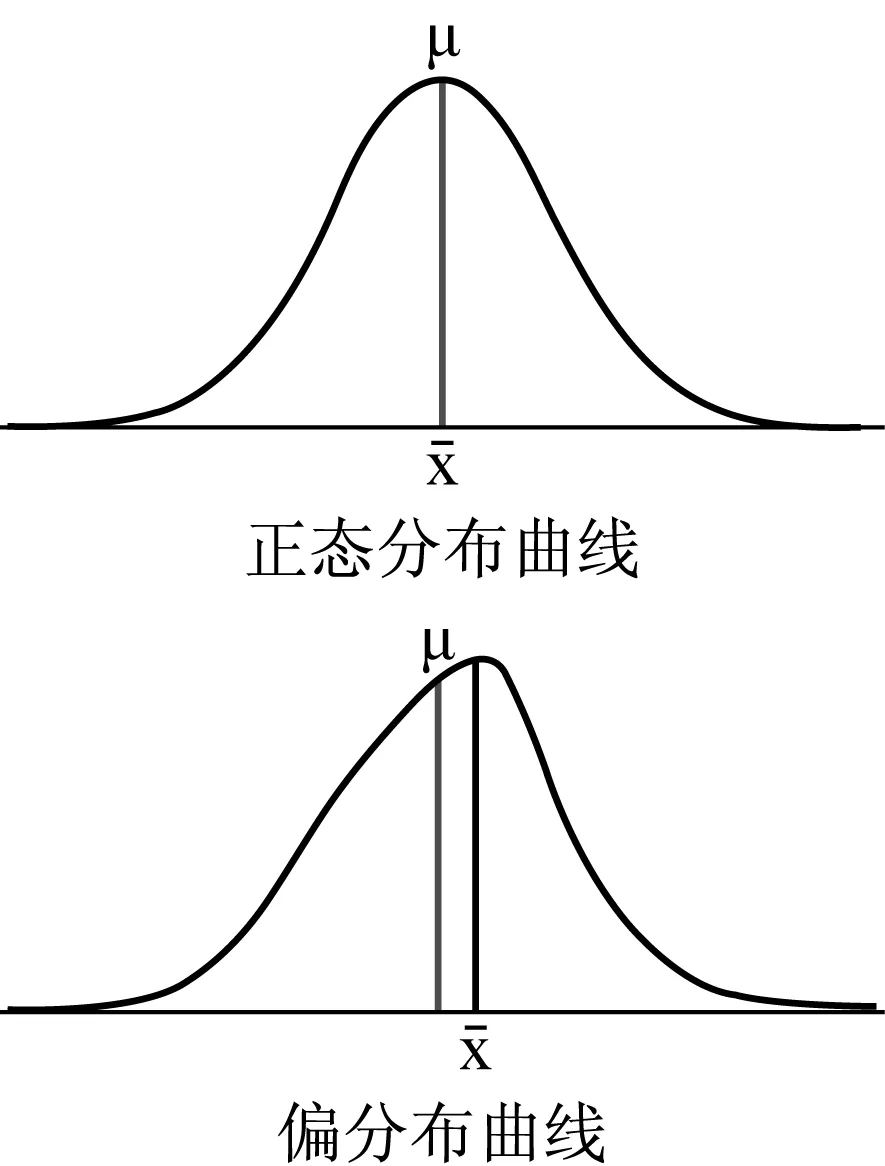
图3 正态分布、偏分布曲线
为了对这种数据偏离现象进行量化描述,可以采用以下一种简单的计算方法。
设:N1为小于平均值的数据个数;N2为大于平均值的数据个数;D1为N1跟平均值之间的平均距离;D2为N2跟平均值之间的平均距离。M为样本数据总数。得到:
N1×D1=N2×D2
N1∶N2=D2∶D1
(N1/M)∶(N2/M)=D2∶D1
即N1与D1成反比关系,N2与D2成反比关系。
把(N1/M)作为计算大于平均值的数据分布的偏离参数,把(N2/M)作为小于平均值的数据分布的偏离参数。就有N1/M+N2/M=1或∴N2/M=1-N1/M。偏离参数(N1/M)为0.5表明数据是平均分布;(N1/M)大于0.5表明数据分布偏向平均值下方;(N1/M)小于0.5表明数据偏向平均值上方。
再设:SD为标准差。就有(N1/M)×2SD,得到的是数值大于平均值的数据在主体分布中的距离位置;还有(N2/M)×2SD,得到的是数值小于平均值的数据在主体分布中的距离位置。
另外,如果把0.5定位为零点,那么大于0.5就是正值,小于0.5就是负值,变化偏离的方向看起来就会一目了然。

图4 北京话四个声调的偏分布总图
图4是通过计算声调的每个点的偏离参数(N1/M)而得到的北京话四个声调的偏分布总图。结果表明:声调数据的偏离表现突出和强化了各自的区别性特征。相对于动态段而言,稳态段中数据的偏离方向更清晰、偏离程度更显著。如阳平调稳态段调尾的数据多向平均值上方偏离,突出“高”、“升”特征;上声调的2/3数据向平均值下方偏离,突出“低”特征,其中稳态段折点处偏离程度最大;去声的调头和调干各点数据多朝向平均值上方偏离,突出开头的“高”特征,其中稳态段调头的偏离程度最显著(王萍、石锋2009)。
1.4 声调格局的应用
1.4.1 语言变异及演化研究
石锋和王萍(2006a;2006b)依据52位北京发音人的较大样本,按性别、年龄、家庭语言环境进行声调数据的分组统计,发现男女发音的声调曲线具有系统性差异。老北京人各声调的分布依照年龄段呈现出有规律的分布,显示出北京话声调正在发生细微的变化(见图5)。

图5 北京话四声的性别比较
从图5中,我们可以看到女性和男性的声调曲线的整体位置很接近,并且呈现有规律的分布,即女性的声调曲线基本都位于男性的上方。
石锋、王萍(2004)通过200位天津发音人的大样本统计分析,得到天津话连读变调的新派跟老派发音之间有系统性的差异。按年龄段分别对语体差异和使用频度分组统计考察,发现了变化方向和变化速率的量化对应关系。
1.4.2 语言接触研究
贝先明(2008)采用声调格局的方法分析湘语和赣语之间的方言接触,发现混合型方言的语音格局的构建、发展和演变是语言内部因素和外部因素共同作用的结果(见图6)。
在两种方言不同语音接触中的演化表现出三种模式:过渡、越位、反弹。其中过渡模式出现最多,反弹模式出现最少。
方言接触中,混合方言与目的方言有可能产生同调调值相似,也有可能产生异调调值相似。这两种调值相似都体现了方言接触中语音趋同的规律,是方言接触在声调调值上的重要表现。从上图来看,撇开调类的对应,混合方言浏阳话的5个声调,有3个声调(阴平、阳平、入声)的调值和目的方言长沙话的调值一样,有2个声调(上声、去声)的调值和长沙话的调值相近。

图6 方言接触声调格局图
1.4.3 二语习得研究
梁磊和张薇(2010)考察了蒙古学生所发的四个普通话声调,发现除了去声以外,其他三声都存在着一定的发音偏误(见图7):
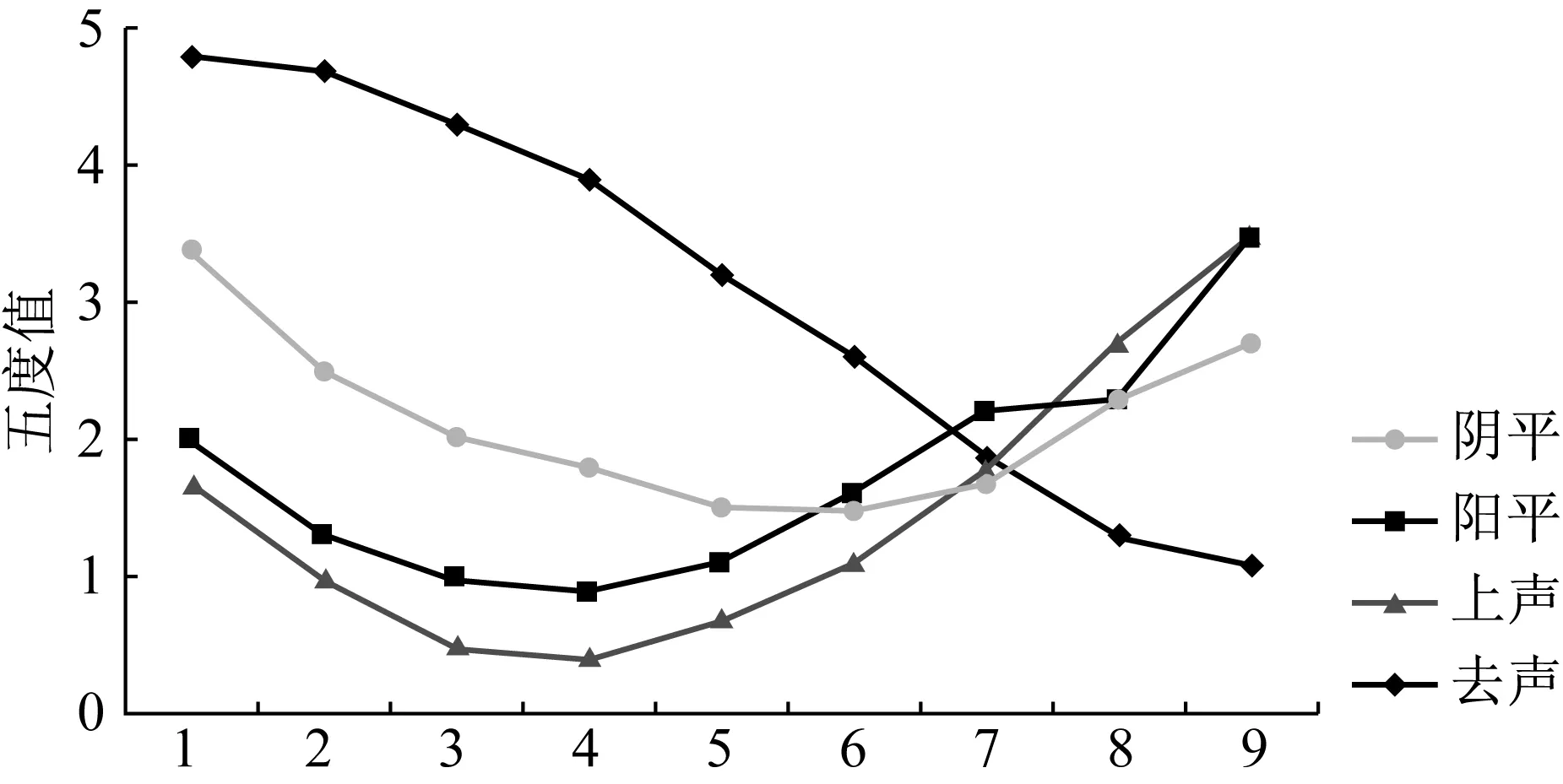
图7 蒙古学生普通话四声格局图
2.1 元音V值的计算
元音格局是元音系统性的表现,包括的内容可以有元音的定位特征、内部变体的表现、整体的分布关系等等。元音格局重在主要元音的表现。主要元音在音节中可以有各种组合:出现在单韵母中的元音是一级元音,又称为基础元音;能够带韵头的元音是二级元音;能够带韵尾的元音是三级元音;既能够带韵头又能带韵尾的元音是四级元音(石锋2008)。
声学元音图的纵轴坐标为线性标度的元音第一共振峰(F1)数据,横轴坐标为对数标度的元音第二共振峰(F2)数据,坐标的零点设在右上角。每个单元音的发音数据在图上都可以标示为一个点。声学元音图跟发音舌位图在相对位置上大致对应,又称为声位图。利用声位图分析元音的格局是很方便的。首先,舌位高低跟F1密切相关:舌位高,F1就小;舌位低,F1就大。其次,舌位前后跟F2密切相关:舌位靠前,F2就大,舌位靠后,F2就小。另外,F2和嘴唇的圆展也有关系,圆唇作用可以使F2降低一些。我们从中可以直观地考察同一元音音位内部变体的表现,以及不同元音之间分布的相对关系等等(见图8)。
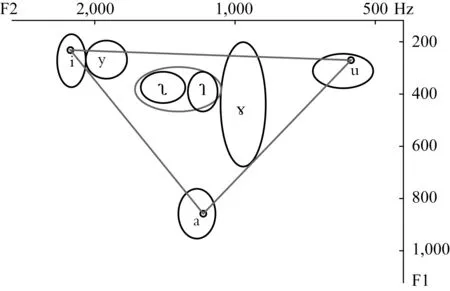
图8 北京话基础元音声位图
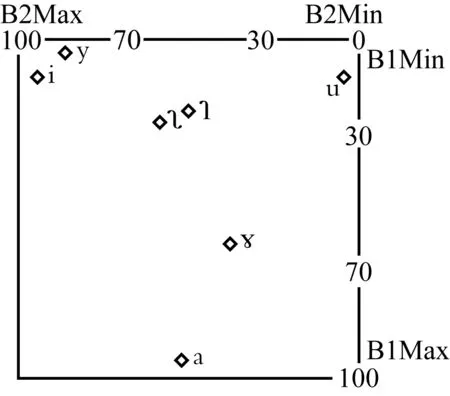
图9 北京话基础元音格局图
以元音声位图为基础,利用V值公式进行计算,可以得到相对化的元音格局图(见图9)。为了接近实际的听感距离,依次将全部共振峰频率值转换为对数性的巴克值(Bark)。元音V值的计算公式如下(时秀娟2007):
其中,V1为某元音第一共振峰的相对值,V2为这个元音第二共振峰的相对值。B1max表示各元音第一共振峰中最大的巴克值,B1min为各元音第一共振峰中最小的巴克值,B1x表示某元音的第一共振峰巴克值;B2的情况据此类推。在V值计算中,一般首先要把频率值做对数性转换,包括常用对数、半音、美标度、巴克等,选择其中任何一种进行换算都可以。关键是归一化、相对化的计算过程。
元音格局V值与声调格局T值的出发点是一致的。V值计算的意义是实现元音分析的归一化、相对化。将每一个元音放在该语言(或方言)的全部元音空间中来考察,得到各元音在元音空间中的相对表现。从而淡化不同发音人的个性差异,突显同一语言元音系统的共性特征。
2.2 元音三维分析图
对于元音声学特性的描写,可以采用三维的方法:分别将F1、F2、F3-F2作为三维空间的三个维度,即x轴、y轴、z轴。上文已经讲到F1、F2跟元音发音的对应关系。圆唇和卷舌两种发音都同样会使第三共振峰(F3)降低,但圆唇作用使F2降低,卷舌作用使F2升高,从而跟F3彼此接近。所以F3-F2这个参量能够较好地区分圆唇和卷舌这两种发音特征,从而增大元音间的区分度(见图10)。

图10 北京话基础元音三维平面声位图
各种元音在三维空间中不同平面(F1/F2、F1/F3-F2)的相对关系存在着补偿性。主要表现为三种类型:第一、F1/F2平面上相互距离较小的元音,在F1/F3-F2平面上的距离显著增大;第二、F1/F2平面上彼此距离较大的元音,在F1/F3-F2平面上的距离反而会减小;第三、还有的元音在F1/F2和F1/F3-F2两个平面中与其它元音之间的距离都是比较适中,都能形成较好的区别性(王萍、贝先明、石锋2009)。
相对于单纯的二维声学空间,三维声学空间在表现各元音的分布距离及相对关系上能够更有效、更全面地对不同元音进行定位,从而更真实地反映语音的实际表现。
2.3 元音格局数据的统计分析
跟声调的统计分析一样,在对于大样本元音实验数据进行统计分析中,需要在原有V值公式的基础上做适当调整。以第一共振峰(F1)为例,先分别统计所有元音的对数性Bark值中的最大值(B1max)和最小值(B1min),以及这两个Bark值所对应的元音的标准差(SD1max、SD1min)。分别用B1max+SD1max代替B1max;用B1min—SD1min代替B1min。第二共振峰(F2)也同样处理。然后,就可以分别计算每个元音F1和F2的平均值、标准差,得到Bark标度的值;最后,使用调整的V值公式进行归一化,将以上各个Bark标度的值转换为V值标度,画出相对的元音主体分布图(孙雪、石锋2009)。
总括以上说明,适合大样本元音统计的V值公式如下:
经过调整的V值公式消除了大样本统计分析中位于顶点的元音分布区域受到的抑制作用,更符合实际发音事实。原有的V值公式适合于单个发音人的小样本数据处理,调整的V值公式适合于多个发音人的大样本数据统计。
采用以上方法分析26种自然语言中的基本元音(见图11),可以看到/i/元音分布区域最小,集中程度最好,是元音发音的基点。/a/、/u/元音分布区域增大。/a/的差异主要体现在高低上;/u/在前后维上游移较大。

图11 自然语言基本元音声学分布图
2.4 元音统计中的偏分布
以V值公式为基础,同时按照上文所述的偏分布算法,我们对52位北京话发音人的基础元音的顶点元音进行了偏分布统计分析。北京话元音/i/的数据偏分布在平均值的前半部分;元音/a/的偏分布位于后上方;元音/y/、/u/的偏分布都位于前上方(见图12)。
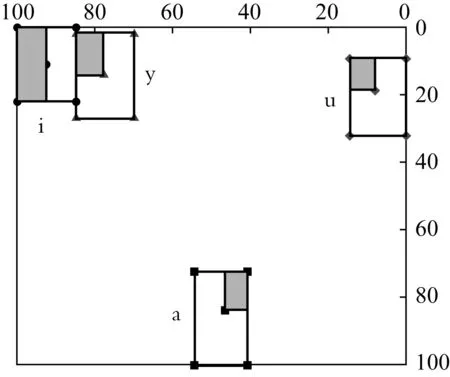
图12 北京话基础元音中顶点元音的偏分布格局图
偏分布分析可以使我们看到不同元音数据的偏离方向、偏离位置和偏离程度。这些定量的表现提供了联系元音共时表现和历时变化的纽带。/a/、/i/、/u/这三个顶点元音的数据偏分布的位置与它们各自的历时变化方向相一致,又可以预示未来的“音变方向”。/a/的高化符合“低元音高化”的通则,/u/的前化符合“后元音前化”的通则(Labov 1994:116)。/i/的前化符合发音省力的原则,同时从北京话的元音格局来看,/i/的前化有利于跟/y/的区别,保持相互之间的音位距离(王萍、石锋2008)。
2.5 元音调格局的应用
2.5.1 儿童语言习得研究
儿童掌握语音的先后顺序与语音的普遍性密切相关,对于儿童语音发展的顺序的研究,也会对语音共性的研究有重要意义。温宝莹(2008)将语音格局应用到儿童语言习得研究中,考察40名汉语儿童的普通话元音正确率和发音表现。结果显示儿童元音发音的错误并不是某一个人偶然发生的错误,而是大多数儿童对于某个元音在某一阶段的系统性的发音倾向。儿童元音的发展也具有系统性,儿童习得元音的过程就是建立系统的过程。每个元音的出现并不是孤立的现象,都是最大限度地去建立和维持音位间的对立。舌位高低先于舌位前后,也就是开口度的区别最先掌握。元音的高低是第一维度的区分;元音的前后是元音系统的第二维度;圆唇度是元音系统的第三维度;舌尖发音和舌面发音的区分,是元音系统的另一个维度。普通话儿童汉语七个基础元音的习得顺序如下:/a/>/i/>//>/u/>//>//>/y/(>表示早于)。
总之,不同的元音依据发音难易程度排定习得次序。这个次序又恰好反映出每个元音在系统中的位次。同时,这种习得次序也显示出各个元音音位的标记性不同,习得越晚,标记性越强(石锋、温宝莹2007)。
2.5.2 语言共性及类型研究
比较不同语言或方言的语音格局,可以考察语言的共性特征和类型区分,具有语言类型学的意义。时秀娟(2007)用实验分析的方法研究汉语方言40个点的元音格局,得出汉语方言元音格局的类型特点:优先采用无标记元音/a/、/i/、/u/;一般有6至9个基础元音;前重型多于后重型和同重型;央元音不多于一个。
孙雪(2009)考察人类26种自然语言中的元音格局,比较它们在分布范围、相对位置、系统关系等方面的特点,可以发现元音/i/的分布最集中、语际差异和人际差异均最小,是人类元音发音中的基点。从基点出发,在高低维度上延伸,确定/a/;在前后维度上延伸,确定/u/。其他元音位置都随这三个元音而定。语言的普遍性不仅存在于句法和语用等方面,在语音层面也明显存在。
3. 结语
经过二十余年的不懈努力,从声调格局,到辅音格局(冉启斌2011)、元音格局、语调格局(王萍、石峰2011),我们始终面向“语言学的语音学”(linguistic phonetics,LP)这一研究对象,秉承实验音系学的研究范式,致力于归一化、相对化基础上的语音系统性探索。利用T值、V值的计算,分别把声调与元音的语音学研究、音系学研究,传统定性研究、科学的定量研究很好地结合起来,并在语言演变、语言接触及语言习得等研究领域得到了初步的应用成果。
Labov, William. 1994.PrinciplesofLinguisticChange:InternalFactors[M]. Cambridge, MA: Blackwell.
贝先明.2008.方言接触中的语音格局[D].南开大学博士学位论文.
梁磊、张薇.2010.蒙古留学生汉语声调习得初步研究[A].第九届国际汉语教学研讨会论文选编辑委员会.第九届国际汉语教学研讨会论文选[C].北京:高等教育出版社.695-702.
冉启斌.2011.辅音声学格局研究[J].当代外语研究(8):待刊.
石锋.1986.天津方言双字组声调分析[J].语言研究(1):77-90.
石锋.1990.语音学探微[M].北京:北京大学出版社.
石锋.2008.语音格局——语音学与音系学的交汇点[M].北京:商务印书馆.
石锋.2009.实验音系学探索[M].北京:北京大学出版社.
石锋、廖荣蓉.1994.语音丛稿[M].北京:北京语言学院出版社.
石锋、王萍.2004.天津话声调的新变化[A].石锋、沈钟伟.乐在其中:王士元教授七十华诞庆祝文集[C].天津:南开大学出版社.176-191.
石锋、王萍.2006a.北京话单字音声调的统计分析[J].中国语文(1):33-40.
石锋、王萍.2006b.北京话单字音声调的分组统计分析[J].当代语言学(4):324-333.
石锋、温宝莹.2007.汉语普通话儿童的元音发展[M].中国语文(5):444-454.
时秀娟.2007.现代汉语方言元音格局的类型分析[J].南开语言学刊(1):70-78.
孙雪.2009.国际音标元音发音声学分析[D].南开大学博士学位论文.
孙雪、石锋.2009.自然语言与国际音标元音发音比较[J].南开语音年报3(1):24-33.
王萍.2007.普通话单字调和元音的统计性研究[D].南开大学博士学位论文.
王萍、贝先明、石锋.2009.元音的三维空间[J].南开语音年报3(1):15-23.
王萍、石锋.2008.北京话一级元音的统计分析[J].中国语音学报(1):104-110.
王萍、石锋.2009.北京话单字音声调的再分析[J].南开语音年报3(2):75-81.
王萍、石锋.2011.试论语调格局的研究方法[J].当代外语研究(5):10-17.
温宝莹.2008.汉语普通话的元音习得[M].天津:南开大学出版社.
猜你喜欢
幼儿100(2023年9期)2023-03-24 07:24:50
作文周刊·小学一年级版(2022年28期)2022-05-30 10:48:04
考试与评价·七年级版(2021年1期)2021-08-14 04:25:30
小天使·一年级语数英综合(2020年9期)2020-12-16 02:57:03
考试与评价·七年级版(2020年1期)2020-10-23 09:10:18
早期教育(家庭教育)(2020年1期)2020-05-28 23:19:57
小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:16
作文周刊·小学一年级版(2019年28期)2019-09-07 03:42:03
儿童绘本(2016年2期)2016-02-18 05:15:37
儿童绘本(2015年6期)2015-05-25 17:48:45
